Sleuth+Zipkin 实现 SpringCloud 链路追踪
Posted zuozewei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sleuth+Zipkin 实现 SpringCloud 链路追踪相关的知识,希望对你有一定的参考价值。
文章目录
一、前言
在 全链路监控:方案概述与比较 一文中,我们有详细介绍过分布式链路跟踪的实现理论基础。
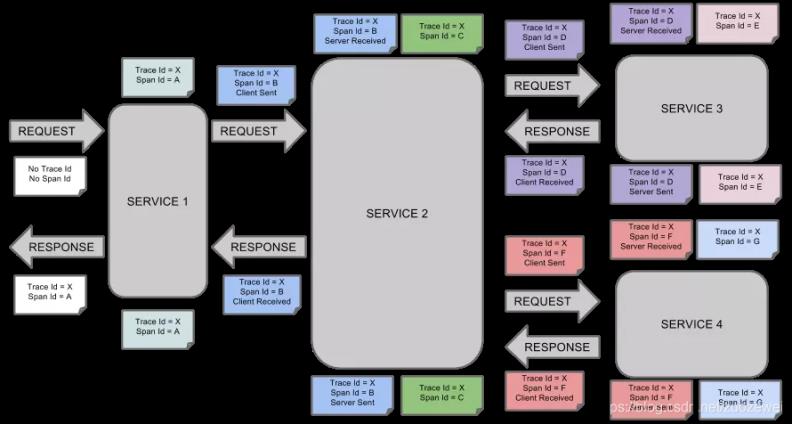
我们看到上图,知道在微服务架构下,系统的功能是由大量的微服务协调组成的,例如:电商下单业务就需要订单服务、库存服务、支付服务、短信通知服务逐级调用才能完成。而每个服务可能是由不同的团队进行开发,部署在成百上千台服务器上。
如此复杂的消息传递过程,当系统发生故障的时候,我们就需要一种机制对故障点进行快速定位,确认到底是哪个服务出了问题,分布式链路追踪技术由此而生。
所谓的分布式链路追踪,就是运行时通过某种方式记录下服务之间的调用过程,在通过可视化的 UI 界面帮相关人员快速定位到故障点。分布式链路追踪,是微服务架构运维监控的底层基础设施,没有它,相关人员就像盲人摸象一样,根本无法了解服务间通信过程。
二、应用架构图
本文将会介绍如何在如何在 Spring Cloud 架构下基于 Sleuth+Zipkin 实现微服务链路追踪,主要演示HTTP 调用方式。
在具体介绍之前,我们先来看一下我们本文示例 Spring Cloud 集成 Zipkin 的应用架构,如下图所示:
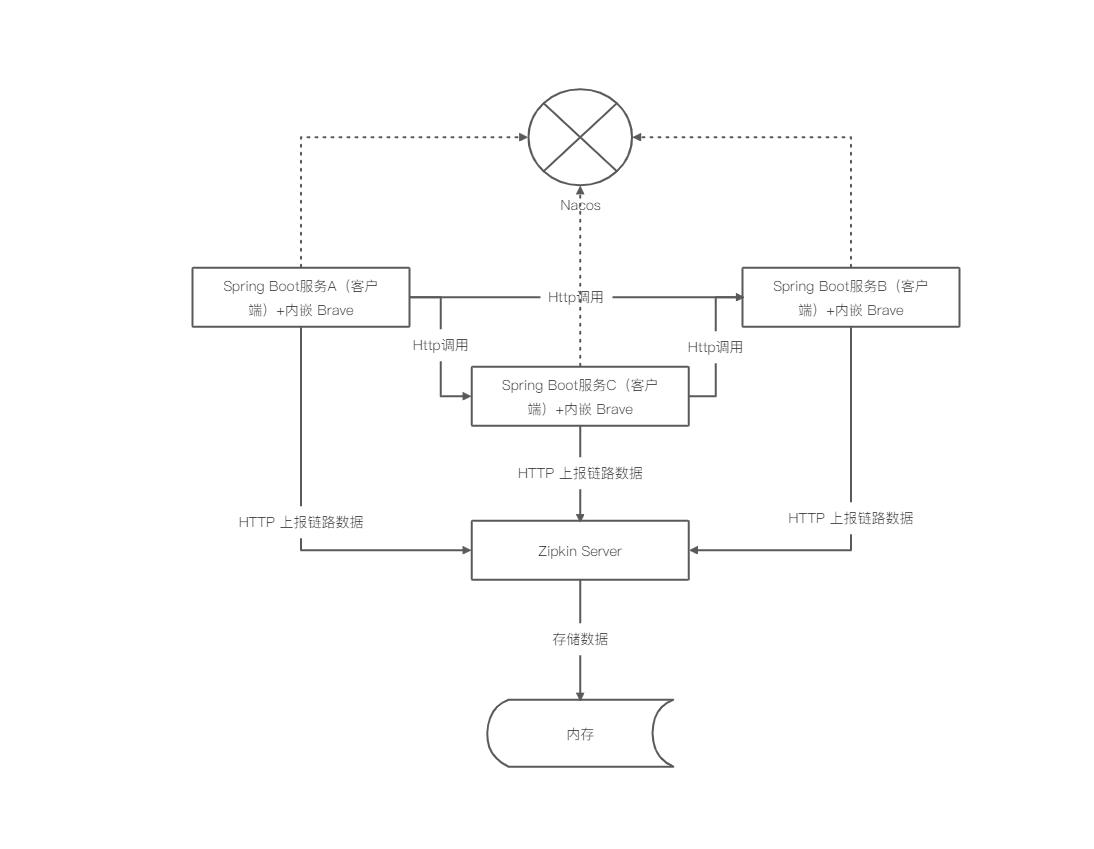
从架构图中可以看到:所有的服务都注册到 Nacos 上;当客户端的请求到来之时,从 Nacos 中获取对应服务的信息,并将请求反向代理到指定的服务实例。
涉及的业务服务与组件包含以下 5 个:
- Nacos,本地安装并启动;
- Zipkin,本地安装并启动;
- Spring Boot 服务A;
- Spring Boot 服务B;
- Spring Boot 服务C。
如果你对 Zipkin 还不熟悉,建议去看下我的这篇文章:快速了解分布式跟踪系统 Zipkin
三、快速了解 Sleuth
Sleuth 是 Spring Cloud 提供的服务治理模块,在其标准生态下内置了 Sleuth 这个组件。它通过扩展 Logging 日志的方式实现微服务的链路追踪。
在标准的微服务下日志产生的格式是:
2021-09-21 02:03:20.166 INFO [a-service,,,] 40327 --- [erListUpdater-0] c.netflix.config.ChainedDynamicProperty : Flipping property: b-service.ribbon.ActiveConnectionsLimit to use NEXT property: niws.loadbalancer.availabilityFilteringRule.activeConnectionsLimit = 2147483647
但是当引入 Spring Cloud Sleuth 链路追踪组件后就会变成下面的格式:
2021-09-21 02:06:41.410 INFO [a-service,632f57c51af8c7a4,632f57c51af8c7a4,true] 40415 --- [nio-7000-exec-1] c.netflix.config.ChainedDynamicProperty : Flipping property: b-service.ribbon.ActiveConnectionsLimit to use NEXT property: niws.loadbalancer.availabilityFilteringRule.activeConnectionsLimit = 2147483647
⽇志输出格式是固定的,包含以下四部分:
[appname,traceId,spanId,exportable]
- appname,说明日志是由哪个微服务产生的。
- TraceId,轨迹编号。一次完整的业务处理过程被称为轨迹,例如:实现登录功能需要从服务 A 调用服务 B,服务B再调用服务 C,那这一次登录处理的过程就是一个轨迹,从前端应用发来请求到接收到响应,每一次完整的业务功能处理过程都对应唯一的 TraceId。
- SpanId,步骤编号。刚才要实现登录功能需要从服务 A 到服务 C 涉及 3 个微服务处理,按处理前后顺序,每一个微服务处理时日志都被赋予不同的 SpanId。一个 TraceId 拥有多个 SpanId,而 SpanId 只能隶属于某一个 TraceId。
- 导出标识,当前这个日志是否被导出,该值为 true 的时候说明当前轨迹数据允许被其他链路追踪可视化服务收集展现。
我们模拟了服务 A -> B -> C 的调用链路,分别产生的日志如下:
2021-09-21 02:18:36.494 DEBUG [a-service,14aa6f21d700f377,14aa6f21d700f377,true] 40619 --- [nio-7000-exec-7] org.apache.tomcat.util.http.Parameters : Set encoding to UTF-8
2021-09-21 02:18:36.524 DEBUG [b-service,14aa6f21d700f377,828df12c1c851367,true] 40622 --- [nio-8000-exec-6] org.apache.tomcat.util.http.Parameters : Set encoding to UTF-8
2021-09-21 02:18:36.571 DEBUG [c-service,14aa6f21d700f377,ebd9892f8756801d,true] 40626 --- [nio-9000-exec-7] org.apache.tomcat.util.http.Parameters : Set encoding to UTF-8
可以发现,按调用时间先后顺序分别是 A 到 C 依次出现。因为是一次完整业务处理,TraceId 都是相同的,SpanId 却各不相同,这些日志都已经被 Sleuth 导出,正常被 ZipKin 收集展示。
Zipkin 是 推特的一个开源分布式链路跟踪系统,它能收集各个服务实例上的链路追踪数据并可视化展现。刚才 ABC 服务控制台产生的日志在 ZipKin 的 UI 界面中会以链路追踪图表的形式展现。
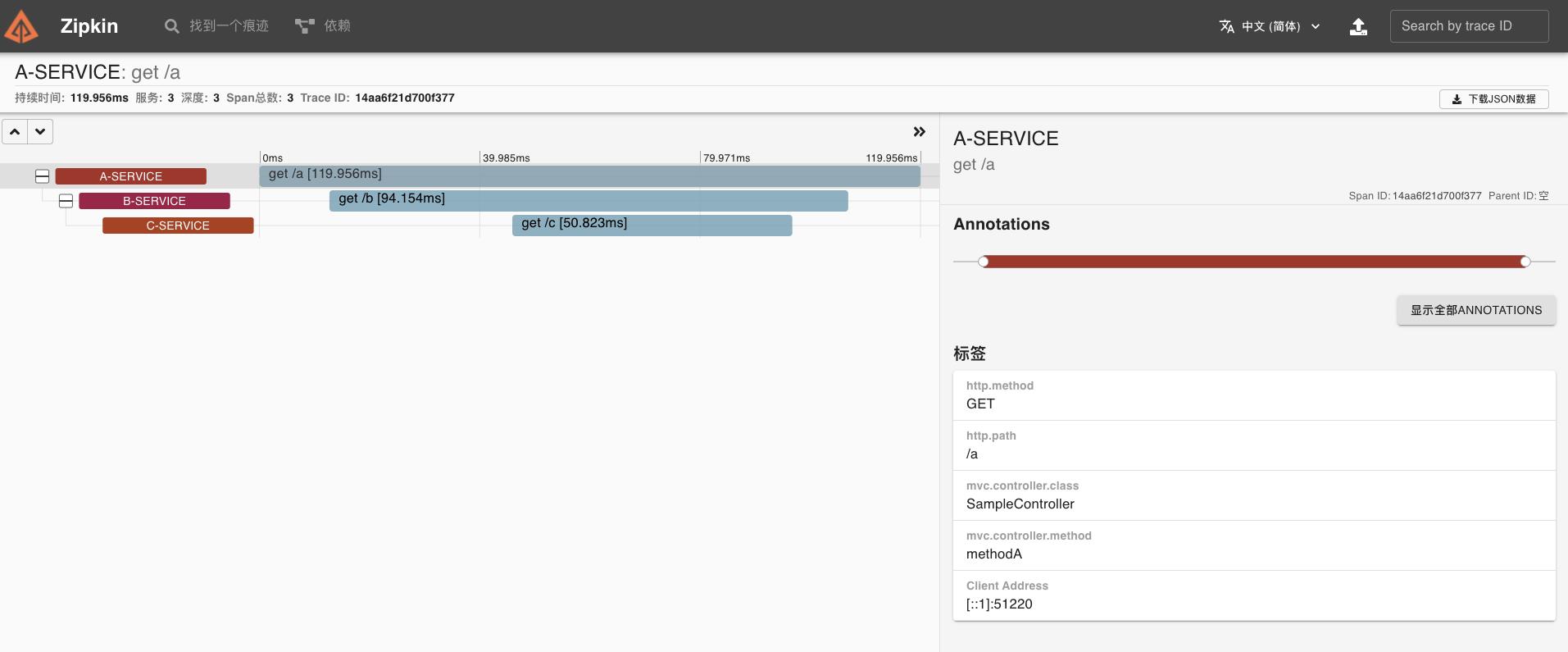
通过这个可视化 UI 可以非常直观的了解业务处理过程中服务间的依赖关系与处理时间、处理状态等信息,是故障分析的必要的工具。
说到这,想必大家已经对微服务链路追踪与 Sleuth+Zipkin 组合已经有了初步认识,下面咱们通过实例讲解如何在微服务架构中进行链路追踪改造。
这个过程分为两大部分:
- 在服务中加入 Spring Cloud Sleuth 生成链路追踪日志;
- 通过 ZipKin 收集链路最终日志,生产可视化UI。
四、准备工作
1、搭建 Zipkin 单机环境
这里我们使用 docker 快速启动 zipkin 演示实例。
#获取镜像
sudo docker pull openzipkin/zipkin
#运⾏镜像
sudo docker run -d -p 9411:9411 --name zipkin openzipkin/zipkin
2、搭建 naocos 单机环境
这里我们使用 docker 快速启动 nacos 演示实例。
#获取镜像
sudo docker pull nacos/nacos-server
#运⾏镜像
sudo docker run -d -p 8848:8848 --env MODE=standalone --name nacos nacos/nacos-server
五、微服务整合 Sleuth
这里创建 a、b、c 三个微服务工程,代码调用关系如下:

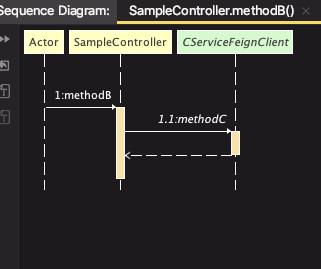
这里 A -> B -> C 服务间通过 Fegin 实现远程调用。
1、创建 SpringBoot 工程
首先创建创建 A、B、C 三个 Spring Boot 工程。
A、B 服务 pom.xml 依赖如下:
<!--Spring Web应用 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--Nacos 客户端 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--服务间通信组件OpenFeign -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
<version>2.2.6.RELEASE</version>
</dependency>
<!--添加Sleuth依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
<version>2.2.6.RELEASE</version>
</dependency>
C服务 pom.xml 依赖如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--添加Sleuth依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
<version>2.2.6.RELEASE</version>
</dependency>
因为调用关系是服务 A -> B -> C,所以在 A、B 两个服务中需要额外依赖 OpenFeign 实现服务间通信。
2、配置文件
然后,我们配置各服务的 application.yml,这三个配置文件除了服务名称与端口不同外,其他都一致。
server:
port: 7000
spring:
cloud:
nacos:
discovery:
server-addr: localhost:8848
username: nacos
password: nacos
application:
name: a-service
sleuth:
web: #Spring Cloud Sleuth 针对 Web 组件的配置项,例如说 SpringMVC
enabled: true
logging:
level:
root: debug #为演示需要,开启debug级别日志
3、实现核心代码
首先实现服务 C 的控制器:
@RestController
public class SampleController {
@GetMapping("/c")
public String methodC(){
String result = " -> Service C";
return result;
}
}
实现 methodC 方法产生响应字符串 “-> Service C”,方法映射地址 “/c”。
然后实现服务 B 的 CServiceFeignClient 通过 Feign 实现了 C 服务的通信客户端,方法名为 methodC。
@FeignClient("c-service")
public interface CServiceFeignClient {
@GetMapping("/c")
public String methodC();
}
控制器通过 methodB 方法调用 methodC 的同时为响应附加的字符串“-> Service B”,方法映射地址“/b”。
@Controller
public class SampleController {
@Resource
private CServiceFeignClient cService;
@GetMapping("/b")
@ResponseBody
public String methodB(){
String result = cService.methodC();
result = " -> Service B" + result;
return result;
}
}
最后,我们然后实现服务 A 的 BServiceFeignClient 通过 Feign 实现了 B 服务的通信客户端,方法名为 methodB。
@FeignClient("b-service")
public interface BServiceFeignClient {
@GetMapping("/b")
public String methodB();
}
控制器通过 methodA 方法调用 methodB 的同时,成为响应附加的字符串“-> Service A”,方法映射地址“/a”。
@RestController
public class SampleController {
@Resource
private BServiceFeignClient bService;
@GetMapping("/a")
public String methodA(){
String result = bService.methodB();
result = "-> Service A" + result;
return result;
}
}
这样我们的核心链路已经实现了,接下来我们做个测试验证下。
使用 Postman 请求下服务 A 的接口。
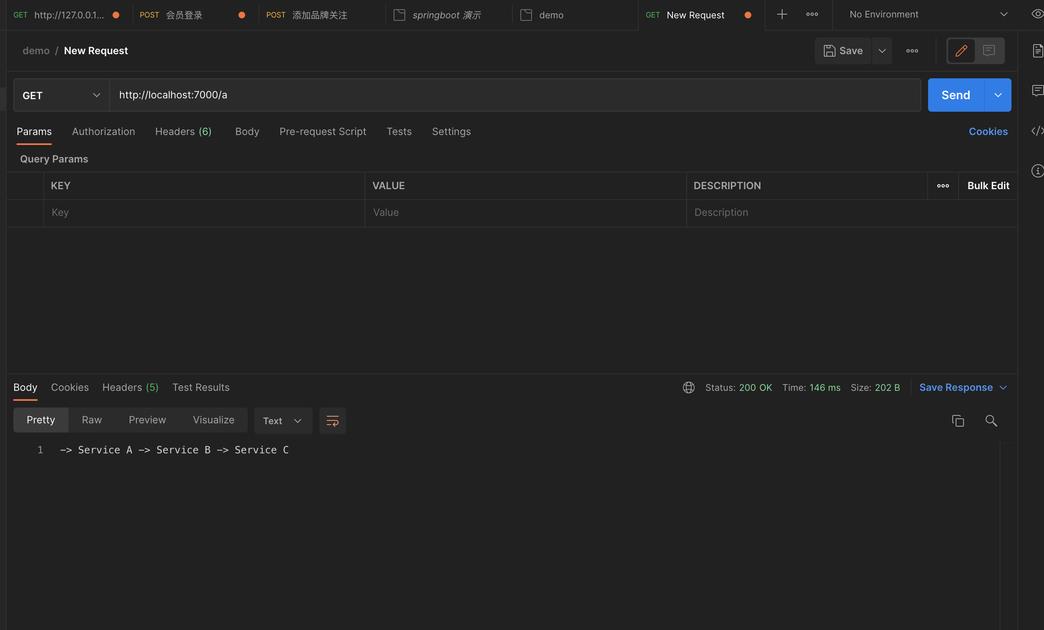
可以看到 ABC 三个服务按前后顺序依次产生结果,但在日志包含任何链路追踪数据。
2021-09-21 02:18:36.494 DEBUG [a-service,14aa6f21d700f377,14aa6f21d700f377,true] 40619 --- [nio-7000-exec-7] org.apache.tomcat.util.http.Parameters : Set encoding to UTF-8
2021-09-21 02:18:36.524 DEBUG [b-service,14aa6f21d700f377,828df12c1c851367,true] 40622 --- [nio-8000-exec-6] org.apache.tomcat.util.http.Parameters : Set encoding to UTF-8
2021-09-21 02:18:36.571 DEBUG [c-service,14aa6f21d700f377,ebd9892f8756801d,true] 40626 --- [nio-9000-exec-7] org.apache.tomcat.util.http.Parameters : Set encoding to UTF-8
虽然链路日志已产生,但如果在生产环境靠人工统计链路日志显然不现实,我们还需要部署分布式链路跟踪系统 Zipkin 来简化这个过程。
六、集成 Zipkin
Zipkin 服务端部署非常简单,可以通过官网快速上手。前面我们已经通过 docker 部署了一个演示实例。
1、引入客户端
首先我们需要每个服务集成 Zipkin 的客户端。
<!--Zipkin 客户端-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<version>2.2.6.RELEASE</version>
</dependency>
2、配置文件
然后,我们需要每个服务的 application.yml 配置 Zipkin 通信地址以及采样率。
server:
port: 7000
spring:
cloud:
nacos:
discovery:
server-addr: localhost:8848
username: nacos
password: nacos
application:
name: a-service
sleuth:
sampler: #采样器
probability: 1.0 #采样率,采样率是采集Trace的比率,默认0.1
rate: 10000 #每秒数据采集量,最多n条/秒Trace
web: #Spring Cloud Sleuth 针对 Web 组件的配置项,例如说 SpringMVC
enabled: true
zipkin: #设置zipkin服务端地址
base-url: http://127.0.0.1:9411
logging:
level:
root: debug #为演示需要
注意配置项:
spring.sleuth.sampler.probability是指采样率,假设在过去的 1 秒服务产生了 10 个 Trace,如果采用默认采样率 0.1 则代表只有其中1条会被发送到 Zipkin 服务端进行分析整理,如果设为 1,则 10 条 Trace 都会被发送到服务端进行处理。spring.sleuth.sampler.rate指每秒最多采集量,说明每条最多允许采集多少条 Trace,超出部分将直接抛弃。
3、运行效果
服务都设置好后,启动应用,重新测试服务 A 接口,然后打开 Zipkin 服务端 UI 界面 http://localhost:9411,查看调用链路。
点击“Run Query”。
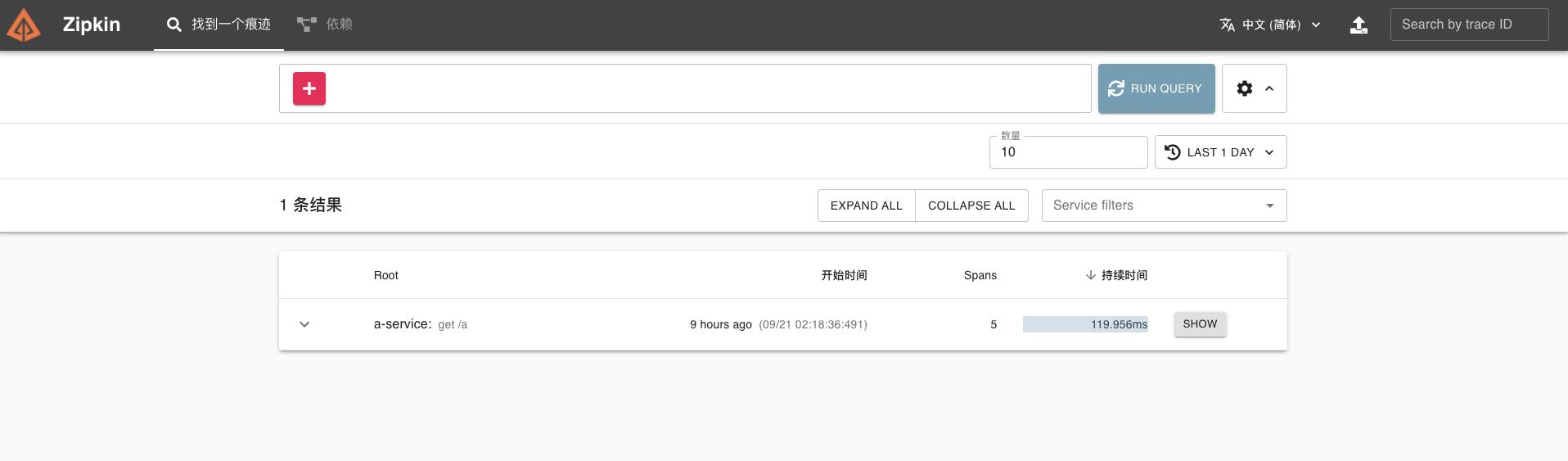
点击“show”,便会出现对应的链路调用图及详细的链路。
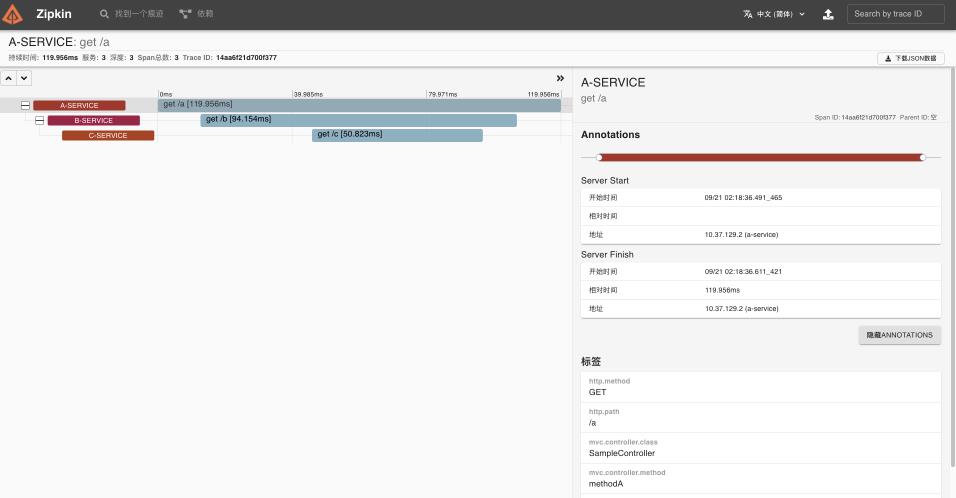
如果点击对应的“依赖”,还可以看到更详细的拓扑关系内容。
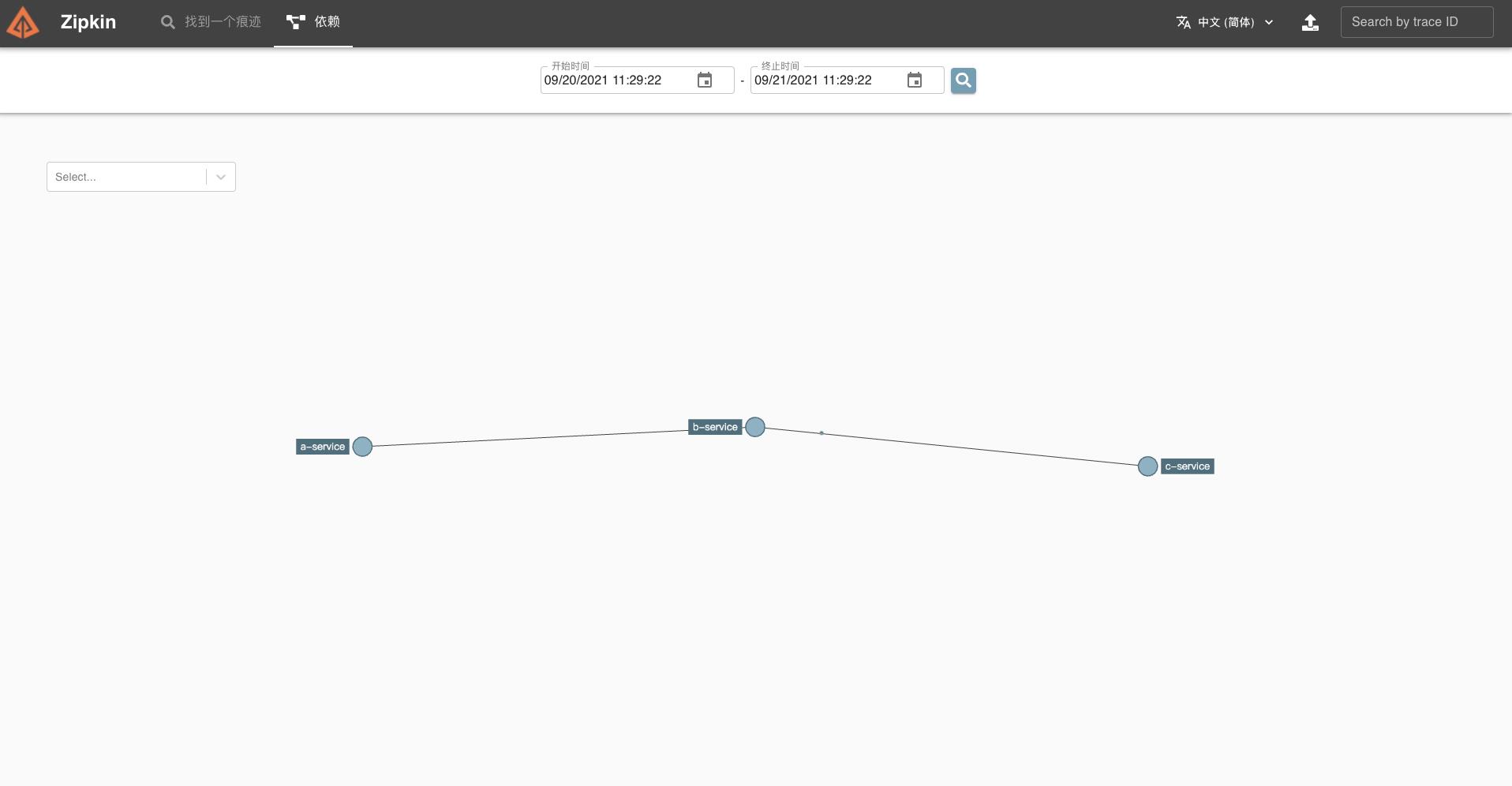
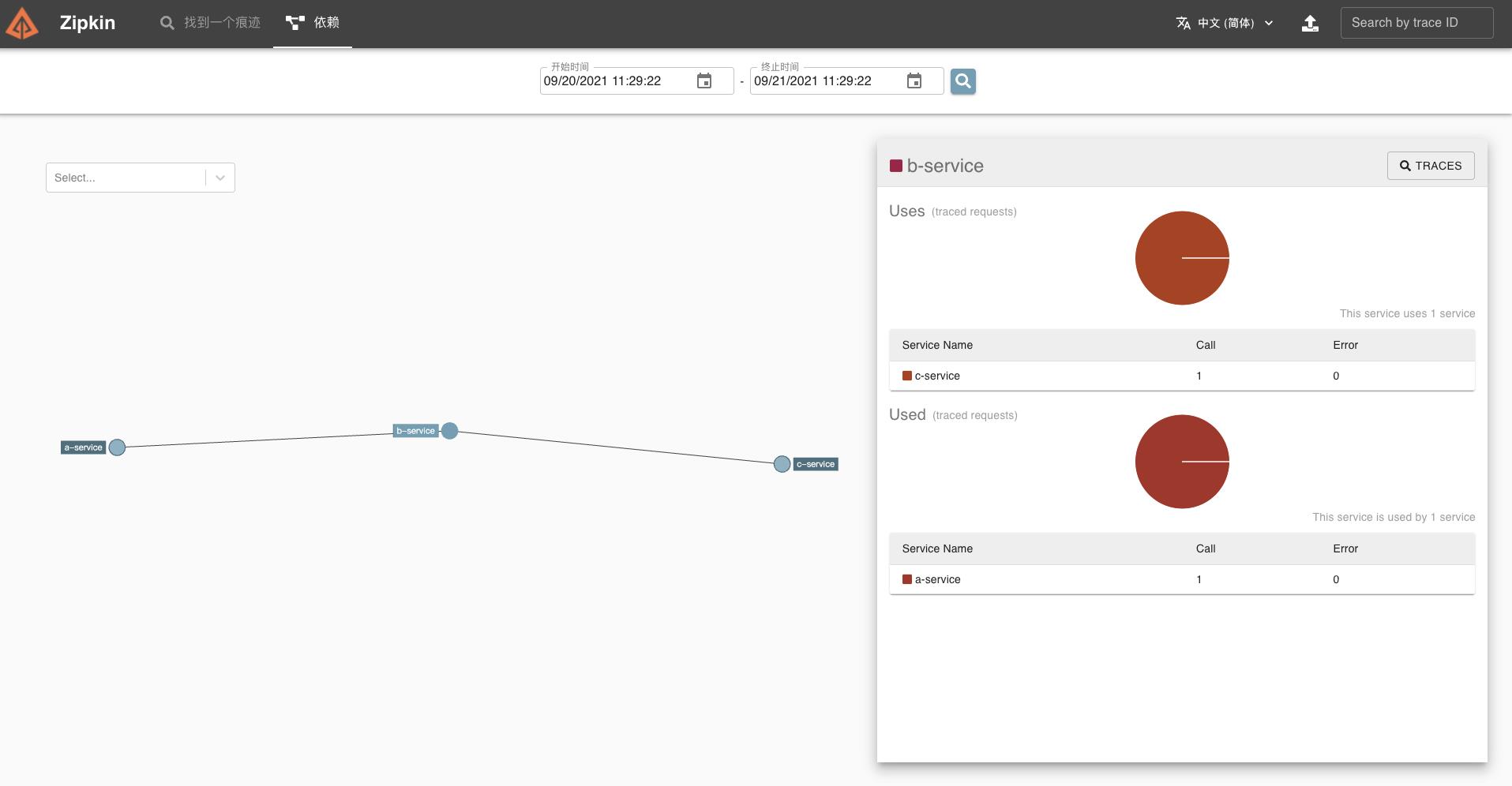
点击对应的服务节点,可以查看服务调用的统计信息。
如果我们主动停掉服务 C 呢,会是什么样的情况呢?
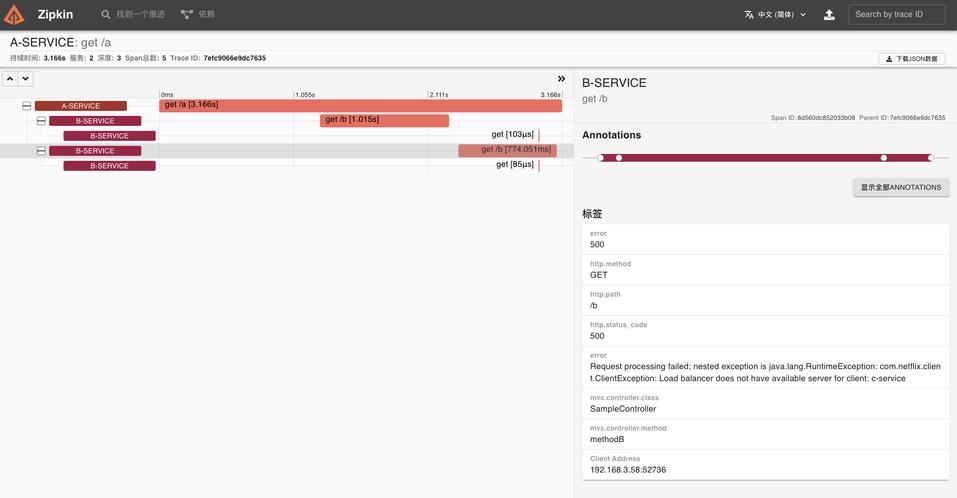
我们可以看到 Zipkin 已经在 error 里面提示故障原因了,说明服务 C 没有可用的实例导致处理失败。
七、小结
这一课时我们进行了案例实战,选择当前流行微服务框架 SpringCloud 作为示例,演示如何在微服务中集成 Sleuth + Zipkin,同时模拟了异常情况。
源码地址:
以上是关于Sleuth+Zipkin 实现 SpringCloud 链路追踪的主要内容,如果未能解决你的问题,请参考以下文章
Spring Cloud Sleuth + zipkin 实现服务追踪
spring-cloud-sleuth-zipkin实现微服务的链路跟踪
Spring Cloud全链路追踪实现(Sleuth+Zipkin+RabbitMQ+ES+Kibana)
十springcloud之展示追踪数据 Sleuth+zipkin
Java之 Spring Cloud 微服务的链路追踪 Sleuth 和 Zipkin(第三个阶段)SpringBoot项目实现商品服务器端是调用