Python初学者必须吃透的 69 个内置函数
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python初学者必须吃透的 69 个内置函数相关的知识,希望对你有一定的参考价值。
所谓内置函数,就是Python提供的, 可以直接拿来直接用的函数,比如大家熟悉的print,range、input等,也有不是很熟,但是很重要的,如enumerate、zip、join等,Python内置的这些函数非常精巧且强大的.
对初学者来说,经常会忽略,但是偶尔会碰到,我也是用了一段时间python之后才发现,哇还有这么好的函数,每个函数都非常经典,而且经过严格测试,使用内置函数,不用自己闭门造车,并且代码简洁易读了很多,真是方便又实用,值得花时间进行体系化研究学习。喜欢技术交流的小伙伴,文末提供技术交流群
初学者的代码之所以写的不简洁,不是因为学的不够好,而是学的不够多,很多内置的东西都没学透。(初学者一定要买一本基础书籍了解语言的基本框架,推荐下面这一本,当然其他任何的书都可以)
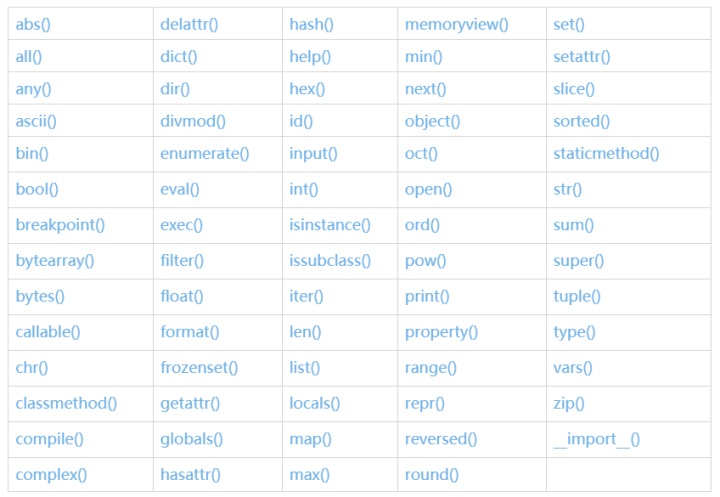
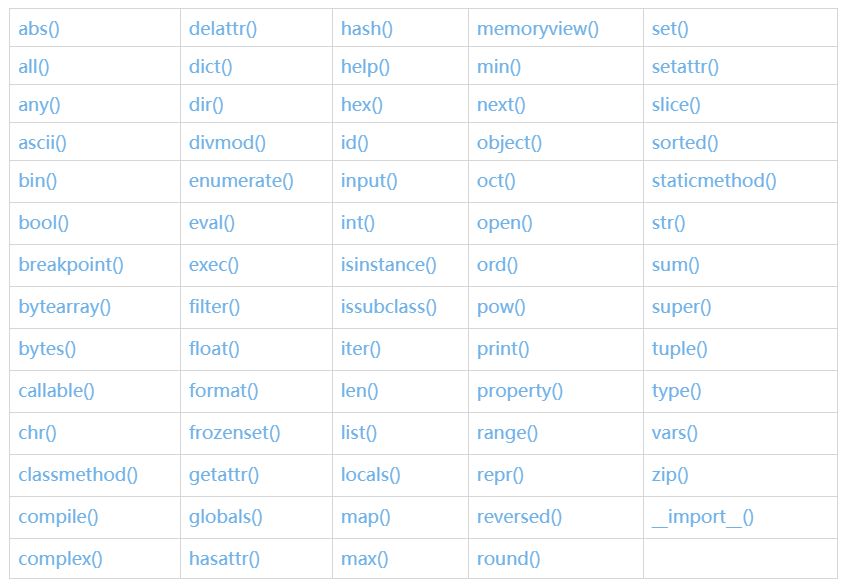
一、数字相关
01 数据类型
bool()
描述:测试一个对象是True, 还是False.bool 是 int 的子类。
语法:class bool([x])
参数:x – 要进行转换的参数。
案例:
bool([0,0,0])
True
bool([])
False
issubclass(bool, int) # bool 是 int 子类
True
int()
**描述:**int() 函数用于将一个字符串或数字转换为整型。 x可能为字符串或数值,将x 转换为一个普通整数。如果参数是字符串,那么它可能包含符号和小数点。如果超出了普通整数的表示范围,一个长整数被返回。
**语法:**int(x, base =10)
参数:
- x – 字符串或数字。
- base – 进制数,默认十进制。
案例:
int('12',16)
18
int('12',10)
12
float()
描述:将一个字符串或整数转换为浮点数
语法:class float([x])
参数:x – 整数或字符串
案例:
float(3)
3.0
float('123')
123.0
complex()
描述:创建一个复数
语法:class complex([real[, imag]])
参数:
real – int, long, float或字符串;
imag – int, long, float;
案例:
complex(1,2)
(1+2j)
complex('1')
(1+0j)
complex("1+2j")
(1+2j)
02 进制转换
bin()
描述:bin() 返回一个整数 int 或者长整数 long int 的二进制表示。将十进制转换为二进制
语法:bin(x)
参数:x – int 或者 long int 数字
案例:
bin(2)
'0b10'
bin(20)
'0b10100'
oct()
**描述:**将十进制转换为八进制 otc() 将给的参数转换成八进制
**语法:**oct(x)
**参数:**x – 整数。
案例:
oct(8)
'0o10'
oct(43)
'0o53'
hex()
描述:hex() 函数用于将10进制整数转换成16进制,以字符串形式表示。
**语法:**hex(x)
**参数:**x – 10进制整数。
案例:
将十进制转换为十六进制
hex(43)
'0x2b'#43等于2B
hex(15)
'0xf'
03 数学运算
abs()
**描述:**返回数字绝对值或复数的模
**语法:**abs( x )
**参数:**x 数值表达式。
案例:
abs(-6)
6
abs(5j+4)
6.4031242374328485
divmod()
**描述:**divmod() 函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。
**语法:**divmod(a, b)
**参数:**a: 数字–被除数
b: 数字–除数
案例:
divmod(11,3)
(3, 2)
divmod(20,4)
(5, 0)
round()
**描述:**round() 函数返回浮点数x的四舍五入值。
**语法:**round( x [, n] )
参数:
- x – 数值表达式。
- n --代表小数点后保留几位
案例:
round(10.0222222, 3)
10.022
pow()
描述:pow(x,y) 方法返回x的y次方的值,等价于x**y。函数是计算x的y次方,如果z在存在,则再对结果进行取模,其结果等效于pow(x,y) %z
**语法:**pow(x, y[, z])
参数:
- x – 数值表达式。
- y – 数值表达式。
- z – 数值表达式。
案例:
pow(10, 2)
100
10**2
100
pow(4,3,5)
4
等价于4**3%
sum()
**描述:**sum() 方法对系列进行求和计算。
**语法:**sum(iterable[, start])
参数:
- iterable – 可迭代对象,如:列表、元组、集合。
- start – 指定相加的参数,如果没有设置这个值,默认为0。
案例:
a = [1,4,2,3,1]
sum(a)
11
sum(a,10) #求和的初始值为10
21
min()
**描述:**min() 方法返回给定参数的最小值,参数可以为序列。
**语法:**min( x, y, z, … )
参数:
- x – 数值表达式。
- y – 数值表达式。
- z – 数值表达式。
案例:
min(80, 100, 1000)
80
min([80, 100, 1000])
80
max()
**描述:**max() 方法返回给定参数的最大值,参数可以为序列。
**语法:**max( x, y, z, … )
参数:
- x – 数值表达式。
- y – 数值表达式。
- z – 数值表达式。
案例:
最大值:
max(3,1,4,2,1)
4
di = {'a':3,'b1':1,'c':4}
max(di)
'c'
二、数据结构相关
01 序列数据类型
1)列表和元组
list()
**描述:**list() 函数创建列表或者用于将序列转换为列表。
**语法:**list( iterable )
**参数:**iterable – 可迭代序列。
案例:
序列为元组时
s=(123, 'xyz', 'zara', 'abc')
list(S)
[123, 'xyz', 'zara', 'abc']
序列为字符串
s= '小伍哥真是帅,特别帅'
list(s)
['小', '伍', '哥', '真', '是', '帅', ',', '特', '别', '帅']
序列为字典
s = {'nanme':'小伍哥','age':30,'address':'Hangzhou'}
list(s)
['nanme', 'age', 'address']
tuple()
描述: 元组 tuple() 函数将列表转换为元组。
**语法:**tuple( iterable )
**参数:**iterable – 要转换为元组的可迭代序列。
案例:
tuple([1,2,3,4])
(1, 2, 3, 4)
tuple({'a':2,'b':4}) #针对字典 会返回字典的key组成的tuple
('a', 'b')
tuple('小伍哥真是帅,特别帅')
('小', '伍', '哥', '真', '是', '帅', ',', '特', '别', '帅')
2)集合数据类型
dict()
**描述:**创建数据字典
语法:
class dict(**kwarg)
class dict(mapping, **kwarg)
class dict(iterable, **kwarg)
参数:
- **kwargs – 关键字
- mapping – 元素的容器。
- iterable – 可迭代对象。
案例:
#创建空字典
dict()
{}
#传入关键字
dict(a='a', b='b', t='t')
{'a': 'a', 'b': 'b', 't': 't'}
# 映射函数方式来构造字典
dict(zip(['one', 'two', 'three'], [1, 2, 3]))
{'three': 3, 'two': 2, 'one': 1}
#可迭代对象方式来构造字典
dict([('one', 1), ('two', 2), ('three', 3)])
{'three': 3, 'two': 2, 'one':
set()
**描述:**set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。
**语法:**class set([iterable])
**参数:**iterable – 可迭代对象对象;
案例:
#返回一个set对象,可实现去重:
a = [1,4,2,3,1]
set(a)
{1, 2, 3, 4}
frozenset()
**描述:**frozenset() 返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。
**语法:**class frozenset([iterable])
**参数:**iterable – 可迭代的对象,比如列表、字典、元组等等。
案例:
创建一个不可修改的集合。
frozenset([1,1,3,2,3])
frozenset({1, 2, 3})
3)字符串
str()
**描述:**str() 函数将对象转化为适于人阅读的形式。将字符类型、数值类型等转换为字符串类型
**语法:**class str(object=’’)
**参数:**object – 对象。
案例:
integ = 100
str(integ)
'100'
dict = {'baidu': 'baidu.com', 'google': 'google.com'};
str(dict)
"{'baidu': 'baidu.com', 'google': 'google.com'}"
format()
**描述:**Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。基本语法是通过 {} 和 : 来代替以前的 % 。使用format()来格式化字符串时,使用在字符串中使用{}作为占位符,占位符的内容将引用format()中的参数进行替换。可以是位置参数、命名参数或者兼而有之。
format 函数可以接受不限个参数,位置可以不按顺序。
**语法:**format(value, format_spec)
参数:
案例:
# 位置参数
'{}:您{}购买的{}到了!请下楼取快递。'.format('快递小哥','淘宝','快递')
'快递小哥:您淘宝购买的快递到了!请下楼取快递。'
#给批量客户发短息
n_list=['马云','马化腾','麻子','小红','李彦宏','二狗子']
for name in n_list:
print('{0}:您淘宝购买的快递到了!请下楼取快递!'.format(name))
马云:您淘宝购买的快递到了!请下楼取快递!
马化腾:您淘宝购买的快递到了!请下楼取快递!
麻子:您淘宝购买的快递到了!请下楼取快递!
小红:您淘宝购买的快递到了!请下楼取快递!
李彦宏:您淘宝购买的快递到了!请下楼取快递!
二狗子:您淘宝购买的快递到了!请下楼取快递!
#名字进行填充
for n in n_list:
print('{0}:您淘宝购买的快递到了!请下楼取快递!'.format(n.center(3,'*')))
*马云:您淘宝购买的快递到了!请下楼取快递!
马化腾:您淘宝购买的快递到了!请下楼取快递!
*麻子:您淘宝购买的快递到了!请下楼取快递!
*小红:您淘宝购买的快递到了!请下楼取快递!
李彦宏:您淘宝购买的快递到了!请下楼取快递!
二狗子:您淘宝购买的快递到了!请下楼取快递!
'{0}, {1} and {2}'.format('gao','fu','shuai')
'gao, fu and shuai'
x=3
y=5
'{0}+{1}={2}'.format(x,y,x+y)
# 命名参数
'{name1}, {name2} and {name3}'.format(name1='gao', name2='fu', name3='shuai')
'gao, fu and shuai'
# 混合位置参数、命名参数
'{name1}, {0} and {name3}'.format("shuai", name1='fu', name3='gao')
'fu, shuai and gao'
#for循环进行批量处理
["vec_{0}".format(i) for i in range(0,5)]
['vec_0', 'vec_1', 'vec_2', 'vec_3', 'vec_4']
['f_{}'.format(r) for r in list('abcde')]
['f_a', 'f_b', 'f_c', 'f_d',
bytes()
**描述:**将一个字符串转换成字节类型
**语法:**class bytes([source[, encoding[, errors]]])
参数:
- 如果 source 为整数,则返回一个长度为 source 的初始化数组;
- 如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
- 如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
- 如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
- 如果没有输入任何参数,默认就是初始化数组为0个元素。
案例:
s = "apple"
bytes(s,encoding='utf-8')
b'apple'
bytes([1,2,3,4])
b'\\x01\\x02\\x03\\x04'
bytearray()
**描述:**返回一个新字节数组. 这个数字的元素是可变的, 并且每个元素的值得范围是[0,256)
**语法:**class bytearray([source[, encoding[, errors]]])
参数:
- 如果 source 为整数,则返回一个长度为 source 的初始化数组;
- 如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
- 如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
- 如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
- 如果没有输入任何参数,默认就是初始化数组为0个元素。
bytearray()
bytearray(b'')
bytearray([1,2,3])
bytearray(b'\\x01\\x02\\x03')
bytearray('baidu', 'utf-8')
bytearray(b'baidu')
ord()
**描述:**查看某个ascii对应的十进制数
**语法:**ord©
**参数:**c – 字符。
案例:
ord('A')
65
ord('~')
126
chr()
**描述:**chr() 用一个范围在 range(256)内的(就是0~255)整数作参数,返回一个对应的字符。
**语法:**chr(i)
**参数:**i – 可以是10进制也可以是16进制的形式的数字。
案例:
查看十进制整数对应的ASCII字符
chr(65)
'A'
可以参考4案例中的表
ascii()
**描述:**ascii() 函数返回任何对象(字符串,元组,列表等)的可读版本。
ascii() 函数会将所有非 ascii 字符替换为转义字符:
å 将替换为 \\xe5。
**语法:**ascii(object)
**参数:**object–对象,可以是元组、列表、字典、字符串、set()创建的集合。
案例:
ascii('中国')
"'\\\\u4e2d\\\\u56fd'"
ascii('新冠肺炎')
"'\\\\u65b0\\\\u51a0\\\\u80ba\\\\u
ascii("My name is Ståle")
"'My name is St\\\\xe5le'"
print(ascii((1,2))) #元组
(1, 2)
print(type(ascii((1,2))))
<class 'str'>
print(ascii([1,2])) #列表
[1, 2]
print(type(ascii([1,2])))
<class 'str'>
print(ascii('?')) #字符串,非 ASCII字符,转义
'\\uff1f'
print(type(ascii("?")))
<class 'str'>
print(ascii({1:2,'name':5})) #字典
{1: 2, 'name': 5}
print(type(ascii({1:2,'name':5})))
<class '
ASCII码表具体如下所示(节选)
| Bin(二进制) | Oct(八进制) | Dec(十进制) | Hex(十六进制) | 缩写/字符 | 解释 |
| 0000 0000 | 00 | 0 | 0x00 | NUL(null) | 空字符 |
| 0010 0001 | 041 | 33 | 0x21 | ! | 叹号 |
| 0010 0010 | 042 | 34 | 0x22 | " | 双引号 |
| 0010 1010 | 052 | 42 | 0x2A | * | 星号 |
| ... | ... | ... | ... | ... | ... |
| 0111 1101 | 0175 | 125 | 0x7D | } | 闭花括号 |
| 0111 1110 | 0176 | 126 | 0x7E | ~ | 波浪号 |
| 0111 1111 | 0177 | 127 | 0x7F | DEL (delete) | 删除 |
repr()
返回一个对象的string形式
03 数据结构处理相关函数
len()
**描述:**len() 函数返回对象(字符、列表、元组等)长度或项目个数。
**语法:**len(s)
**参数:**s – 对象。
案例:
#字典的长度
dic = {'a':1,'b':3}
len(dic)
2
#字符串长度
s='aasdf'
len(s)
5
#列表元素个数
l = [1,2,3,4,5]
len(l)
sorted()
**描述:**sorted()函数对所有可迭代的对象进行排序操作。
**语法:**sorted(iterable, key=None, reverse=False)
参数:
- iterable–可迭代对象。
- key–主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse – 排序规则,reverse=True降序 ,reverse = False升序(默认)。
案例:
a = [5,7,6,3,4,1,2]
b = sorted(a) #保留原列表
a
[5, 7, 6, 3, 4, 1, 2]
b
[1, 2, 3, 4, 5, 6, 7]
#利用key
L=[('b',2),('a',1),('c',3),('d',4)]
sorted(L, key=lambda x:x[1])
[('a', 1), ('b', 2), ('c', 3), ('d', 4)]
#按年龄排序
students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
sorted(students, key=lambda s: s[2])
[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
#按降序
sorted(students, key以上是关于Python初学者必须吃透的 69 个内置函数的主要内容,如果未能解决你的问题,请参考以下文章