一起重新开始学大数据-Hbase篇-day 57 Hbase调优
Posted 你的动作太慢了!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一起重新开始学大数据-Hbase篇-day 57 Hbase调优相关的知识,希望对你有一定的参考价值。
| 一起重新开始学大数据-Hbase篇-day 57 Hbase调优 |

1、预分区
Pre-Creating Regions(预分区) 概述:
默认情况下,在创建HBase表的时候会自动创建一个region分区,当导入数据的时候, 所有的HBase客户端都向这一个region写数据,直到这个region足够大了才进行切分。 但这样的情况,会导致如果数据量过大导致写入速度过慢,所以可以使用一种可以加快批量写入速度的方法是通过预先创建一些空的regions,这样当数据写入 HBase时,会按照region分区情况,在集群内做数据的负载均衡。
如果知道hbase数据表的key的分布情况,就可以在建表的时候对hbase进行region的预分区。这样做的好处是防止大数据量插入的热点问题,提高数据插入的效率。
执行步骤:
①理解分区方式并且生成分区文件
首先就是要想明白数据的key是如何分布的,然后规划一下要分成多少region,每个region的startkey和endkey是多少,然后将规划的key写到一个文件中。比如,key的前几位字符串都是从0001~0010的数字,这样可以分成10个region,划分key的文件如下:
0001|
0002|
0003|
0004|
0005|
0006|
0007|
0008|
0009|
为什么后面会跟着一个"|",是因为在ASCII码中,"|"的值是124,大于所有的数字和字母等符号,当然也可以用“~”(ASCII-126)。分隔文件的第一行为第一个region的stopkey,每行依次类推,最后一行不仅是倒数第二个region的stopkey,同时也是最后一个region的startkey。也就是说分区文件中填的都是key取值范围的分隔点,如下图分区文件所示(第一行为第一个region的stopkey,也就是说小于1500100100的都放在第一个分区,大于等于1500100100的以及小于1500100200的放在第二个分区):
在本地创建一个分区文件
vim region_split_info.txt
输入以下内容:

②base shell中建分区表,指定分区文件
可以通过指定SPLITS_FILE的值指定分区文件,如果分区信息比较少,也可以直接用SPLITS分区。我们可以通过如下命令建一个分区表,指定第一步中生成的分区文件:
create 'split_table_test', 'cf', {SPLITS_FILE => '/usr/local/soft/data/region_split_info.txt'}
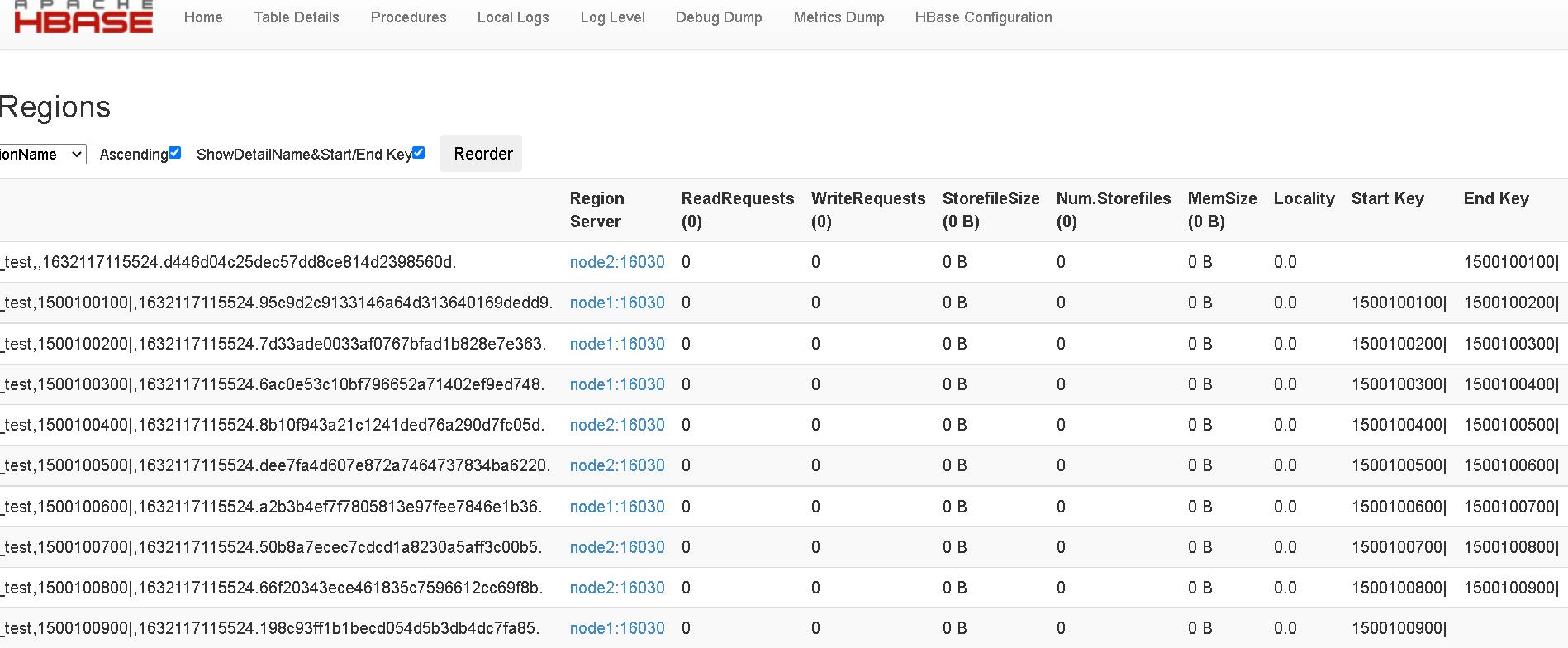
下面,我们登陆一下master的web页面Hmaster:60010,查看一下hbase的表信息,找到刚刚新建的预分区表,进入查看region信息:
2、Rowkey设计
①设计原则
HBase中row key用来检索表中的记录,支持以下三种方式:
-
通过单个row key访问:即按照某个row key键值进行get操作;
-
通过row key的range进行scan:即通过设置startRowKey和endRowKey,在这个范围内进行扫描;
-
全表扫描:即直接扫描整张表中所有行记录。
在HBase中,row key可以是任意字符串,最大长度64KB,实际应用中一般为 10~100bytes,存为byte[]字节数组,一般设计成定长的。
row key是按照字典序存储,因此,设计row key时,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。
HBase是三维有序存储的,通过rowkey(行键),column key(column family和qualifier)和TimeStamp(时间戳)这个三个维度可以对HBase中的数据进行快速定位。
rowkey长度原则
rowkey是一个二进制码流,可以是任意字符串,最大长度 64kb ,实际应用中一般为10-100bytes,以 byte[] 形式保存,一般设计成定长。
建议越短越好,不要超过16个字节,原因如下:
数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如超过100字节,1000w行数据,光rowkey就要占用100*1000w=10亿个字节,将近1G数据,这样会极大影响HFile的存储效率;
MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
rowkey散列原则
如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将rowkey的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息,所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别的RegionServer上,造成热点问题,会降低查询效率。
rowkey唯一原则
必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
②热点问题
HBase中的行是按照rowkey的字典顺序排序的,这种设计优化了scan操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于scan。然而糟糕的rowkey设计是热点的源头。 热点发生在大量的client直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作)。大量访问会使热点region所在的单个机器超出自身承受能力,引起性能下降甚至region不可用,这也会影响同一个RegionServer上的其他region,由于主机无法服务其他region的请求。 设计良好的数据访问模式以使集群被充分,均衡的利用。
为了避免写热点,设计rowkey会使得不同行在同一个region,但是在更多数据情况下,数据应该被写入集群的多个region,而不是一个。
下面是一些常见的避免热点的方法以及它们的优缺点(附带案例说明):
加盐
这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,以避免热点。
#数据
20210918_10001
20210919_10001
20210920_10001
# 加盐
1679592560_20210918_10001
665840881_20210919_10001
374714006_20210920_10001
哈希
哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据
#数据
20210918_10001
20210919_10001
20210920_10001
# 哈希
37410b3a3a683b1dbeaf165b750bf7ed_20210918_10001
9b58fa08284d1a30c386e17aa7cffc35_20210919_10001
fb1c5c2fb7add4d693181e69ed78228d_20210920_10001
反转
第三种防止热点的方法时反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。
反转rowkey的例子以手机号为rowkey,可以将手机号反转后的字符串作为rowkey,这样的就避免了以手机号那样比较固定开头导致热点问题
#数据:
183XXXX5028
188XXXX5027
139XXXX1245
#反转
8205XXXX381
7205XXXX881
5421XXXX931
时间戳反转
一个常见的数据处理问题是快速获取数据的最近版本,使用反转的时间戳作为rowkey的一部分对这个问题十分有用,可以用 Long.Max_Value - timestamp 追加到key的末尾,例如[key][reverse_timestamp] , [key] 的最新值可以通过scan [key]获得[key]的第一条记录,因为HBase中rowkey是有序的,第一条记录是最后录入的数据。
比如需要保存一个用户的操作记录,按照操作时间倒序排序,在设计rowkey的时候,可以这样设计
# 数据 = > 时间戳反转
000001_1631929041 => 000001_9223372035222846766
000001_1631929341 => 000001_9223372035222846466
000001_1631929641 => 000001_9223372035222846166
000001_1631929941 => 000001_9223372035222845866
000001_1631930441 => 000001_9223372035222845366
3、In memory
创建表的时候,可以通过HColumnDescriptor.setInMemory(true)将表放到 RegionServer的缓存中,保证在读取的时候被cache命中。(针对列簇)
在Hbase shell中通过desc 查看表,可以看到是否开启

4、Max Version
创建表的时候,可以通过HColumnDescriptor.setMaxVersions(int maxVersions)设置 表中数据的最大版本,如果只需要保存最新版本的数据,那么可以设置 setMaxVersions(1)。
5、Compact&split
在HBase中,数据在更新时首先写入WAL 日志(HLog)和内存(MemStore)中, MemStore中的数据是排序的,当MemStore累计到一定阈值(128M)时,由单独的线程flush到磁盘上,成为一个StoreFile。与此同时, 系统会在zookeeper中记录一个redo point,表示这个时刻之前的变更已经持久化了
StoreFile是只读的,一旦创建后就不可以再修改。因此Hbase的更新其实是不断追加的操作。当一个Store中的StoreFile的数量达到一定的阈值后,就会进行一次合并(major compact),将对同一个key的修改合并到一起,形成一个大的StoreFile;当StoreFile的大小达到一定阈值后,又会对 StoreFile进行分割(split),等分为两个StoreFile。
6、BulkLoading
优点:
-
如果我们一次性入库hbase巨量数据,处理速度慢不说,还特别占用Region资源, 一个比较高效便捷的方法就是使用 “Bulk Loading”方法,即HBase提供的HFileOutputFormat类。
-
它是利用hbase的数据信息按照特定格式存储在hdfs内这一原理,直接生成这种hdfs内存储的数据格式文件,然后上传至合适位置,即完成巨量数据快速入库的办法。配合mapreduce完成,高效便捷,而且不占用region资源,增添负载。
限制:
-
仅适合初次数据导入,即表内数据为空,或者每次入库表内都无数据的情况。
-
HBase集群与Hadoop集群为同一集群,即HBase所基于的HDFS为生成HFile的MR的集群
①代码
- 生成HFile部分
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.RegionLocator;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.hbase.mapreduce.KeyValueSortReducer;
import org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles;
import org.apache.hadoop.hbase.mapreduce.SimpleTotalOrderPartitioner;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class BulkLoading {
public static class BulkLoadingMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, KeyValue> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] splits = value.toString().split(",");
String mdn = splits[0];
String start_time = splits[1];
// 经度
String longitude = splits[4];
// 维度
String latitude = splits[5];
String rowkey = mdn + "_" + start_time;
KeyValue lg = new KeyValue(rowkey.getBytes(), "info".getBytes(), "lg".getBytes(), longitude.getBytes());
KeyValue lt = new KeyValue(rowkey.getBytes(), "info".getBytes(), "lt".getBytes(), latitude.getBytes());
context.write(new ImmutableBytesWritable(rowkey.getBytes()), lg);
context.write(new ImmutableBytesWritable(rowkey.getBytes()), lt);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "master:2181,node1:2181,node2:2181");
// 创建Job实例
Job job = Job.getInstance(conf);
job.setJarByClass(BulkLoading.class);
job.setJobName("BulkLoading");
// 保证全局有序
job.setPartitionerClass(SimpleTotalOrderPartitioner.class);
// 设置reduce个数
job.setNumReduceTasks(4);
// 配置map任务
job.setMapperClass(BulkLoadingMapper.class);
// 配置reduce任务
// KeyValueSortReducer 保证在每个Reduce有序
job.setReducerClass(KeyValueSortReducer.class);
// 输入输出路径
FileInputFormat.addInputPath(job, new Path("/data/DIANXIN/"));
FileOutputFormat.setOutputPath(job, new Path("/data/hfile"));
// 创建HBase连接
Connection conn = ConnectionFactory.createConnection(conf);
// create 'dianxin_bulk','info'
// 获取dianxin_bulk 表
Table dianxin_bulk = conn.getTable(TableName.valueOf("dianxin_bulk"));
// 获取dianxin_bulk 表 region定位器
RegionLocator regionLocator = conn.getRegionLocator(TableName.valueOf("dianxin_bulk"));
// 使用HFileOutputFormat2将输出的数据按照HFile的形式格式化
HFileOutputFormat2.configureIncrementalLoad(job, dianxin_bulk, regionLocator);
// 等到MapReduce任务执行完成
job.waitForCompletion(true);
// 加载HFile到 dianxin_bulk 中
LoadIncrementalHFiles load = new LoadIncrementalHFiles(conf);
load.doBulkLoad(new Path("/data/hfile"), conn.getAdmin(), dianxin_bulk, regionLocator);
/**
* create 'dianxin_bulk','info'
* hadoop jar HBaseJavaAPI10-1.0-jar-with-dependencies.jar com.shujia.Demo10BulkLoading
*/
}
}
②说明
-
最终输出结果,无论是map还是reduce,输出部分key和value的类型必须是: < ImmutableBytesWritable, KeyValue>或者< ImmutableBytesWritable, Put>。
-
最终输出部分,Value类型是KeyValue 或Put,对应的Sorter分别是KeyValueSortReducer或PutSortReducer。
-
MR例子中HFileOutputFormat2.configureIncrementalLoad(job, dianxin_bulk, regionLocator);自动对job进行配置。SimpleTotalOrderPartitioner是需要先对key进行整体排序,然后划分到每个reduce中,保证每一个reducer中的的key最小最大值区间范围,是不会有交集的。因为入库到HBase的时候,作为一个整体的Region,key是绝对有序的。
-
MR例子中最后生成HFile存储在HDFS上,输出路径下的子目录是各个列族。如果对HFile进行入库HBase,相当于move HFile到HBase的Region中,HFile子目录的列族内容没有了,但不能直接使用mv命令移动,因为直接移动不能更新HBase的元数据。
-
HFile入库到HBase通过HBase中 LoadIncrementalHFiles的doBulkLoad方法,对生成的HFile文件入库
上一章-Hbase篇-day 56 Phoenix
下一章-随缘更新


以上是关于一起重新开始学大数据-Hbase篇-day 57 Hbase调优的主要内容,如果未能解决你的问题,请参考以下文章