Hadoop 数据压缩
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop 数据压缩相关的知识,希望对你有一定的参考价值。
Hadoop 数据压缩
1. 概述
1)压缩的好处和坏处
- 压缩的优点:以减少磁盘 IO、减少磁盘存储空间。
- 压缩的缺点:增加 CPU 开销。
2)压缩原则
(1)运算密集型的 Job,少用压缩
(2)IO 密集型的 Job,多用压缩
2. MR 支持的压缩编码
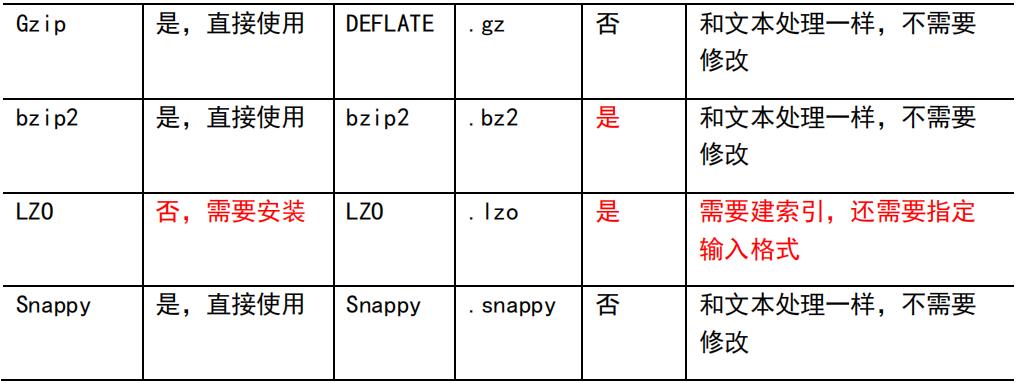
1)压缩算法对比介绍

2)压缩性能的比较

http://google.github.io/snappy/
Snappy is a compression/decompression library.
It does not aim for maximum compression, or
compatibility with any other compression library; instead,
it aims for very high speeds and
reasonable compression. For instance, compared to the fastest mode of zlib, Snappy is an order of
magnitude faster for most inputs, but the resulting compressed files are anywhere from 20% to 100%
bigger.
On a single core of a Core i7 processor in 64-bit mode, Snappy compresses at about 250
MB/sec or more and decompresses at about 500 MB/sec or more.
3. 压缩方式选择
压缩方式选择时重点考虑:压缩/解压缩速度、压缩率(压缩后存储大小)、压缩后是否可以支持切片。
3.1 Gzip 压缩
- 优点:压缩率比较高;
- 缺点:不支持 Split;压缩/解压速度一般;
3.2 Bzip2 压缩
- 优点:压缩率高;支持 Split;
- 缺点:压缩/解压速度慢。
3.3 Lzo 压缩
- 优点:压缩/解压速度比较快;支持 Split;
- 缺点:压缩率一般;想支持切片需要额外创建索引。
3.4 Snappy 压缩
- 优点:压缩和解压缩速度快;
- 缺点:不支持 Split;压缩率一般;
3.5 压缩位置选择
压缩可以在 MapReduce 作用的任意阶段启用。

4. 压缩参数配置
1)为了支持多种压缩/解压缩算法,Hadoop 引入了编码/解码器

2)要在 Hadoop 中启用压缩,可以配置如下参数


5. 压缩实操案例
5.1 Map 输出端采用压缩
即使你的 MapReduce 的输入输出文件都是未压缩的文件,你仍然可以对 Map 任务的中间结果输出做压缩,因为它要写在硬盘并且通过网络传输到 Reduce 节点,对其压缩可以提高很多性能,这些工作只要设置两个属性即可,我们来看下代码怎么设置。
1)给大家提供的 Hadoop 源码支持的压缩格式有:BZip2Codec、DefaultCodec
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
// 开启 map 端输出压缩
conf.setBoolean("mapreduce.map.output.compress", true);
// 设置 map 端输出压缩方式
conf.setClass("mapreduce.map.output.compress.codec",
BZip2Codec.class,CompressionCodec.class);
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
2)Mapper 保持不变
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context
context)throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 循环写出
for(String word:words){
k.set(word);
context.write(k, v);
}
}
}
3)Reducer 保持不变
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
int sum = 0;
// 1 汇总
for(IntWritable value:values){
sum += value.get();
}
v.set(sum);
// 2 输出
context.write(key, v);
}
}
5.2 Reduce 输出端采用压缩
基于 WordCount 案例处理。
1)修改驱动
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.DefaultCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.io.compress.Lz4Codec;
import org.apache.hadoop.io.compress.SnappyCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 设置 reduce 端输出压缩开启
FileOutputFormat.setCompressOutput(job, true);
// 设置压缩的方式
FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
// FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
// FileOutputFormat.setOutputCompressorClass(job,
DefaultCodec.class);
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
2)Mapper 和 Reducer 保持不变
加油!
感谢!
努力!
以上是关于Hadoop 数据压缩的主要内容,如果未能解决你的问题,请参考以下文章