快速了解分布式跟踪系统 Zipkin
Posted zuozewei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了快速了解分布式跟踪系统 Zipkin相关的知识,希望对你有一定的参考价值。
文章目录
一、概述
FROM https://zipkin.io/
Zipkin is a distributed tracing system.
Zipkin 是一个分布式链路追踪系统。
It helps gather timing data needed to troubleshoot latency problems in service architectures.
它可以收集分布式场景下的调用链路数据,用于解决服务之间延迟问题。
Features include both the collection and lookup of this data.
功能包括四部分:链路的收集、存储、查找、展示。
If you have a trace ID in a log file, you can jump directly to it. Otherwise, you can query based on attributes such as service, operation name, tags and duration. Some interesting data will be summarized for you, such as the percentage of time spent in a service, and whether or not operations failed.
如果在日志文件中有 trace ID,则可以直接跳转到它。否则,您可以根据服务、操作名称、tags 和持续时间等属性进行查询。将为你总结一些有趣的数据,例如在服务中花费的时间的百分比,以及操作是否失败。
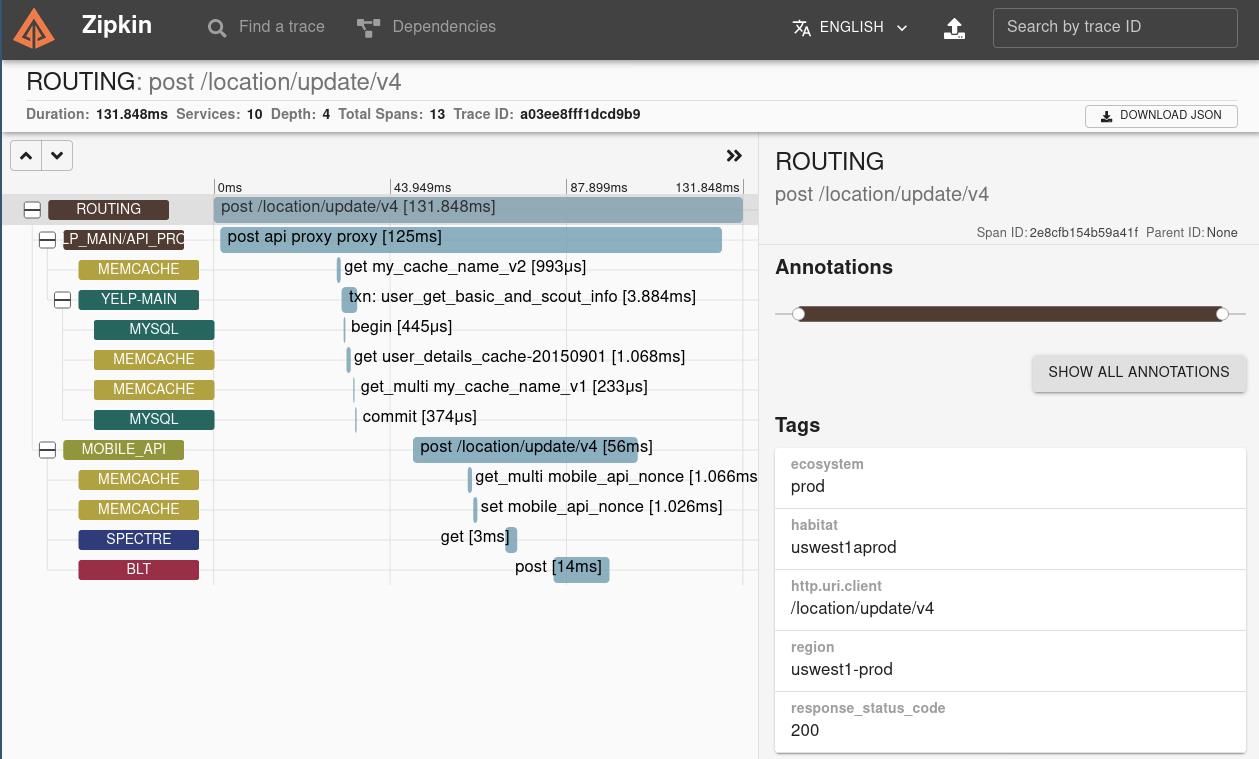
The Zipkin UI also presents a Dependency diagram showing how many traced requests went through each application. This can be helpful for identifying aggregate behavior including error paths or calls to deprecated services.
Zipkin UI 还提供了一个依赖关系图,显示每个应用程序跟踪了多少请求。这有助于识别聚合行为,包括错误路径或对弃用服务的调用。
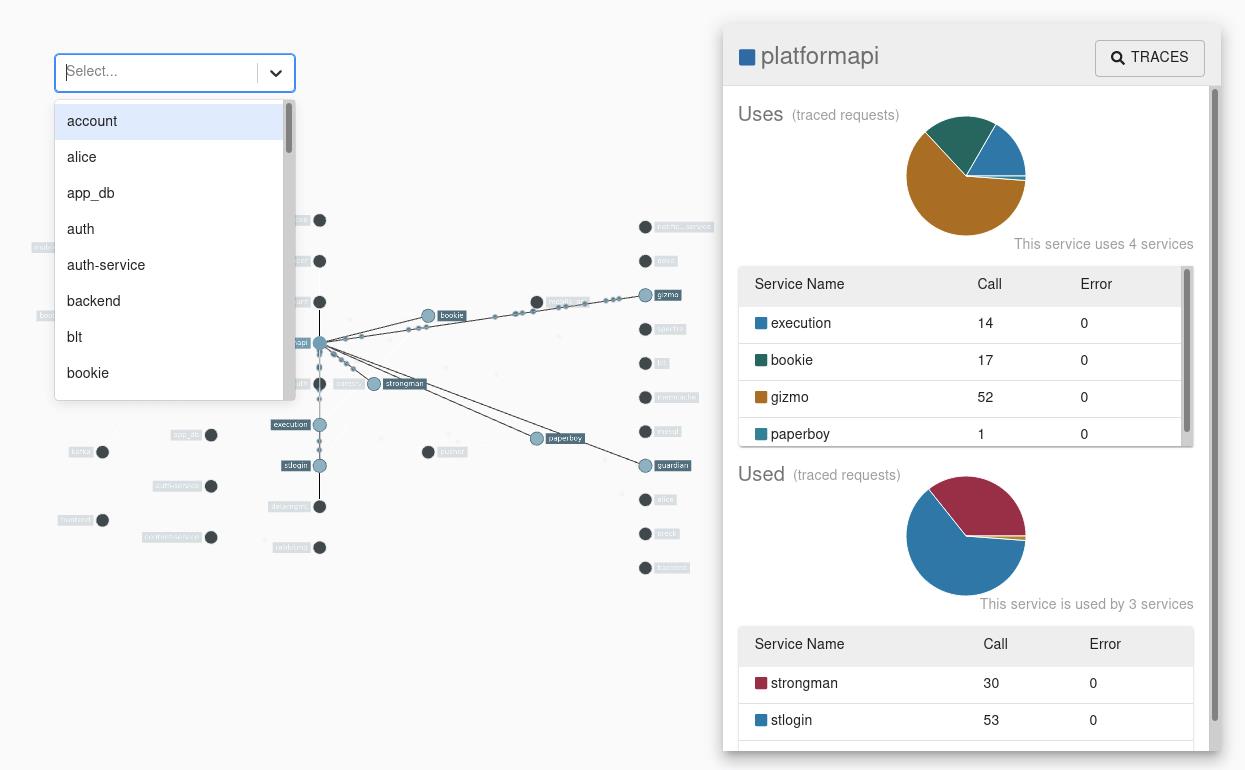
Applications need to be “instrumented” to report trace data to Zipkin. This usually means configuration of a tracer or instrumentation library. The most popular ways to report data to Zipkin are via HTTP or Kafka, though many other options exist, such as Apache ActiveMQ, gRPC and RabbitMQ. The data served to the UI are stored in-memory, or persistently with a supported backend such as Apache Cassandra or Elasticsearch.
需要对应用程序进行“检测”,以便向 Zipkin 报告跟踪数据。这通常意味着配置跟踪程序或检测库。最流行的向 Zipkin 报告数据的方式是通过 HTTP 或 Kafka,尽管还有许多其他选项,如 Apache ActiveMQ、 gRPC 和 RabbitMQ。提供给用户界面的数据存储在内存中,或者通过支持的后端持久地存储在内存中,比如 Cassandra 或 Elasticsearch。
和市面上其它分布式链路追踪系统一样,Zipkin 也是根据 Google 论文《Dapper,大规模分布式系统的跟踪系统》作为理论,进行设计。Zipkin 最初由 Twitter公司开源,而后演化出 Open Zipkin) 社区。
二、快速启动
from https://zipkin.io/pages/quickstart.html
in this section we’ll walk through building and starting an instance of Zipkin for checking out Zipkin locally. There are three options: using Java, Docker or running from source.
在本节中,我们将逐步构建并启动一个 Zipkin 实例,用于检查本地 Zipkin。有三种选择: 使用 Java、 Docker 或者从源代码运行。
If you are familiar with Docker, this is the preferred method to start. If you are unfamiliar with Docker, try running via Java or from source.
如果您熟悉 Docker,这是首选的启动方法。如果你不熟悉 Docker,可以尝试通过 Java 或源代码运行。
Regardless of how you start Zipkin, browse to http://your_host:9411 to find traces!
不管你如何开始 Zipkin,可以浏览 http://your_host:9411 网站找到蛛丝马迹!
1、Docker
The Docker Zipkin) project is able to build docker images, provide scripts and a docker-compose.yml for launching pre-built images. The quickest start is to run the latest image directly:
Dockerzipkin 项目能够构建 Docker 镜像,提供脚本和 Docker-compose。用于运行镜像。最快的开始是直接运行最新的镜像:
docker run -d -p 9411:9411 openzipkin/zipkin
2、Java
if you have Java 8 or higher installed, the quickest way to get started is to fetch the latest release) as a self-contained executable jar:
如果你已经安装了 Java8 或更高版本,最快的方法就是以独立的可执行 jar 的形式获取最新版本:
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar
3、从源代码运行
Zipkin can be run from source if you are developing new features. To achieve this, you’ll need to get Zipkin’s source) and build it.
如果你正在开发新的特性,Zipkin 可以从源代码运行。为了实现这一点,你需要获得 Zipkin 的源代码并构建它。
# get the latest source
git clone https://github.com/openzipkin/zipkin
cd zipkin
# Build the server and also make its dependencies
./mvnw -DskipTests --also-make -pl zipkin-server clean install
# Run the server
java -jar ./zipkin-server/target/zipkin-server-*exec.jar
三、zipkin 的架构
From https://zipkin.io/pages/architecture.html
Tracers live in your applications and record timing and metadata about operations that took place. They often instrument libraries, so that their use is transparent to users. For example, an instrumented web server records when it received a request and when it sent a response. The trace data collected is called a Span.
示踪程序存在于应用程序中,记录发生的操作的计时和元数据。它们经常使用 instrument库,因此它们的使用对用户是透明的。例如,一个检测过的 web 服务器在收到请求和发送响应时都会记录。收集的跟踪数据称为 Span。
Instrumentation is written to be safe in production and have little overhead. For this reason, they only propagate IDs in-band, to tell the receiver there’s a trace in progress. Completed spans are reported to Zipkin out-of-band, similar to how applications report metrics asynchronously.
Instrumentation 的编写是为了在生产中保证安全,并且开销很小。由于这个原因,它们只在带内传播 id,以告诉接收者有一个正在进行的跟踪。已完成的跨度报告给 Zipkin 带外,类似于应用程序异步报告指标的方式。
For example, when an operation is being traced and it needs to make an outgoing http request, a few headers are added to propagate IDs. Headers are not used to send details such as the operation name.
例如,当一个操作正在被跟踪并且它需要发出一个传出 http 请求时,会添加一些头来传播 id。标头不用于发送诸如操作名称之类的详细信息。
The component in an instrumented app that sends data to Zipkin is called a Reporter. Reporters send trace data via one of several transports to Zipkin collectors, which persist trace data to storage. Later, storage is queried by the API to provide data to the UI.
发送数据到 Zipkin 的测试应用程序中的组件被称为 Reporter。 记者通过几种传输方式中的一种将跟踪数据发送给 Zipkin 收集者,这些收集者将跟踪数据存储起来。 随后,存储将被 API 查询,以向 UI 提供数据。
Zipkin 整体架构如下图所示,分成三个部分:
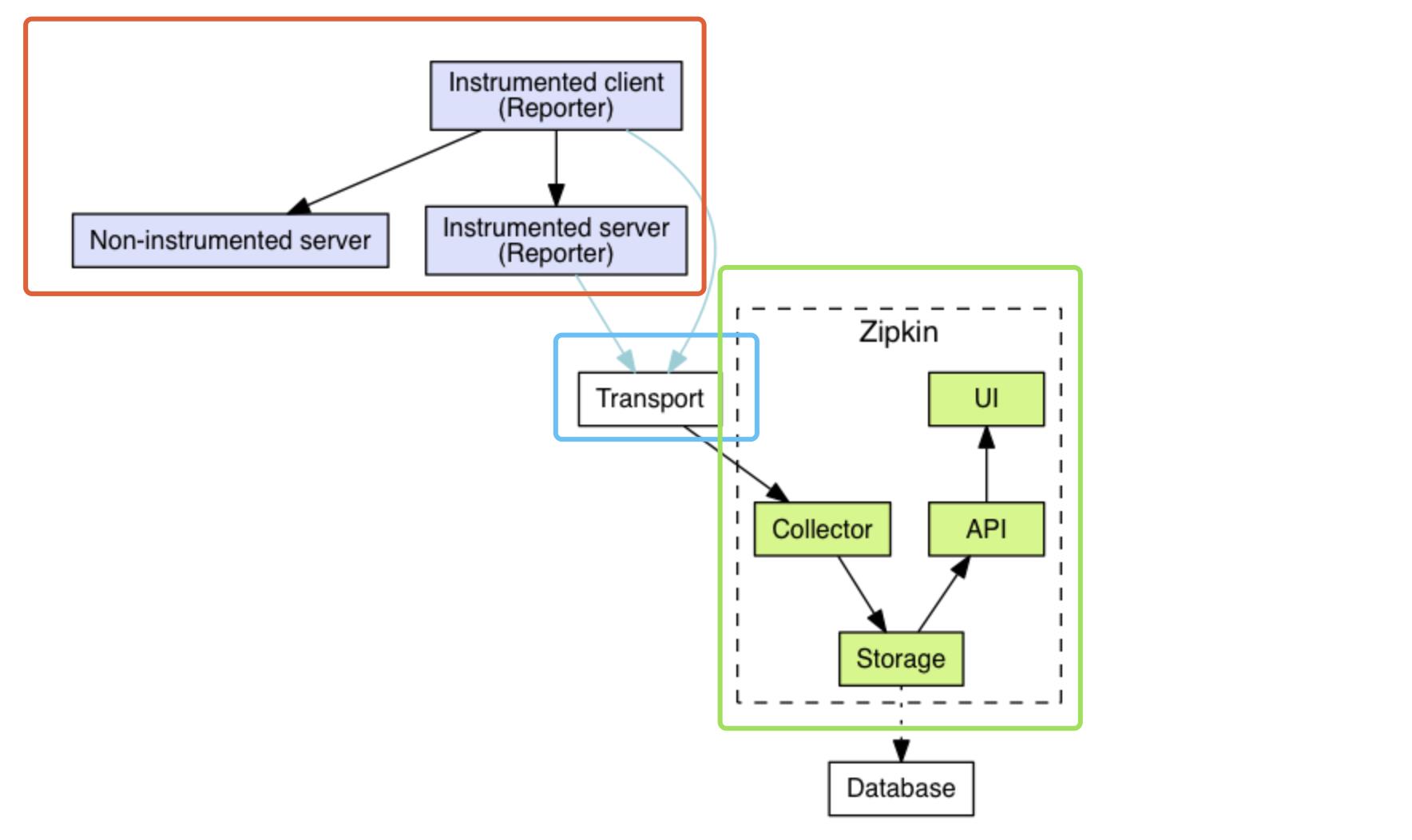
- 【红框】Zipkin Tracer :负责从应用中,收集分布式场景下的调用链路数据,发送给 Zipkin Server 服务。
- 【蓝框】Transport :链路数据的传输方式,目前有 HTTP、MQ 等等多种方式。
- 【绿框】Zipkin Server :负责接收 Tracer 发送的 Tracing 数据信息,将其聚合处理并进行存储,后提供查询功能。之后,用户可通过 Web UI 方便获得服务延迟、调用链路、系统依赖等等。
1、Zipkin Tracer
一般来说,在 Java 应用程序中,我们使用 Brave 库,作为 Zipkin Server 的 Java Tracer 客户端。同时它的 instrumentation 子项目,已经提供了 SpringMVC、mysql、Dubbo 等等的链路追踪的功能。
Instrumented Client 和 Instrumented Server 的区别:
- Instrumented Client 和 Instrumented Server,它们是指分布式架构中使用了 Tracer 工具的两个应用,Client 会调用 Server 提供的服务,两者都会向 Zipkin 上报链路数据。
- Non-Instrumented Server,指的是未使用 Trace 工具的 Server,显然它不会上报链路数据,但是调用其的 Instrumented Client 还是会上报链路数据。
2、Transport
Reporter 通过 Transport 发送追踪数据到 Zipkin 的 Collector,Collector 持久化数据到 Storage 中。之后,API 从 Storage 中查询数据提供给 UI。
一般来说,在 Java 应用程序中,我们使用 zipkin-reporter-java 库,作为 Zipkin Reporter 客户端。
包括如下的 Transport 方式:
- HTTP ,通过 okhttp3 或 urlconnection 实现。
- ActiveMQ,通过 activemq-client 实现。
- RabbitMQ,通过 amqp-client 实现。
- Kafka,通过 kafka 或 kafka08 实现。
- Thrift,通过 libthrift 实现。
请求量级小的时候,选择 HTTP 方式即可。量级比较大的时候,推荐使用 Kafka 消息队列。
3、Zipkin Server
Zipkin Server 包括 Collector、Storage、API、UI 四个组件。
- Collector:负责接收 Tracer 发送的链路数据,并为了后续的查询,对链路数据进行校验、存储、索引。
- Storage;负责存储链路数据,目前支持 Memory、MySQL、Cassandra、ElasticSearch 等数据库。
- Memory :默认存储器,用于简单演示为主,生产环境下不推荐。
- MySQL :小规模使用时,可以考虑 MySQL 进行存储。
- ElasticSearch :主流基本采用 ElasticSearch 存储链路数据。
- Cassandra :在 Twitter 内部被大规模使用,,因为 Cassandra 易跨站,支持灵活的 schema。
- API:负责提供了一个简单的 JSON API 查询和获取追踪数据。API 的主要消费者就是 Web UI。
- UI:Web UI 负责提供了基于服务、时间和标记(annotation)查看服务延迟、调用链路、系统依赖等等的界面。
四、流程图
让我们来一起看个 Zipkin 的示例流程图:
from https://zipkin.io/pages/architecture.html
As mentioned in the overview, identifiers are sent in-band and details are sent out-of-band to Zipkin. In both cases, trace instrumentation is responsible for creating valid traces and rendering them properly. For example, a tracer ensures parity between the data it sends in-band (downstream) and out-of-band (async to Zipkin).
正如概述中提到的,标识符发送到带内,详细信息发送到带外 Zipkin。在这两种情况下,跟踪检测都负责创建有效的跟踪并正确地呈现它们。例如,跟踪程序确保了它发送的带内(下游)和带外(async to Zipkin)数据之间的奇偶校验。
Here’s an example sequence of http tracing where user code calls the resource /foo. This results in a single span, sent asynchronously to Zipkin after user code receives the http response.
下面是用户代码调用资源/foo 的 http 跟踪示例序列。这将导致一个跨度,在用户代码接收到 http 响应后异步发送到 Zipkin。
┌─────────────┐ ┌───────────────────────┐ ┌─────────────┐ ┌──────────────────┐
│ User Code │ │ Trace Instrumentation │ │ Http Client │ │ Zipkin Collector │
└─────────────┘ └───────────────────────┘ └─────────────┘ └──────────────────┘
│ │ │ │
┌─────────┐
│ ──┤GET /foo ├─▶ │ ────┐ │ │
└─────────┘ │ record tags
│ │ ◀───┘ │ │
────┐
│ │ │ add trace headers │ │
◀───┘
│ │ ────┐ │ │
│ record timestamp
│ │ ◀───┘ │ │
┌─────────────────┐
│ │ ──┤GET /foo ├─▶ │ │
│X-B3-TraceId: aa │ ────┐
│ │ │X-B3-SpanId: 6b │ │ │ │
└─────────────────┘ │ invoke
│ │ │ │ request │
│
│ │ │ │ │
┌────────┐ ◀───┘
│ │ ◀─────┤200 OK ├─────── │ │
────┐ └────────┘
│ │ │ record duration │ │
┌────────┐ ◀───┘
│ ◀──┤200 OK ├── │ │ │
└────────┘ ┌────────────────────────────────┐
│ │ ──┤ asynchronously report span ├────▶ │
│ │
│{ │
│ "traceId": "aa", │
│ "id": "6b", │
│ "name": "get", │
│ "timestamp": 1483945573944000,│
│ "duration": 386000, │
│ "annotations": [ │
│--snip-- │
└────────────────────────────────┘
由上图可以看出,应用的代码(User Code)发起 Http Get 请求(请求路径 /foo),经过 Zipkin Tracer 框架(Trace Instrumentation)拦截,并依次经过如下步骤,记录链路信息到 Zipkin Server 中:
- 1、record tags :记录 tags 信息到 Span 中。
- 2、add trace headers :将当前调用链的链路信息记录到 Http Headers 中。
- 3、record timestamp :记录当前调用的时间戳(timestamp)。
- 4、发送 HTTP 请求,并携带链路相关的 Header。例如说, X-B3-TraceId:aa,X-B3-SpandId:6b。
- 5、调用结束后,记录当次调用所花的时间(duration)。
- 6、将步骤 1-5,汇总成一个 Span(最小的 Trace 单元),异步上报该 Span 信息给 Zipkin Collector。
Trace instrumentation report spans asynchronously to prevent delays or failures relating to the tracing system from delaying or breaking user code.
异步地跨越跟踪检测报告,以防止与跟踪系统相关的延迟或故障延迟或破坏用户代码。
五、几个核心概念
zipkin 涉及 Span、Trace、Annotation 等基本概念,这些概念还是比较重要的,所以下面我们就具体介绍下这些概念。
1、Span
基本工作单元,Span 表示一个服务调用的开始和结束时间,即执行的时间段。一次链路调用(可以是 RPC,DB 等没有特定的限制)创建一个 span,通过一个 64 位 ID 标识它,uuid 较为方便,span 中还有其他的数据,例如描述信息,时间戳,key-value 对的(Annotation)tag 信息,parent_id 等,其中 parent-id 可以表示span调用链路来源。
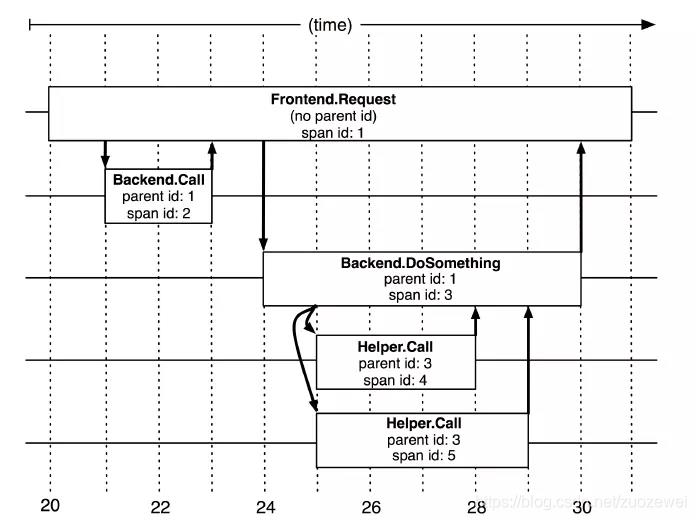
对于每个 Trace 树,Trace 都要定义一个全局唯一的 TraceID,在这个跟踪中的所有 Span 都将获取到这个TraceID。每个 Span 都有一个 ParentID 和它自己的 SpanID。上面图中 Frontend Request 调用的 ParentID 为空,SpanID 为 1;然后 Backend Call 的 ParentID 为 1,SpanID 为 2;Backend DoSomething 调用的 ParentID 也为 1,SpanID 为 3,其内部还有两个调用,Helper Call 的 ParentID 为 3,SpanID 为 4,以此类推。
上图说明了 span 在一次大的跟踪过程中是什么样的。Dapper 记录了 span 名称,以及每个 span 的 ID 和父 ID,以重建在一次追踪过程中不同 span 之间的关系。如果一个 span 没有父 ID 被称为 root span。所有 span 都挂在一个特定的跟踪上,也共用一个 TraceID。
Span 数据结构:
type Span struct {
TraceID int64 // 用于标示一次完整的请求id
Name string
ID int64 // 当前这次调用span_id
ParentID int64 // 上层服务的调用span_id 最上层服务parent_id为null
Annotation []Annotation // 用于标记的时间戳
Debug bool
}
2、Trace
类似于 树结构的 Span 集合,表示一次完整的跟踪,从请求到服务器开始,服务器返回 response 结束,跟踪每次 rpc 调用的耗时,存在唯一标识 trace_id。比如:你运行的分布式大数据存储一次 Trace 就由你的一次请求组成。
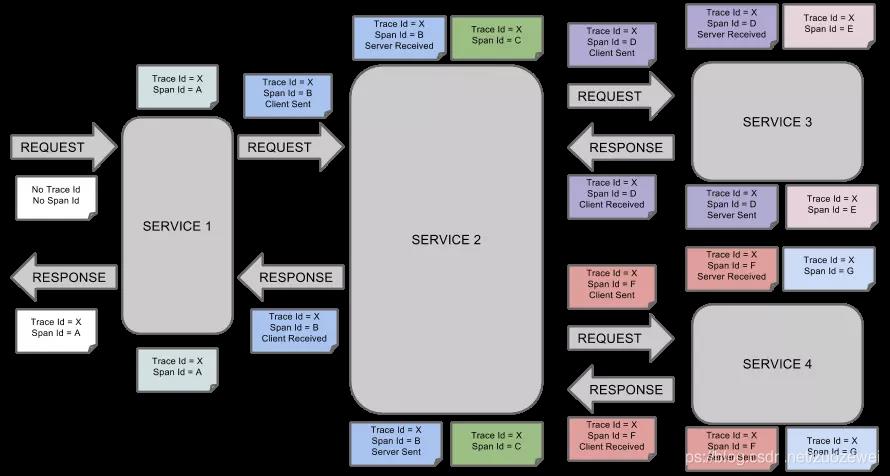
每种颜色的 note 标注了一个 span,一条链路通过 TraceId唯一标识,Span 标识发起的请求信息。树节点是整个架构的基本单元,而每一个节点又是对 span 的引用。节点之间的连线表示的 span 和它的父 span 直接的关系。虽然 span 在日志文件中只是简单的代表 span 的开始和结束时间,他们在整个树形结构中却是相对独立的。
3、Annotation
注解,用来记录请求特定事件相关信息(例如时间),一个 span 中会有多个 annotation 注解描述。通常包含四个注解信息:
- (1) cs:Client Start,表示客户端发起请求
- (2) sr:Server Receive,表示服务端收到请求
- (3) ss:Server Send,表示服务端完成处理,并将结果发送给客户端
- (4) cr:Client Received,表示客户端获取到服务端返回信息
Annotation 数据结构:
type Annotation struct {
Timestamp int64
Value string
Host Endpoint
Duration int32
}
因为 Zipkin 的模型基本符合 Opentracing 规范,所以大家有空可以去了解下《OpenTracing 官方标准》(https://github.com/opentracing-contrib/opentracing-specification-zh),进一步了解分布式链路追踪。
六、小结
本文仅仅是简单的 Zipkin 入门文章,如果大家想更好的使用 Zipkin,推荐详细阅读下官方文档。
以上是关于快速了解分布式跟踪系统 Zipkin的主要内容,如果未能解决你的问题,请参考以下文章