现代信息检索——索引构建
Posted 白水baishui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了现代信息检索——索引构建相关的知识,希望对你有一定的参考价值。
1. 索引
建立倒排索引的过程称为索引构建,负责构建索引的算法称为索引器。操作系统往往以数据块为单位对数据进行读写,因此从磁盘读取一个字节和读一个数据块所耗费的时间可能一样多。采用一种高效的解压缩算法对数据进行压缩,然后读取磁盘上的压缩数据,再进行解压,这个过程所花的时间往往会比直接读取原始数据的时间少。
下文涉及到是3个名词:倒排、索引均是指倒排表的不同形式;词典是指词项名到词项ID的映射表。
1. BSBI算法
BSBI(Blocked sort-based Indexing,基于块的排序索引方法)的基本思想是:收集每一个数据块(数据库大小由内存决定)的倒排表,对每个倒排表排序后写入硬盘,最后将不同分块的倒排表合并为一个大的全局倒排表(词典),该词典就是索引文件。
算法流程:
- 词项ID映射
将所有文档的词项映射为对应的ID,形成全局的termStr-termID词典; - 构建词项块
将映射后的所有词项划分为大小相等的块构建倒排表,并存入磁盘; - 对倒排表排序
将每个块读入内存,然后按照termID排序(快速排序大约需要 O ( N ln N ) O(N\\ln N) O(NlnN)步)。不断重复直到所有倒排表都完成排序。 - 对倒排表合并
从磁盘中取出两个数据块的倒排表,进行合并形成一个全局倒排表,再将全局倒排表存入磁盘。不断重复直到所有倒排表都完成合并。
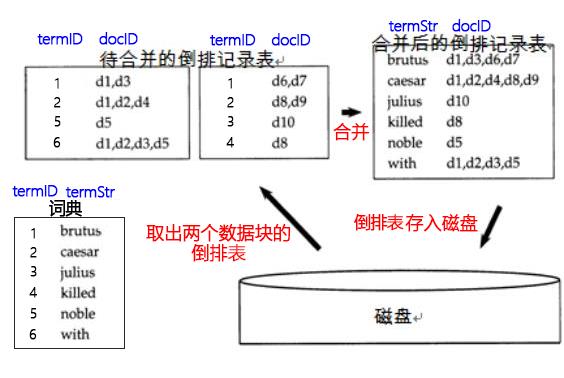
需要注意的是,待合并的倒排记录表的term是用id来表示的,上图的字符串只是为了方便理解;词典的term是字符串形式。
为了加快处理速度,可以进行多项合并,多项合并(multi-way merge)比两两合并效率更高。所谓多项合并,也就是从所有块同时读取。
多项合并的流程如下:
- 同时从所有块读取,并且为每块维持一个读缓冲区(read buffer),为输出文件(即合并后的倒排表)维持一个写缓冲区(write buffer);
- 维护一个待处理termid的优先级队列(priority queue),每次迭代从队列中选取一个最小的未处理 termid;
- 合并不同块中所有的该termID的倒排表,并写入磁盘。
不断迭代,最终完成合并,在多项合并的过程中,每次迭代均处理较小规模的数据(一个词项的倒排表),需要一定的内存开销。
2. SPIMI算法
SPIMI(Single-pass in-memory indexing, 内存式单遍扫描索引构建算法)是在BSBI的基础上改进的,它不做id转换,而是直接关联了词项与索引。另外词项不排序,直接按照出现的先后顺序构建索引。
算法流程:
- 构建词项块
将所有文档的词项划分为大小相等的块; - 构建块倒排表
对的每个块内的词项映射为对应的ID,形成单个块的局部termStr-termID词典,然后构造倒排表; - 合并块倒排表
将所有块的倒排表进行合并
3. BSBI与SPIMI的区别
BSBI算法在分块索引阶段,维护一个全局termStr-termid的词典,局部索引为termid及其倒排记录表,按词典顺序排序。是在合并前就构造全局词典。
SPIMI算法分块索引阶段建立局部词典和索引,无需全局词典。 在合并阶段,将块倒排表两两合并,合并完成后自然产生全局termStr-termid词典。是在合并过程中构造全局词典。
3. 动态索引构建
在实际使用索引时,文档常常会增加、删除和修改,这也意味着词典和倒排记录表必须要动态更新。
一个最简单的方案是主辅索引:主索引(Main index)+辅助索引(Auxiliary index)。
- 对于增加文档
该方案在磁盘上维护一个大的主索引(Main index),新增的文档放入内存中较小的辅助索引中。定期同时搜索两个索引(主和辅),然后合并搜索结果。这样就实现了自动扩充索引。 - 对于删除文档
对于要删除的文档,索引不马上将其从索引中去除,而是采用无效位向量(Invalidation bit-vector)来表示删除的文档。得到定期搜索主辅索引时,利用无效位向量过滤返回的结果,去掉已删除文档。
主辅索引合并存在的问题主要是合并任务量大、合并过于频繁,合并时如果正好在搜索,那么搜索的性能将很低。为了缓解这个问题,在合并阶段可以采用对数合并:
对数合并算法能够缓解(随时间增长)索引合并的开销,使用户不会明显感觉到搜索操作在响应时间上的延迟。对数合并的思想是:
- 维护一系列索引,其中每个索引的容量是前一个索引的两倍,第一个索引的容量为 n n n;
- 将最小的索引 ( i 0 ) (i_0) (i0)载入内存,其他更大的索引 ( i 1 , i 2 , . . . ) (i_1,i_2,...) (i1,i2,...)置于磁盘;
- 当
(
i
0
)
(i_0)
(i0)变得过大时
(
i
0
>
n
)
(i_0>n)
(i0>n)
若 i 1 i_1 i1不存在,则将 i 0 i_0 i0写入磁盘作为 i 1 i_1 i1;
若 i 1 i_1 i1存在,则将 i 0 i_0 i0与 i 1 i_1 i1合并,然后将合并结果作为 i 2 i_2 i2写到磁盘中(若 i 2 i_2 i2不存在),或者继续和后面的索引合并。
设 T T T为所有倒排记录的个数,则对数合并的复杂度( O ( T log T ) O(T\\log T) O(TlogT))比辅助索引( ( O ( T 2 ) ) (O(T^2)) (O(T2)))要低一个数量级,是一个很好的合并算法。
以上是关于现代信息检索——索引构建的主要内容,如果未能解决你的问题,请参考以下文章