LSTM VS RNN改进
Posted bitcarmanlee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LSTM VS RNN改进相关的知识,希望对你有一定的参考价值。
1.rnn常见的图形表示
rnn是一种早期相对比较简单的循环神经网络,其结构图可以用如下表示。
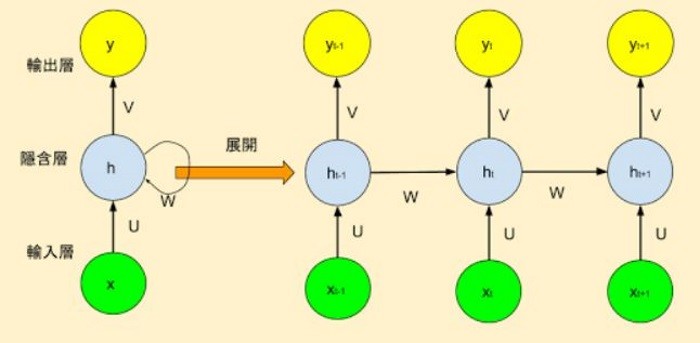
图片来自网络。
其中,x,y,h分别表示神经元的输入,输出以及隐藏状态。
根据上面的图片不难看出,在时刻t,神经元的输入包括
x
t
x_t
xt与上一时刻的隐藏状态
h
t
−
1
h_{t-1}
ht−1,而输出包括当前时刻的隐藏状态
h
t
h_t
ht与当前时刻的输出
y
t
y_t
yt。
RNN的输入
x
t
x_t
xt只包含了t时刻的信息,而不包含顺序信息。而
h
t
h_t
ht则包含了历史信息与当前输入信息,所以RNN是能用到历史信息的。
h
t
=
σ
(
z
t
)
=
σ
(
U
x
t
+
W
h
t
−
1
+
b
)
y
t
=
σ
(
V
h
t
+
c
)
h_t = \\sigma(z_t) = \\sigma(Ux_t + Wh_{t-1} + b) \\\\ y_t = \\sigma(Vh_t + c)
ht=σ(zt)=σ(Uxt+Wht−1+b)yt=σ(Vht+c)
2.RNN的问题
RNN最主要的问题是梯度消失与梯度爆炸
具体梯度消失与梯度爆炸的原因,可以查看参考文献1
3.LSTM
LSTM,Long short-term memory,中文直译的话就是长短记忆模型,主要就是为了解决RNN训练中的梯度消失与梯度爆炸问题。
LSTM与RNN的对比,经常用下面一张图来表示。

LSTM的神经元除了隐状态
h
t
−
1
h_{t-1}
ht−1与当前输入
x
t
x_t
xt外,还多了一个细胞状态
c
t
−
1
c_{t-1}
ct−1 cell。其中,cell更多地与rnn中的h比较像,保存的是历史状态的信息,而LSTM中的h更多的保存上一时刻的输出信息。
LSTM内部的计算,可以分为遗忘门,输入门与输出门。

遗忘门主要是盘段cell状态
c
t
−
1
c_{t-1}
ct−1哪些信息被删除。输入的 ht-1 和 xt 经过 sigmoid 激活函数之后得到 ft,ft 中每一个值的范围都是 [0, 1]。ft 中的值越接近 1,表示 cell 状态 ct-1 中对应位置的值更应该记住;ft 中的值越接近 0,表示 cell 状态 ct-1 中对应位置的值更应该忘记。将 ft 与 ct-1 按位相乘,可以得到遗忘无用信息之后的 c’t-1。
f
t
=
σ
(
W
f
(
h
t
−
1
,
x
t
)
+
b
f
)
c
t
−
1
′
=
c
t
−
1
⊙
f
t
f_t = \\sigma(W_f(h_{t-1}, x_t) + b_f) \\\\ c'_{t-1} = c_{t-1} \\odot f_t
ft=σ(Wf(ht−1,xt)+bf)ct−1′=ct−1⊙ft

输入门主要是判断哪些信息需要加入到cell状态
c
t
−
1
′
c'_{t-1}
ct−1′中。
h
t
−
1
h_{t-1}
ht−1与
x
t
x_t
xt经过tanh激活以后可以得到新的输入信息,但是这些输入信息不需要全部加入,因此需要用
h
t
−
1
h_{t-1}
ht−1与
x
t
x_t
xt经过sigmoid激活以后得到it,it表示哪些新信息有用,两向量相乘后的结果加到
c
t
−
1
′
c'_{t-1}
ct−1′ 中,即得到 t 时刻的 cell 状态
c
t
c_t
ct。

输出门主要用来判断哪些信息到
h
t
h_t
ht中。cell 状态 ct 经过 tanh 函数得到可以输出的信息,然后 ht-1 和 xt 经过 sigmoid 函数得到一个向量 ot,ot 的每一维的范围都是 [0, 1],表示哪些位置的输出应该去掉,哪些应该保留。两向量相乘后的结果就是最终的 ht。
4.LSTM解决梯度爆炸与梯度消失
根据第二部分参考文献里面的内容,我们可以得知梯度爆炸与梯度消失主要是犹豫连乘项引起的,所以要解决这个问题主要是去掉连乘项。
LSTM 中通过门的作用,可以使连乘项约等于 0 或者 1。首先我们看一下 LSTM 中 ct 与 ht 的计算公式。
c t = c t − 1 ⊙ f t + ( i t ⊙ c t ~ h t = o t ⊙ c t ~ c_t = c_{t-1} \\odot f_t + (i_t \\odot \\tilde{c_t} \\\\ h_t = o_t \\odot \\tilde{c_t} ct=ct−1⊙ft+(it⊙ct~ht=ot⊙ct~
在公式中 ft 与 ot 都是通过 sigmoid 函数得到的,意味着它们的值要么接近 0,要么接近 1。因此在 LSTM 中的连乘项变成:
∂ c t ∂ c t − 1 = f t ∂ t t ∂ t t − 1 = o t \\frac{\\partial c_t }{\\partial c_{t-1}} = f_t \\\\ \\frac{\\partial t_t }{\\partial t_{t-1}} = o_t ∂ct−1∂ct=ft∂tt−1∂tt=ot
因此当门的梯度接近1时,连乘项能够保证梯度很好地在 LSTM 中传递,避免梯度消失的情况发生。
而当门的梯度接近 0 时,意味着上一时刻的信息对当前时刻并没有作用,此时没有必要把梯度回传。
参考文献
1.https://zhuanlan.zhihu.com/p/28687529
2.https://juejin.cn/post/6949159845731762184
以上是关于LSTM VS RNN改进的主要内容,如果未能解决你的问题,请参考以下文章