推荐系统GBDT+LR模型
Posted 天泽28
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统GBDT+LR模型相关的知识,希望对你有一定的参考价值。
推荐系统(二)GBDT+LR模型
推荐系统系列博客:
在写这篇博客之前,一度纠结许久,到底该不该起这个标题,因为把GBDT+LR模型放在推荐系统系列里,似乎有些不妥,如果放到计算广告里那才是根正苗红,但目前推荐和广告在模型这一块几乎都是一样的,因此就暂且把这些CTR预估的模型放到推荐系统系列博客里了。
最近重读了Facebook发表在ADKDD’14上的论文《Practical Lessons from Predicting Clicks on Ads at Facebook》,从这篇论文标题中的“Practical Lessons” 二字就能看出这篇论文诞生于工业实践,论文确实干货满满,在模型这一块就是个GBDT+LR,简单明了(知道了这个范式之后认为朴素直白,但能想到这个范式不简单),在论文中也没有用太多笔墨来赘述,但珍贵的是大量工业实践中需要用到的点被尽数。
在介绍这篇论文之前,我们先来回想下CTR预估模型的发展史(参见博客:推荐系统(一)推荐系统整体概览),在2014年之前工业界CTR预估模型基本是LR的天下,自LR开始,**CTR预估模型演化的一条主线在于如何得到更有用的特征?**我用的词为“得到”,那么就基本有两种方式:人工的方式和模型自动的方式。显然,更有用的特征就是 交叉特征,要想得到交叉特征最简单的方式就是人工的去组合(这个等到介绍FM模型时再赘述),其实交叉特征是个永恒的主题,即使DNN能够自动学习到一些隐含的高阶特征,在百度的推荐场景下,人工显式的交叉特征依然是非常有效的手段,尤其是用户侧特征和item侧特征的交叉。Facebook巧妙的利用树模型进行特征组合,**GBDT+LR的核心思想用一句话即可描述:利用GBDT自动进行特征交叉,然后把交叉特征输入到LR中进行模型训练。**需要注意的是,这个模型实际上是两阶段的,GBDT仅进行特征交叉,其他的并不会和LR产生任何关联。
这篇博客主要把这篇论文中介绍的一些要点拿出来逐点过一下:
一、模型结构
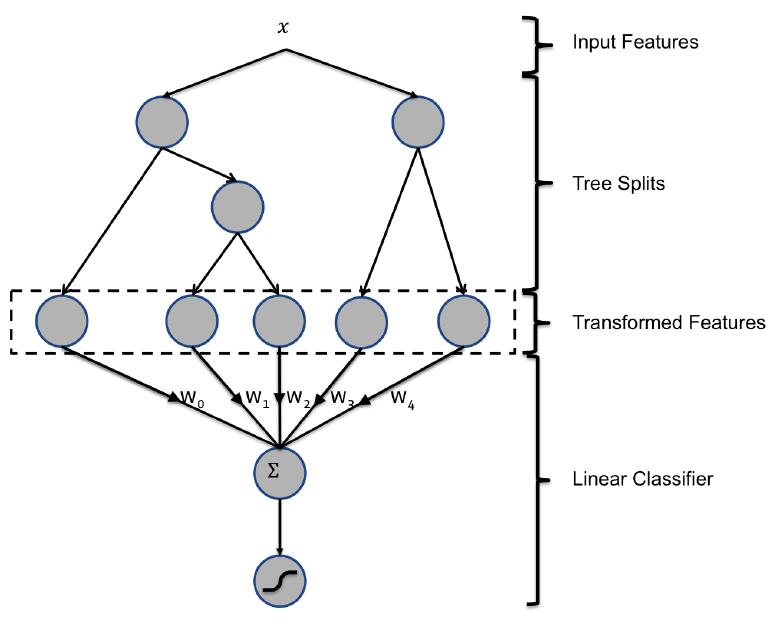
这个模型结构如上图所示,结构倒是很简单,基本一眼就能看明白,但对于一些细节,可能大多数人有时候还会云里雾里。一直觉得讲解某个东西最好的方式,就是上例子。因此直接上例子,如下图所示,这棵提升树包含了4棵子树,每棵树子树的叶子节点数量分别为4,6,7,5,树最大深度为3。

来一条样本,三个特征分别为[13. 19. 85.6],按照4棵树的结构走一发,叶子节点从左往右编号,发现这一条样本最终落在子树1的第2个叶子节点上,子树2的第2个叶子节点上,子树3的第2个叶子节点上,子树4的第1个叶子节点上。这四棵子树的叶子节点个数分别为4,6,7,5。因此,最终的输出向量为 [0,1,0,0, 0,1,0,0,0,0, 0,1,0,0,0,0,0, 1,0,0,0,]。然后此向量会输入到LR中,进行模型的训练。因此,我们能够发现,子树的高度决定了特征交叉的阶数,在本例里子树的高度为3,则进行了3次节点的分裂,因此,最终的叶子节点实际上是进行了三阶特征交叉,比如子树1中最终落入的叶子节点分裂路径为:x[2]<=87.25#x[1]<=18.54#x[1]<=21.59。
二、模型评价指标
这篇论文,Facebook采用了Normalized Entropy(NE)和Calibration作为评价指标。具体来看NE的公式为:
N
E
=
−
1
N
∑
i
=
1
n
(
1
+
y
i
2
l
o
g
(
p
i
)
+
1
−
y
i
2
l
o
g
(
1
−
p
i
)
)
−
(
p
∗
l
o
g
(
p
)
+
(
1
−
p
)
∗
l
o
g
(
1
−
p
)
)
NE = \\frac{-\\frac{1}{N}\\sum_{i=1}^n(\\frac{1+y_i}{2}log(p_i) + \\frac{1-y_i}{2}log(1-p_i))}{-(p*log(p) + (1-p)*log(1-p))}
NE=−(p∗log(p)+(1−p)∗log(1−p))−N1∑i=1n(21+yilog(pi)+21−yilog(1−pi))
其中,
y
i
y_i
yi为样本的真实label,
p
i
p_i
pi为预估的CTR,
p
p
p为训练集上的真实平均CTR。
Calibration这个指标,其实和COPC就是一样的,唯一不同的是
c
o
p
c
=
真
实
C
T
R
预
估
C
T
R
copc=\\frac{真实CTR}{预估CTR}
copc=预估CTR真实CTR,而Calibration则返回来,为预估CTR/真实CTR。
值得一提的是现在对于广告CTR模型来说,业界比较常用评估指标为AUC和COPC。在推荐里一般只用AUC这个指标,因为推荐模型追求的是模型的排序能力,只要排序准确,PCTR都偏高或者都偏低,并不会影响到item之间的序,因此也就不影响AUC。但是广告不一样,CTR直接涉及到钱,因此不仅追求排序能力,还要求预估的准确,因此有了COPC这个评价指标。
三、模型训练学习率
在进行LR模型的训练时,论文对比了几种优化算法,分别为:
Per-Coordinate Learning Rates
先来看看Per-Coordinate Learning Rates的公式:
η
t
,
i
=
α
β
+
∑
j
=
1
t
▽
j
,
i
2
\\eta_{t,i} = \\frac{\\alpha}{\\beta + \\sqrt{\\sum_{j=1}^t\\bigtriangledown_{j,i}^2}}
ηt,i=β+∑j=1t▽j,i2α
这个学习率方法来自于谷歌那篇大名鼎鼎的著作FTRL [2],先说下上面公式中几个符号的含义:
η
t
,
i
\\eta_{t,i}
ηt,i为第t次迭代时第i个特征的学习率,
α
\\alpha
α和
β
\\beta
β为两个可调的参数,在谷歌的那篇论文中,建议
β
=
1
\\beta=1
β=1。
▽
j
,
i
2
\\bigtriangledown_{j,i}^2
▽j,i2为第j次迭代时第i个特征的梯度。
实际上,从这个公式能够发现,当一个特征出现的次数较多时,说明此时这个特征参数训练的已经比较充分了,因此学习率可以比较低一点;但当一个特征出现的次数较少时,说明此时训练的还不够充分,所以需要较大的学习率来尽快的收敛。这个做法一个非常大的好处是使得那些低频长尾特征也能学到一个比较好的参数。在我们(dudududu)的实际经验中发现,即使简单的使用除以每个特征的曝光次数的开方(其实就是论文中提到的Per-weight square root learning rate),也能够使得AUC提升百分位2个点左右(大家可以去看看deepFM相比较LR AUC提升了多少\\偷笑)。 Facebook这篇论文实验中也证实了在他们的场景下,Per-Coordinate Learning Rates也是取得最好的结果。
论文中陈述的其他几种学习率方法,这里就直接简略不在介绍了。
四、在线工程的trick
这篇论文在工程方面有个trick
- 使用GBDT进行特征组合,会导致模型周期拉长,导致模型更新不及时,效果变差该如何解决?
关于上面这个问题,Facebook在论文给出的做法是
- GBDT部分天级别甚至几天更新一次
- LR部分的参数online learning 实时的更新
五、样本采样
即使GBDT天级别甚至几天更新一次,但对于动辄几十亿样本量的大厂来说,模型训练依然面临比较大的挑战,因此Facebook这篇论文里做了一个负采样,但是做了负采样之后会导致样本分布发生变化,尤其是CTR发生变化,因此需要进行CTR校准还原,Facebook这里给出了校准公式:
q
=
p
p
+
(
1
−
p
)
/
w
q = \\frac{p}{p + (1-p)/w}
q=p+(1−p)/wp
其中,p为在采样后的pctr,w为负采样采样率,q为校准后的CTR。
六、一些思考
- 仅仅的使用GBDT进行特征组合,然后灌到LR中,相比较仅仅使用GBDT到底能够有多大的效果提升?这一点欢迎有过工业界真实经验的大佬们留言交流。
- 论文是否有所保留,所用特征,难道仅仅只是gbdt组合后的特征?原始的特征没有一起放进去训练?
七、简单实现
原本想用scikit-learn简单的实现一下gbdt+lr,但无意间发现一个问题。先来看看scikit-learn官方的gbdt+lr实现,其中最重要的一个点就是如何获取每个样本落到了每颗子树的哪个叶子节点上,官方GradientBoostingClassifier API中提供了一个函数apply,官方介绍为:Return the index of the leaf that each sample is predicted as. 我兴高采烈的以为发现了宝藏,其实官方给的demo以及目前网上所有用scikit-learn实现的gbdt+lr的demo中都使用了这个apply函数,可是这个apply函数真的是返回了样本落到的叶子节点的index吗? 答案是否定的也是肯定的,肯定的地方在于他确实返回了样本落到的叶子节点的index,否定的是他的叶子节点编号有问题,至少用于实现Facebook这篇gbdt+lr是有问题的。 再来回顾下Facebook这篇论文使用gbdt进行特征组合产生特征向量时的做法,叶子节点从左往右,样本命中了哪个叶子节点,向量对应位置置为1。而scikit-learn中子树编号,并不是只对叶子节点进行了编号,而是整棵树所有节点进行的编号。这样导致了使用apply函数返回的index是基于整棵子树的,而不是只是基于叶子节点的。
咱们来真实看一看:
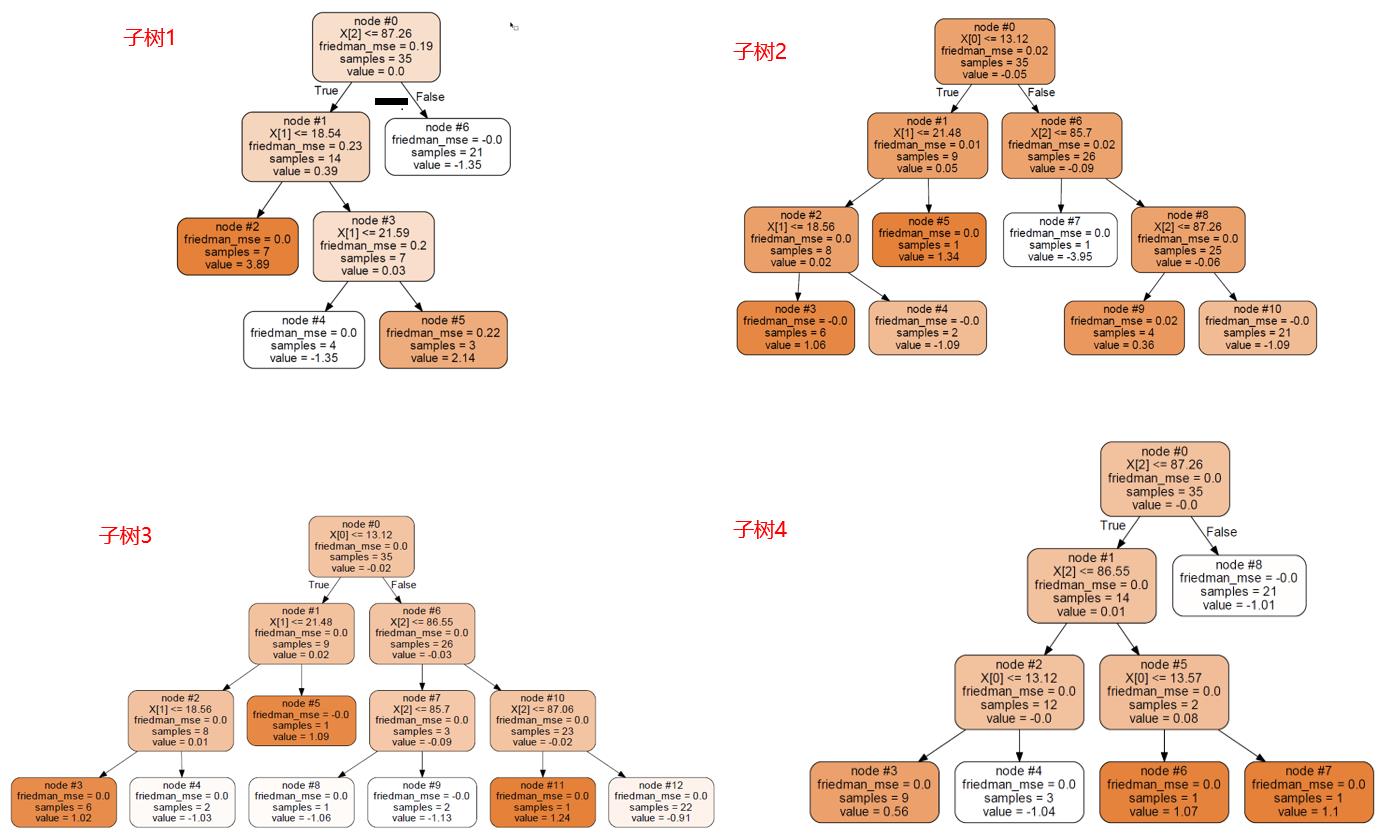
一目了然,编号基于整颗子树的。那么apply函数返回的index呢,来上代码:
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import GradientBoostingClassifier
cancer = load_breast_cancer()
clf = GradientBoostingClassifier(n_estimators=4, learning_rate=1.0, max_depth=3, random_state=0)
x = cancer.data[20:55, 0:3]
y = cancer.target[20:55]
clf.fit(x, y)
X_test = np.array([[13, 19, 88.6]])
# 获取每颗子树
for t in clf.estimators_:
# print(t[0].predict(X_test))
print(t[0].get_n_leaves()) # 输出每颗子树的叶子节点数量
# 返回样本落在的每颗子树的叶子节点的index
leaf_index = clf.apply(X_test)
print(leaf_index)
#==================
# print(t[0].get_n_leaves()) --> 4, 6, 7, 5
# print(leaf_index) --> 6, 4, 4, 8
# 返回的叶子节点的index超过叶子节点数量
# ================
从代码中能够看出使用apply返回的叶子节点的index明显超过叶子节点的数量。因此使用apply()函数去实现fb这篇论文中的gbdt+lr显然是有问题的,与论文描述不符。这样做会使得特征向量维度变大,拖慢训练速度。因此关于如何使用scikit-learn去实现论文的gbdt+lr,暂时未想到什么好的办法。
参考文献
[1]: Practical Lessons from Predicting Clicks on Ads at Facebook
[2]: Ad Click Prediction: a View from the Trenches
以上是关于推荐系统GBDT+LR模型的主要内容,如果未能解决你的问题,请参考以下文章