Keras入门必读教程:手把手从安装到解决实际问题
Posted 大数据v
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Keras入门必读教程:手把手从安装到解决实际问题相关的知识,希望对你有一定的参考价值。
导读:Keras是目前深度学习研究领域非常流行的框架。
作者:史丹青
来源:大数据DT(ID:hzdashuju)

01 Keras简介与安装
Keras是目前深度学习研究领域非常流行的框架,相比于TensorFlow,Keras是一种更高层次的深度学习API。
Keras使用Python编写而成,包含了大量模块化的接口,有很多常用模型仅需几行代码即可完成,大大提高了深度学习的科研效率。它是一个高级接口,后端可支持TensorFlow、Theano、CNTK等多种深度学习基础框架,默认为TensorFlow,其他需要单独设置。
目前,谷歌已经将Keras库移植到TensorFlow中,也让Keras成了TensorFlow中的高级API模块。
Keras具备了三个核心特点:
允许研究人员快速搭建原型设计。
支持深度学习中最流行的卷积神经网络与循环神经网络,以及它们两者的组合。
可以在CPU与GPU上无缝运行。
Keras的口号是“为人类服务的深度学习”,在整体的设计上坚持对开发者友好,在API的设计上简单可读,将用户体验放在首位,希望研发人员可以以尽可能低的学习成本来投入深度学习的开发中。
Keras的API设计是模块化的,用户可以基于自己设想的模型对已有模块进行组装,其中如神经网络层、损失函数、优化器、激活函数等都可以作为模块组合成新的模型。与此同时,Keras的扩展性非常强大,用户可以轻松创建新模块用于科学研究。
目前最简单的引入Keras的方法就是直接使用最新版本的TensorFlow,可以通过以下引入方式在代码中使用Keras。
from tensorflow import keras此外,Keras具有一个非常活跃的开发者社区,每天都会有大量的开源代码贡献者为Keras提供各种各样的功能。其中Keras-contrib是一个官方的Keras社区扩展版本,包含了很多社区开发者提供的新功能,为Keras的用户提供了更多选择。
Keras-contrib的新功能通过审核后都会整合到Keras核心项目中,如果现在就想在项目中使用,需要单独安装,同样,可以使用pip工具直接安装。
$ sudo pip install git+https://www.github.com/keras-team/keras-contrib.git随着Karas加入TensorFlow,为了更好地进行代码上的整合,Keras-contrib项目被整合进了TensorFlow Addons。
TensorFlow Addons是一个针对TensorFlow核心库功能的补充,集成了社区最新的一系列方法。由于AI领域发展的速度快,一些最新的算法无法立刻移植到TensorFlow核心库中,所以会优先在TensorFlow Addons中进行发布。
可以使用pip的方式方便地安装TensorFlow Addons,从而使用一些高级的API接口。
$ pip install tensorflow-addons02 Keras使用入门
Keras包含两种模型类型,第一种是序列模型,第二种是函数式模型。其中后者属于Keras的进阶型模型结构,适用于多入多出、有向无环图或具备共享层的模型,具体可参考Keras官方文档。本节中主要通过介绍序列模型来带读者学习Keras的使用方法。
所谓序列模型是指多个网络层线性堆叠的模型,结构如下列代码所示,该序列模型包含了一个784×32的全连接层、ReLU激活函数、32×10的全连接层以及softmax激活函数。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
model = Sequential([
Dense(32, input_shape=(784,)),
Activation('relu'),
Dense(10),
Activation('softmax'),
])也可以使用add() 方法进行序列模型中网络层的添加。
model = Sequential()
model.add(Dense(32,input_dim=784))
model.add(Activation('relu'))下面我们来看一个用Keras实现的神经网络二分类示例,网络结构非常简单,由两个全连接层构成。示例中包含了网络模型的搭建、模型的编译以及训练,读者可以在自己的设备上尝试运行此代码以熟悉Keras的使用。
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
data = np.random.random((1000,100))
labels = np.random.randint(2,size=(1000,1))
model = Sequential()
model.add(Dense(32,activation='relu', input_dim=100))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['accuracy'])
model.fit(data,labels,epochs=10,batch_size=32)
predictions = model.predict(data)下面我们根据Keras官网的示例来尝试搭建一个类似VGG网络的卷积神经网络模型。首先引入需要使用的模块,其中包括Keras库中的全连接层、卷积层等。
import numpy as np
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.optimizers import SGD为了实现模型,我们需要先准备一些训练和测试数据,这里使用随机方法进行数据的准备。
x_train = np.random.random((100, 100, 100, 3))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)),
num_classes=10)
x_test = np.random.random((20, 100, 100, 3))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(20, 1)),
num_classes=10)整体上可以按照VGG的结构来搭建整个网络,包括叠加卷积层、池化层、Dropout层、Max Pooling层、全连接网络层等。
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(100, 100, 3)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))最后我们进行模型的优化设置以及对模型进行编译,并可以在训练数据上进行学习。
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd)
model.fit(x_train, y_train, batch_size=32, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=32)同样地,我们也可以使用Keras 的序列模型实现基于LSTM 的循环神经网络模型。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Embedding,LSTM
model = Sequential()
model.add(Embedding(20000,128))
model.add(LSTM(128,dropout=0.2,recurrent_dropout=0.2))
model.add(Dense(1,activation='sigmoid'))下面则是对于该循环神经网络模型的编译与训练,同时最终评估了训练模型的效果。
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=
['accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=15, verbose=1, validation_data=
(x_test,y_test))
score = model.evaluate(x_test, y_test, batch_size=32)最终我们可以将模型保存到本地的model文件夹路径下。
model.save('./model')当在业务中需要使用对应模型时,只需要使用加载模型的方法从model 路径中进行模型的加载即可。
from tensorflow.keras.models import load_model
my_model = load_model('./model')通过这几个示例我们会发现,使用Keras 来实现那些复杂的深度学习网络像是搭建积木一样,把一些非常复杂的工作简单化了。在下一节中,会通过一个简明的案例带领大家了解如何使用Keras解决实际的应用问题。
03 Keras实例:文本情感分析
本小节中我们通过学习Keras官方的一个实例来熟悉一下Keras的使用方法。
参考链接:
https://github.com/keras-team/keras/blob/master/examples/imdb_lstm.py
情感分析是自然语言处理领域的研究热点,也是一项非常实用的技术,可以利用这项技术来分析用户在互联网上的观点和态度,同时也可以分析企业或商品在互联网上的口碑。
在深度学习中,循环神经网络(RNN)是处理像文本这样的序列模型的最好方式,但传统的RNN存在的问题是,当序列变长后,RNN无法记住之前的重要信息,并且会存在梯度消失的问题。为了解决上述问题,研究者提出了一种长短期记忆网络(LSTM),这也是目前业内处理文本序列非常流行的一种模型(见图2-14)。
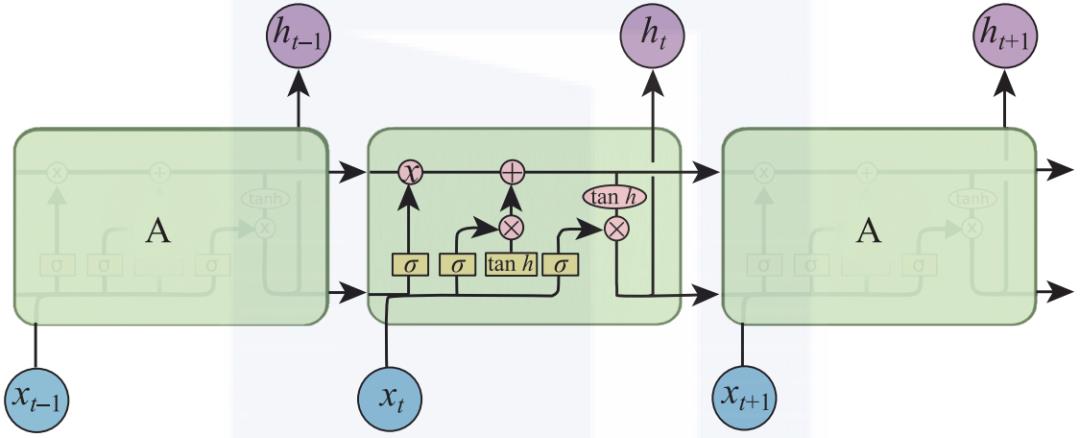
▲图2-14 LSTM网络结构示意图
Keras官方已经为大家准备好了LSTM模型的API,并且提供了IMDB电影评论数据集,其中包含了评论内容和打分。下面让我们来看如何使用Keras来解决情感分析的问题。首先引入所有需要的模块。
from __future__ import print_function
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, LSTM
from tensorflow.keras.datasets import imdb准备好数据,选择最常用的20000个词作为特征数据,并将数据分为训练集和测试集。对于文本数据,这里需要进行长度统一,设置最大长度为80个词,如果超过则截断,不足则补零。
max_features = 20000
maxlen = 80
batch_size = 32
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)数据处理完成后就可以搭建模型了。首先使用嵌入层作为模型的第一层,将输入的20000维的文字向量转换为128维的稠密向量。接着就是利用LSTM模型进行文本序列的深度学习训练。最终使用全连接层加上Sigmoid激活函数作为最终的判断输出。搭建完毕后还需要为模型设置编译的损失函数和优化器。
model = Sequential()
model.add(Embedding(max_features, 128))
model.add(LSTM(128, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',optimizer='adam',
metrics=['accuracy'])然后就可以训练和评估情感分析的模型了。在Keras帮助下,通过简单的几步就可以完成基于深度学习的文本情感分析的任务。
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=15,
validation_data=(x_test, y_test))
score, acc = model.evaluate(x_test, y_test,
batch_size=batch_size)
print('Test score:', score)
print('Test accuracy:', acc)在使用Keras框架训练完模型以后,可以通过Keras的save方法将模型保存下来。为了能够更好地让机器学习投入真实世界的应用中去,我们可以为模型封装一个外部的应用程序。在互联网时代,使用网络接入AI模型是对于用户来说成本最低的方式。
为此我们可以搭建一个基于Web的AI应用程序,将模型投入生产环境中为互联网用户提供即时的网页服务。
在Python中常用的Web编程框架是Flask,它是一个非常流行的Python服务端程序框架,相比于在Python领域非常流行的Django,它的特点在于更为精简,去除了一些封装好的服务,只保留了最基本的服务器程序,而其余的扩展可以通过用户自己添加第三方包实现。
关于作者:史丹青,语忆科技联合创始人兼技术负责人,毕业于同济大学电子信息工程系。拥有多年时间的AI领域创业与实战经验,具备深度学习、自然语言处理以及数据可视化等相关知识与技能。是AI技术的爱好者,并拥抱一切新兴科技,始终坚信技术分享和开源精神的力量。
本文摘编自《生成对抗网络入门指南》(第2版),经出版方授权发布。

延伸阅读《生成对抗网络入门指南》(第2版)
点击上图了解及购买
转载请联系微信:DoctorData
推荐语:揭秘AI如何生成逼真人脸图像,追踪GAN前沿技术更新。

划重点👇
干货直达👇
更多精彩👇
在公众号对话框输入以下关键词
查看更多优质内容!
读书 | 书单 | 干货 | 讲明白 | 神操作 | 手把手
大数据 | 云计算 | 数据库 | Python | 爬虫 | 可视化
AI | 人工智能 | 机器学习 | 深度学习 | NLP
5G | 中台 | 用户画像 | 数学 | 算法 | 数字孪生
据统计,99%的大咖都关注了这个公众号
👇
以上是关于Keras入门必读教程:手把手从安装到解决实际问题的主要内容,如果未能解决你的问题,请参考以下文章