hadoop学习记录
Posted 一加六
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop学习记录相关的知识,希望对你有一定的参考价值。
Hadoop学习
虚拟机安装
第一步:创建新的虚拟机

第二步:选择“自定义向导”
第三步:
第四步:选择操作系统的类型

第五步:安装及位置

第六步:cpu及核心数 建议最少2核
第七步:内存 建议最少4G

第八步:网络类型选择桥接或nat都可

创建好了虚拟机 图中CPU核心和内存都是为简化流程没有改

安装一台centos7并克隆两台共三台机器

linux网络配置
1.修改主机名称
将克隆的2、3主机分别改名为hadoop02、hadoop03
Vi /etc/hostname

2.主机名和ip映射配置
Host文件配置 三台虚拟机之间通信名称代替ip

2.网络参数配置 配置静态ip

3.测试网卡配置

SSH服务配置 免密登录
1.生成私匙 和公匙

将共匙 加入authorized_keys 文件(如没有touch创建该文件) 实现自我登录
cat id_rsa.pub >> authorized_keys

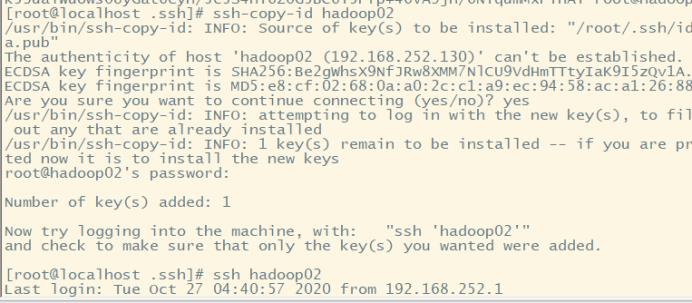
复制共匙到hadoop02和hadoop03 实现免密登录
防火墙配置
firewall-cmd --zone=public --add-port=9000/tcp --permanent
firewall-cmd --zone=public --add-port=50075/tcp --permanent
firewall-cmd --zone=public --add-port=8088/tcp --permanent
放开端口需重载防火墙配置
firewall-cmd --reload
查看一下开放的端口
firewall-cmd --zone=public --list-ports

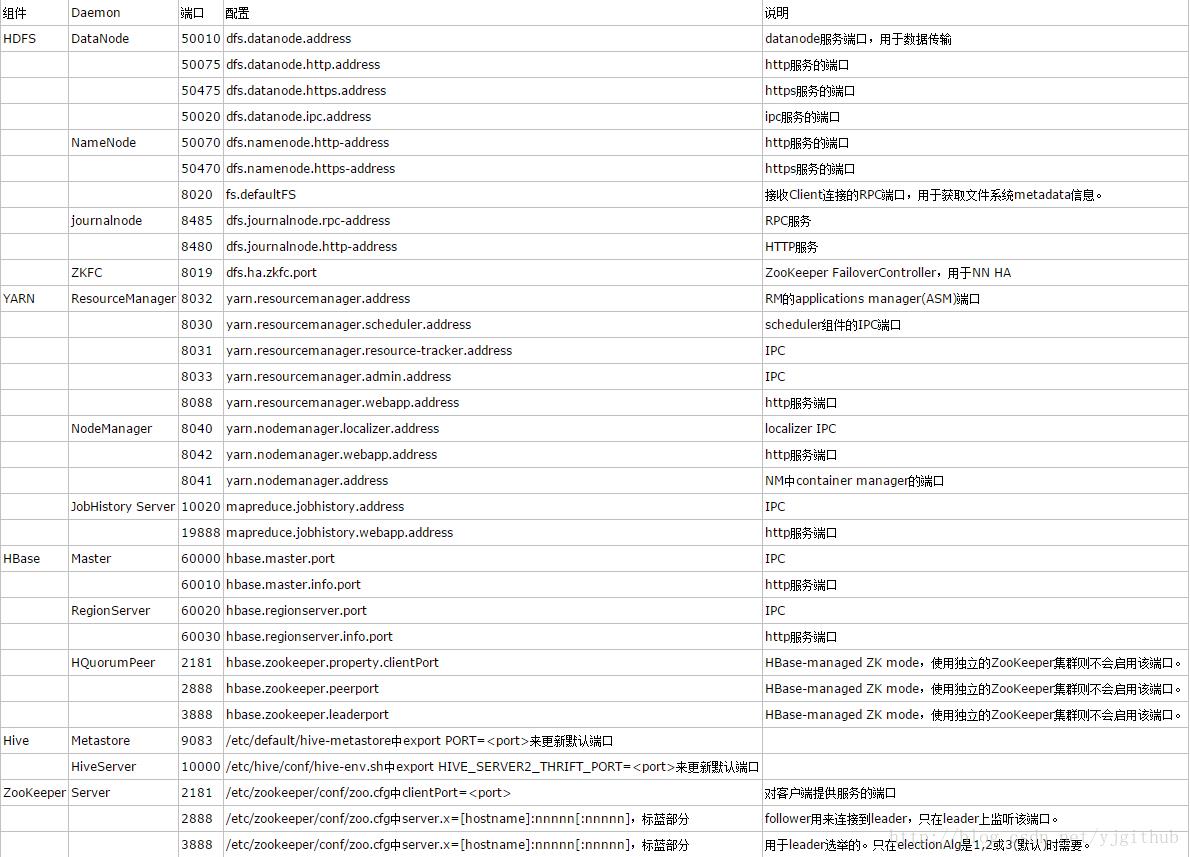
常用的端口如下
Jdk安装
上传

解压

重命名

配置环境变量
验证安装完成

Hadoop安装和集群配置
上传

解压

配置环境变量

需要注意的是配置环境变量的时候若有两个path 一定要记得两个都要在前面加$符号
验证安装成功

主节点配置
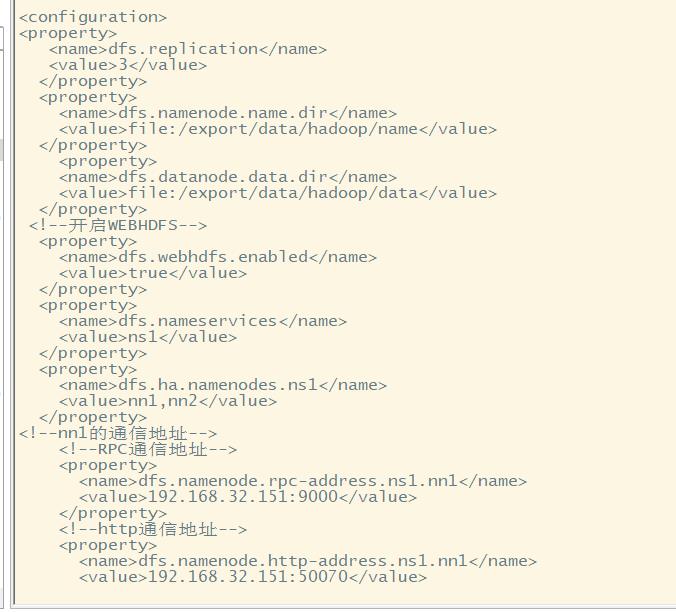
core-site.xml 配置 此地fs需注意value值开头需添加hdfs 非高可用

高可用ha配置

Hdfs-site.xml文件配置 此处dfs需注意value前无需添加hdfs

高可用ha配置


Mapred-site.xml文件配置

yarn-site.xml文件配置
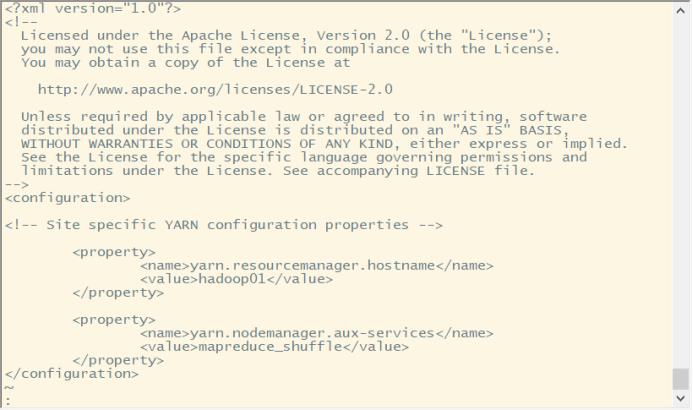
高可用ha配置
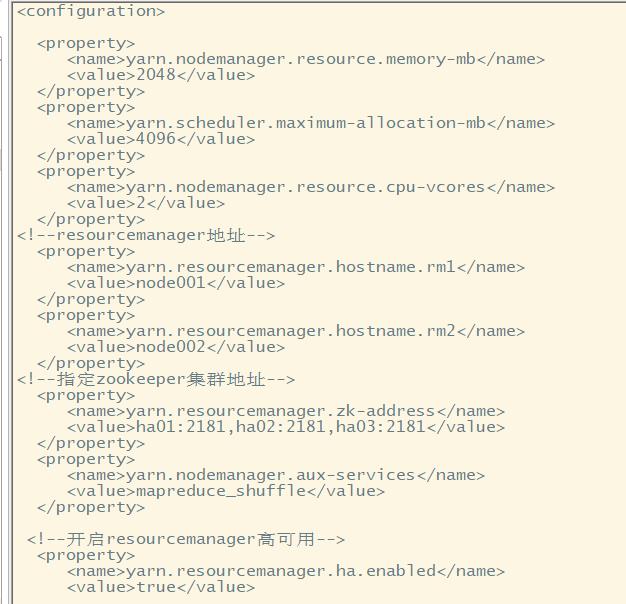

Slaves文件配置

将主节点内容分发到子节点
分发profile配置

同步分发、export下的文件

zookeeper安装并配置
1.下载并解压

配置环境变量
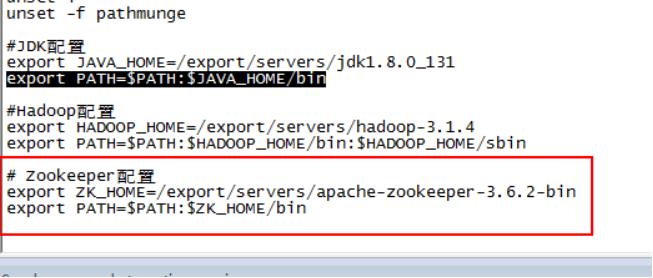
配置zoo.cfg

添加myid文件

Ha-01输入值1,ha-02输入值为2,ha-03输入值为3
Hadoop集群测试
1.启动各个节点的zookeeper服务
zkServer.sh start

2.启动集群监控namenode的管理日志journalNode
hadoop-daemons.sh start journalnode
说明:该命令不推荐使用,系统会提示使用新的命令
hdfs –daemon start journalnode
可以不用单独启动,在启动hadoop集群的时候会自动启动(如果配置了的journalnode情况)

3.在node-01上格式化namenode,并分发到node-02
1.Hadoop namenode –format 提示用:hdfs namenode -format
2.scp –r /export/data/hadoop node-02:/export/data
注意:只分发master和backupmaster
hdfs namenode -format
若初始化时出现下面错误

错误原因:
我们在执行start-dfs.sh的时候,默认启动顺序是namenode>datanode>journalnode>zkfc,如果journalnode和namenode不在一台机器启动的话,很容易因为网络延迟问题导致namenode无法连接journalnode,无法实现选举,最后导致刚刚启动的namenode会突然挂掉。虽然namenode启动时有重试机制等待journalnode的启动,但是由于重试次数限制,可能网络情况不好,导致重试次数用完了,也没有启动成功。
解决方法:
方法①:手动启动namenode,避免了网络延迟等待journalnode的步骤,一旦两个namenode连入journalnode,实现了选举,则不会出现失败情况。
方法②:先启动journalnode然后再运行start-dfs.sh。
方法③:把namenode对journalnode的容错次数或时间调成更大的值,保证能够对正常的启动延迟、网络延迟能容错。在hdfs-site.xml中修改ipc参数,namenode对journalnode检测的重试次数,默认为10次,每次1000ms,故网络情况差需要增加。具体修改信息为:
<property>
<name>ipc.client.connect.max.retries</name>
<value>100</value>
<description>Indicates the number of retries a client will make to establish
a server connection.
</description>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
<description>Indicates the number of milliseconds a client will wait for
before retrying to establish a server connection.
</description>
</property>
原文链接:link
如出现以下错误
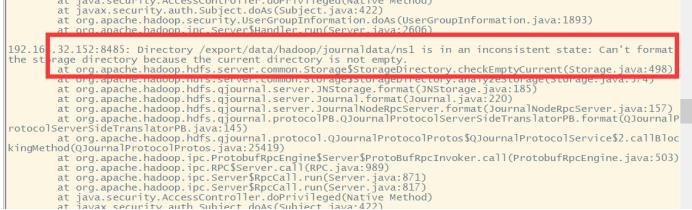
要删除对应文件下的目录再初始化
4.在node-01上格式化ZKFC
hdfs zkfc –formatZK
5.在node-01上启动hadfs
start-dfs.sh
6.在node-01上启动yarn
start-yarn.sh
一键启动 终止
start-dfs.sh start-yarn.sh
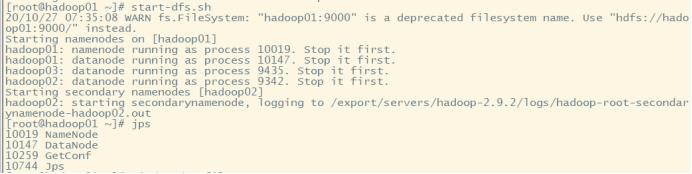
结果 3台均正常启动dfs 和yarn

如果有漏掉的机器没有启动
则可以用
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start secondarymanager
yarn-daemon.sh start nodemanager
在漏掉的机器上执行启动
一键终止 stop-dfs.sh stop-yarn.sh

通过UI查看hadoop集群

三台集群均成功通信展示在UI界面
在UI界面创建添加文件
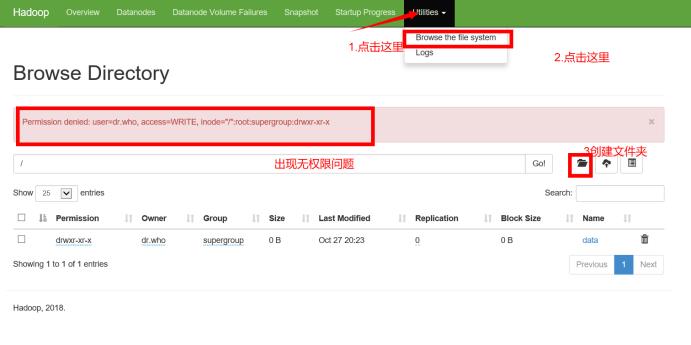
解决办法:在linux系统中hadoop fs -chmod -R 777 /释放权限(实际生产应该不会让这样做)
Hadoop运行mapreduce 使用基础jar包统计词频
前提条件:
1.dfs、yarn已运行
2.在hadoop文件系统创建如下文件夹

3.在input目录下上传word.txt.txt文件

4.防火墙50070、8088、9000、50075端口放开
运行统计词频案例
在/export/servers/hadoop2.9.2/share/hadoop/mapreduce/目录下有一些简单例子的jar包如统计词频、计算Pi值等,下面演示一个词频统计
进入到/export/servers/hadoop2.9.2/share/hadoop/mapreduce/目录下
hadoop jar hadoop-mapreduce-examples-2.9.2.jar wordcount /data/input/word.txt.txt /data/output/result
输出文件在hadoop文件系统的/data/output/result目录下

查看下输出结果
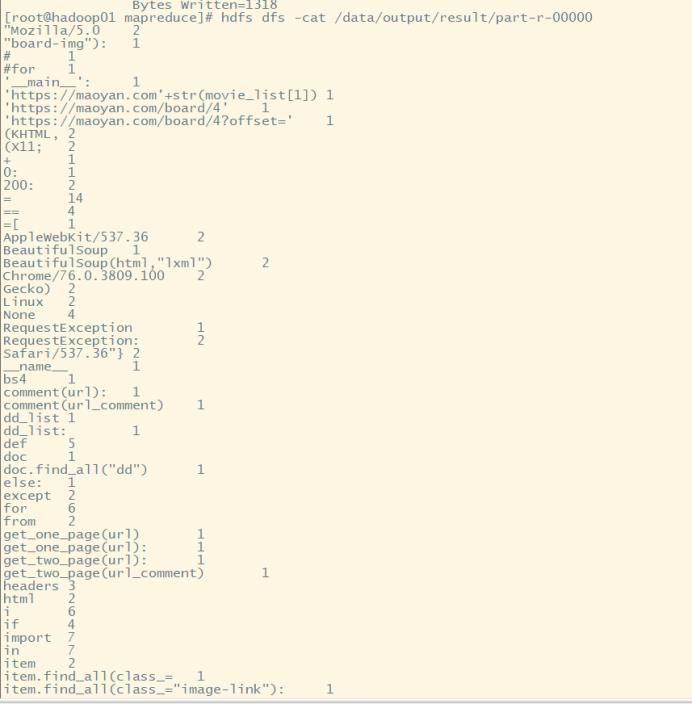
输出为各个词的词频
在网页端查看输出结果
需要防火前放开50075端口


Hadoop - JavaAPI (with IDEA in Windows)
Windows 安装hadoop
(hadoop-2.5.2.tar.gz解压到本地)

Windows配置hadoop环境变量
HADOOP_HOME
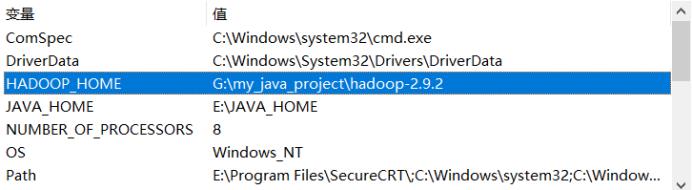
添加path

winutils工具包
解压下载的winutils,找到对应或邻近版本的Hadoop,进入其bin目录,将其中的hadoop.dll和winutils.exe拷贝到C:\\Windows\\System32目录
创建maven project
配置pom.xml

配置core-site.xml、hdfs-site.xml、log4j.properties
将远程集群的Hadoop安装目录下hadoop/hadoop-2.7.7/etc/hadoop目录下的core-site.xml、hdfs-site.xml两个文件通过Xftp等SFTP文件传输软件将两个文件复制,并移动到上述src/main/resources目录中(拖拽即可),然后将下载的log4j.properties文件移动到src/main/resources目录中(防止不输出日志文件)
(可以直接从linux的/export/servers/hadoop-2.9.2/etc/hadoop下复制过来)
编写java程序相应模块测试创建、上传读取文件

将连接属性前添加@before方法作为连接前提条件
创建、上传文件夹前添加@test方法连接测试
编写经典案例倒排索引(课本Mapreduce案例)
文件准备
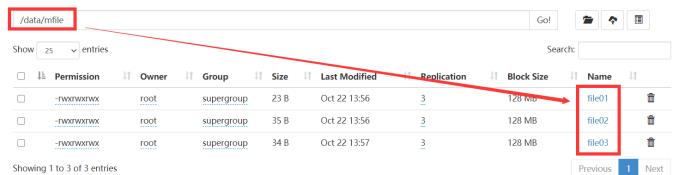
首先在/data的目录下创建两个文件

在mfile里创建三个文件
编写java类文件
Mapper

Reducer

Combiner

Driver

结果
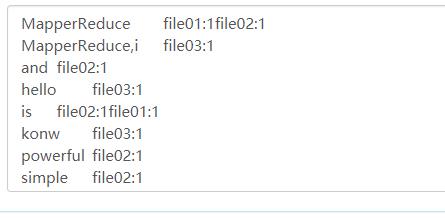
文档出现词和文档对应索引
以上是关于hadoop学习记录的主要内容,如果未能解决你的问题,请参考以下文章