音视频专题音频质量评估方法那些事
Posted 声网Agora
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了音视频专题音频质量评估方法那些事相关的知识,希望对你有一定的参考价值。
今天参加了声网 Agora 的《实时语音质量监控系统的过去、现在与未来》,结合之前工作时音频处理的一些经验,分享一些自己的理解。
音频(泛指人能听到的自然界的所有声音,人耳能听到声音的频谱范围一般为 20~20000HZ)和语音 (语音是指人说话的声音,人说话的声音频谱能量范围大部分分布在 300~3400HZ)两者是不同的,可以看出人是可以听到比人说话更广范围的声音的;这就是人可以听到像乐器,自然界,尖鸣声这些声音,但是人并不能发出来。
为什么要做质量评估,原因有几个方面,比如大家除了面对面交流,在通话,刷视频,听音乐等等活动中的音频是经过了编解码压缩处理的,是为了便于更小代价的传输和存储;像原始声音中掺杂噪声的去除,原始说话声音的增强处理等;可以看出不管是编解码处理还是其他语音处理,目的都是让人听起来更舒服,因此质量评估方法就是评估在对于声音进行处理后的人听起来的感受度情况。
音频评估方法分为主观评价和客观评价。
主观评价其实就是人凭借听觉感受对语音进行打分,常见的有 MOS、CMOS 和 ABX Test;像 AB TEST 在我早期的工作中经常使用到,比如对语音增强算法做了小的优化,想得到实际听觉的感受改善情况,就会把原始算法和优化后算法处理后的语音进行编组,让小伙伴们帮忙测试打分,以此判断是变优还是变差。国际电信联盟(ITU)将语音质量的主观评价方法做了标准化处理,代号为 ITU-T P.800.1。其中收听质量的绝对等级评分(Absolute Category Rating, ACR) 是目前比较广泛采用的一种主观评价方法。参与评测的人员对语音整体质量进行打分,分值范围为 1-5 分,分数越大表示语音质量最好。这种 MOS 值分数后来也应用于客观质量评价。一般 MOS 应为 4 或者更高的,会被认为是比较好的语音质量,一旦 MOS 低于 3.6,则这个语音质量基本不太能接受。
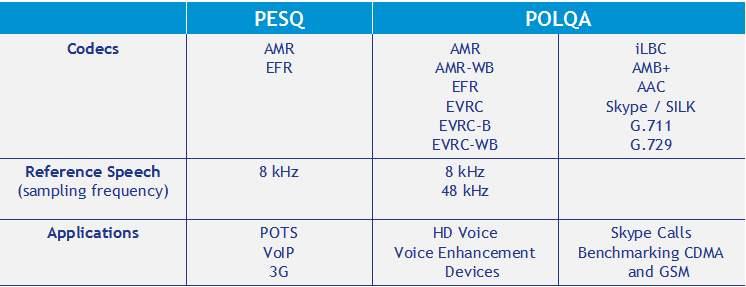
客观评价则主要是使用算法代替人打分的工作,通过算法来评测声音的质量。在客观评价中又分为有参考评价和无参考评价。
- 有参考评价(intrusive method)顾名思义,需要声音源素材进行对比,因此这种方法只能用在线下处理上,对于实时通话处理是不可能做到的;常见的有像 ITU-T P.861(MNB), ITU-T P.862(PESQ)[2], ITU-T P.863(POLQA)[3], STOI[4], BSSEval[5],
- 无参考评价(non intrusive method)则不需要声音源素材,常见的有 ITU-T P.563[6], ANIQUE+[7],ITU-T G.107(E-Model)[8],基于 AI 深度学习的 AutoMOS[9], QualityNet[10], NISQA[11], MOSNet[12]等等
下面表中为主流语音编解码 MOS 值测试评分(来自 Opus 官网,后来又出来了 MOS9,即最高分为 9 分
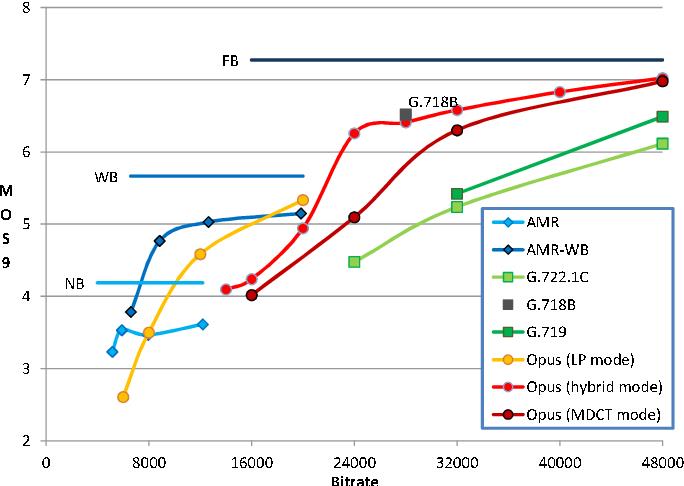
这里重点介绍下 PESQ 和 POLQA
PESQ 属于有参考的客观评价方案,将两个音频信号作为输入,其中一个由 itu 组织提供,另一个输入为经过被测 voip 系统处理后的输出信号。Pesq 算法通过对输入的两个信号提取时频域或变换域特征参数的差异,再将特征参数差异经神经网络模型映射得到客观的音质分值。PESQ 分值其实就是对 MOS 值的一个映射。
POLQA 算法是新一代语音质量评估标准,适用于固网、移动通信网络和 IP 网 络 中 的 语 音 质 量 评 估 。 POLQA 被 ITU-T(International Telecommunication Union)确定为推荐规范 P.863,可用于高清语音、 3G、4G/VoLTE、5G 网络语音质量评估。它用以替代和升级 2001 年发布的 PESQ(ITU-TRecommendation P.862)
与传统 pesq 的区别在于,POLQA 算法具有以下优点:
- 增加对宽带(Wideband)和超宽(SuperWideband)语音质量评估的能力,支持宽带(48khz)。
- 支持最新的语音编码和 VoIP 传输技术,针对现有的 opus、silk 编码器进行过特殊优化。
- 支持多语言环境,各国语言都支持。ITU 组织提供标准测试语料,可进行针对性测试。
当然音频质量评估不只是评估编解码,同样还有其他因素会影响,像 VAD 传输,丢包补偿,网络质量变化(时延/抖动/丢包),甚至包括设备采集。
像上述的无论有参考和无参考,都有其应用的局限性,包括使用场景比较窄,鲁棒性差,复杂度高等问题,而要克服上述的问题,就需要一套覆盖多场景,性能运行几乎无感知的质量评估算法及体系,因此声网自行开发了一套独有的音频质量评估手段。包括上行质量评估和下行质量评估。
上行链路声音经历采集-AEC(回声消除)-NS(噪声抑制)-AGC(增益)处理过程,因此质量评估包含了设备采集稳定性/回声消除能力/噪声抑制能力/音量增益能力的处理效果。
下行链路则主要是通过设备播放给人听,经过编解码-网络传输-弱网对抗(我理解是 VAD/PLC/纠错等处理)-设备播放,最终多弱网,多设备,多模式测试下,其算法与 POLQA 误差值小于 0.15,可以说是达到了不错的效果。
关于音频质量评估,个人认为后续会按照更细化的领域方向发展,包含元素的不同,比如语音评估和音乐评估应该是属于不同的;包含场景的不同,比如实时在线处理和线下评估,实时处理需要高实时性,性能消耗小;而线下评估不需要这么高的要求,对于精准度则要求更高,则可以更多的利用 AI 人工智能的优势以及算法系统上的优化。
以上是关于音视频专题音频质量评估方法那些事的主要内容,如果未能解决你的问题,请参考以下文章
LiveVideoStackCon 2022 上海站 专题抢先看