看完这篇还不懂HashMap的扩容机制,那我要哭了~
Posted 沉默王二
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了看完这篇还不懂HashMap的扩容机制,那我要哭了~相关的知识,希望对你有一定的参考价值。
HashMap 发出的 Warning:这是《Java 程序员进阶之路》专栏的第 56 篇。那天,小二垂头丧气地跑来给我诉苦,“老王,有个学弟小默问我‘ HashMap 的扩容机制’,我愣是支支吾吾讲了半天,没给他讲明白,讲到最后我内心都是崩溃的,差点哭出声!”
我安慰了小二好一会,他激动的情绪才稳定下来。我给他说,HashMap 的扩容机制本来就很难理解,尤其是 JDK8 新增了红黑树之后。先基于 JDK7 讲,再把红黑树那块加上去就会容易理解很多。
小二这才恍然大悟,佩服地点了点头。
HashMap 发出的呼声:有 GitHub 账号的小伙伴记得去安排一波 star 呀,《Java 程序员进阶之路》开源教程目前在 GitHub 上有 244 个 star 了,准备冲 1000 了,求求各位了。
GitHub 地址:https://github.com/itwanger/toBeBetterJavaer
在线阅读地址:https://itwanger.gitee.io/tobebetterjavaer
大家都知道,数组一旦初始化后大小就无法改变了,所以就有了 ArrayList这种“动态数组”,可以自动扩容。
HashMap 的底层用的也是数组。向 HashMap 里不停地添加元素,当数组无法装载更多元素时,就需要对数组进行扩容,以便装入更多的元素。
当然了,数组是无法自动扩容的,所以如果要扩容的话,就需要新建一个大的数组,然后把小数组的元素复制过去。
HashMap 的扩容是通过 resize 方法来实现的,JDK 8 中融入了红黑树,比较复杂,为了便于理解,就还使用 JDK 7 的源码,搞清楚了 JDK 7 的,我们后面再详细说明 JDK 8 和 JDK 7 之间的区别。
resize 方法的源码:
// newCapacity为新的容量
void resize(int newCapacity) {
// 小数组,临时过度下
Entry[] oldTable = table;
// 扩容前的容量
int oldCapacity = oldTable.length;
// MAXIMUM_CAPACITY 为最大容量,2 的 30 次方 = 1<<30
if (oldCapacity == MAXIMUM_CAPACITY) {
// 容量调整为 Integer 的最大值 0x7fffffff(十六进制)=2 的 31 次方-1
threshold = Integer.MAX_VALUE;
return;
}
// 初始化一个新的数组(大容量)
Entry[] newTable = new Entry[newCapacity];
// 把小数组的元素转移到大数组中
transfer(newTable, initHashSeedAsNeeded(newCapacity));
// 引用新的大数组
table = newTable;
// 重新计算阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
代码注释里出现了左移(<<),这里简单介绍一下:
a=39
b = a << 2
十进制 39 用 8 位的二进制来表示,就是 00100111,左移两位后是 10011100(低位用 0 补上),再转成十进制数就是 156。
移位运算通常可以用来代替乘法运算和除法运算。例如,将 0010011(39)左移两位就是 10011100(156),刚好变成了原来的 4 倍。
实际上呢,二进制数左移后会变成原来的 2 倍、4 倍、8 倍。
transfer 方法用来转移,将小数组的元素拷贝到新的数组中。
void transfer(Entry[] newTable, boolean rehash) {
// 新的容量
int newCapacity = newTable.length;
// 遍历小数组
for (Entry<K,V> e : table) {
while(null != e) {
// 拉链法,相同 key 上的不同值
Entry<K,V> next = e.next;
// 是否需要重新计算 hash
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
// 根据大数组的容量,和键的 hash 计算元素在数组中的下标
int i = indexFor(e.hash, newCapacity);
// 同一位置上的新元素被放在链表的头部
e.next = newTable[i];
// 放在新的数组上
newTable[i] = e;
// 链表上的下一个元素
e = next;
}
}
}
e.next = newTable[i],也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置;这样先放在一个索引上的元素终会被放到链表的尾部(如果发生了hash冲突的话),这一点和 JDK 8 有区别。
在旧数组中同一个链表上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上(仔细看下面的内容,会解释清楚这一点)。
假设 hash 算法(之前的章节有讲到,点击链接再温故一下)就是简单的用键的哈希值(一个 int 值)和数组大小取模(也就是 hashCode % table.length)。
继续假设:
- 数组 table 的长度为 2
- 键的哈希值为 3、7、5
取模运算后,哈希冲突都到 table[1] 上了,因为余数为 1。那么扩容前的样子如下图所示。
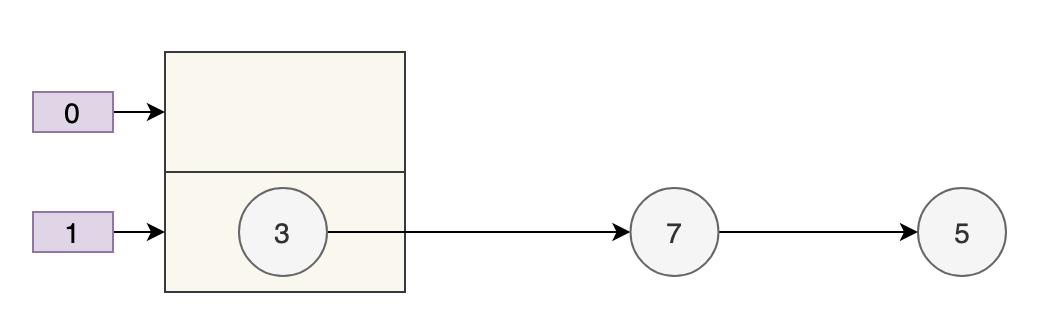
小数组的容量为 2, key 3、7、5 都在 table[1] 的链表上。
假设负载因子 loadFactor 为 1,也就是当元素的实际大小大于 table 的实际大小时进行扩容。
扩容后的大数组的容量为 4。
- key 3 取模(3%4)后是 3,放在 table[3] 上。
- key 7 取模(7%4)后是 3,放在 table[3] 上的链表头部。
- key 5 取模(5%4)后是 1,放在 table[1] 上。
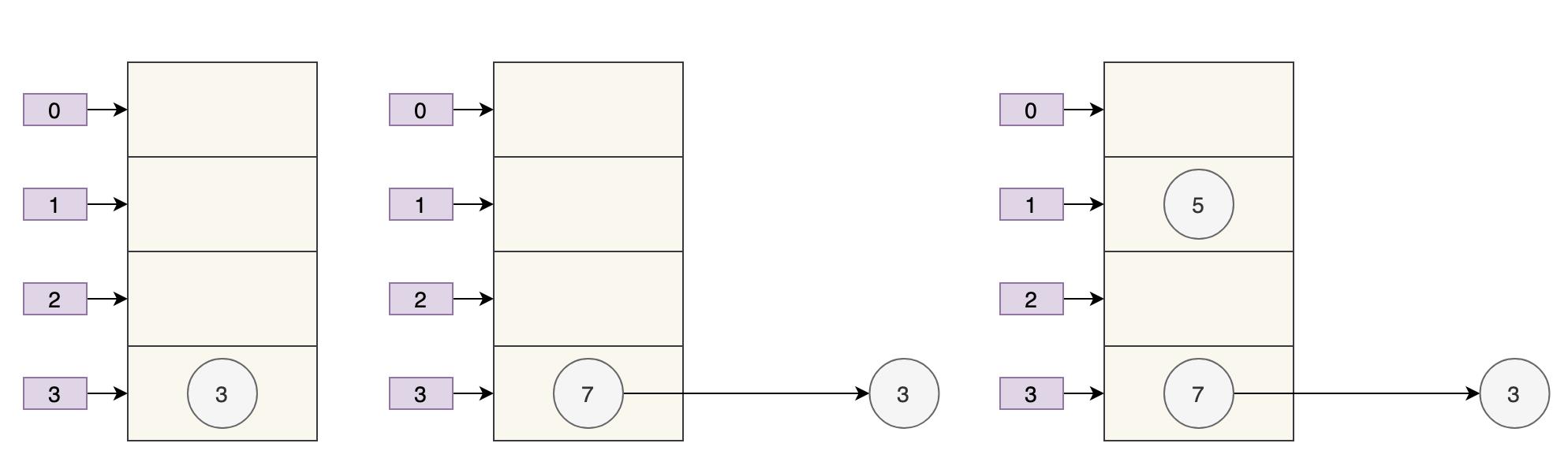
按照我们的预期,扩容后的 7 仍然应该在 3 这条链表的后面,但实际上呢? 7 跑到 3 这条链表的头部了。针对 JDK 7 中的这个情况,JDK 8 做了哪些优化呢?
看下面这张图。
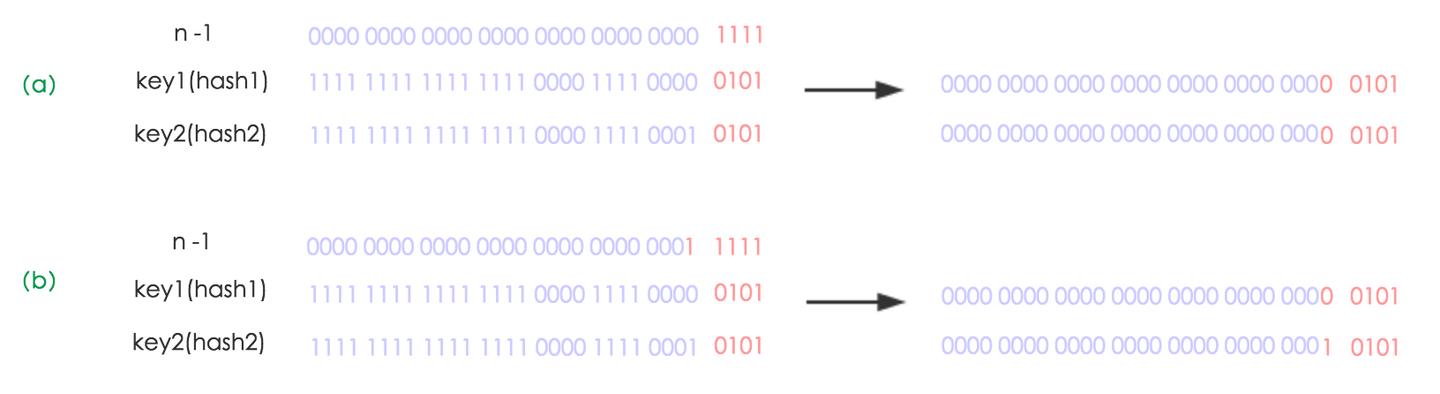
n 为 table 的长度,默认值为 16。
- n-1 也就是二进制的 0000 1111(1X 2 0 2^0 20+1X 2 1 2^1 21+1X 2 2 2^2 22+1X 2 3 2^3 23=1+2+4+8=15);
- key1 哈希值的最后 8 位为 0000 0101
- key2 哈希值的最后 8 位为 0001 0101(和 key1 不同)
- 做与运算后发生了哈希冲突,索引都在(0000 0101)上。
扩容后为 32。
- n-1 也就是二进制的 0001 1111(1X 2 0 2^0 20+1X 2 1 2^1 21+1X 2 2 2^2 22+1X 2 3 2^3 23+1X 2 4 2^4 24=1+2+4+8+16=31),扩容前是 0000 1111。
- key1 哈希值的低位为 0000 0101
- key2 哈希值的低位为 0001 0101(和 key1 不同)
- key1 做与运算后,索引为 0000 0101。
- key2 做与运算后,索引为 0001 0101。
新的索引就会发生这样的变化:
- 原来的索引是 5(0 0101)
- 原来的容量是 16
- 扩容后的容量是 32
- 扩容后的索引是 21(1 0101),也就是 5+16,也就是原来的索引+原来的容量
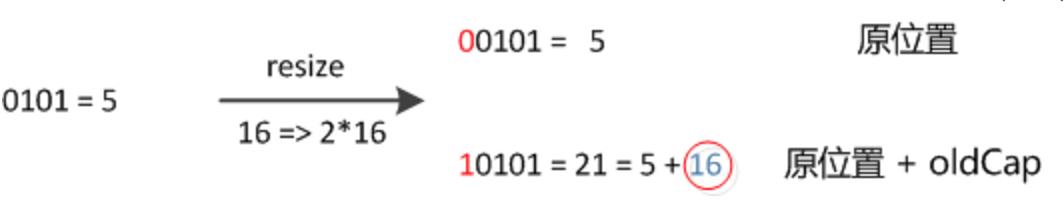
也就是说,JDK 8 不需要像 JDK 7 那样重新计算 hash,只需要看原来的hash值新增的那个bit是1还是0就好了,是0的话就表示索引没变,是1的话,索引就变成了“原索引+原来的容量”。
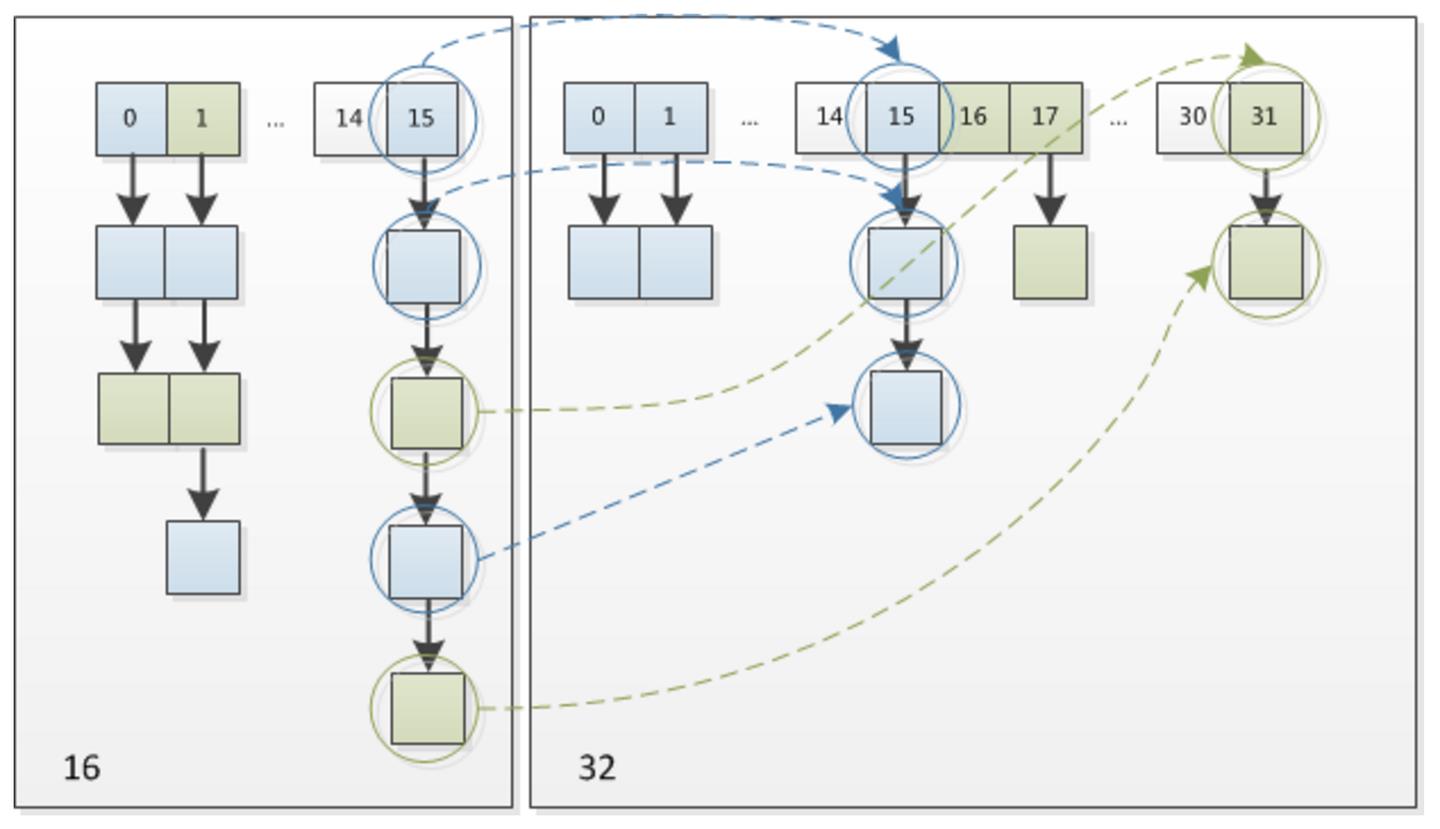
JDK 8 的这个设计非常巧妙,既省去了重新计算hash的时间,同时,由于新增的1 bit是0还是1是随机的,因此扩容的过程,可以均匀地把之前的节点分散到新的位置上。
woc,只能说 HashMap 的作者 Doug Lea、Josh Bloch、Arthur van Hoff、Neal Gafter 真的强——的一笔。
JDK 8 扩容的源代码:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超过最大值就不再扩充了,就只好随你碰撞去吧
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 小数组复制到大数组
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 链表优化重 hash 的代码块
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原来的索引
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 索引+原来的容量
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
参考链接:
https://zhuanlan.zhihu.com/p/21673805
Java 程序员进阶之路,风趣幽默、通俗易懂,对 Java 初学者极度友好和舒适😘,内容包括但不限于 Java 语法、Java 集合框架、Java IO、Java 并发编程、Java 虚拟机等核心知识点。
https://github.com/itwanger/toBeBetterJavaer
以上是关于看完这篇还不懂HashMap的扩容机制,那我要哭了~的主要内容,如果未能解决你的问题,请参考以下文章