Hadoop+Spark+Zookeeper+Hbase集群搭建
Posted 吾仄lo咚锵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop+Spark+Zookeeper+Hbase集群搭建相关的知识,希望对你有一定的参考价值。

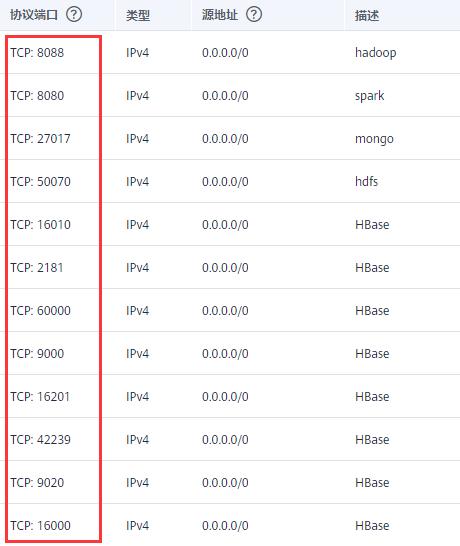
端口
端口开放问题
关闭防火墙systemctl stop firewalld,并在服务器开放以下端口:
Hadoop
vim core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
</property>
vim hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hdfs_name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hdfs_data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop1:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
vim mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
vim yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8

Spark

(
插播反爬信息)博主CSDN地址:https://wzlodq.blog.csdn.net/
Zookeeper
wget https://downloads.apache.org/zookeeper/stable/apache-zookeeper-3.6.3-bin.tar.gz
tar -zxvf apache-zookeeper-3.6.3-bin.tar.gz
mv apache-zookeeper-3.6.3-bin /usr/local/zookeeper
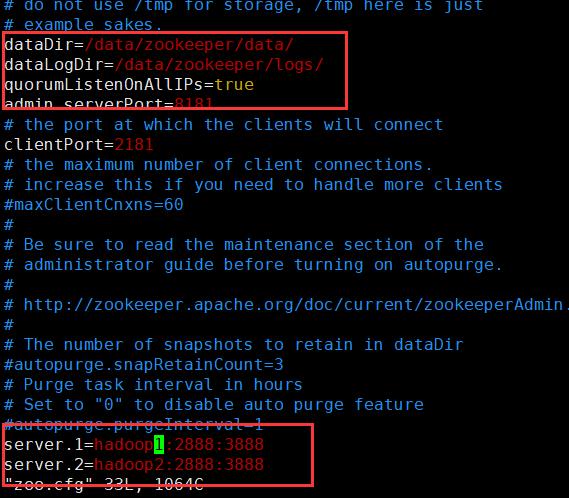
- 配置zoo.cfg
cd /usr/local/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
dataDir=/data/zookeeper/data/
dataLogDir=/data/zookeeper/logs/
quorumListenOnAllIPs=true
admin.serverPort=8181
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
- 配置myid
mkdir -p /data/zookeeper/
cd /data/zookeeper/
mkdir data logs
cd data
vim myid

- 同步
scp -r /usr/local/zookeeper/ hadoop2:/usr/local/
- 启动
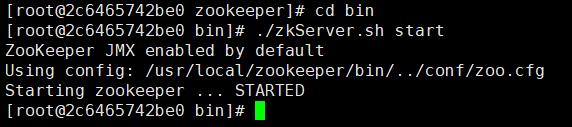
在各个节点启动zookeeper
cd /usr/local/zookeeper/bin
./zkServer.sh start
Hbase
IDEA远程连接HBase及其Java API实战当时这篇是单机的,没介绍集群,步骤基本一致。
- 下载解压
wget https://downloads.apache.org/hbase/2.3.5/hbase-2.3.5-src.tar.gz
tar -zxvf hbase-2.3.5-src.tar.gz
mv hbase-2.3.5 /usr/local/hbase
- 配置hbase-site.xml
cd /usr/local/hbase/conf
vi hbase-site.xml
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop1:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181</value>
<description>The directory shared by RegionServers. </description>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>90000</value>
<source>hbase-default.xml</source>
</property>
- 配置hbase-env.sh
cd /usr/local/hbase/conf
echo $JAVA_HOME
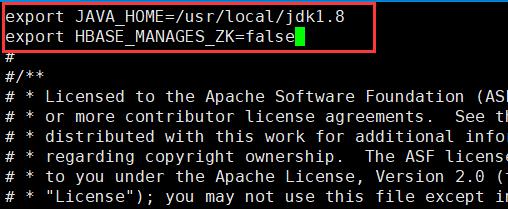
vi hbase-env.sh #添加和你输出的JAVA_HOME一致
export JAVA_HOME=/usr/local/jdk1.8
export HBASE_MANAGES_ZK=false
- 设置从节点
cd /usr/local/hbase/conf
vi regionservers
- 同步
将主节点Hbase配置同步给从节点
scp -r /usr/local/hbase/ hadoop2:/usr/local/
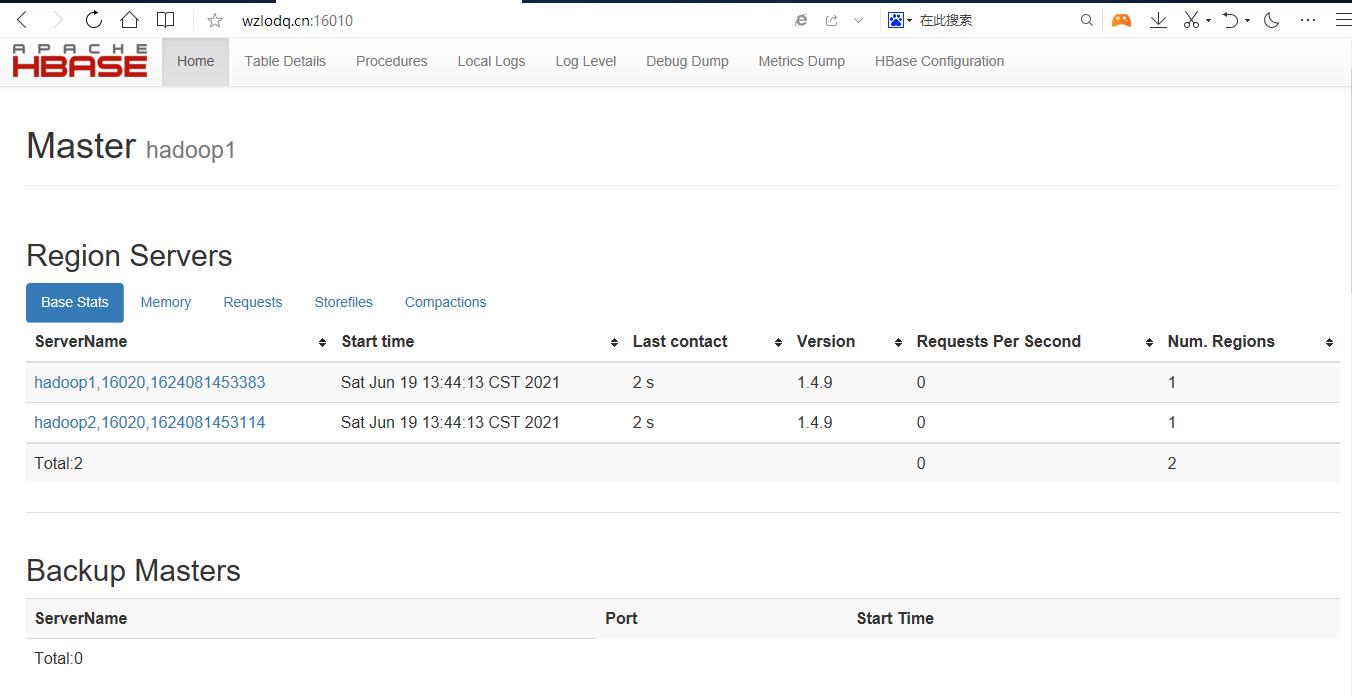
- 启动测试
记得先启动zookeeper和hadoop
cd /usr/local/hbase/bin
./start-hbase.sh
原创不易,请勿转载(
本不富裕的访问量雪上加霜)
博主首页:https://wzlodq.blog.csdn.net/
来都来了,不评论两句吗👀
如果文章对你有帮助,记得一键三连❤
以上是关于Hadoop+Spark+Zookeeper+Hbase集群搭建的主要内容,如果未能解决你的问题,请参考以下文章