Entity Framework Core 性能优化
Posted JimCarter
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Entity Framework Core 性能优化相关的知识,希望对你有一定的参考价值。
https://docs.microsoft.com/zh-cn/ef/core/performance/
1. 定位性能问题
1.1 通过LogTo方法
定位生成的sql语句和sql的执行时间。
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder
.UseSqlServer(@"Server=(localdb)\\mssqllocaldb;Database=Blogging;Integrated Security=True")
.LogTo(Console.WriteLine, LogLevel.Information);
}
info: 06/12/2020 09:12:36.117 RelationalEventId.CommandExecuted[20101] (Microsoft.EntityFrameworkCore.Database.Command)
Executed DbCommand (4ms) [Parameters=[], CommandType='Text', CommandTimeout='30']
SELECT [b].[Id], [b].[Name]
FROM [Blogs] AS [b]
WHERE [b].[Name] = N'foo'
这个sql执行了4ms。
注意:不建议在生产环境中配置LogTo。一方面会影响程序的运行速度,另一方面过多的日志会占用空间。
2.2 将sql与LINQ查询关联起来
上述的方法即使你知道了sql的问题所在,有时候也很难找到对应的linq是哪一个。所以需要跟linq打tag:
var myLocation = new Point(1, 2);
var nearestPeople = (from f in context.People.TagWith("This is my spatial query!")
orderby f.Location.Distance(myLocation) descending
select f).Take(5).ToList();
生成的sql中就会出现tag:
-- This is my spatial query!
SELECT TOP(@__p_1) [p].[Id], [p].[Location]
FROM [People] AS [p]
ORDER BY [p].[Location].STDistance(@__myLocation_0) DESC
2.解决问题
找到有问题的sql之后,下一步是分析这个sql的执行流程。对于sql server来说,SSMS执行sql时会生成这个sql的执行计划图,可做进一步分析。
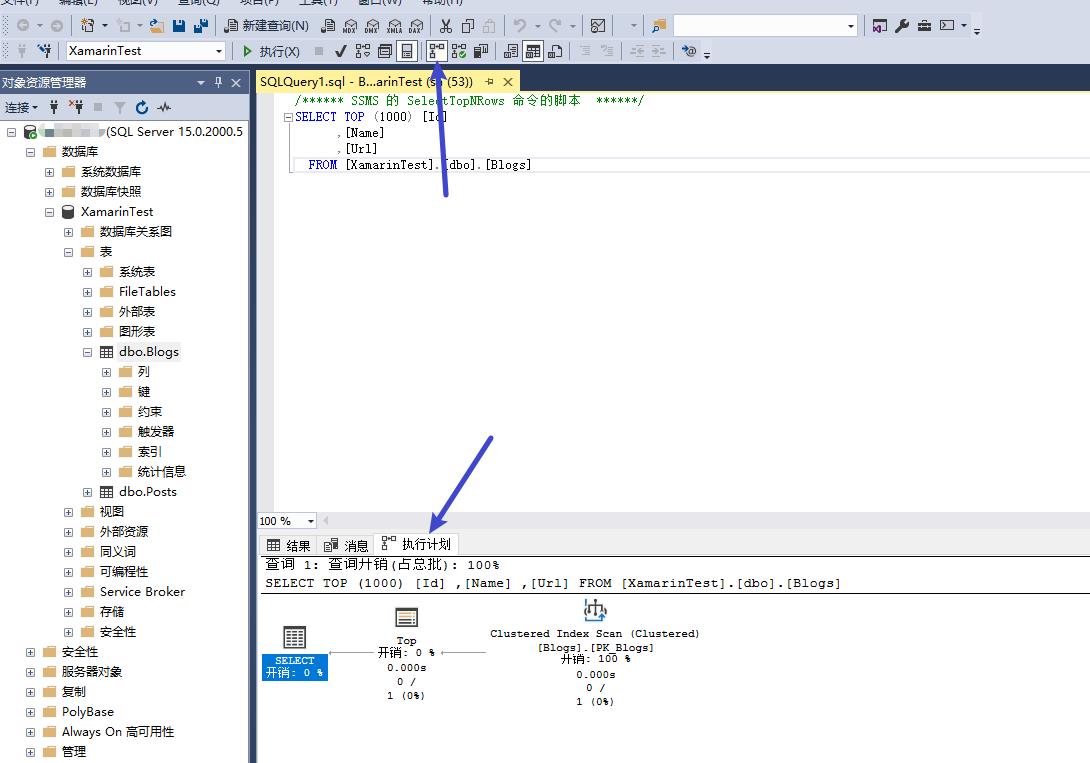
3. 进行Benchmark
如果同一个功能可以有多个实现,我们可以借助BenchmarkDotNet库进行基准测试。这里提供了一个基准测试用来比对一个计算平均值功能的4中实现:
- 加载所有实体,然后计算平均值
- 加载所有实体但是不启用跟踪(AsNoTracking),然后计算平均值
- 仅加载要计算的列,然后计算平均值
- 让数据库计算平均值
四个方法的实现如下:
//跟踪
[Benchmark]
public double LoadEntities()
{
var sum = 0;
var count = 0;
using var ctx = new BloggingContext();
foreach (var blog in ctx.Blogs)
{
sum += blog.Rating;
count++;
}
return (double)sum / count;
}
//不跟踪
[Benchmark]
public double LoadEntitiesNoTracking()
{
var sum = 0;
var count = 0;
using var ctx = new BloggingContext();
foreach (var blog in ctx.Blogs.AsNoTracking())
{
sum += blog.Rating;
count++;
}
return (double)sum / count;
}
//仅加载Rating列
[Benchmark]
public double ProjectOnlyRanking()
{
var sum = 0;
var count = 0;
using var ctx = new BloggingContext();
foreach (var rating in ctx.Blogs.Select(b => b.Rating))
{
sum += rating;
count++;
}
return (double)sum / count;
}
//数据库进行计算
[Benchmark(Baseline = true)]
public double CalculateInDatabase()
{
using var ctx = new BloggingContext();
return ctx.Blogs.Average(b => b.Rating);
}
结果如下:
| 方法 | 平均值 | 错误 | 标准偏差 | 中值 | 比率 | RatiosD | 第 0 代 | 第 1 代 | 第 2 代 | 已分配 |
|---|---|---|---|---|---|---|---|---|---|---|
| LoadEntities | 2,860.4μs | 54.31μs | 93.68μs | 2844.5μs | 4.55 | 0.33 | 210.9375 | 70.3125 | - | 1309.56 KB |
| LoadEntitiesNoTracking | 1353.0μs | 21.26μs | 18.85μs | 1355.6μs | 2.10 | 0.14 | 87.8906 | 3.9063 | - | 540.09 KB |
| ProjectOnlyRanking | 910.9μs | 20.91μs | 61.65μs | 892.9μs | 1.46 | 0.14 | 41.0156 | 0.9766 | - | 252.08 KB |
| CalculateInDatabase | 627.1μs | 14.58μs | 42.54μs | 626.4μs | 1.00 | 0.00 | 4.8828 | - | - | 33.27 KB |
注意:BenchmarkDotNet只是单线程运行方法
4. 查询优化
4.1 正确使用索引
// Matches on start, so uses an index (on SQL Server)
var posts1 = context.Posts.Where(p => p.Title.StartsWith("A")).ToList();
// Matches on end, so does not use the index
var posts2 = context.Posts.Where(p => p.Title.EndsWith("A")).ToList();
配合数据库检查工具(如之前介绍的SSMS的执行计划),找出索引问题。
4.2 只查需要的属性
如果只需要Id和Url属性那就不要查其他的。
foreach (var blogName in context.Blogs.Select(b =>new{Id=b.Id,Url=b.Url}))
{
Console.WriteLine("Blog: " + blogName.Url);
}
这样生成的sql比较短:
SELECT [b].[Id],[b].[Url]
FROM [Blogs] AS [b]
4.3 使用Take限制返回的条数
var blogs25 = context.Posts
.Where(p => p.Title.StartsWith("A"))
.Take(25)
.ToList();
4.4 使用拆分查询AsSplitQuery避免笛卡尔积爆炸
AsSplitQuery要配合Include使用,而且只对一对多的关系进行查询时才生效,多对一和一对一不会拆分。
4.5 使用Include进行预先加载
可以在一个sql中把关联的数据加载过来,避免生成多次sql查询
using (var context = new BloggingContext())
{
var filteredBlogs = context.Blogs
.Include(
blog => blog.Posts
.Where(post => post.BlogId == 1)
.OrderByDescending(post => post.Title)
.Take(5))
.ToList();
}
如果当前不需要关联实体的数据,可以考虑使用“显示加载”和“懒加载”。
4.6 注意“懒加载”产生的N+1问题
对于以下代码会生成4条sql,分来用来查询blog和查询三个blog对应的post。又被称为N+1问题
foreach (var blog in context.Blogs.ToList())
{
foreach (var post in blog.Posts)
{
Console.WriteLine($"Blog {blog.Url}, Post: {post.Title}");
}
}
可以优化为以下单个sql查询:
foreach (var blog in context.Blogs.Select(b => new { b.Url, b.Posts }).ToList())
{
foreach (var post in blog.Posts)
{
Console.WriteLine($"Blog {blog.Url}, Post: {post.Title}");
}
}
4.7 缓冲和流式处理
缓冲:将所有查询结果加载到内存里
流式:每次将结果集的一部分放到内存里,无论查询1条还是1万条,占用的内存空间都是固定的。当查询大量数据时考虑使用这种方式。
// ToList 和 ToArray 将导致缓冲
var blogsList = context.Posts.Where(p => p.Title.StartsWith("A")).ToList();
var blogsArray = context.Posts.Where(p => p.Title.StartsWith("A")).ToArray();
// 流式:一次只处理一行数据
foreach (var blog in context.Posts.Where(p => p.Title.StartsWith("A")))
{
// ...
}
// AsEnumerable 也属于流式
var doubleFilteredBlogs = context.Posts
.Where(p => p.Title.StartsWith("A")) // 服务端和数据库执行
.AsEnumerable()
.Where(p => SomeDotNetMethod(p)); // 这段代码将在客户端执行
4.8 efcore的内部缓冲
除了ToList和ToArray会进行缓冲外,当遇到以下两种情况时,efcore内部也会缓冲一些数据。
- 当重试策略准备就绪时。这是为了保证重试查询能够返回相同的结果。
- 当使用了拆分查询时,会缓冲除最后一个sql外其他的sql查询数据。除非sql server启用了MARS。
注意:如果你的重试策略里使用了ToList,那么就会缓冲两次。
4.9 使用AsNoTracking查询
当不关心查询出来的数据的状态时,就可以使用AsNoTracking提高效率。
4.10 直接执行sql
某些情况下你自己写的sql可能更优。
4.11 使用异步方法
尽量使用诸如SaveChangesAsync之类的异步方法。同步方法会在数据库IO期间阻塞线程,当其他请求进来时可能需要再次开辟新的线程,增加总的线程数和线程上线文切换次数。
4.12 实体上尽量使用[Required]特性
- 非null的比较比null的比较要快,所以尽量将实体的属性上填写
[Required]特性。 - 尽量检查是否相等(
==)避免检查不相等(!=)。因为==有时不用区分是否为null。 - 查询时显示指定某些属性不能为null,下面第二行代码要快于第一行:
var query1 = context.Entities.Where(e => e.String1 != e.String2 || e.String1.Length == e.String2.Length);
var query2 = context.Entities.Where(
e => e.String1 != null && e.String2 != null && (e.String1 != e.String2 || e.String1.Length == e.String2.Length));
5. 更新优化
5.1 批量处理(Batching)
var blog = context.Blogs.Single(b => b.Url == "http://someblog.microsoft.com");
blog.Url = "http://someotherblog.microsoft.com";
context.Add(new Blog { Url = "http://newblog1.microsoft.com" });
context.Add(new Blog { Url = "http://newblog2.microsoft.com" });
context.SaveChanges();
以上代码会产生4个sql往返:查询、更新、插入、插入。
info: 2021/5/31 17:49:19.507 RelationalEventId.CommandExecuted[20101] (Microsoft.EntityFrameworkCore.Database.Command)
Executed DbCommand (5ms) [Parameters=[], CommandType='Text', CommandTimeout='30']
SELECT TOP(2) [b].[Id], [b].[Name], [b].[Url]
FROM [Blogs] AS [b]
WHERE [b].[Name] = N'fish'
info: 2021/5/31 17:49:19.517 RelationalEventId.CommandExecuted[20101] (Microsoft.EntityFrameworkCore.Database.Command)
Executed DbCommand (1ms) [Parameters=[@p1='?' (DbType = Int64), @p0='?' (Size = 4000)], CommandType='Text', CommandTimeout='30']
SET NOCOUNT ON;
UPDATE [Blogs] SET [Url] = @p0
WHERE [Id] = @p1;
SELECT @@ROWCOUNT;
info: 2021/5/31 17:49:19.518 RelationalEventId.CommandExecuted[20101] (Microsoft.EntityFrameworkCore.Database.Command)
Executed DbCommand (0ms) [Parameters=[@p0='?' (Size = 4000), @p1='?' (Size = 4000)], CommandType='Text', CommandTimeout='30']
SET NOCOUNT ON;
INSERT INTO [Blogs] ([Name], [Url])
VALUES (@p0, @p1);
SELECT [Id]
FROM [Blogs]
WHERE @@ROWCOUNT = 1 AND [Id] = scope_identity();
info: 2021/5/31 17:49:19.520 RelationalEventId.CommandExecuted[20101] (Microsoft.EntityFrameworkCore.Database.Command)
Executed DbCommand (0ms) [Parameters=[@p0='?' (Size = 4000), @p1='?' (Size = 4000)], CommandType='Text', CommandTimeout='30']
SET NOCOUNT ON;
INSERT INTO [Blogs] ([Name], [Url])
VALUES (@p0, @p1);
SELECT [Id]
FROM [Blogs]
WHERE @@ROWCOUNT = 1 AND [Id] = scope_identity();
efcore是否将多个sql放到一个数据库往返里取决于所使用的数据库provider。例如,当涉及到4条以下或40条以上的语句时,对sql server进行批处理效率会比较低。所以efcore再默认情况下单个批处理中最多只会执行42条语句,然后在其他往返中执行其他语句。
当然你可以手动进行配置,当语句在1-100之间时就启用批处理:
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder.UseSqlServer(
@"Server=(localdb)\\mssqllocaldb;Database=Blogging;Integrated Security=True",
o => o
.MinBatchSize(1)
.MaxBatchSize(100));
}
配置完之后针对上述同一个操作,可以看到只有两次往返:
info: 2021/5/31 17:48:37.891 RelationalEventId.CommandExecuted[20101] (Microsoft.EntityFrameworkCore.Database.Command)
Executed DbCommand (4ms) [Parameters=[], CommandType='Text', CommandTimeout='30']
SELECT TOP(2) [b].[Id], [b].[Name], [b].[Url]
FROM [Blogs] AS [b]
WHERE [b].[Name] = N'fish'
info: 2021/5/31 17:48:37.909 RelationalEventId.CommandExecuted[20101] (Microsoft.EntityFrameworkCore.Database.Command)
Executed DbCommand (7ms) [Parameters=[@p1='?' (DbType = Int64), @p0='?' (Size = 4000), @p2='?' (Size = 4000), @p3='?' (Size = 4000), @p4='?' (Size = 4000), @p5='?' (Size = 4000)], CommandType='Text', CommandTimeout='30']
SET NOCOUNT ON;
UPDATE [Blogs] SET [Url] = @p0
WHERE [Id] = @p1;
SELECT @@ROWCOUNT;
DECLARE @inserted1 TABLE ([Id] bigint, [_Position] [int]);
MERGE [Blogs] USING (
VALUES (@p2, @p3, 0),
(@p4, @p5, 1)) AS i ([Name], [Url], _Position) ON 1=0
WHEN NOT MATCHED THEN
INSERT ([Name], [Url])
VALUES (i.[Name], i.[Url])
OUTPUT INSERTED.[Id], i._Position
INTO @inserted1;
SELECT [t].[Id] FROM [Blogs] t
INNER JOIN @inserted1 i ON ([t].[Id] = [i].[Id])
ORDER BY [i].[_Position];
5.2 大容量更新(Bulk Update)
以下代码
foreach(var p in context.Posts)
{
p.Content += "a";
}
context.SaveChanges();
产生了两次数据库往返,最后一次往返用来update数据:
info: 2021/5/31 17:44:32.068 RelationalEventId.CommandExecuted[20101] (Microsoft.EntityFrameworkCore.Database.Command)
Executed DbCommand (1ms) [Parameters=[], CommandType='Text', CommandTimeout='30']
SELECT [p].[Id], [p].[BlogId], [p].[Content], [p].[IsDeleted], [p].[Title]
FROM [Posts] AS [p]
info: 2021/5/31 17:44:32.098 RelationalEventId.CommandExecuted[20101] (Microsoft.EntityFrameworkCore.Database.Command)
Executed DbCommand (28ms) [Parameters=[@p1='?' (DbType = Int64), @p0='?' (Size = 4000), @p3='?' (DbType = Int64), @p2='?' (Size = 4000), @p5='?' (DbType = Int64), @p4='?' (Size = 4000), @p7='?' (DbType = Int64), @p6='?' (Size = 4000), @p9='?' (DbType = Int64), @p8='?' (Size = 4000), @p11='?' (DbType = Int64), @p10='?' (Size = 4000)], CommandType='Text', CommandTimeout='30']
SET NOCOUNT ON;
UPDATE [Posts] SET [Content] = @p0
WHERE [Id] = @p1;
SELECT @@ROWCOUNT;
UPDATE [Posts] SET [Content] = @p2
WHERE [Id] = @p3;
SELECT @@ROWCOUNT;
UPDATE [Posts] SET [Content] = @p4
WHERE [Id] = @p5;
SELECT @@ROWCOUNT;
UPDATE [Posts] SET [Content] = @p6
WHERE [Id] = @p7;
SELECT @@ROWCOUNT;
UPDATE [Posts] SET [Content] = @p8
WHERE [Id] = @p9;
SELECT @@ROWCOUNT;
UPDATE [Posts] SET [Content] = @p10
WHERE [Id] = @p11;
SELECT @@ROWCOUNT;
虽然efcore对最后一次往返进行了batching,但是还是不够完美。第一,查询了post的所有字段并进行了跟踪。第二,保存时需要与快照对比确定哪些属性改变了,并将这些改变生成sql。遗憾的是efcore现在还不支持大容量更新(Bulk Update),所以需要我们手动执行sql:
context.Database.ExecuteSqlRaw("UPDATE [Employees] SET [Salary] = [Salary] + 1000");
6. 其他优化性能的方式
6.1 使用DbContext池
ASP.NET Core的构造函数注入或Razor Pages的构造函数注入上下文,每次都是一个新实例。通过重复利用上下文,而不是为每个请求都创建上下文的实例,可以提高系统的吞吐量。通过AddDbContextPool启用上下文池:
services.AddDbContextPool<BloggingContext>(
options => options.UseSqlServer(connectionString));
当请求实例时,efcore先检查池子中有没有可用的实例。请求处理完成后,会重置实例的所有状态,然后放入池中。可以设置AddDbContextPool的poolSize参数来控制池子中最多可以由多少个实例。当超出poolSize后池子就不再缓存新的实例。
6.2 查询缓存与参数化查询
efcore会先将linq查询树“编译”为对应的sql语句。由于这个过程比较繁重,efcore会按照查询树的形状缓存查询:树结构相同的查询会重用内部缓存的编译结果。
考虑下述代码:
var post1 = context.Posts.FirstOrDefault(p => p.Title == "post1");
var post2 = context.Posts.FirstOrDefault(p => p.Title == "post2");
因为linq查询树包含不同的常量,所以查询树不一样。每一个查询都会被单独编译,然后生成以下细微差别的sql:
SELECT TOP(1) [b].[Id], [b].[Name]
FROM [Blogs] AS [b]
WHERE [b].[Name] = N'blog1'
SELECT TOP(1) [b].[Id], [b].[Name]
FROM [Blogs] AS [b]
WHERE [b].[Name] = N'blog2'
因为sql不相同,所以查询计划也不一样。
但是我们可以做以下优化:
var postTitle = "post1";
var post1 = context.Posts.FirstOrDefault(p => p.Title == postTitle);
postTitle = "post2";
var post2 = context.Posts.FirstOrDefault(p => p.Title == postTitle);
现在已经将常量参数化,所以两个查询树一样,并且efcore只需要编译一次。生成的sql也进行了参数化,允许数据库重复使用同一查询计划:
SELECT TOP(1) [b].[Id], [b].[Name]
FROM [Blogs] AS [b]
WHERE [b].[Name] = @__blogName_0
注意:没必要参数化每一个查询,使用常量进行查询也还是ok的。efcore会进行优化,详见下一章节。
EF Core的事件计数器报告查询缓存命中率。 在正常的应用程序中,在程序启动后,此计数器不久就会达到100%,一旦大多数查询执行至少一次。 如果此计数器的值低于100%,则表示应用程序可能正在执行与查询缓存不一致的操作.
数据库如何管理缓存查询计划依赖于数据库。 例如,SQL Server 隐式维护 LRU 查询计划缓存,而 PostgreSQL 不 (但已准备好的语句可能会产生非常类似的最终效果) 。 有关更多详细信息,请参阅数据库文档。
以上是关于Entity Framework Core 性能优化的主要内容,如果未能解决你的问题,请参考以下文章