大数据运维 大数据平台运维总结
Posted 脚丫先生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据运维 大数据平台运维总结相关的知识,希望对你有一定的参考价值。
大家好,我是脚丫先生 (o^^o)
目前自己在运维方面,主要管理着CDH平台和HDP平台,同时负责着以docker的形式进行产品的交付。
文章目录
- 0、CDH集群配置、日志、jar包以及安装目录和常用命令汇总
- 1、namenode出现missing blocks
- 2、Spark on Yarn 查看任务日志及状态
- 3、安装hive报错:
- 4、CDH初始化scm_prepare_database.sh数据库遇到的问题
- 5、CM定期报"查询 Service Monitor 时发生内部错误"解决办法
- 6 文件系统检查点已有 1 天,14 小时,36 分钟。占配置检查点期限 1 小时的 3,860.33%。 临界阈值:400.00%。 自上个文件系统检查点以来已发生 14,632 个事务。
- 7 cdh6 存在隐患 : 主机网络接口似乎以全速运行
- 8 当安装agent的时候出现信号不法响应
- 9 CDH 集群,出现 Entropy 不良问题,原因是系统熵值低于 CDH 检测的阀值引起的。
- 9 FileNotFoundException: ...3.0.0-cdh6.0.0-mr-framework.tar.gz(hive执行聚合函数出现的问题)
- 10 cdh6.2中datanode无法启动问题
- 11 启动spark时,有可能提示Log directory specified does not exist:
- 12、安装失败。 无法接收 Agent 发出的检测信号。&& Dependency failed for Cloudera Manager Agent Service.
- 13、CDH集群的hive采用local模式测试
- 14、CDH集群的Cloudera Manager 节点 ,迁移Cloudera Scm Server端
0、CDH集群配置、日志、jar包以及安装目录和常用命令汇总
0.1 关键目录
(1)开启应用目录:默认可以直接敲命令行
/opt/cloudera/parcels/CDH/bin
查询
# ls
avro-tools kite-dataset sqoop-create-hive-table
beeline kudu sqoop-eval
bigtop-detect-javahome llama sqoop-export
catalogd llamaadmin sqoop-help
cli_mt load_gen sqoop-import
cli_st mahout sqoop-import-all-tables
flume-ng mapred sqoop-job
hadoop oozie sqoop-list-databases
hadoop-0.20 oozie-setup sqoop-list-tables
hadoop-fuse-dfs parquet-tools sqoop-merge
hadoop-fuse-dfs.orig pig sqoop-metastore
hbase pyspark sqoop-version
hbase-indexer sentry statestored
hbase-indexer-sentry solrctl whirr
hcat spark-shell yarn
hdfs spark-submit zookeeper-client
hive sqoop zookeeper-server
hiveserver2 sqoop2 zookeeper-server-cleanup
impala-collect-minidumps sqoop2-server zookeeper-server-initialize
impalad sqoop2-tool
impala-shell sqoop-codegen
(2)日志目录
/var/log/下面有对应节点所开启服务的日志
其中
cloudera-scm-agent CDH客户端日志
cloudera-scm-server CDH服务端日志
hadoop-hdfs hadoop日志目录
hadoop-mapreduce
hadoop-yarn
hbase hbase日志目录
hive hive日志目录
zookeeper zookeeper日志目录
(3)配置文件目录
- 各个部件配置
/etc/cloudera-scm-agent/config.ini cm agent的配置目录
/etc/cloudera-scm-server/ cm server的配置目录
/etc/hadoop/conf Hadoop各个组件的配置
/etc/hive/conf hive配置文件目录
/etc/hbase/conf hbase配置文件目录
/opt/cloudera/parcels/CDH/etc是hadoop集群以及组件的配置文件文件夹
- 服务运行时所有组件的配置文件目录
/var/run/cloudera-scm-agent/process/
查看内容
# ls
244-hdfs-NAMENODE
245-hdfs-SECONDARYNAMENODE
246-hdfs-NAMENODE-nnRpcWait
247-zookeeper-server
250-yarn-RESOURCEMANAGER
254-yarn-JOBHISTORY
255-hive-HIVESERVER2
256-hive-HIVEMETASTORE
260-hbase-MASTER
280-collect-host-statistics
283-host-inspector
291-cluster-host-inspector
296-cluster-host-inspector
302-hdfs-NAMENODE
303-hdfs-SECONDARYNAMENODE
304-hdfs-NAMENODE-nnRpcWait
305-hive-HIVEMETASTORE
308-collect-host-statistics
311-host-inspector
320-collect-host-statistics
323-host-inspector
333-collect-host-statistics
336-host-inspector
343-yarn-RESOURCEMANAGER
347-yarn-JOBHISTORY
348-hive-HIVESERVER2
349-hive-HIVEMETASTORE
359-yarn-RESOURCEMANAGER
363-yarn-JOBHISTORY
364-hive-HIVESERVER2
365-hive-HIVEMETASTORE
377-collect-host-statistics
380-host-inspector
391-collect-host-statistics
394-host-inspector
403-collect-host-statistics
406-host-inspector
415-solr-SOLR_SERVER
ccdeploy_hadoop-conf_etchadoopconf.cloudera.hdfs_2394207936436282336
ccdeploy_hadoop-conf_etchadoopconf.cloudera.yarn_-5589955826917190240
ccdeploy_hadoop-conf_etchadoopconf.cloudera.yarn_-5844902762347635403
ccdeploy_hbase-conf_etchbaseconf.cloudera.hbase_1078272019303849382
ccdeploy_hive-conf_etchiveconf.cloudera.hive_-2148401581528977976
ccdeploy_hive-conf_etchiveconf.cloudera.hive_-9144129025529935636
ccdeploy_solr-conf_etcsolrconf.cloudera.solr_4855637747225843610
ccdeploy_spark2-conf_etcspark2conf.cloudera.spark2_on_yarn_-5389810983416787264
ccdeploy_spark2-conf_etcspark2conf.cloudera.spark2_on_yarn_-8416474417781205702
(4) 安装各个组件目录
/opt/cloudera/parcels/CDH
(5)jar包目录
- 所有jar包所在目录
/opt/cloudera/parcels/CDH/jars
- 各个服务组件对应的jar包
例如sqoop:/opt/cloudera/parcels/CDH/lib/sqoop/lib - Parcels包目录
/opt/cloudera/parcel-repo/
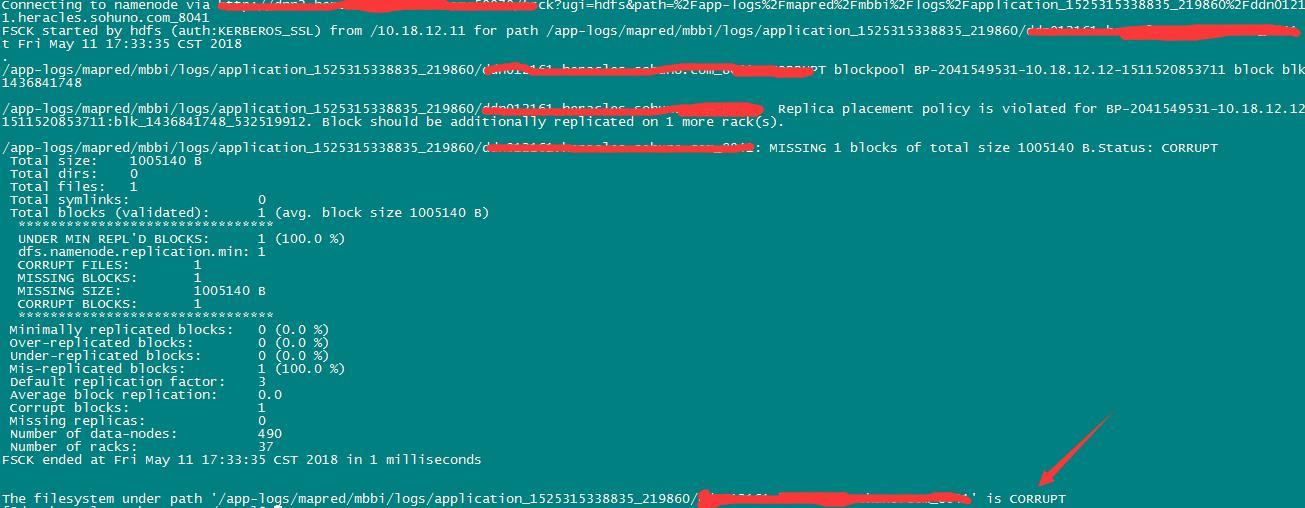
1、namenode出现missing blocks
日常巡检CDH集群和HDP集群发现有些namenode下有很多missing blocks ,hadoop数据存储单位为块。一块64M,这些Missing大多因为元数据丢失而毁坏,很难恢复。就行硬盘故障一样,需要fsck并且delete。
CDH集群 :Cloudera manager的dashboard----HDFS----NameNode Web UI 如图:


清理Missing blocks步骤:登录到console中控机,su hdfs 切换至hadoop集群管理用户
hdfs fsck /blocks-path/ 查看文件系统cluster,如:
hdfs fsck -fs hdfs://dc(n) /block-path/ 指定集群
hdfs fsck -fs hdfs://dc /block-path/ -delete 如果上步元数据已损坏,则直接清理。
例: hdfs fsck /app-logs/mapred/mbbi/logs/application_1525315338835_219860/10.11.12.161
hdfs fsck -fs hdfs://dc1 /app-logs/mapred/mbbi/logs/application_1525315338835_219860/10.11.12.161
hdfs fsck -fs hdfs://dc1 /app-logs/mapred/mbbi/logs/application_1525315338835_219860/10.11.12.161 -delete
2、Spark on Yarn 查看任务日志及状态
1、根据application ID查看某个job的日志
yarn logs -applicationId application_1525315338835_7483
2、查看某个job的状态
yarn application -status application_1525315338835_7483
3、kill掉某个job(完全停止该job的执行,如果直接在Web上kill实际还会继续运行)
yarn application -kill application_1525315338835_7483
也可以通过 http://ip:8088/cluster/scheduler/ 查看,在此Web界面可通过applicationId查看任务状态和日志。

3、安装hive报错:
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to retrieve schema tables from Hive Metastore DB,Not supported

解决:
jdbc版本不对,要求使用5.1.26以上版本的jdbc驱动
4、CDH初始化scm_prepare_database.sh数据库遇到的问题

5、CM定期报"查询 Service Monitor 时发生内部错误"解决办法
本机通过CM搭建CDH成功后,web界面经常报"查询 Service Monitor 时发生内部错误"无法正常显示包括cloudera-scm-server和cloudera-scm-server后台日志也经常报连接拒绝。
思路:
出现此问题,应该是Cloudera Management Service的内存不足所致,Service Monitor 和 Host Monitor服务JVM内存配置太低以至于垃圾回收增多,导致服务进程当掉,扩大相关服务内存即可
解决:

6 文件系统检查点已有 1 天,14 小时,36 分钟。占配置检查点期限 1 小时的 3,860.33%。 临界阈值:400.00%。 自上个文件系统检查点以来已发生 14,632 个事务。
思路:
1.namenode的Cluster ID 与 secondnamenode的Cluster ID 不一致
2. 修改之后还出现这个状况,查看secondnamenode 日志,报ERROR: Exception in doCheckpoint java.io.IOException: Inconsistent checkpoint field
解决:
1、 namenode的Cluster ID 与 secondnamenode的Cluster ID 不一致,对比/dfs/nn/current/VERSION 和/dfs/snn/current/VERSION中的Cluster ID 来确认,如果不一致改成一致后重启应该可以解决。
2、 这个错误,直接删除 /dfs/snn/current/下所有文件,重启snn节点
7 cdh6 存在隐患 : 主机网络接口似乎以全速运行
思路
cloudera后台,显示,存在隐患 : 以下网络接口似乎未以全速运行:enp4s0。1 主机网络接口似乎以全速运行。cloudera cdh6的测试机,硬件达不到要求,才会有上面的问题。然后不影响系统的使用,但是看着不舒服。
解决:
降低cdh,对带宽的要求

8 当安装agent的时候出现信号不法响应
思路
查看supervisor进程,或者查看journalctl -xe打印系统日志。
9 CDH 集群,出现 Entropy 不良问题,原因是系统熵值低于 CDH 检测的阀值引起的。
思路:
需要调大系统熵值
9 FileNotFoundException: …3.0.0-cdh6.0.0-mr-framework.tar.gz(hive执行聚合函数出现的问题)
进行如下图的操作:


上述操作完成后,问题就可以解决了。
10 cdh6.2中datanode无法启动问题
报错:关键信息 java.io.IOException: Incompatible clusterIDs in /dfs/dn: namenode clusterID = cluster74; datanode clusterID = cluster14
关键信息,namenode的 clusterID和datanode的不一致。
解决:
- 如果是新建的集群,则直接主机目录 /dfs/dn (cdh->hdfs->配置-> dfs.datanode.data.dir )下的current目录下的文件删除 rm -rf /dfs/dn/current/*
- 如果集群内有数据,则只改 /dfs/dn/current/VERSION 中的 clusterID=clusterXX XX为正确的namenode的clusterID重启datanode即可
11 启动spark时,有可能提示Log directory specified does not exist:
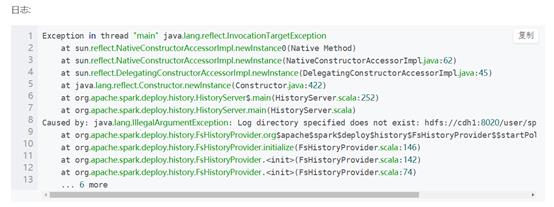
解决:
手动在hdfs上添加/user/spark/applicationHistory目录,主要目录的owner需要是spark用户,可以先用hdfs用户新建此目录,然后使用命令:hdfs dfs –chown –R spark:spark /user/spark/applicationHistory,将拥有者转换成spark即可。

12、安装失败。 无法接收 Agent 发出的检测信号。&& Dependency failed for Cloudera Manager Agent Service.
Cloudera Manager 6.1.0 在集群中添加一个节点,安装过程中遇到:安装失败。 无法接收 Agent 发出的检测信号。
通过去该节点看程序状态:systemctl status cloudera-manager-agent 发现错误:Dependency failed for Cloudera Manager Agent Service.
解决:
1.登录该节点:使用yum卸载 cloudera-manager-agent 和 cloudera-manager-daemons
yum remove cloudera-manager-agent
yum remove cloudera-manager-daemons
2.重新使用Cloudera Manager安装向导,将该节点添加到集群。
注:网上很多说的是开启Auto-TLS造成的,我没有开启Auto-TLS,所以不是这个原因。
13、CDH集群的hive采用local模式测试
采用的CDH大数据平台,由于hive会走yarn平台造成测试很慢,因此设置local模式

14、CDH集群的Cloudera Manager 节点 ,迁移Cloudera Scm Server端
原有的 Cloudera Manager 节点 服务器不稳定,需要迁移至新的服务器
原有: http://192.168.1.212:7180
迁移后: http://192.168.1.44:7180
停止原有的server端与所有agent端
1、在新的服务器里安装好所需要的依赖包(完全离线环境,新环境需要装各种依赖)
文件夹:

2、在旧的 Cloudera Manager 节点压缩文件
scm server 存储目录:/var/lib/cloudera-scm-server
(可以把其他3个重要角色目录也压缩)
3、在新服务器安装 server端(注意:这里是对新服务器已经配置了本地源、免密登录)
cloudera manager server
yum install cloudera-manager-daemons cloudera-manager-agent cloudera-manager-server
4、修改 cloudera-scm-server 配置文件
vim /etc/cloudera-scm-server/db.properties
com.cloudera.cmf.db.type=mysql
com.cloudera.cmf.db.host=192.168.1.44
com.cloudera.cmf.db.name=cm
com.cloudera.cmf.db.user=root
com.cloudera.cmf.db.setupType=EXTERNAL
com.cloudera.cmf.db.password=*****
5、解压恢复备份数据到新服务器指定配置的目录中
新服务器安装完server端,要讲server端目录删除掉,然后进行替换,
默认 : /var/lib/cloudera-scm-server
6、修改所有agent节点的配置文件内容
> vim /etc/cloudera-scm-agent/config.ini
server_host= 新的clouderaManager服务器ip
7、启动新服务器的server端以及agent端
8、登陆新的ClouderaManager地址
以上是关于大数据运维 大数据平台运维总结的主要内容,如果未能解决你的问题,请参考以下文章