Brief Summary of Bokeh Effect Rendering
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Brief Summary of Bokeh Effect Rendering相关的知识,希望对你有一定的参考价值。
注:本文无任何商业用途
1. 前言
在之前一些厂商的人像背景虚化效果中,能够明显看到其是对人像进行了分割,之后再单独将背景进行虚化,最后将人像区域与虚化之后的背景融合起来(这里面需要处理很多画质相关的细节问题)。其效果在目前看来已经有了较大的进步,下图是最新发布的VIVO X70处理出来的虚化结果(注:图片来源于网络,侵删):

可以看到其参照莱卡相机的虚化效果,对应对输入的图像进行虚化处理,这样的效果在外行人看来已经像那么回事了(尽管还会存在一些badcase,但是相信明天会更好。。。)。
单反相机拍摄的背景虚化效果一直是手机相机希望达到的,现在已经有一些工作围绕这个主体展开,并且也取得了相当不错的效果,比如上文中提到的VIVO和Google Pixel 2等。就技术角度来讲现在的背景虚化算法包含了基于传统的图像滤波器背景虚化,以及基于深度学习的背景虚化上来了。但是其背景虚化的终极目标还是希望达到单反相机的效果,下图展示真实的单反相机背景虚化样张(注:图片源自网络,侵删):

对此也有一些学者开展这方面的研究以及相关的竞赛,如:AIM 2020,其包含的挑战内容就包含:
对此,本篇文章从深度学习的角度对bokeh effect的生成进行了研究,在研究的过程中找到一些文章,这里对其进行简要说明,希望对大家在进行该项目的时候在思维上有所启发。
PS: 下面文献中的一些方法没有开放完全代码,需要复现需慎重,但是可以提供一些思路作为参考。
2. 文献
2.1 PyNet
论文名称:《Rendering Natural Camera Bokeh Effect with Deep Learning》
参考代码:PyNET-PyTorch
这篇文章使用未虚化的图像与虚化的图像构建pair对,之后使用一个U型的编解码网络完成对虚化的拟合。在这个过程中为了提升虚化效果的鲁棒性,还可以选择使用深度估计作为额外的guidance,使得最后生成的结果更加准确。下图是其网络结构图:
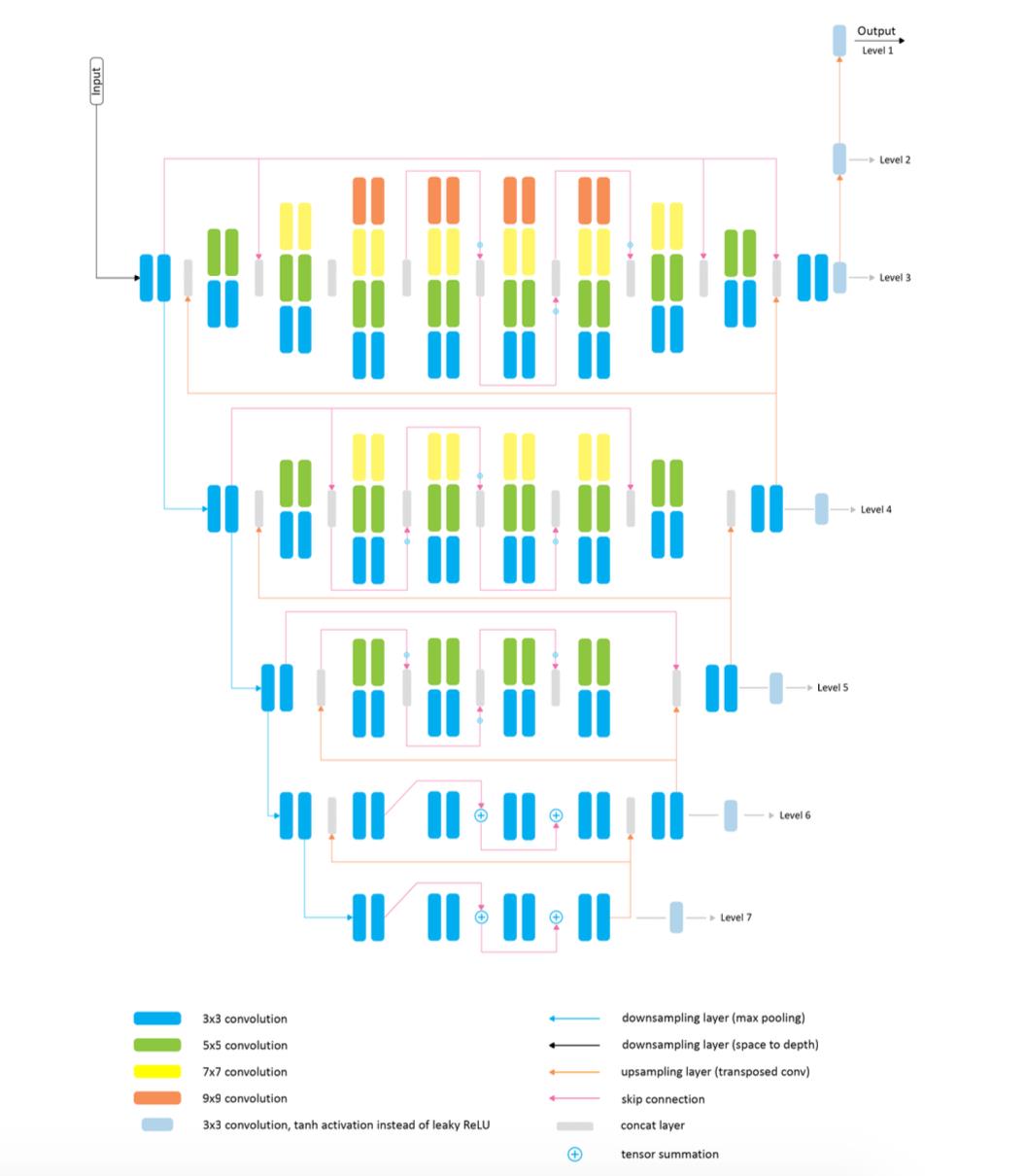
其监督的损失函数使用的是L1、SSIM和content-loss(style transfer中的content loss)组成,不过在不同的输出stage上略有不同,其损失函数的组合形式为:
L
l
e
v
e
l
i
=
α
i
L
L
1
+
β
i
(
1
−
L
S
S
I
M
)
+
σ
i
L
c
o
n
t
e
n
t
\\mathcal{L}_{level_i}=\\alpha_i\\mathcal{L}_{L1}+\\beta_i(1-\\mathcal{L}_{SSIM})+\\sigma_i\\mathcal{L}_{content}
Lleveli=αiLL1+βi(1−LSSIM)+σiLcontent
PS: 具体的实现细节可以参考其放出的代码实现,不过需要留意的是其训练的过程是有点繁琐。。。
2.2 BGGAN
论文名称:《BGGAN:Bokeh-Glass Generative Adversarial Network for Rendering Realistic Bokeh》
参考代码:null
这篇文章使用的是级联的双U型结构去优化bokeh效果,其网络结构也很简单,可以参考下图:

其对应的损失函数先是包含了bokeh预测结果的L1、SSIM和content-loss。这里需要指出的一点是其content-loss使用了L1的形式:
L
c
o
n
t
e
n
t
=
1
H
W
C
∑
i
=
1
H
∑
j
=
1
W
∑
k
=
1
C
∣
∣
F
(
G
(
I
)
i
,
j
,
k
−
F
(
C
i
,
j
,
k
)
)
∣
∣
1
\\mathcal{L}_{content}=\\frac{1}{HWC}\\sum_{i=1}^H\\sum_{j=1}^W\\sum_{k=1}^C||F(G(I)_{i,j,k}-F(C_{i,j,k}))||_1
Lcontent=HWC1i=1∑Hj=1∑Wk=1∑C∣∣F(G(I)i,j,k−F(Ci,j,k))∣∣1
除此之外呢,文章还通过引入GAN损失的形式去监督生成的bokeh结果,从而使得生成bokeh结果更加贴近自然,这里使用了WGAN-GP和PatchGAN的形式,它们的判别器结构见下图所示:

对于GAN部分的损失函数,将其描述为:
L
a
d
v
=
−
1
H
W
∑
i
=
1
H
∑
j
=
1
W
D
(
F
(
I
)
i
,
j
)
\\mathcal{L}_{adv}=-\\frac{1}{HW}\\sum_{i=1}^H\\sum_{j=1}^WD(F(I)_{i,j})
Ladv=−HW1i=1∑Hj=1∑WD(F(I)i,j)
因而,总的损失函数描述为:
L
=
0.5
∗
L
1
+
0.05
∗
L
s
s
i
m
+
0.1
∗
L
c
o
n
t
e
n
t
+
L
a
d
v
\\mathcal{L}=0.5*\\mathcal{L}_1+0.05*\\mathcal{L}_{ssim}+0.1*\\mathcal{L}_{content}+\\mathcal{L}_{adv}
L=0.5∗L1+0.05∗Lssim+0.1∗Lcontent+Ladv
比较可惜的是这篇文章的代码没有开源,在实际炼丹过程中还需多调试。
2.3 Depth-aware Blending
论文名称:《Depth-aware Blending of Smoothed Images for Bokeh Effect Generation》
参考代码:null
在一张具有虚化效果的单反拍摄图片中,其实其中的区域是按照虚化程度划分是可以被划分为多个区域的,那么一个很自然的方式就是去估计这些分量的组成,之后再将其组合起来,那么深度学习网络部分就是去预测这些不同分量的权重的。对其文章的方法在深度估计网络的基础上构建一个虚化权重估计头,从而对不同分量进行加权组合得到最后结果,其网络结构见下图:

上图中的权重参数
(
w
0
,
w
1
,
w
2
,
w
3
)
(w_0,w_1,w_2,w_3)
(w0,w1,w2,w3)就是分区域组合的权重,那么最后虚化的结果其组成描述为:
I
b
o
k
e
h
=
w
0
⊙
I
o
r
g
+
∑
i
=
1
n
w
i
⊙
B
(
I
o
r
g
,
k
i
)
I_{bokeh}=w_0\\odot I_{org}+\\sum_{i=1}^nw_i\\odot B(I_{org},k_i)
Ibokeh=w0⊙Iorg+i=1∑nwi⊙B(Iorg,ki)
其中,
B
(
I
o
r
g
,
k
i
)
B(I_{org},k_i)
B(Iorg,ki)代表的是不同kernel大小的高斯滤波器,并且在每个像素点上其加权参数应该满足
∑
i
=
0
n
w
i
[
x
,
y
]
=
1
\\sum_{i=0}^nw_i[x,y]=1
∑i=0nwi[x,y]=1。
对于损失函数部分,其损失函数被描述为:
L
=
α
∗
L
1
+
β
∗
L
s
s
i
m
\\mathcal{L}=\\alpha*\\mathcal{L}_1+\\beta*\\mathcal{L}_{ssim}
L=α∗L1+β∗Lssim
2.4 Stacked DMSHN
论文名称:《Stacked Deep Multi-Scale Hierarchical Network for Fast Bokeh Effect Rendering from a Single Image》
参考代码:Stacked_DMSHN_bokeh
这篇文章的方法使用了更加复杂的编解码网络结构,并且还是级联优化的形式,其使用的网络结构见下图所示:

在这篇文中中除了较为复杂的编解码网络结构之外,还通过级联优化的形式优化最后结果,自然其训练的过程被划分为了2个阶段,在不同阶段会使用不同的损失函数。在第一个阶段中其损失函数被描述为:
L
s
t
1
=
L
1
+
α
L
s
s
i
m
\\mathcal{L}_{st1}=\\mathcal{L}_1+\\alpha\\mathcal{L}_{ssim}
Lst1=L1+αL