联邦学习如何训练用户识别模型?
Posted LeoJarvis
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了联邦学习如何训练用户识别模型?相关的知识,希望对你有一定的参考价值。
“用户识别模型”也就是训练一个通过语音,或人脸,或指纹等个人信息进行身份识别的模型,也是一个选择“接受”或”拒绝”的二元决策问题。以基于embedding的分类为例,一个样本只有其embedding与reference embedding足够接近,才能通过模型验证(被模型接受),换句话说就是“身份验证成功”。
联邦学习训练“用户识别模型”存在两个挑战:
- 每个参与方只有一个用户的信息作为训练数据,也就是说所有数据都属于同一个类标签(用户自身)
- 采用embeddind vector表征用户身份信息,由于涉及用户隐私,每个参与方的embeddind vector都不能与他人进行共享。
损失函数的一般定义:
w
y
∈
R
n
d
w_y∈R^{n_d}
wy∈Rnd是类y的embedding,
g
θ
:
X
→
R
n
d
g_θ: X → R^{n_d}
gθ:X→Rnd是一个将输入x由X维空间映射至
n
d
n_d
nd维的embedding的网络,该embedding用
g
θ
(
x
)
g_θ(x)
gθ(x)表示。d为距离函数,模型基于(x,y)进行训练,则有
y
=
a
r
g
m
i
n
u
d
(
g
θ
(
x
)
,
w
u
)
y = argmin_u\\ d (g_θ(x), w_u)
y=argminu d(gθ(x),wu),该式等价于
d
(
g
θ
(
x
)
,
w
y
)
d (g_θ(x), w_y)
d(gθ(x),wy) <
m
i
n
u
≠
y
min_{u≠y}
minu=yd(
g
θ
(
x
)
,
w
u
g_θ(x), w_u
gθ(x),wu) 。因此损失函数可以定义如下:
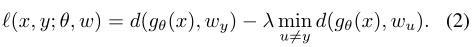
最小化式(2)中的损失函数分为两项,分别为positive loss和negative loss,positive loss decreases the distance of the instance embedding to the true class embedding and negative loss increases the distance to the embeddings of other classes.
并且文章【1】表明 negative loss term is needed to ensure that the training does not lead to a trivial solution that all inputs and classes collapse to a single point in the embedding space
方法1:Federated Averaging with Spreadout (FedAwS)
基于式(2)的损失函数,文章【2】基于FedAvg,提出服务端除了聚合梯度外,还要进行一个优化,以保证每个用户的embedding都要与其他用户的embedding保持一定距离v。公式化来看也就是在每轮训练中,服务端需要执行下述几何正则化:
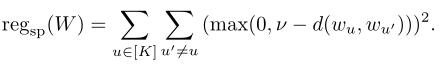
FedAwS可以使每个用户不需要与其他用户共享其embedding vector,但仍然需要与服务器进行共享,这在实际应用中其实还是不现实的。
方法2: Federated User Verification (FedUV)
其实如果要基于式(2)的损失函数进行模型训练的话,就不可避免地需要用户贡献其embedding来计算negative loss,换言之如果不用计算negative loss,不就不需要用户贡献其embedding了吗?而文章【1】又证明了negative loss是不可或缺的,那还有其他办法吗?答案是肯定的!
文章【3】证明,在满足所需条件的情况下,negative loss是可以舍弃的,并且在多轮训练后,without negative loss的模型精度与with negative loss的模型相当。
1、首先说说FedUV的损失函数以及基于什么条件能舍弃negative loss
首先修改式(2)的损失函数为:
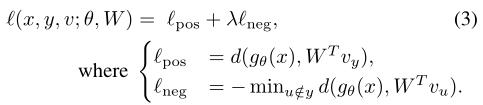
令
S
u
=
W
T
v
u
S_u = W^Tv_u
Su=WTvu为用户u的secret embedding,这里用户仍然需要获得其他用户的secret vector:
v
u
v_u
vu或secret embedding:
S
u
S_u
Su才能计算损失函数。
接下来定义positive loss和negative loss如下,其中positive loss最大化instance embedding和true secret embedding的关系,negative loss最小化instance embedding与其他用户的secret embedding的关系。
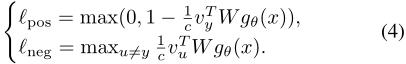
接下来是舍弃negative loss的条件及其证明过程,相对比较简单,我就直接贴上来了。不想看可以直接跳过,不影响。
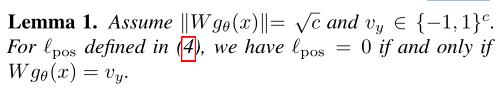

简单说就是当满足①
∣
∣
W
g
θ
(
x
)
∣
∣
=
c
1
/
2
||Wg_θ(x)|| = c^{1/2}
∣∣Wgθ(x)∣∣=c1/2、② secret vectors选自ECC codewords(Error-Correcting Codes)时,negative loss就成了冗余项,可以舍弃。且当positive loss较小时,舍弃negative loss与否,模型精度都不受影响。
2、如何训练
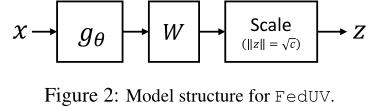
训练过程如图二所示,模型基于FedAvg进行训练,损失函数为
l
p
o
s
=
m
a
x
(
0
,
1
−
(
1
/
c
)
v
y
T
σ
(
W
g
θ
(
x
)
)
)
l_{pos} = max(0,1 - (1/c)v_y^Tσ(Wg_θ(x)))
lpos=max(0,1−(1/c)vyTσ(Wgθ(x))),其中σ是将输入规范化至模为√c的函数。
3、如何验证
完成训练后,每个用户可以基于本地模型进行用户验证(识别)。对于输入x‘,验证过程为:
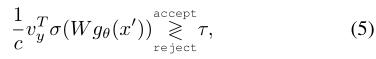
其中τ是一阈值。阈值是由每个用户独立确定的,以便其True Positive Rate(TPR)大于某个值,比如q = 90%。TPR被定义为用户被正确验证的比率。
τ具体怎么设置呢?在warm-up阶段(见伪代码),对于n个输入样本
x
j
x_j
xj’,j∈[n],它们的loss通过
(
1
/
c
)
v
y
T
σ
(
W
g
θ
(
x
j
′
)
)
)
(1/c)v_y^Tσ(Wg_θ(x_j')))
(1/c)vyTσ(Wgθ(xj′)))进行计算,接着根据期望通过验证的样本比例设置阈值。
4、综上,FedUV的伪代码如下

参考文献
【1】Bojanowski, P . and Joulin, A. Unsupervised learning by predicting noise. In International Conference on Machine Learning, 2017.
【2】Y u, F. X., Rawat, A. S., Menon, A. K., and Kumar, S. Federated learning with only positive labels. In International Conference on Machine Learning, 2020.
【3】Hosseini H , Park H , Yun S , et al. Federated Learning of User Verification Models Without Sharing Embeddings[J]. 2021.
以上是关于联邦学习如何训练用户识别模型?的主要内容,如果未能解决你的问题,请参考以下文章