数据结构与算法学习笔记 线性表Ⅱ
Posted 临风而眠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法学习笔记 线性表Ⅱ相关的知识,希望对你有一定的参考价值。
数据结构与算法学习笔记(4) 线性表Ⅱ
文章目录
复习顺序表:

一.线性表的链式表示和实现
1.链式存储结构
-
结点在存储器中的位置是任意的,即逻辑上相邻的数据元素在物理上不一定相邻
-
线性表的链式表示又称为非顺序映像或链式映像
-
用一组物理位置任意的存储单元来存放线性表的数据元素
-
这组存储单元可以连续,也可以不连续,甚至零散分布在内存中的任意位置
-
链表中元素的逻辑次序和物理次序不一定相同
情境引入

链表的结点随意分布,但是还是要体现逻辑结构,于是存放了下一个元素的地址
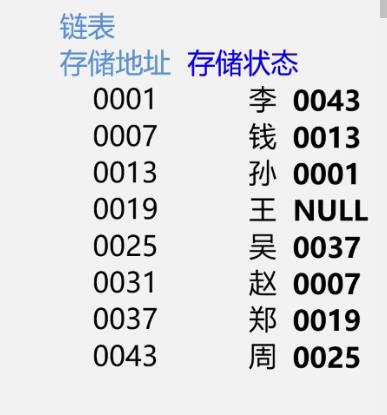

26个英文字母

H表示前面的是16进制地址
2.链式存储相关术语
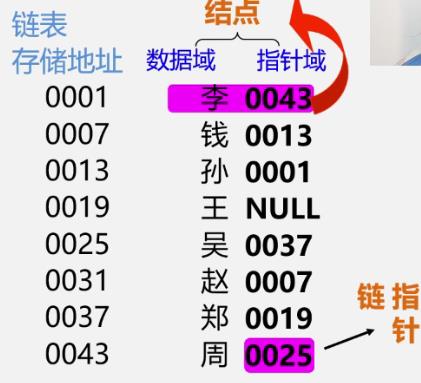
结点
- 数据元素在存储器中的存储映像
- 由数据域和指针域两部分构成
链表
-
n个结点由指针链组成一个链表
-
它是线性表的链式存储映像,称为线性表的链式存储结构
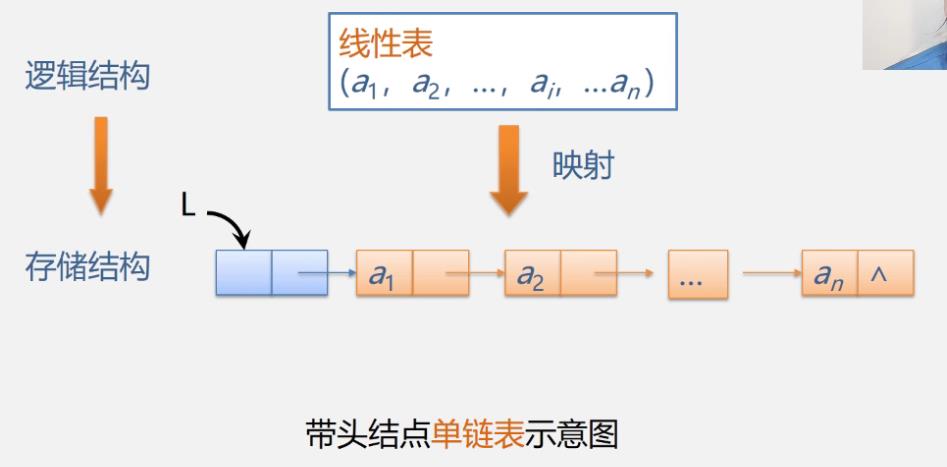
映射不一定是连续的,存储位置是任意随机的
通过存储前趋后继的地址来描述逻辑关系
单链表、双链表、循环链表

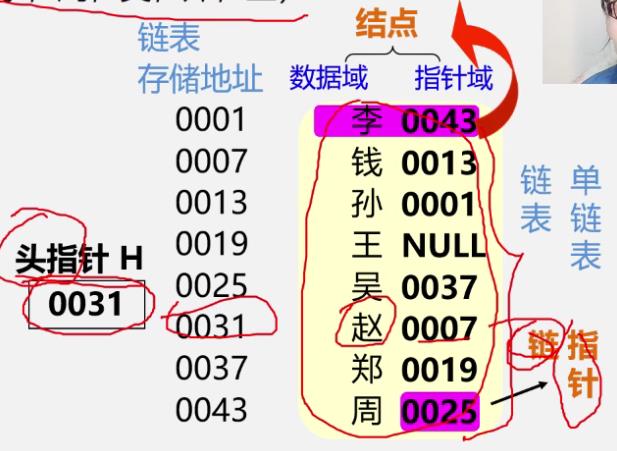
头指针、头结点和首元结点

- 头指针: 指向链表中第一个结点的指针
- 首元结点:链表中存储第一个数据元素 a 1 a_1 a1的结点
- 头结点: 在链表的首元结点之前附设的一个结点
单链表的两种形式
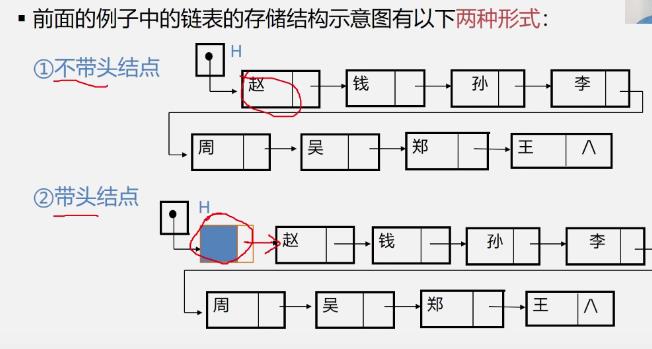
- 不带头结点,头指针直接指向第一个数据元素
- 带头结点,头指针指向头结点,头结点存放第一个数据元素的地址
如何表示空表
- 无头结点时,头指针为空时表示空表
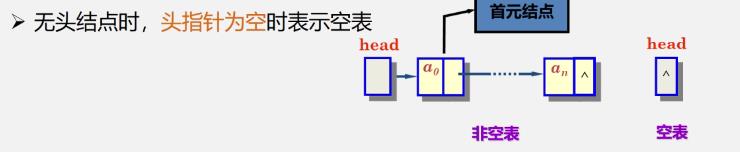
- 有头结点时,当头结点的指针域为空时表示空表

在链表中设置头结点的好处
-
便于首元结点的处理

-
便于空表和非空表的统一处理

头结点的数据域内是什么
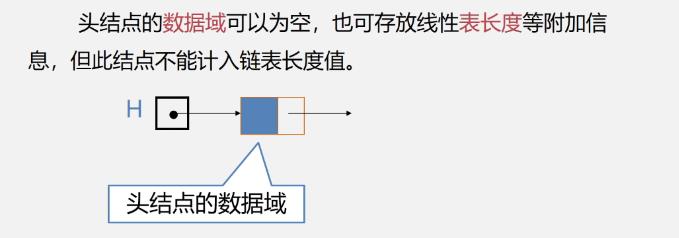
注意头结点不是数据元素,所以不能计入表长度
链表(链式存储结构的特点)

- 注意:

链表必须从头上一个一个往后找,找完前面的,才能找下一个
而顺序表每个元素的位置都能计算出来,所以可以随便找到
3.单链表
知识回顾:

- 带头结点的单链表

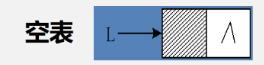
带头结点的单链表若为空表 头结点的指针域为空,后面没有元素
单链表的名称
- 单链表由表头唯一确定,因此单链表可以用头指针的名字来命名
- 若头指针名是L,则把链表称为表L
找到一个单链表只要找到头指针
单链表的存储结构

单链表的定义
typedef struct Lnode
{ //声明结点类型和指向结点的指针类型
ElemType data; //结点的数据域
struct Lnode *next; //结点的指针域, 指向struct Lnode类型的指针
//嵌套定义
} Lnode, *LinkList; //LinkList为指向结构体Lnode的指针类型
-
注意这里的Lnode 和LinkList都是类型
相当于:
struct Lnode{ ElemType data; struct Londe *next; }; typedef struct Lnode; typedef struct Lnode* LinkList;把
struct Lnode*重命名为LinkList,就可以用LinkList来简化定义Lnode*类型(指向结点的指针型)的变量了
-
定义链表L:
LinkList L -
定义结点指针p:
LNode *p- 虽然
Lnode *p与LinkList p等价(链表类型就是指向结点的指针),但还是常用LNode *p
- 虽然
-
例:存储学生学号、姓名、成绩的单链表结点类型定义如下:
typedef struct student { char num[8]; //数据域 char name[8]; //数据域 int score; //数据域 struct student *next; //指针域 } Lnode, *LinkList;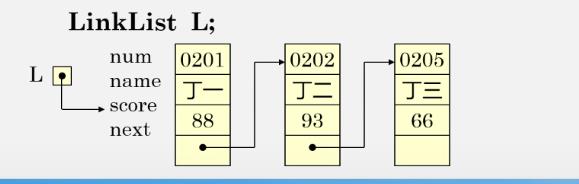
-
为了统一链表的操作,通常这样定义
-
先将数据域中所需的数据项定义为一个结构类型
typedef struct{ char num[8]; //数据域 char name[8]; //数据域 int score; //数据域 } ElemType; typedef struct student{ ElemType data; //数据域 struct student *next; //指针域 } Lnode, *LinkList;
-
-
单链表基本操作的实现
[单链表的初始化]
带头结点的单链表
-
即构造一个如图的空表

-
算法步骤:
- 生成新结点作为头结点,用头指针L指向头结点
- 将头结点的指针域置为空
-
算法描述
-
下面的LinkList就是

相当于Lnode*
-
一开始L是没有的,用L去获得分配好的空间,所以用引用型变量
Status InitList_L(LinkList &L){ //相当于Lnode *&L,Lnode *&L是一个指向指针的引用 L = new LNode; //或 L=(LinkList)malloc(sizeof(LNode)) //都表示在从内存中找到一块空间,然后把这块空间的地址赋值给L L->next = NULL; //指针变量操作其成员用-> return OK; } -
不带头结点的链表
- 头指针指向空
LinkList L;
void InitList(LinkList &L){
L=NULL;
}
InitList(&L)
[判断链表是否为空]
带头结点
-
空表:链表中无元素,称为空链表(头指针和头结点仍然在)
-
算法思路:
-
若L是空表,头结点的指针域为空
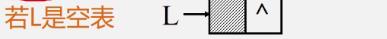
-
-
算法实现
int ListEmpty(LinkList L){ //若L为空表,返回1,否则返回0
if(L->next) //非空
return 0;
else
return 1;
}
这里只是判断链表是否是空表,不涉及到改变链表,所以不需要引用
不带头结点
int ListEmpty(LinkList L){ //若L为空表,返回1,否则返回0
if(L==NULL) //非空
return 1;
else
return 0;
}
[单链表的销毁]
-
链表销毁后不存在
-
算法思路:从头指针开始,依次释放所有结点

-
如何让一个指针指向下一个结点?
- 就是把L的next域重新赋值给L
- next域里的值就是下一个结点的地址
- 当L指向下一个节点,就可以把p删掉了
- 就是把L的next域重新赋值给L
-
继续执行

-
-
算法实现
Status DestroyList_L(LinkList &L){ //销毁单链表L Lnode *p; //或LinkList p; while (L) { p = L; L = L->next; //将头指针指向下一个结点 delete p; } return OK; }
[清空链表]

-
算法思路:依次释放所有结点,并将头结点指针域设置为空
- 从首元结点开始

-
注意和销毁链表不同
- 销毁链表p=L是从头结点开始
-
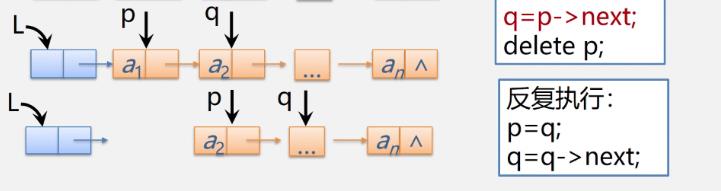
-

-
算法实现
Status ClearList(LinkList & L){ //将L重置为空表 Lnode *p, *q; //或LinkList p,q; p = L->next; while(p){ q = p->next; delte p; p = q; } L->next = NULL; //头结点指针域置为空 return OK; }
[求单链表的表长]
注意头结点不是数据元素,不能计入表长
-
算法思路:从首元结点开始,依次计数所有结点
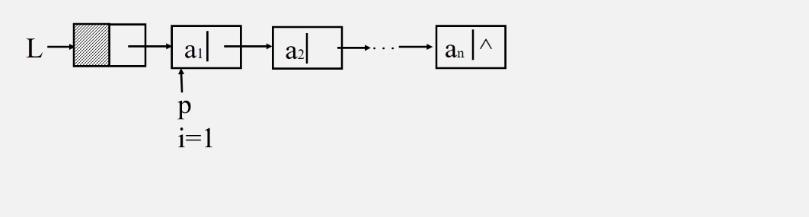
先指向首元,不为空,i就加一
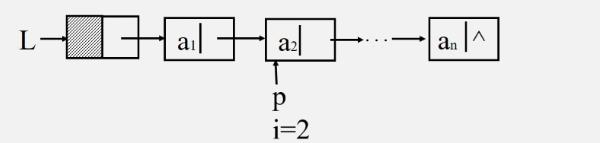
继续下去

-
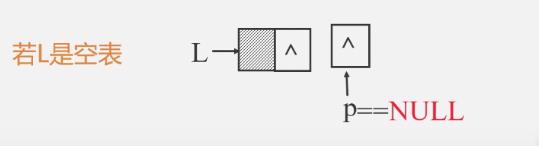
若L是空表,那头结点的next成员直接就是空
把头结点的next赋值给p p=L->next
表长为0
-
算法实现
int ListLength_L(LinkList L){//返回L中数据元素个数 Lnode *p; p=L->next; //p指向第一个结点 i=0; while(p){ //遍历单链表,统计结点个数 i++; //不为空就加1 p=p->next; //p->next是p指向的结点的next成员,存放的是p指向的结点的下一个结点的地址 //p->next赋值给p就是让p再指向下一个结点 } //当p指向尾结点的时候,尾结点的next成员的值为NULL return i; }
超级折腾!!!!!!!!
柳暗花明
关于这里的p=L->next,一直很疑惑,认为应该是L->next->next,然后看到了这个博主写的文章,恍然大悟:
👉文章链接
要注意头指针的数据类型是LinkList(或Lnode*),而普通结点的数据类型是Lnode, Lnode*是指向Lnode数据类型的指针
复习结构体指针
👉这里还要复习一下结构体指针
指针引用结构体变量成员的方式是:
(*指针变量名).成员名
或者
指针变量名->成员名
头指针L指向的是头结点
复习指针给指针赋值
指针赋值都给忘了,指针也是变量,就是把变量的值赋给另一个变量嘛
下面把指针q的值赋给指针p
#include <stdio.h>
int main()
{
int number = 5;
int *q =&number;
// int *p =q;
int *p = NULL;
p = q;
printf("%d\\n",*p);
printf("%d\\n",*q);
printf("%p\\n",&number);
printf("%p\\n",p);
printf("%p\\n",q);
printf("%p\\n",&p);
printf("%p\\n",&q);
return 0;
}

赋值之后,他们本身的地址不同,但是存放的值相同,指向的变量相同
醒悟过程
呜呜呜呜😭😭😭,终于发现自己为啥一直不能理解了!
指针没学好!
之前居然以为->是取自己本身的成员,但它是结构体指针引用它所指向的结构体变量的成员
之前理解的L->next是把L也想成了有指针域和数据域的结构体了,然后以为->就是.的意思,啊啊啊,我真的伞兵,之前以为L->next代表的是L的成员变量next,L的成员变量next存放头结点的地址,所以之前会一直误以为p=L->next是让p指向头结点!
现在懂了!大一学C语言的同学们一定要规格严格,功夫到家!!! 不要像我这样!
L->next是头结点的指针域成员,,那么L->next的值是啥呢?
L->next还是个结构体指针,指向的是下一个结点(结构体变量),L->next的值就是的下一个结点的地址,而这个结点就是首元结点
那么L->next->next是啥呢?
L->next是指向首元结点的结构体指针,L->next->next就是引用了首元结点的next成员,首元结点的next成员还是一个结构体指针指向的是首元结点的下一个结点
若像之前那样错误地认为应该是 p=L->next->next,那就是把首元结点的成员next指针赋值给了指针p,首元结点的指针域成员next存放的是首元结点的后一个结点的地址,那样的话,p就存放首元结点的后一个结点的地址了,就指向的是首元结点的后一个结点
😭 😭 😭
之前还似懂非懂的以为 p->next指向p->next->next ,这句话的说法就是大错特错,指向的是结点,->是用指针引用结构体变量成员的方式!!!!
remake吧!
其实就是指针没学好 ,ԾㅂԾ,
[取第i个元素的值]
基础知识回顾
类型定义
typedef struct LNode{ ElemType data; struct LNode *next; }LNode,*LinkList;变量定义
LinkList L; //定义头指针(整个链表) LNode *p,*s; //指向结点的指针重要操作
p=L; //p指向头结点 s=L->next; //s指向首元结点 首元结点的地址在头结点的next域, 头结点的next域就是L->next p=p->next; //p指向下一结点 下一个结点的地址就存在当前结点的next域
顺序表获取第i个元素
elem[i-1],随机存取
-
算法思路

-
算法步骤

-
算法实现
Status GetElem_L(LinkList L,int i,ElemType &e){ //获取线性表L中的某个数据元素的内容,通过变量e返回 p=L->next;//指向首元结点 j=1; //初始化 while(p&&j<i){ //向后扫描,直到p指向第i个元素(j==i)或p为空 //如果一开始给的i比1小那也不进入这个循环 p=p->next; //指向下一个结点 ++j; } //退出while循环就三种情况: j==i退出了;p为空;一开始i给的是0,-1等数据 //如果指针为空或者出现j大于i的情况 ,就说明i的位置不对,就返回ERROR if(!p||j>i) return ERROR; //第i个元素不存在 //找到了就赋值给e e=p->data; return OK; }
[按值查找]
根据指定数据获取该数据所在的位置(该数据的地址)
-
算法步骤

-
算法描述
Lnode *LocateElem_L(LinkList L,Elemtype e){ //在线性表L中查找值为e的数据元素 //找到就返回L中值为e的数据元素的地址,查找失败返回NULL p=L->next; //先指向首元结点 while(p&&p->data!=e){ //p不为空且data域的值不等于e,就继续循环 p=p->next; } return p; //不管找没找到,返回p就行 没找到返回的就是空 }
根据指定数据获取该数据所在的位置序号(是第几个数据元素)
-
算法描述
//在线性表L中查找值为e的数据元素的位置序号 int LocateElem_L(LinkList L,Elemtype e){ //返回L中值为e的数据元素的位置序号,查找失败返回0 p=L->next;//先指向首元结点 j=1; while(p&&p->data!=e) { p=p->next; ++j; } if(p) //找到了就指向找到的结点,没找到就指向空结点 { return j; } else return 0; }
[插入结点]
在第i个结点前插入值为e的新结点
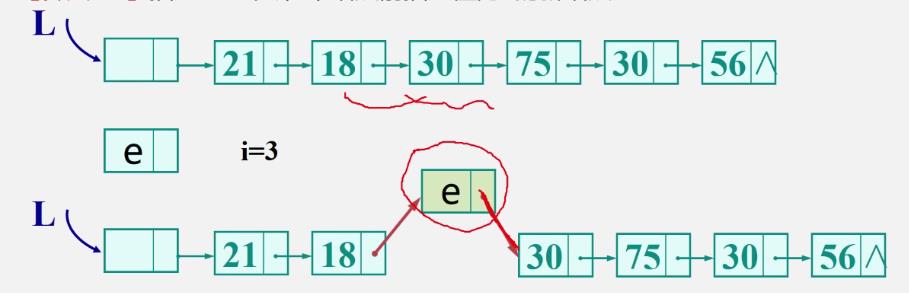
-
算法步骤
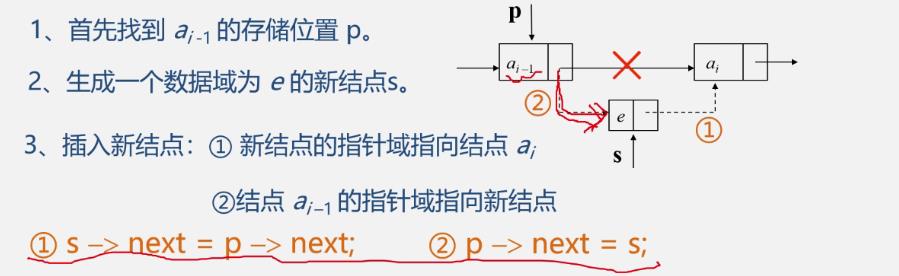
- 关键
- a i a_i ai接入新结点的后面
- 新结点接在 a i − 1 a_{i-1} ai−1后面
- 关键

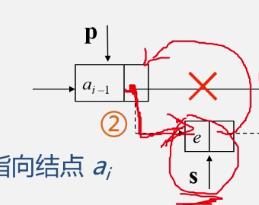
若要互换,得再多用一个指针
-
算法描述
//在链表L中第i个元素之前插入数据元素e Status ListInsert_L(LinkList &L,int i,ElemType e){ p=L; //指向头结点 j=0; while(p&&j<i-1) //寻找第i-1个结点,p指向第i-1个结点 //如果本身是空链表或者当p已经遍历完了,为空结点了,还没找到,那就要退出循环 { p=p->next; j++; } //找完之后有两种情况 if(!p||j>i-1) //i大于表长+1或者小于1,插入位置非法 return ERROR; s = new LNode; //生成新结点s,将结点s的数据域置为e s->data = e; s->next=p->next; p->next=s; return OK; }
[删除结点]
删除第i个节点
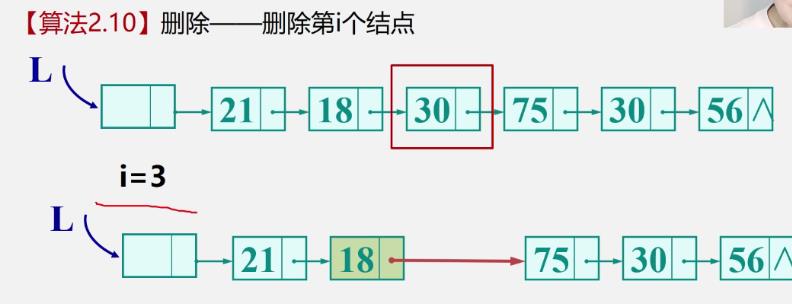
-
算法步骤
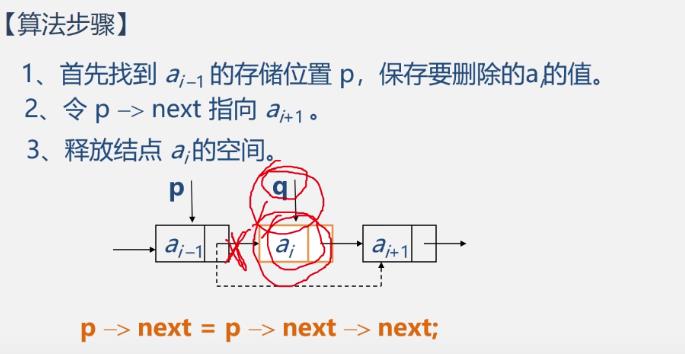
-
算法描述
//将线性表L中第i个数据元素删除 Status ListDelete_L(LinkList &L,int i,ElemType &e){ p=L; j=0; while(p->next&&j<i-1){ p=p->next; ++j; }//寻找第i个结点,并令p指向其前驱 if(!(p->next)||j>i-1) //删除第小于0个(j>i-1) 或者大于n都不可(空) return ERROR; //删除位置不合理 q=p->next; //临时保存被删除结点的地址以备释放 p->next=q->next; //改变删除结点前驱结点的指针域 e=q->data; //保存删除结点的数据域 delete q; //释放删除结点的空间 return OK; }
[单链表查找、插入、删除算法时间效率分析]
-
查找
Lnode *LocateElem_L(LinkList L, Elemtype e){ //在线性表L中查找值为e的数据元素 //找到,则返回L中值为e的数据元素的地址,查找失败返回NULL p=L->next; while(p&&p->data!=e){ p=p->next; } return p; }
-
插入和删除

[单链表的建立]
头插法
-
元素插入在链表头部,也叫前插法



L = new LNode; //或C语言中: L = (LinkList)malloc(sizeof(LNode));
L -> next = NULL;
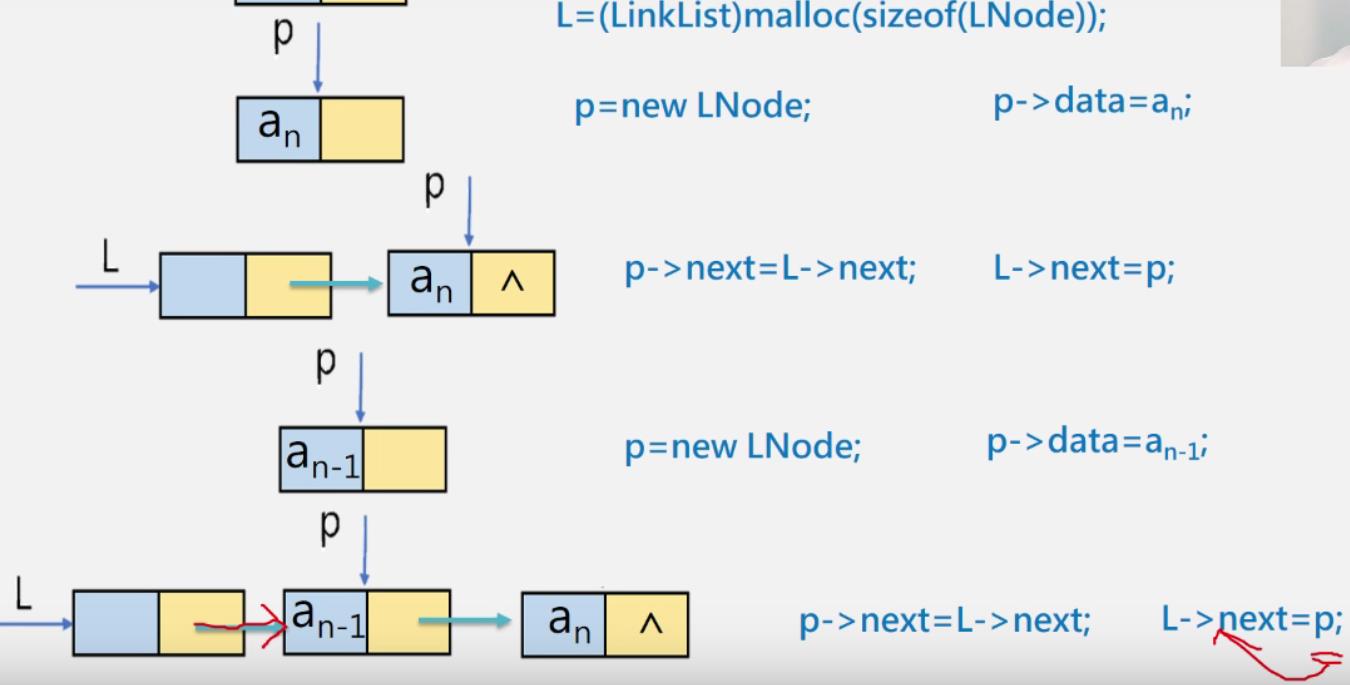
-
算法描述
关键:
把后面所有结点接在新结点的后面,再把新结点接在头结点的后面
反复n次,把n个元素都插进去
void CreateList_H(LinkList &L,int n){ L = new LNode; L->next = NULL; //建立一个带头结点的单链表 for(i=n;i>0;i--){ p=new LNode; //生成新结点 C写法: p=(LNode*)malloc(sizeof(LNode)); cin>>p->data; //输入元素值 C写法 scanf(&p->data) p->next = L->next; //后面的结点接在新结点的后面 L->next = p; //新结点接在头结点的后面 } } -
算法时间复杂度: O ( n ) O(n) O(n)
尾插法

-
算法描述
void CreateList_R(LinkList &L,int n){ L= new LNode; L->next=NULL; r=L; //尾指针r指向头结点 for(i=0;i<n;++i){ p=new LNode; //生成新结点 cin>>p->data; //输入元素值 p以上是关于数据结构与算法学习笔记 线性表Ⅱ的主要内容,如果未能解决你的问题,请参考以下文章