Batch Normalization在联邦学习中的应用
Posted LeoJarvis
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Batch Normalization在联邦学习中的应用相关的知识,希望对你有一定的参考价值。
回想一下联邦学习(FL)中的FedAvg,这个算法是将每个参与方的模型的所有参数进行加权平均聚合,包括Batch Normalization(BN)的参数。
再回顾一下BN。式中µ和
σ
2
σ^2
σ2为BN统计量,是通过每个channel的空间和批次维度计算而得的running mean和running variances。γ和β为实现"变换重构"的超参数。ε用于预防分母为零。
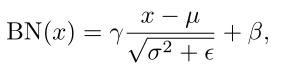
我们知道FL的一个重要意义就在于保护参与方的数据隐私,而BN层的统计参数µ和
σ
2
σ^2
σ2实际上在一定程度上隐含着本地数据的统计信息,所以把这些参数用于聚合会对数据隐私造成一定威胁,并且影响全局模型的收敛性和精度。
对于这个问题,目前我看到的主要有两种方法:
- 一种方法来自于ICLR 2021上的一篇文章:《FedBN: Federated Learning on Non-IID Features via Local Batch Normalization》,适用于feature shift的情况。思想是直接把BN层的所有参数保留在本地,而把其他层的参数用于全局聚合,待服务端返回全局模型后,再与本地的BN参数结合构成本地模型,这在保护数据隐私的同时也实现了模型个性化设计。具体的实验效果在我之前的这篇博客有做过总结:FedBN总结
- 另一种方法来自于Springer 2020上的一篇文章《Siloed Federated Learning for Multi-centric Histopathology Datasets》。思想是把BN的统计参数µ和 σ 2 σ^2 σ2保留在本地,把BN的超参数γ和β以及其他层的参数用于全局聚合,待服务端返回全局模型后,再与本地的BN参数结合构成本地模型,这同样实现了隐私保护和模型个性化设计。
以上是关于Batch Normalization在联邦学习中的应用的主要内容,如果未能解决你的问题,请参考以下文章