Elasticsearch:理解 Elasticsearch Percolate 查询
Posted 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:理解 Elasticsearch Percolate 查询相关的知识,希望对你有一定的参考价值。
这篇博文深入探讨了 Elasticsearch 的 percolate query。此机制允许你根据已注册的查询对文档进行分类或标记。起初听起来很奇怪的是一个强大的机制,我们将在这篇文章中深入探讨。
为什么我需要 percolate query?
这是渗透功能最难的部分。因为它翻转了文档和查询之间的关系,所以第一次阅读或解释时很难理解这一点。让我们尝试一些用例:
- 你正在运营一个新闻网站,并希望在你呈现的每篇文章中投放广告。一篇关于汽车的文章投放与移动性有关的广告可能是有道理的。如果一篇文章是关于健康的,不妨展示一些健康的食物或运动服。
- 你正在运营一个二手车在线市场。用户正在输入他们的汽车标准,但对显示的汽车不满意。你允许他们注册警报以在符合他们要求的合适汽车添加到你的汽车列表后发送通知。
- 你正在经营一家商店。用户点击了缺货的产品。你希望确保在该产品重新入库后通知用户。
这个概念与许多其他用例类似:约会平台、工作平台 - 一旦将新文档添加到符合用户要求的数据中,就需要通知机制。
这里的基本思想是,你正在存储带有参数的查询,例如:
brand:bmw AND model:330e AND price < 35000 AND region:Munich- product_id:XYZ AND stock:>1
并且每当文档与这些查询之一匹配时,你希望通知存储该查询的用户。
这基本上就是 percolate。因此,不是存储文档并对其运行查询,percolate 需要存储查询并对其运行文档。这就是为什么它经常被称为翻转查询和文档的原因。
过去曾经存在一个专用的 percolate API,而现在,percolator 是作为自定义查询实现的。这使得理解基本概念有时变得更加复杂,因为它看起来像所有其他查询。
理解概念
那么,让我们来看看 percolate 时会发生什么。对于此示例,我们将采用汽车广告用例。用户已保存查询以搜索特定汽车条件。在某个时候,一个新的 Tesla Model 3 出现了,它的 JSON 表示看起来像这样:
{
"brand": "Tesla",
"model" : "3",
"price": 60000
}让我们忽略这是一个不完整的文档,缺少许多字段,例如区域(可能是最常见的过滤器)及其所有功能。
倒排索引中的表示与其他汽车一起可能看起来像这样:
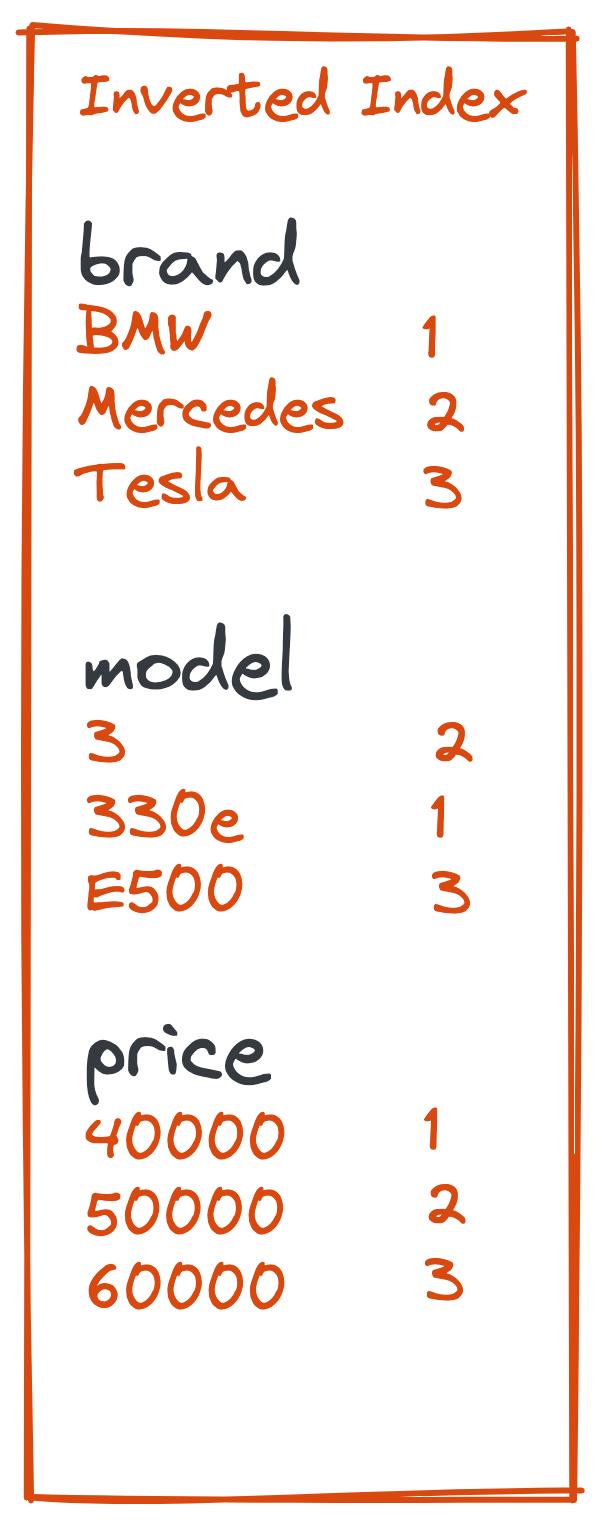
上面的倒排索引包含三种 car 的三个字段。 搜索可能如下所示:

事实证明,没有便宜的特斯拉。 想象一下,当特斯拉的价格低于或等于 50k 时,我们希望收到通知。
用户可以存储一个小于 50000 的与 Tesla Model 3 的条件匹配的查询。当针对存储的查询运行文档时,percolate 开始。
通过使用新的 Tesla Model 3 文档,percolate 查询从中创建了一个内存索引。 此内存索引仅在 percolate query 查询期间存在。
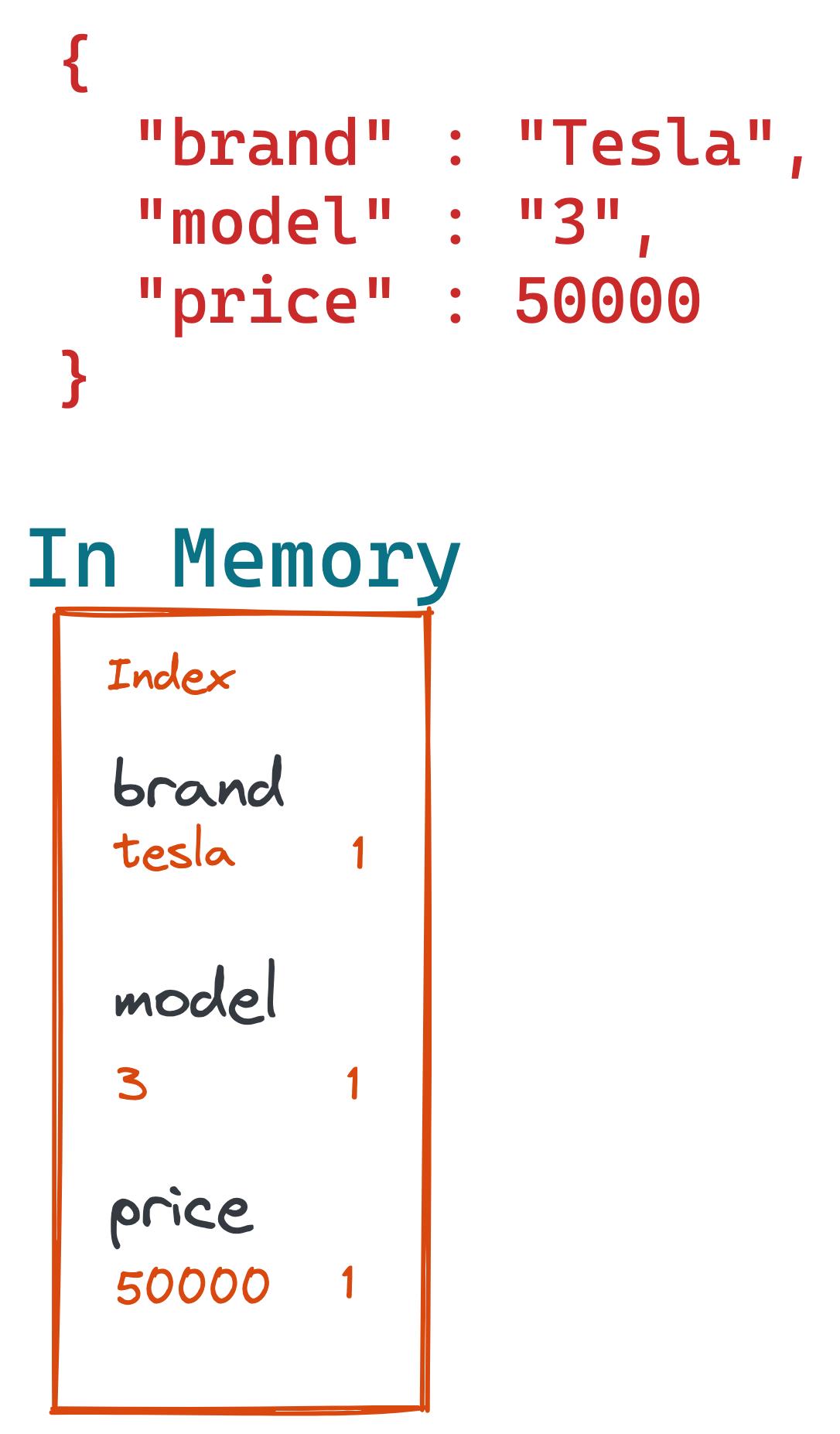
如果作为下一步,percolate query 现在检索存储的搜索,例如搜索低于 50k 的 Tesla。

现在最后一步是针对内存索引运行每个存储的查询,并简单地返回匹配的查询。
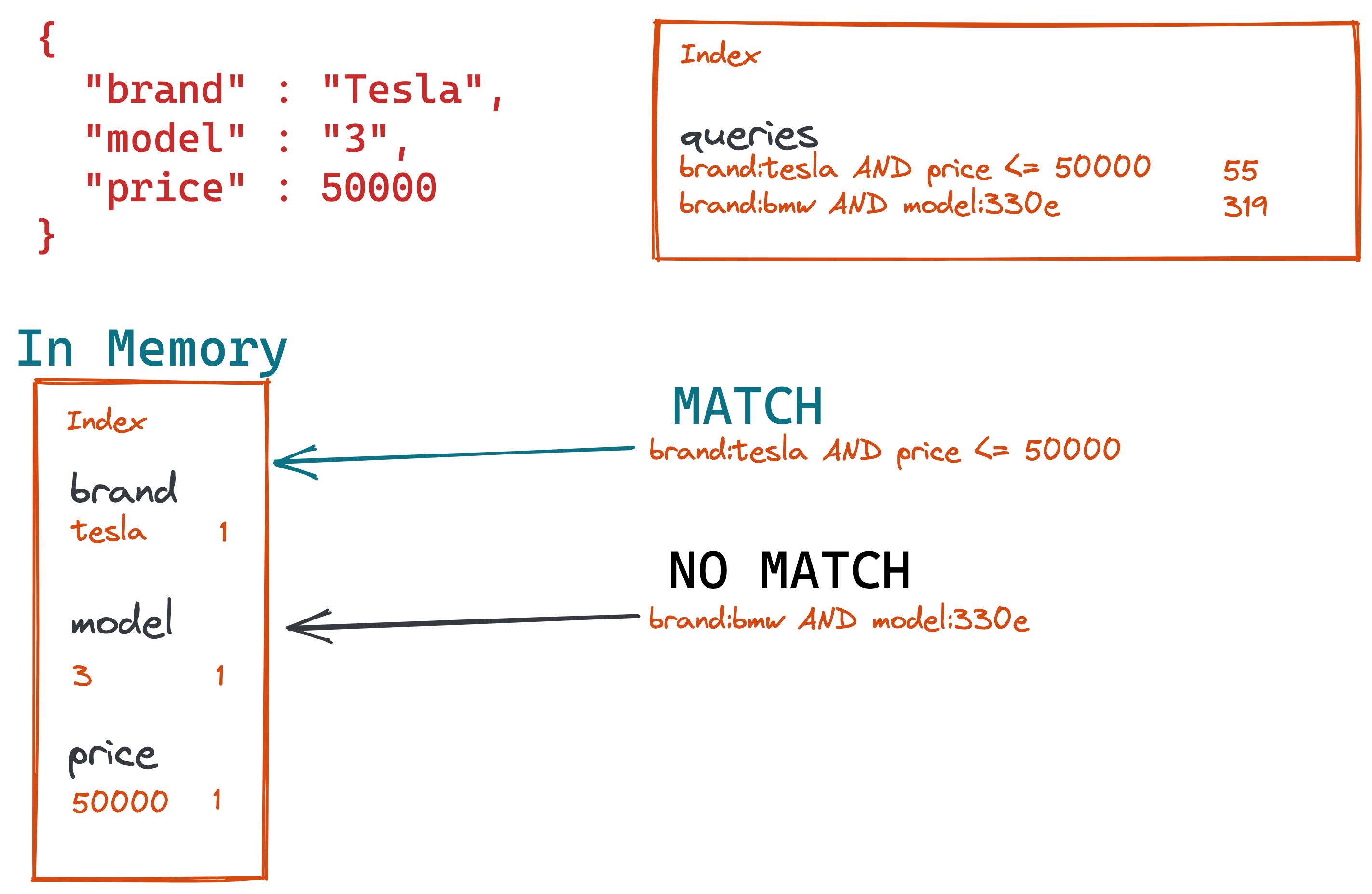
将查询匹配的信息作为查询响应的一部分,你现在可以触发任何机制,例如发送电子邮件或触发应用程序内通知,以向你的用户发送有关可用的新的廉价 Tesla 的信息。
这是核心概念。 它有更多功能,但这就是每次渗透都会发生的情况。
让我们抛开概念,深入探讨具体的 Elasticsearch 实现。
Document index
让我们继续以汽车广告为例,创建一个包含三辆汽车的汽车索引。
PUT cars
{
"mappings": {
"properties": {
"brand" : { "type" : "keyword" },
"model" : { "type" : "keyword" },
"price" : { "type" : "long" }
}
}
}
PUT cars/_bulk?refresh
{ "index" : { "_id": "1" } }
{ "brand" : "Tesla", "model" : "3", "price": 60000 }
{ "index" : { "_id": "2" } }
{ "brand" : "BMW", "model" : "330e", "price": 40000 }
{ "index" : { "_id": "3"} }
{ "brand" : "Mercedes", "model" : "E500", "price": 50000 }以下查询不会产生结果,因为目前没有廉价的 Tesla 索引:
GET cars/_search
{
"query" : {
"query_string" : {
"query" : "brand:Tesla AND model:3 AND price:<=50000"
}
}
}但是,我们希望得到通知并进行该确切查询并将其存储在我们的 percolate 索引中。 现在让我们创建一个:
Percolate index
创建 percolate index 时,你需要从要查询的汽车索引中复制字段的映射:
PUT percolator-queries
{
"mappings": {
"properties": {
"query" : {
"type" : "percolator"
},
"brand" : { "type" : "keyword" },
"model" : { "type" : "keyword" },
"price" : { "type" : "long" }
}
}
}接下来是该存储警报的时候了:
PUT percolator-queries/_doc/tesla_model_3_alert
{
"query" : {
"query_string" : {
"query" : "brand:Tesla AND model:3 AND price:<=50000"
}
}
}现在,过了一段时间,一个汽车经销商想以 5 万美元的价格出售一辆特斯拉:
PUT cars/_bulk?refresh
{ "index" : { "_id": "4" } }
{ "brand" : "Tesla", "model" : "3", "price": 50000 }什么也没发生,因为在索引文档时,没有运行 percolate query。 我们需要手动执行此操作。
使用 percolate API
要么采用上述 JSON 文档并使用 percolate 查询,要么指定文档索引和 id 作为 percolate 查询的一部分:
GET percolator-queries/_search
{
"query": {
"percolate": {
"field": "query",
"document": {
"brand": "Tesla",
"model": "3",
"price": 50000
}
}
}
}
GET percolator-queries/_search
{
"query": {
"percolate": {
"field": "query",
"index" : "cars",
"id" : "4"
}
}
}这两个查询都返回完全相同的响应:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.2615292,
"hits" : [
{
"_index" : "percolator-queries",
"_type" : "_doc",
"_id" : "tesla_model_3_alert",
"_score" : 1.2615292,
"_source" : {
"query" : {
"query_string" : {
"query" : "brand:Tesla AND model:3 AND price:<=50000"
}
}
},
"fields" : {
"_percolator_document_slot" : [
0
]
}
}
]
}
}响应包含其查询与提供的文档匹配的 percolator-queries 索引的命中。 有了这些知识,我们现在可以继续向添加警报的用户发送电子邮件。 该电子邮件或用户 ID 可以存储在上述文档以及一个附加字段中。
常规查询响应的唯一补充是 _percolator_document_slot。 如果你提供多个文档,则这用于识别匹配的文档:
GET percolator-queries/_search
{
"query": {
"percolate": {
"field": "query",
"documents": [
{
"brand": "Tesla", "model": "3", "price": 60000
},
{
"brand": "Tesla", "model": "3", "price": 40000
}
]
}
}
}响应现在在 _percolator_document_slot 中包含 1,表示提供的数组中的文档 1(从零开始)匹配。
现在我们知道了 percolate 的基础知识。 让我们考虑一下高级功能和适当的集成:
文档管道中的渗透
事件订阅
如前所述,文档索引和运行 percolate 是不同的操作。这意味着你的管道需要意识到这一点并运行其他查询以触发此类警报。
如果你有另一个主数据存储,你将已经拥有将数据添加到搜索索引的机制 -- 这可能是基于事件的(想想 Kafka/Pulsar),然后你可以添加另一个使用相同流并针对其运行 Elasticsearch 的 percolate 查询。
Logstash
Logstash 具有 Elasticsearch 过滤器插件,当你指定模板文件时,该插件支持完整的查询 DSL。通过这种方式,你可以在索引文档之前运行 percolate 查询,然后在匹配的情况下使用不同的输出以触发产品警报。关于这个你可以参考我之前的文章 “Logstash:运用 Elasticsearch 过滤器来丰富数据”。
使用 cron 作业
如果你的文档具有 last_updated 字段,当它上次被索引/更新时,你可以使用它来运行 PIT 搜索,遍历所有文档,然后对每个请求进行过滤并指定多个文档以提高效率。
cronjob 方法提供了另一个简洁的功能。你可以根据与渗透查询一起存储的条件运行这些警报,以便优先考虑付费用户而不是免费用户的警报。谁不想早点买到更便宜的东西呢?
让我们来看看 percolate 还提供什么!
高级 percolate 功能
如果你对分数不感兴趣,你可以将 percolate 包装在一个 constant_score 查询中以获得一点速度提升。
GET percolator-queries/_search
{
"query": {
"constant_score": {
"filter": {
"percolate": {
"field": "query",
"documents": [
{
"brand": "Tesla",
"model": "3",
"price": 40000
}
]
}
}
}
}
}Filter 运行速度更快
另一个提速是不针对你的内存索引运行所有 percolate。 你可以使用过滤器来实现这一点。 想象一下,你有多个商业层级,并且只应包括某个特定组
PUT percolator-queries/_doc/tesla_model_3_alert
{
"query" : {
"query_string" : {
"query" : "brand:Tesla AND model:3 AND price:<=50000"
}
},
"type" : "platinum"
}这将另一个名为 type 的字段添加到 percolator 文档,我们可以立即在查询中使用:
GET percolator-queries/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"filter": [
{ "term" : { "type" : "platinum" } },
{
"percolate": {
"field": "query",
"documents": [
{ "brand": "Tesla", "model": "3", "price": 40000 }
]
}
}
]
}
}
}
}
}这样,只有 percolate 类型的查询才会被视为针对内存索引运行。
实际存储了哪些数据?
如果你对实际存储的数据感到好奇,请运行以下查询:
GET percolator-queries/_search
{
"fields": [
"query.*"
]
}这将返回 fields 参数作为每次命中的一部分:
{
...
"fields" : {
"query.extracted_terms" : [
"{query_string={query=brand:Tesla AND model:3 AND price:<=50000}}"
],
"query.query_builder_field" : [
{
"query_string" : {
"query" : "brand:Tesla AND model:3 AND price:<=50000"
}
}
],
"query.extraction_result" : [
"{query_string={query=brand:Tesla AND model:3 AND price:<=50000}}"
]
}
...
}所以,这些是 percolate 字段映射器存储的子字段。
Highlighting
要查看的最后一个功能是突出显示。 这在我们的广告示例中没有太大意义,因为在 percolator 查询中没有真正的全文查询。 通知用户新的新闻文章的服务怎么样? 让我们对此建模:
PUT articles-percolator
{
"mappings": {
"properties": {
"query" : {
"type" : "percolator"
},
"title" : { "type" : "text" },
"content" : { "type" : "text" }
}
}
}
PUT articles-percolator/_doc/1
{
"query": {
"multi_match": {
"query": "percolate",
"fields": ["title", "content"]
}
}
}现在对两个文档使用 percolate 查询:
GET articles-percolator/_search
{
"query": {
"percolate": {
"field": "query",
"documents": [
{
"title": "The Power of the Percolate Query",
"content": "This will be an introduction into percolation..."
},
{
"title": "Advanced Elasticsearch queries",
"content": "In todays lecture we will take a look at queries, that are less known but can influence your search in various interesting ways, i.e. the ids query or the percolate query."
}
]
}
},
"highlight": {
"fields": {
"title": {},
"content": {}
}
}
}这将返回以下内容,因为两个文档都匹配 "percolate":
{
"took" : 9,
"timed_out" : false,
"_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 },
"hits" : {
"total" : { "value" : 1, "relation" : "eq" },
"max_score" : 0.2772589,
"hits" : [
{
"_index" : "articles-percolator",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.2772589,
"_source" : {
"query" : {
"multi_match" : { "query" : "percolate", "fields" : [ "title", "content" ] }
}
},
"fields" : { "_percolator_document_slot" : [ 0, 1 ] },
"highlight" : {
"0_title" : [
"The Power of the <em>Percolate</em> Query"
],
"1_content" : [
"are less known but can influence your search in various interesting ways, i.e. the ids query or the <em>percolate</em>"
]
}
}
]
}
}这里有趣的部分是高亮响应字段中的 0_title 和 1_content 字段。 根据响应中的字段名称,你可以推断所提供文档中的哪个文档匹配,以及文档中的字段。
如果文档确实匹配,你现在可以在电子邮件中使用这些片段来为你的用户提供上下文。
在索引之前向文档添加 percolation 结果
另一个用例可能是基于 percolate 的响应来丰富文档的能力。 对于我在开头提到的标记用例,这可能是一个好主意。 让我们创建一些基本的标记示例,以确保每个人都有相同的理解:
PUT documents-percolator
{
"mappings": {
"properties": {
"query" : {
"type" : "percolator"
},
"title" : { "type" : "text" },
"content" : { "type" : "text" }
}
}
}
PUT documents-percolator/_doc/1
{
"query": {
"query_string" : {
"query" : "title:\\"us open\\" title:wimbledon title:\\"french open\\" title:\\"australian open\\""
}
},
"tags" : [ "sports", "sports-tennis" ]
}
PUT documents-percolator/_doc/2
{
"query": {
"query_string" : {
"query" : "title:djokovic"
}
},
"tags" : [ "sports", "sports-niqlo" ]
}两个 percolate 查询还包含一个 tags 字段。 现在,我们可以根据 tags 字段收集用于投放广告的信息,如下所示:
GET documents-percolator/_search
{
"size": 0,
"query": {
"percolate": {
"field": "query",
"documents": [
{
"title": "US Open: Novak Djokovic wins against Alexander Zverev",
"content": "A dominant win against the german"
}
]
}
},
"aggs": {
"tags": {
"terms": {
"field": "tags.keyword",
"size": 10
}
}
}
}它返回以下聚合(由于 size 设置为 0,未显示具体文档):
"aggregations" : {
"tags" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "sports",
"doc_count" : 2
},
{
"key" : "sports-tennis",
"doc_count" : 1
},
{
"key" : "sports-uniqlo",
"doc_count" : 1
}
]
}
}我们现在可以将其添加到文档和索引的 tags 字段中,如下所示:
PUT documents/_doc/1
{
"title": "US Open: Novak Djokovic wins against Alexander Zverev",
"content": "A dominant win against the german",
"tags" : ["sports", "sports-tennis", "sports-uniqlo" ]
}基于此,你现在可以轻松找到应该与本文一起投放的广告。 如果你也将广告存储在 Elasticsearch 中,请考虑使用术语查找查询(terms lookup query)。
请注意,这仍然需要设置你的摄入管道以添加此额外步骤,在 Elasticsearch 内部无法执行此操作。
enrich 处理器呢?
在阅读最后一句话时,你可能认为 enrich processor 可能是在存储文档之前丰富信息的好方法。 一般来说,这是正确的,但这是一个重要的限制:该处理器的当前范围几乎是精确的键锁定并且不使用查询 - 即使在 7.16 中将支持 ranges。
我不确定 percolate processor 是否有意义,以便将渗滤查询作为摄入管道的一部分执行,因为这将是非常自定义的,你将添加到现有文档的响应的哪一部分。
总结
Percolator 从 0.15 版本开始就已经存在了——我不骗你,查看 2011 年的原始博客文章。然而,当时的实现有很大不同,即你可以一次性运行 percolate 和 index 操作,但整个架构是不可扩展的并在 2013 年发布 Elasticsearch 1.0 之前进行了大修(请参阅此幻灯片演示)。有了这些变化,人们可以跨多个节点和分片扩展 percolate 查询,如果有专用的渗透节点,则可以使用 shard allocation filtering。
此外,percolator 曾经是一个特殊的专用索引,而不是一个专门的查询。 2016 年进行了另一轮改进,通过在存储 percolator 查询时索引所有查询词,减少了需要针对内存索引触发的查询数量。
也就是说,percolator 的想法和概念已经存在了十年,直到今天还在进行各种改进和改进。如果你查看最近的 PR,你会发现 percolator 已经成为一个稳定的特性,只有几个 PR。这同样适用于问题。
还有一个不同的 Lucene 实现遵循相同的思想,将文档和查询的关系颠倒过来,以前称为 Luwak,并已合并到 Lucene 作为监视器子项目。不幸的是,关于那个的文档相当稀少。通常,由于所有查询都存储在内存中,因此监视器项目的内存要求稍高,但这也意味着 percolator 的延迟稍高。
如果你确实对 percolator 有新的想法或功能,我会全神贯注并充满好奇!
对我来说,percolate 的一个一般规则是,这永远不是你开始使用的功能。在某些时候,当你对数据和用例了解得更多时,你很可能会找到一个用例,但不知道你的数据的内在、以及你的用户如何查询该数据以及在哪些部分他们有兴趣这真的很难。所以,开始你的搜索用例,然后考虑随着时间的推移潜在的 percolate 用法。
快乐 Percolating!
更对阅读:Elasticsearch:理解 Elasticsearch 中的 Percolator 数据类型及 Percolate 查询
以上是关于Elasticsearch:理解 Elasticsearch Percolate 查询的主要内容,如果未能解决你的问题,请参考以下文章