《The Book of Why》 — Chapter7
Posted flower48237
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《The Book of Why》 — Chapter7相关的知识,希望对你有一定的参考价值。
第七章 超越统计调整:征服干预之峰
CHAPTER 7 — Beyond Adjustment: The Conquest of Mount Intervention
- 因果之梯的第二层:对未尝试过的行动和策略的效果进行预测。混杂因子是导致我们预测混淆的主要障碍。在用“路径阻断”工具和后门标准消除这一障碍后,就能精确而系统地绘制出登上干预之峰地路线图。(路径阻断工具是d-separation)(195)
- do演算允许研究者探索并绘制出通往干预之峰的所有可能的路线。(195)
最简单的路线:后门调整公式
-
最常用的预测干预效果的方法是使用统计调整公式“控制”混杂因子,如果确定已经掌握了变量的一个充分集(去混因子)的数据就可以用来阻断干预和结果之间的所有后门路径,就可以使用此方法。为了做到这一点,需要首先估计去混因子在每个“水平”或数据分层中产生的效应,并据此测算出干预的平均因果效应。然后需要计算这些层的因果效应的加权平均值,为此需要对每个层都按期在总体中的分布频率进行加权。(195-196)
-
后门准则在估算平均因果效应的过程中所起的作用是,保证去混因子在各层中的因果效应与我们在这一层观察到的趋势相一致。据此可以从数据中逐层估计出因果效应,若没有后门准则,研究者就无法保证所有的统计调整都是合理的。(196)
-
当有多个混杂因子和多个数据分层时,就很难将所有的可能性都罗列出来,一个补救办法是将数值分成有限并且数目可控的类别,但是这种分类方式的选择上可能存在主观性,如果需要进行统计调整的变量比较多,那么类别的数量就会呈指数增长,这将使计算过程变得难以执行,更糟糕的是,在分类完成后,很可能会发现许多层缺乏样本,因此无法对其进行任何概率估计。为应对“维度灾难”问题,设计了数据外推法,即通过一个与数据拟合的光滑函数来填充空的层所形成的洞。运用最为广泛的光滑函数是线性近似,使用时每个因果效应都可以用一个数字(因果系数)来表示,并且根据统计调整公式进行计算的过程非常简单。(197)
-
无论是否经过统计调整,回归系数只表示一种统计趋势,其自身并不能传递因果信息。(198)
回归系数有时可以体现因果效应,有时则无法体现,而其中的差异无法仅依靠数据来说明。还需要具备另外两个条件才能赋予偏回归系数rYXZ 以因果合法性:
(1)所绘制的相应的因果图能够合理地解释现实情况;
(2)需要据其进行统计调整的变量Z应该满足后门准则。(198)
-
基于回归的统计调整只适用于线性模型:
(1)一旦使用了线性模型,就失去了为非线性的相互作用建模的能力;(2)即使不知道图中箭头背后的函数是什么,后门调整仍有效。(199)
-
后门准则和后门调整公式的关系:
后门准则用于判定哪些变量集可以用来去除数据中的混杂;
后门调整公式所做的实际上就是去混杂。(199)
-
如果因缺乏必要的数据而无法阻断某条后台路径,统计调整公式就会完全失灵。(199)
前门准则
-
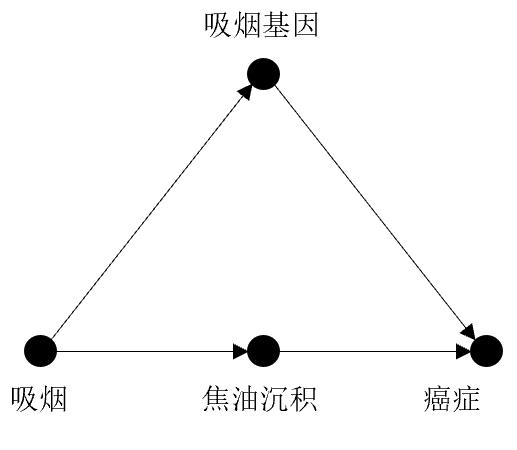
由于缺乏混杂因子的数据,不能阻断“吸烟 <— 混杂因子 —> 癌症”的后门路径,因此不能使用后门调整来控制混杂因子的影响。(200)
前门指的是直接的因果路径“吸烟 —> 焦油沉积 —> 癌症”。(201)
-
可以用纯数学的方式在不引入do算子本身(不进行实际干预)的情况下算出概率结果。(202)
-
在不引入do算子的前提下表示 P(癌症 | do (吸烟)) 就被称作前门调整(202)
-
依据上图,设X代表吸烟,Y代表癌症,Z代表焦油沉积,U代表不可观测的变量(未出现在公式中),公式如下
-
前门调整公式:
P(Y|do(X)) = Σz P(Z=z,X)Σx P(Y|X=x,Z=z)P(X=x)
-
后门调整公式:
P(Y|do(X)) = Σz P(Y|X,Z=z)P(Z=z)
-
从前门公式中可知:
(1)在公式的任何地方都看不到U,这是整个问题的关键;
(2)将被估量视为一种针对问题中的目标量的计算方法。
-
-
因果图的一个主要优势就算让假设变得透明,以供专家和决策者探讨和辩论。(203)
-
在假设正确的情况下,即使没有混杂因子的数据,仍然可以用数学方式消除混杂因子的影响。(203)
-
前门调整是一个强大的工具,因为:
它允许我们控制混杂因子,并且这些混杂因子可以是我们无法观测(如“动机”)甚至无法命名的。也正是因为同样的原因,随机对照试验被认为是估计因果效应的黄金标准。(206)
do演算,或者心胜于物
-
前门调整公式和后门调整公式的最终目标是根据P(Y|X,A,B,Z,……)此类不涉及do算子的数据估算干预的效果,即P(Y|do(X))。
如果可以成功消除计算过程中的do概率,就可以利用观测数据来估计因果效应,就可以从因果关系之梯的第一层踏上第二层。(206)
-
三条合法的do表达式变换⭐:(209)
-
规则1:如果我们观察到变量W和Y无关(其前提可能是以其他变量Z为条件),那么Y的概率分布就不会随W而改变。等式成立的条件是,在删除了指向X的所有箭头之后,变量集Z会阻断所有从W到Y的路径。
句法解释:允许增加或删除某个观察结果。
P(Y|do(X), Z, W) = P(Y|do(X),Z)
-
规则2:如果变量Z阻断了X到Y的的所有后门路径,那么以Z为条件(对Z进行变量控制),则do(X)等同于see(X)。即在控制了一个充分的去混因子之后,留下的相关性就是真正的因果效应。
句法解释:允许用观察替换干预。
P(Y|do(X),Z) = P(Y|X,Z)
-
规则3:如果没有从X到Y的因果路径,就可以将do(X)和从P(Y|do(X))中移除。即如果我们实施的干预行动(do)不会影响Y,那么Y的概率分布就不会改变。
句法解释:允许删除或添加干预。
P(Y|do(X)) = P(Y)
-
-
有了上述三条规则,就可以推导出前门调整公式。这是一个不以控制混杂因子为手段来估计因果效应的方法。(210)
-
如果我们在规则1到3中找不到根据数据估计P(Y|do(X))的方法,那么对于这个问题,解决方案就是不存在的。
在此情况下,除了进行随机对照试验别无选择。这三条规则还能告诉我们,对于某个特定的问题,什么样的额外假设或实验可以使因果效应从不可估计变为可估计。(212)
-
伊利亚·斯皮塞=>发现可以用于确定某个解决方案是否存在“多项式时间”的算法。(213)
案例:斯诺医生的离奇案例
-
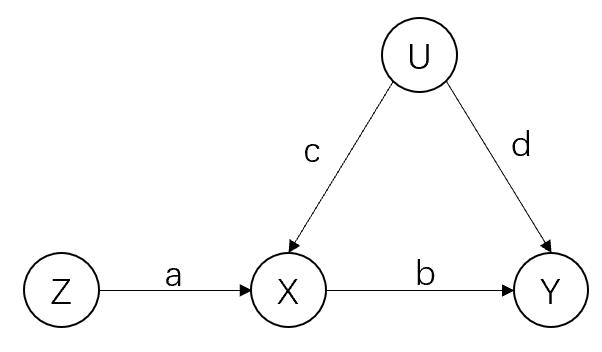
工具变量(222)如图,Z就是一个工具变量:
(1)Z和U之间没有箭头(二者独立)
(2)Z和X之间有一个箭头
(3)Z和Y之间没有直接箭头
-
工具变量允许我们执行与前门调整相同的处理:在无法控制混杂因子或收集其数据的情况下估计X对Y的效应。(223)
-
路径图所体现的假设在本质上是因果关系。(223)
好胆固醇与坏胆固醇
-
“未履行问题”,如受试者虽然随机地接受了药物安排,但实际上并没有复用被分配的药物。(226)
-
当变量都是二元变量,而不是数值变量时,意味着不能使用线性模型,因此工具变量公式也不适用。在这种情况下,通常可以使用被称为“单调性”的弱相关来代替线性假设。但在这么做之前,需要先确保工具变量的三个假设都是有效的(226-227):
(1)工具变量Z独立于混杂因子
(2)Z到Y无直接路径
(3)Z和X之间存在强关联
-
取最好和最坏情况的做法通常会得到一个估计结果的取值范围。(228)
-
在做任何干预研究之前,都要看我们实际操作的变量(如低密度脂蛋白的终生水平)是否与我们认为自己正在操作的变量(如低密度脂蛋白的当前水平)相同。
工具变量是一个重要的工具,他能我们帮助我们揭示do演算无法解释的因果信息,do演算强调的是点估计,而非不等式。
相比工具变量,do演算具有更强大的灵活性,因为在do演算中,我们不需要对因果模型中函数的性质做任何假设。而如果我们的确有足够的科学依据证实类似单调性或线性这样的假设的话,那么像工具变量这种针对性更强的工具就更值得考虑。(230-231)
《THE BOOK OF WHY: THE NEW SCIENCE OF CAUSE AND EFFECT》
——JUDEA PEARL AND DANA MACKENZIE
以上是关于《The Book of Why》 — Chapter7的主要内容,如果未能解决你的问题,请参考以下文章