7Redis持久化(RDBAOF)scan操作
Posted *King*
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了7Redis持久化(RDBAOF)scan操作相关的知识,希望对你有一定的参考价值。
Redis虽然是个内存数据库,但是Redis支持RDB和AOF两种持久化机制,将数据写住磁盘,可以有效避免因进程退出造成的数据丢失问题,当下次重启时利用之前持久化的文件即可实现数据恢复。
一、RDB
RDB持久化是把当前进程数据生成快照保存到硬盘的过程,触发RDB持久化过程分为手动触发和自动触发。
1、触发机制
手动触发
可以用save和bgsave命令
save命令:阻塞当前Redis服务器,直到RDB过程完成为止,对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用。
bgsave命令:Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。
bgsave命令是针对save阻塞问题做的优化,所以Redis内部所涉及RDB的操作都采用的是bgsave
自动触发
- 使用save相关配置,如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。
- 如果从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点
- 执行debug reload命令重新加载Redis时,也会自动触发save操作
- 默认情况下执行shutdown命令时,如果没有开启AOF持久化功能则自动执行bgsave
关闭RDB持久化:将配置文件中的save配置改为 save “”
2、bgsave执行过程
- 执行 bgsave 命令,Redis 父进程判断当前是否存在正在执行的子进程,如RDB/AOF 子进程,如果存在,bgsave 命令直接返回。
- 父进程执行 fork 操作创建子进程,fork 操作过程中父进程会阻塞,通过 info stats 命令查看 latest_fork_esec 选项,可以获取最近一个 fork 操作的耗时,单位为微秒。
- 父进程 fork 完成后,bgsave 命令返回“Background saving started”信息并不再阻塞父进程,可以继续响应其他命令。
- 子进程创建 RDB 文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换。执行 lastsave 命令可以获取最后一次生成 RDB 的时间,对应info 统计的 rdb_last_save_time 选项。
- 进程发送信号给父进程表示完成,父进程更新统计信息,具体见 info Persistence 下的 rdb_*相关选项。
3、RDB文件
RDB 文件保存在 dir 配置指定的目录下,文件名通过 dbfilename 配置指定。可以通过执行 config set dir {newDir}和 config set dbfilename (newFileName}运行期 动态执行,当下次运行时 RDB 文件会保存到新目录。
Redis 默认采用 LZF 算法对生成的 RDB 文件做压缩处理,压缩后的文件远远小于内存大小,默认开启,可以通过参数 config set rdbcompression { yes |no}动态修改。
如果 Redis 加载损坏的 RDB 文件时拒绝启动,并打印如下日志:
# Short read or 0OM loading DB. Unrecoverable error,aborting now.
这时可以使用 Redis 提供的 redis-check-dump 工具检测 RDB 文件并获取对应的错误报告。
4、RDB的优缺点
RDB的优点:
RDB 是一个紧凑压缩的二进制文件,代表 Redis 在某个时间点上的数据快照。非常适用于备份,全量复制等场景。
Redis 加载 RDB 恢复数据远远快于 AOF 的方式。
RDB的缺点:
RDB 方式数据没办法做到实时持久化/秒级持久化。因为 bgsave 每次运行都要执行 fork 操作创建子进程,属于重量级操作,频繁执行成本过高。
RDB 文件使用特定二进制格式保存Redis 版本演进过程中有多个格式的 RDB版本,存在老版本 Redis 服务无法兼容新版 RDB 格式的问题。
针对 RDB 不适合实时持久化的问题,Redis 提供了 AOF 持久化方式来解决。
二、AOF
AOF(append only file):以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中的命令达到恢复数据的目的。AOF主要作用是解决了数据持久化的实时性,目前已是Redis持久化的主流方式。
1、使用AOF
AOF默认是不开启,如需开启AOF则设置配置:appendonly yes,AOF文件名通过appendfilename 配置设置,默认文件名是 appendonly.aof。。保存路径同 RDB 持久化方式一致,通过 dir 配置指定。
2、AOF工作流程
AOF的工作流程操作:命令写入(append)—>文件同步(sync)—>文件重写(rewrite)—>重启加载(load)
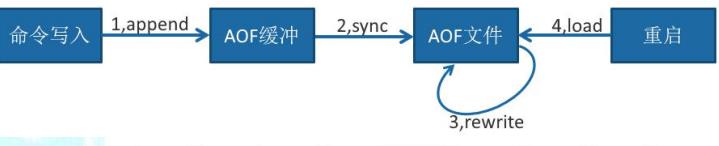
1)所有的写入命令会追加到 aof_buf(缓冲区)中。
2)AOF 缓冲区根据对应的策略向硬盘做同步操作
3)随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。
4)当 Redis 服务器重启时,可以加载 AOF 文件进行数据恢复。
Redis 提供了多种 AOF 缓冲区同步文件策略,由参数 appendfsync 控制:
- always:命令写人 aof_buf 后调用系统 fsync 操作同步到 AOF 文件,fsync 完成后线程返回命令 fsync 同步文件。(默认方式)
- everysec:写人 aof_buf 后调用系统 write 操作,write 完成后线程返回。操作由专门线程每秒调用一次 fsync 命令。
- no:写入 aof_buf 后调用系统 write 操作,不对 AOF 文件做 fsync 同步,同步硬盘操作由操作系统负责,通常同步周期最长 30 秒
3、重写机制
随着命令不断写入 AOF,文件会越来越大,为了解决这个问题,Redis 引入AOF 重写机制压缩文件体积。AOF 文件重写是把 Redis 进程内的数据转化为写命令同步到新 AOF 文件的过程。
重写后的 AOF 文件为什么可以变小:
- 进程内已经超时的数据不再写入文件。
- 旧的 AOF 文件含有无效命令,如 set a 111、set a 222 等。重写使用进程内数据直接生成,这样新的 AOF 文件只保留最终数据的写入命令。
- 多条写命令可以合并为一个,如:lpush list a、lpush list b、lpush listc 可以转化为: lpush list a b c。为了防止单条命令过大造成客户端缓冲区溢出,对于 list、set、hash、zset 等类型操作,以 64 个元素为界拆分为多条
AOF 重写降低了文件占用空间,除此之外,另一个目的是:更小的 AOF 文件可以更快地被 Redis 加载。
AOF重写可以手动触发和自动触发:
手动触发:直接调用 bgrewriteaof 命令。
自动触发:根据 auto-aof-rewrite-min-size 和 auto-aof-rewrite-percentage 参数确定自动触发时机。
- auto-aof-rewrite-min-size:表示运行 AOF 重写时文件最小体积,默认为 64MB。
- auto-aof-rewrite-percentage:代表当前 AOF 文件空间(aof_currentsize)和上一次重写后 AOF 文件空间(aof_base_size)的比值。
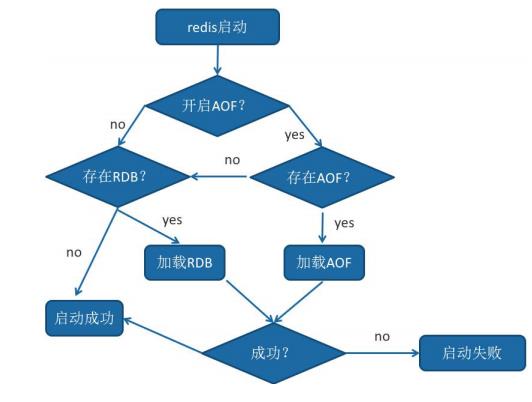
4、重启加载
AOF 和 RDB 文件都可以用于服务器重启时的数据恢复。redis 重启时加载AOF 与 RDB 的顺序是怎样的:
- 当AOF和RDB文件同时存在时,优先加载AOF
- 若关闭了AOF,加载RDB文件
- 加载AOF/RDB成功,redis重启成功
- AOF/RDB存在错误,启动失败打印错误信息
5、文件校验
加载损坏的 AOF 文件时会拒绝启动,对于错误格式的 AOF 文件,先进行备份,然后采用 redis-check-aof --fix 命令进行修复,对比数据的差异,找出丢失的数据,有些可以人工修改补全。
AOF 文件可能存在结尾不完整的情况,比如机器突然掉电导致 AOF 尾部文件命令写入不全。Redis 为我们提供了 aof-load-truncated 配置来兼容这种情况,默认开启。加载 AOF 时当遇到此问题时会忽略并继续启动
三、scan
keys命令执行时会遍历所有键,可能会带来阻塞问题,而scan采用渐进式遍历的方式,每次只扫描字典中的一部分键。
scan cursor [match pattern] [count number]
- cursor 是必需参数,实际上 cursor 是一个游标,第一次遍历从 0 开始,每次scan 遍历完都会返回当前游标的值,直到游标值为 0,表示遍历结束。
- Match pattern是可选参数,它的作用的是做模式的匹配,这点和keys的模式匹配很像。
- Count number 是可选参数,它的作用是表明每次要遍历的键个数,默认值是10,此参数可以适当增大。
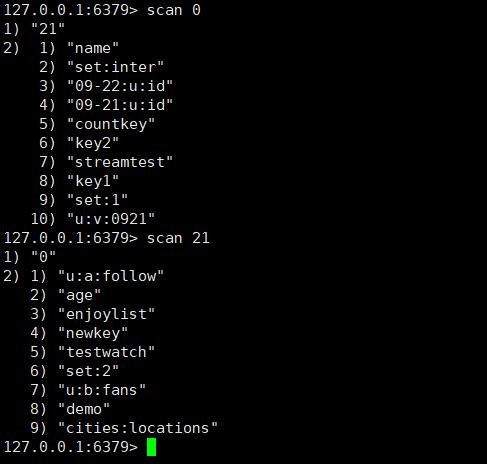
得到结果 cursor 变为 0,说明所有的键已经被遍历过了。
除了 scan 以外,Redis 提供了面向哈希类型、集合类型、有序集合的扫描遍历命令,解决诸如 hgetall、smembers、zrange 可能产生的阻塞问题,对应的命令分别是 hscan、sscan、zscan,它们的用法和 scan 基本类似。
渐进式遍历可以有效的解决 keys 命令可能产生的阻塞问题,但是 scan 并非完美无瑕,如果在 scan 的过程中如果有键的变化(增加、删除、修改),那么遍历效果可能会碰到如下问题:新增的键可能没有遍历到,遍历出了重复的键等情况,也就是说 scan 并不能保证完整的遍历出来所有的键。
以上是关于7Redis持久化(RDBAOF)scan操作的主要内容,如果未能解决你的问题,请参考以下文章