堆排/快排/希尔/归并排序,谁更快?
Posted C_YCBX Py_YYDS
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了堆排/快排/希尔/归并排序,谁更快?相关的知识,希望对你有一定的参考价值。
文章目录

前因后果
好久没有再亲自写排序方法了,最近写题突然就又碰到了堆排,然后灵机一动,试一试我现在掌握的这些
O(nlogn)级别的排序算法谁更快?
排序源码
堆排代码
//堆排序
// C++ Version
void sift_down(int arr[], int start, int end) { // 计算父结点和子结点的下标
int parent = start; int child = parent * 2 + 1; while (child <= end) { // 子结点下标在范围内才做比较
// 先比较两个子结点大小,选择最大的
if (child + 1 <= end && arr[child] < arr[child + 1]) child++;
// 如果父结点比子结点大,代表调整完毕,直接跳出函数
if (arr[parent] >= arr[child]) return; else {
// 否则交换父子内容,子结点再和孙结点比较
swap(arr[parent], arr[child]); parent = child; child = parent * 2 + 1;
}
}
}
//堆排入口
void heap_sort(int arr[], int len) {
// 从最后一个节点的父节点开始 sift down 以完成堆化 (heapify)
for (int i = (len - 1 - 1) / 2; i >= 0; i--)
sift_down(arr, i, len - 1);
// 先将第一个元素和已经排好的元素前一位做交换,再重新调整(刚调整的元素之前的元素),直到排序完毕
for (int i = len - 1; i > 0; i--) {
swap(arr[0], arr[i]); sift_down(arr, 0, i - 1);
}
}
快排代码
//快速排序
void qsort(int* nums, int l, int r) {
if (l >= r)return;
int tl = l, tr = r;
int cmp = nums[(l + r) / 2];
while (tl <= tr) {
while (nums[tl] < cmp)tl++;
while (nums[tr] > cmp)tr--;
if (tl <= tr) {
swap(nums[tl], nums[tr]);
tl++;
tr--;
}
}
qsort(nums, l, tr);
qsort(nums, tl, r);
}
//快排入口
void quickSort(int* nums, int len) {
qsort(nums, 0, len - 1);
}
希尔排序代码
//希尔排序---打散的插入排序
void shellSort(int *nums, int len) {
for (int step = len / 2; step >= 1; step /= 2) {
for (int i = step; i < len; i++) {
int j = i, temp = nums[i];
for (; j >= step && nums[j - step] > temp; j -= step) {
nums[j] = nums[j - step];
}
nums[j] = temp;
}
}
}
归并排序代码
老三步走了,分离+结合
//归并排序的完整处理--msort实现拆分数组,merge实现两个有序序列的排序
void merge(int *nums, int *temp, int l, int mid, int r) {
int p = l;
int lstart = l, lend = mid, rstart = mid + 1, rend = r;
while (lstart <= lend && rstart <= rend) {
if (nums[lstart] < nums[rstart]) {
temp[p++] = nums[lstart];
lstart++;
} else {
temp[p++] = nums[rstart];
rstart++;
}
}
while (lstart <= lend) {
temp[p++] = nums[lstart];
lstart++;
}
while (rstart <= rend) {
temp[p++] = nums[rstart];
rstart++;
}
for (int i = l; i < p; i++) {
nums[i] = temp[i];
}
}
//用于划分每个有序结点区间
void msort(int *nums, int *temp, int l, int r) {
if (l < r) {
int mid = l + (r - l) / 2;
msort(nums, temp, l, mid); //左子树
msort(nums, temp, mid + 1, r); //右子树
merge(nums, temp, l, mid, r);
}
}
//归并入口
void mergeSort(int *nums, int numSize) {
int *temp = (int *) calloc(numSize, sizeof(int));
msort(nums, temp, 0, numSize - 1);
free(temp);
}
测试环境
为了保证公平,我用四个不同的数组通过copy函数实现相同数据的排序,用 clock 函数进行计时。统一用同一个print函数打印结果,为了方便计时,只打印前十个元素。
100w数据量下的效率测试
测试源码
#include <bits/stdc++.h>
using namespace std;
clock_t start, endtime;
#define N 1000000
void print(int *nums, int numSize) { //打印函数
for (int i = 0; i < numSize; i++) {
cout << nums[i] << "--";
}
endtime = clock();
printf("timeConsumer%dms\\n", endtime - start);
}
void get_val(int *a, int len) {//随机数赋值
for (int i = 0; i < len; i++) {
a[i] = 100 + rand() % 10;
}
}
int main() {
//以下为内存分配
int *a = new int[N];
get_val(a, N);
int *b = new int[N];
int *c = new int[N];
int *d = new int[N];
copy(a, a + N, b);
copy(a, a + N, c);
copy(a, a + N, d);
//以下为排序计时
start = clock(); //堆排序计时
heap_sort(a, N);
print(a, 10);
start = clock(); //归并排序计时
mergeSort(b, N);
print(b, 10);
start = clock(); //快速排序计时
quickSort(c, N);
print(c, 10);
start = clock(); //希尔排序计时
shellSort(d, N);
print(d, 10);
}
得出以下五次结果:
一、
二、

三、

四、

五、

快排>希尔>归并>堆排
1000w数据下的测试
测试源码:在之前的源码基础上把N该为1000w
测试结果:


快排>希尔>归并>堆排(差距拉大)
1亿数据量的测试
测试源码:把N改为1亿。
这次测试的时间有点长,我就只测一次了。😂(等了足足一分多钟)

快排>希尔>归并>堆排(差距拉到两倍)
总结
在普通的数据情况下快排真的是一把究极利器,堆排对比而言就不怎么够看了,查了下,堆排主要就是在于稳定(不是那种是否交换相同数据的稳定),是不会掉到O(N^2)的这种。好吧,这几个排序的代码我都写了好几遍了,还是觉得快排性价比高,又好写,速度又快!😂
皇城PK,个人的快排VS std::sort()
再次贴一下我的快排,以免翻上去看了
//快速排序
void qsort(int *nums, int l, int r) {
if (l >= r)return;
int tl = l, tr = r;
int cmp = nums[(l + r) / 2];
while (tl <= tr) {
while (nums[tl] < cmp)tl++;
while (nums[tr] > cmp)tr--;
if (tl <= tr) {
swap(nums[tl], nums[tr]);
tl++;
tr--;
}
}
qsort(nums, l, tr);
qsort(nums, tl, r);
}
void quickSort(int *nums, int len) {
qsort(nums, 0, len - 1);
}
数据量1亿测试
测试接口源码
int main() {
int *a = new int[N];
get_val(a, N);
int *b = new int[N];
copy(a,a+N,b);
start = clock();//我的快排计时
quickSort(a,N);
print(a,10);
start = clock(); //stl库的快排计时
sort(b,b+N);
print(b,10);
}
测试时间对比(娱乐一下:
第一轮:我赢了😂

第二轮:还是我赢了😂
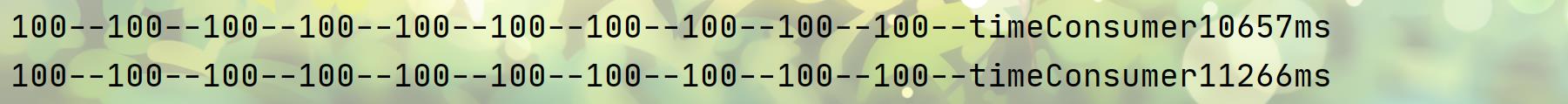
第三轮:不比了,这样对STL库不公平,毕竟sort还需要考虑很多情况,可操作性很强,支持各种模板😂
以上是关于堆排/快排/希尔/归并排序,谁更快?的主要内容,如果未能解决你的问题,请参考以下文章