Python数据结构系列☀️《查找排序-基础知识》——知识点讲解+代码实现☀️
Posted Vax_Loves_1314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数据结构系列☀️《查找排序-基础知识》——知识点讲解+代码实现☀️相关的知识,希望对你有一定的参考价值。
数据结构之查找
1、线性表的查找
在查找表的组织方式中,线性表示最简单的一种。本节将介绍基于线性表的顺序查找、折半查找和分块查找。
1.1 顺序查找
顺序查找的查找过程为:从表的一端开始,依次将记录的关键字和给定值进行比较,若某个记录的关键字和给定值相等,则查找成功;反之,若扫描整个表后,仍未找到关键字和给定值相等的记录,则查找失败。
1.2 折半查找
折半查找也称二分查找,它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。在下面及后序的讨论中,均假设有序表是递增有序的。
折半查找的查找过程为:从表的中间记录开始,如果给定值和中间记录的关键字相等,则查找成功;如果给定值大于或者小于中间记录的关键字,则在表中大于或小于中间记录的那一半中查找,这样重复操作,直到查找成功,或者在某一步中查找区间为空,则代表查找失败。
折半查找每一次查找比较都使查找范围缩小一半,与顺序查找相比,很显然会提高查找效率。
如有序表(05,13,19,21,37,56,64,75,80,92),描述查找关键字21的过程如下:

1.3 分块查找
分块查找又称为索引顺序查找,它吸取了顺序查找和折半查找各自的优点,既有动态结构,又适于快速查找。
分块查找的思想:将查找表分为若干子块。块内的元素可以无序,但块之间是有序的,即第一块中的最大关键字小于第二块中的所有记录的关键字,第二个块中的最大关键字小于第三块中的所有记录的关键字,以此类推。再建立一个索引表,索引表中的每个元素含有各块的最大关键字和各块中的第一个元素的地址,索引表按关键字有序排列。
分块查找的过程分为两步:
- 第一步实在索引表中确定待查记录所在的块,可以顺序查找或折半查找索引表;
- 第二步是在块内顺序查找。
例如:关键码集合为{88,24,72,61,21,6,32,11,8,31,22,83,78,54},按照关键码值24,54,78,88分为四个块和索引表,如下图所示:

大作业一:实现简单查找
- 实现顺序查找
- 实现折半查找
- 实现分块查找
最后输出结果要求:
三种查找的结果返回形式为:存在返回值得索引,不存在则返回None。
输入案例为一个列表,自拟即可。
代码思路:(仅供参考,思路不限)
顺序查找:遍历一下列表,然后跟目标值比较,直到查找成功或查找失败。
折半查找:从有序列表的初始候选区 list[0:n-1] 开始,通过对待查找的值与候选区中间值得比较,可以使候选区减少一半。定义一个初始的left=0,right=n-1,然后计算中间值mid=(left+right)/2(整除),然后判断出中间元素与我们查找的元素的关系,如果一致则查找成功,如果不一致则更新left和right的值,再计算新的mid,重复上述步骤,直到查找成功或查找结束。
注:只有left小于right的时候候选区是有值的,也就是说只要left大于了right则查找失败。
分块查找:分块是在列表加入一个分块的操作,可以自己定义每一块的长度,最后一个不够该长度的也要自成一块,然后每一块中的最大值为该块的索引,因此在查找过程中,我们先在块与块之间使用折半查找或顺序查找,来定位待查找的数所处哪一块中,然后再在该块上使用顺序查找,最终查找成功或者失败。
# 遍历一下列表,然后跟目标值比较,直到查找成功或查找失败。
List = [1,10,23,3,11,30,5,16,34,7,20,50]
def find(x,List):
n = 0
index = None
for i in List:
if x==i:
index = n
n += 1
return index
find(7,List)

def binarySearch(x, arr, low, high):#迭代算法
while low <= high:
mid = (low+high)//2
if x == arr[mid]:
break
elif x < arr[mid]:
high = mid -1
else:
low = mid + 1
else:
print(None)
return
print(mid)
return
List=[2,4,5,6,8,9,12,45,65,70,83]
binarySearch(93,List,0,len(List)-1)
binarySearch(5,List,0,len(List)-1)

def search(data, key): # 用二分查找 想要查找的数据在哪块内
length = len(data) # 数据列表长度
first = 0 # 第一位数位置
last = length - 1 # 最后一个数据位置
print(f"长度:{length} 分块的数据是:{data}") # 输出分块情况
while first <= last:
mid = (last + first) // 2 # 取中间位置
if data[mid] > key: # 中间数据大于想要查的数据
last = mid - 1 # 将last的位置移到中间位置的前一位
elif data[mid] < key: # 中间数据小于想要查的数据
first = mid + 1 # 将first的位置移到中间位置的后一位
else:
return mid # 返回中间位置
return False
def block(data, count, key): # 分块查找数据,data是列表,count是每块的长度,key是想要查找的数据
length = len(data) # 表示数据列表的长度
block_length = length // count # 一共分的几块
if count * block_length != length: # 每块长度乘以分块总数不等于数据总长度
block_length += 1 # 块数加1
print("一共分", block_length, "块") # 块的多少
print("分块情况如下:")
for block_i in range(block_length): # 遍历每块数据
block_data = [] # 每块数据初始化
for i in range(count): # 遍历每块数据的位置
if block_i * count + i >= length: # 每块长度要与数据长度比较,一旦大于数据长度
break # 就退出循环
block_data.append(data[block_i * count + i]) # 每块长度要累加上一块的长度
result = search(block_data, key) # 调用二分查找的值
if result != False: # 查找的结果不为False
return block_i * count + result # 就返回块中的索引位置
return False
data = [23, 43, 56, 78, 97, 100, 120, 135, 147, 150, 155] # 数据列表
print('数据列表为:[23, 43, 56, 78, 97, 100, 120, 135, 147, 150, 155]')
goal = 100
print('查找 ',goal,'\\n')
result = block(data, 4, 100)
print("查找的值的索引位置是:", result) # 输出结果
大作业二:完成排序
题目:给定一个m×n的二维列表,查找一个数是否存在。列表有下列特性:
- 每一行的列表从左到右已经排序好。
- 每一行第一个数比上一行最后一个数大。
测试案例:输入如下列表(list = x),找数值3(target = 3),找到返回True,找不到返回False。
x = [[1,3,5,7],
[10,11,16,20],
[23,30,34,50]
]
代码思路:(仅供参考,思路不限)
可采用折半查找,但是要思考的是此时我们需要定位的数值的索引值将是二维列表的下标,因此mid将不是一个一维数字。
def find(target,arr):
rows=len(arr)-1
cols=len(arr[0])-1
i=rows
j=0
while i>=0 and j<=cols:
if target<arr[i][j]:
i-=1
elif target>arr[i][j]:
j+=1
else:
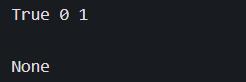
print(True,i,j)
return
print(None)
return
List = [
[1,3,5,7],
[10,11,16,20],
[23,30,34,50]
]
find(3,List)
print()
find(4,List)
大作业三:查找目标值
题目:给定一个有序列表和一个整数,设计算法找到两个数的下标,使得两个数之和为给定的整数。保证肯定且仅有一个结果。
测试案例:例如,输入列表[1,2,5,4]与目标整数3, 由1+2=3,因此输出的结果为(0,1)。
代码思路:(仅供参考,思路不限)
(1)可使用顺序查找,循环判断找到我们的目标值。
(2)我们可以根据一个数,通过目标数减去这个树然后得到另一个数,再来判断另一个数是否窜在,存在则输出他们的索引,不存在则换一个数重复上述步骤,直至成功。
def brute_force(li,target):
n=len(li)
for i in range(0,n):
for j in range(i+1,n):
if li[i]+li[j]==target:
return i,j
List = [1,2,5,4]
target = 3
brute_force(List,target)
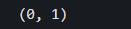
2、B-树
二叉排序树和平衡二叉树的查找方法均适用于存储在计算机内存中较小的文件,统称为内查找法。若文件很大且存放与外存进行查找时,这些查找方法就不适用了。内查找法都以结点为单位进行查找,这样需要反复进行内、外存的交换,是很费时的。因此,提出了一种适用于外查找的平衡多叉树——B-树,磁盘管理系统中的目录管理,以及数据库系统中的索引组织多数都采用B-树这种数据结构。
2.1 、B-树的定义
一棵m阶的B-树,或为空树,或为满足下列特性的m叉树:
(1)树中每个结点至多有m棵子树;
(2)若根结点不是叶子结点,则至少有两棵子树;
(3)除根之外的所有非终端结点至少有[m/2]棵子树
(4)所有的叶子结点都出现在同一层次上,并且不带信息,通常称为失败结点(失败结点并不存在,指向这些结点的指针为空。引入失败结点是为了便于分析B-树的查找性能);
(5)所有的非终端结点最多有m-1个关键字,结点的结构如下图所示。
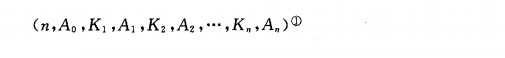
B-树具有平衡、有序、多路的特点,下图所示为一棵四阶的B-树,能很好地说明其特点。
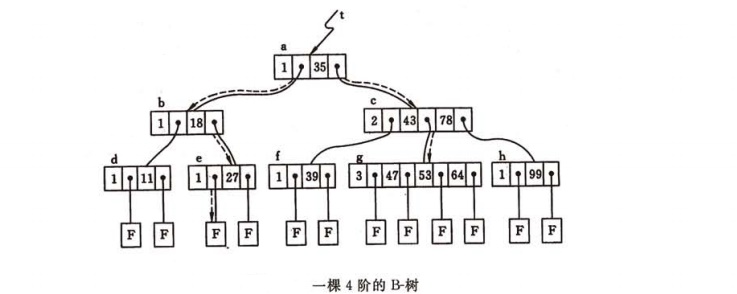
(1)所有叶子结点均在同一层次,这体现出其平衡的特点。
(2)树中每个结点中的关键字都是有序的,且关键字Ki “左子树”中的关键字均小于Ki,而其“右子树”中的关键字均大于Ki,这体现出其有序的特点。
(3)除叶子结点外,有的结点中有一个关键字,两棵子树,有的结点中有两个关键字,三颗子树。这种4阶的B-树最多有三个关键字,四棵子树,这体现出其多路的特点。
在具体实现时,为记录其双亲结点,B-树结点的存储结构通常增加一个parent指针,指向其双亲结点,存储结构示意图如下图所示。

2.2 B-树的查找
由B-树的定义可知,在B-树上进行查找的过程和二叉排序树的查找类似,可以看成二叉排序树的扩展,知识二叉排序树是二路查找,B-树是多路查找。在B-树查找时,结点内进行查找的时候除了顺序查找之外,还可以用二分查找来提高效率。
例如,上述展示的4阶的B-树查找关键字47的过程如下:首先从根开始,根据根结点指针 t 找到 *a 结点,因 *a结点中只有一个关键字,且47>35,若查找的记录存在,则必在指针 P1 所指的子树内,顺指针找到 *c结点,该结点有两个关键字(43和78),而43<47<78,若查找的记录存在,则必在指针P1所指的子树中。同样,顺指针找到 *g 结点,在该结点中顺序查找,查找到关键字47,由此,查找成功。
查找不成功的过程也类似,例如,在同一棵树中查找23。从根开始,因为23<35,则顺该结点中指针 Po 找到 *b 结点,又因为 *b 结点中只有一个关键字18,且23>18,所以顺结点中第二个指针 P1 找到 *e 结点。同理,因为23<27,则顺指针往下找,此时因指针所指为叶子结点,说明此棵B-树中不存在关键字23,查找因失败而告终。
由此可见,在B-树上进行查找的过程是一个顺指针查找结点,和在结点的关键字中查找交叉进行的过程。
在B-树上进行查找包含两种基本操作:(1)在B-树中找结点;(2)在结点中找关键字。
2.3 B-树的插入
B-树是动态查找树,因此其生成过程是从空树起,在查找的过程中通过逐个插入关键字而得到。但由于B-树中除根之外的所有非终端结点中的关键字个数必须大于等于[m/2]-1,因此,每次插入一个关键字不是在树中添加一个叶子结点,而是首先在最底层的某个非终端结点中添加一个关键字,若该结点的关键字个数不超过m-1,则插入完成,否则表明结点已满,要产生结点的“分裂”,将此结点在同一层分成两个结点。一般情况下,结点分裂方法是:以中间关键字为界把结点一分为二,成为两个结点,并把中间关键字向上插入到双亲结点上,若双亲结点已满,则采用同样的方法继续分解。最坏的情况下,一直分解到树根结点,这时B-树高度增加1。
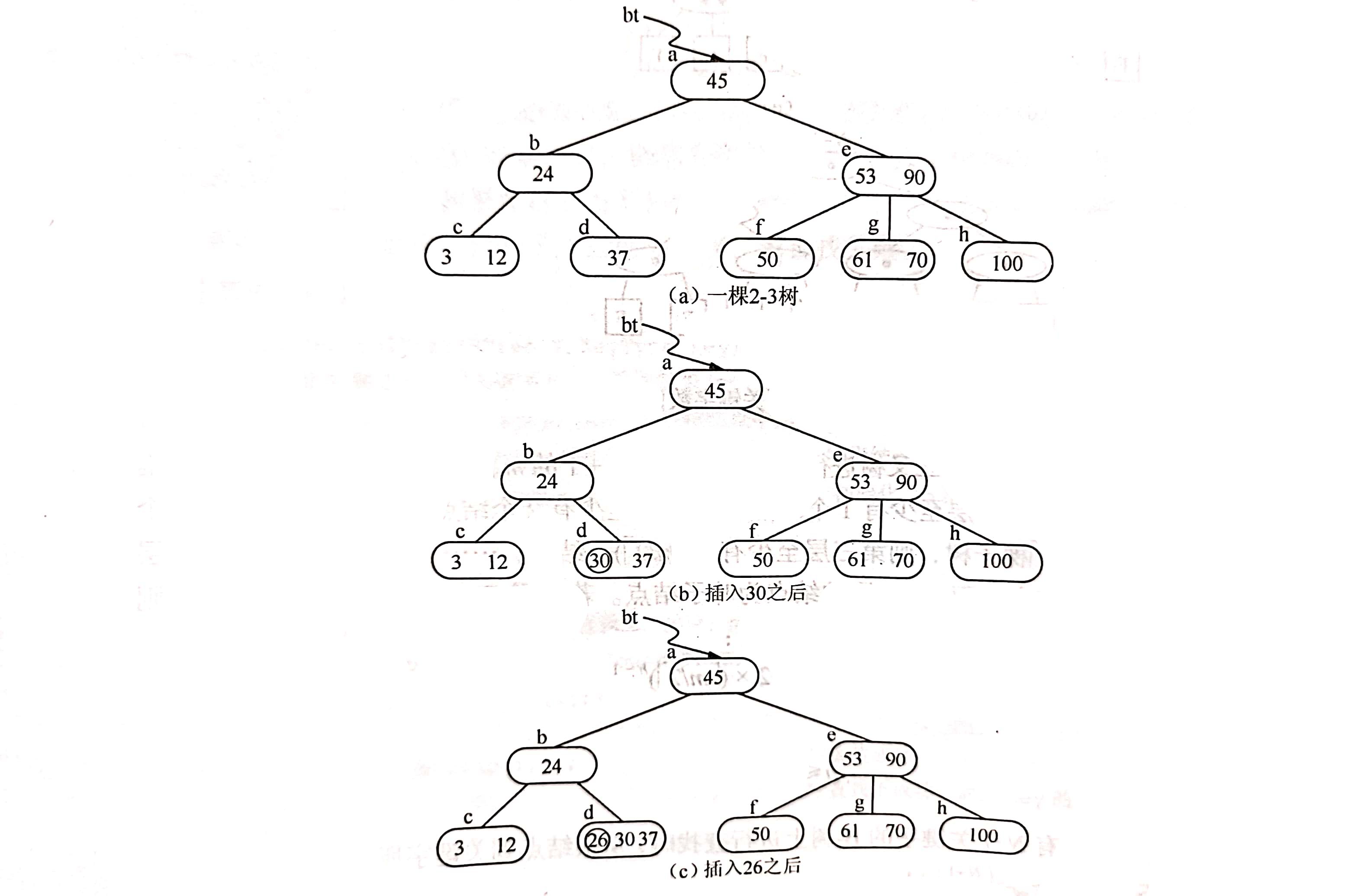
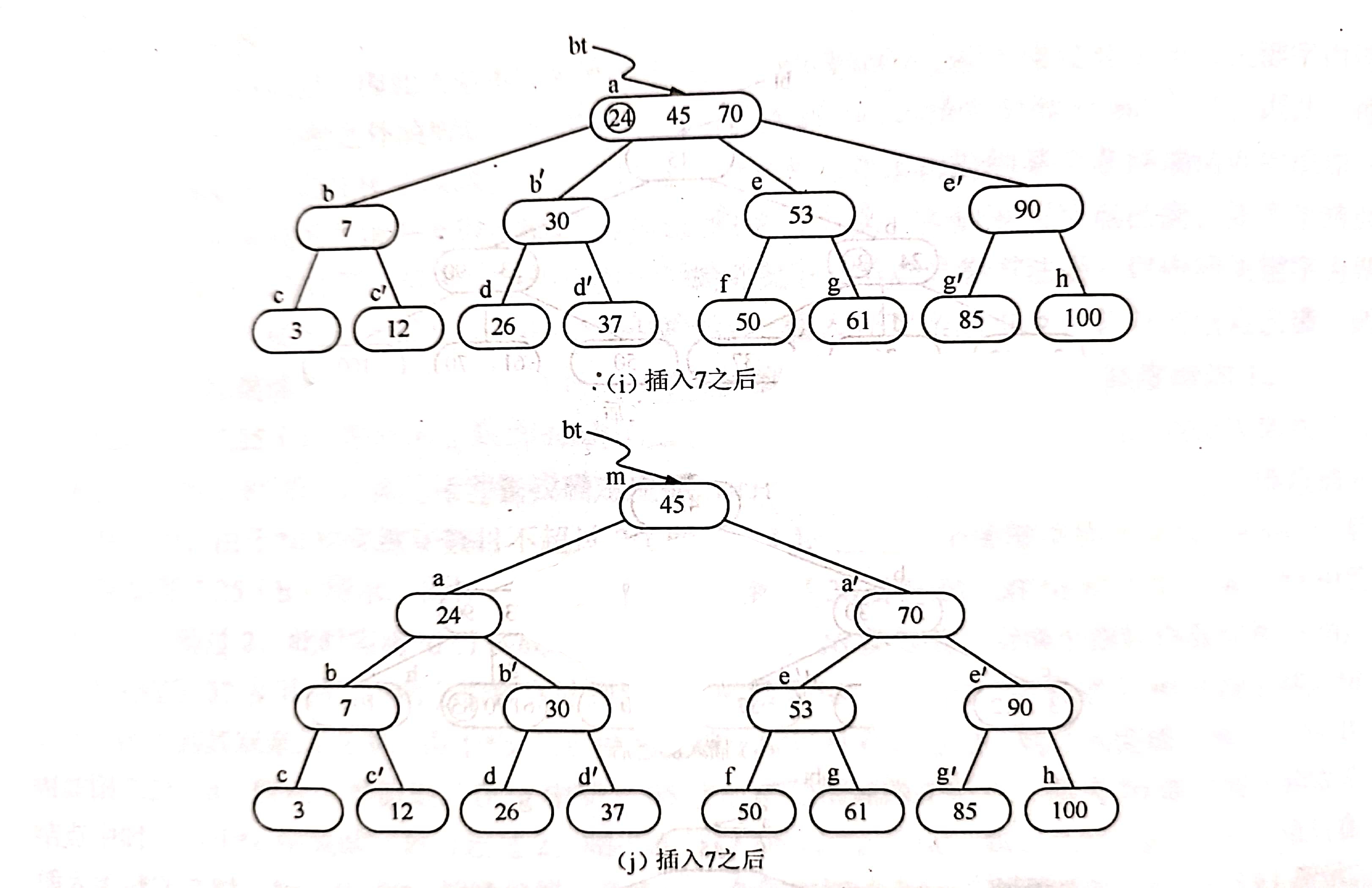
例如,下图中(a)所示为3阶的B-树(图中省去F结点即叶子结点),假设需要依次插入的关键字30、26、85和7。首先通过查找确定应插入的位置。
由根*a 起进行查找,确定30应插入在*d 结点中,由于*d 中关键字数目不超过2即(m-1),故第一个关键字插入完成。插入30后的B-树如图(b)所示。
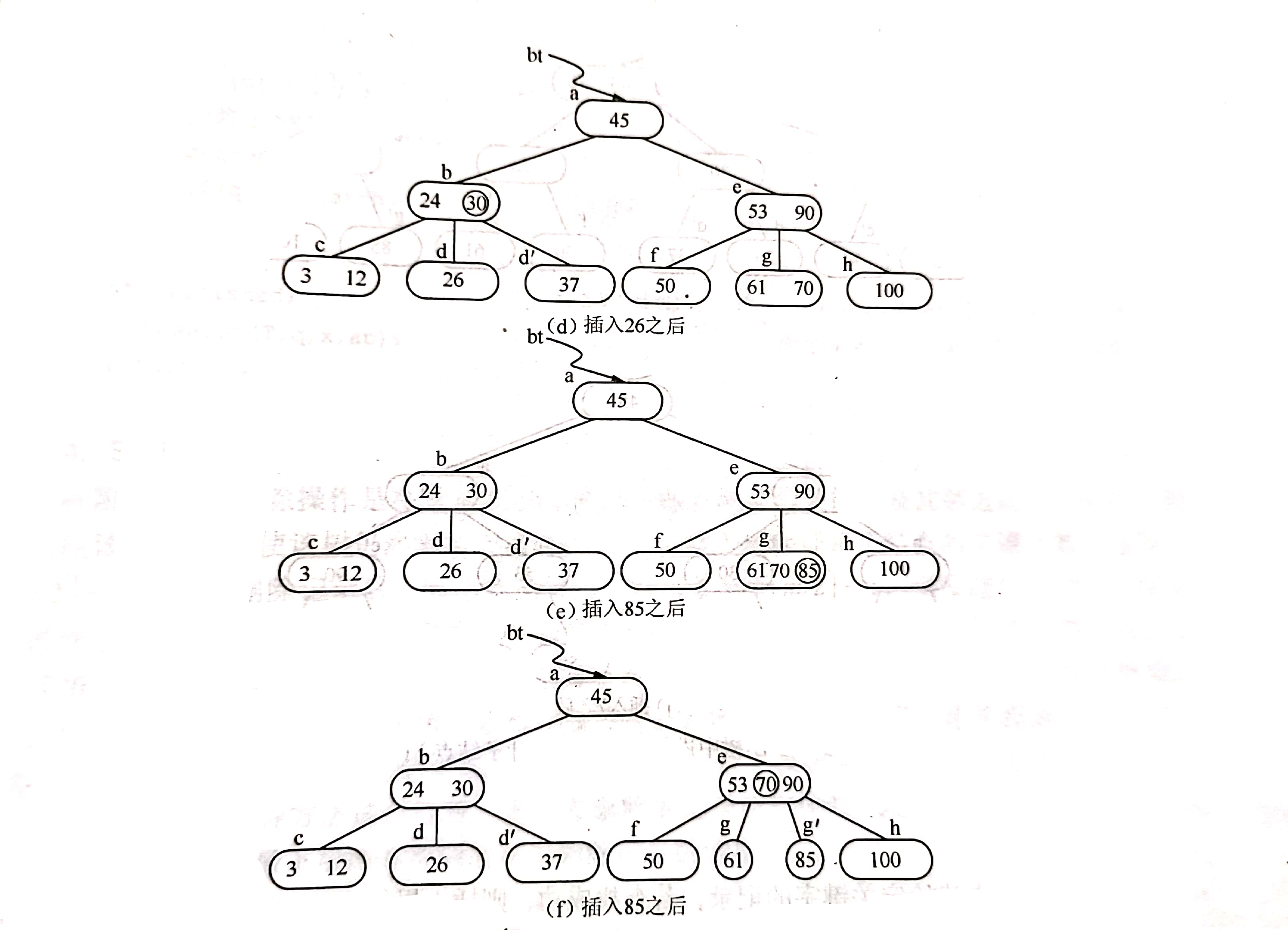
同样,通过查找确定关键字26亦应插入在*d 结点中。由于*d 中关键字的数目超过2,此时需要将*d分裂成两个结点,关键字26及其前、后两个指针仍保留在*d结点中,而关键字37及其前、后两个指针存储到新产生的结点 *d’ 中。同时,将关键字30和指示结点 *d’ 的指针插入到其双亲结点中。由于*b结点中的关键字数目没有超过2,则插入完成。插入后B-树如图(d)所示。
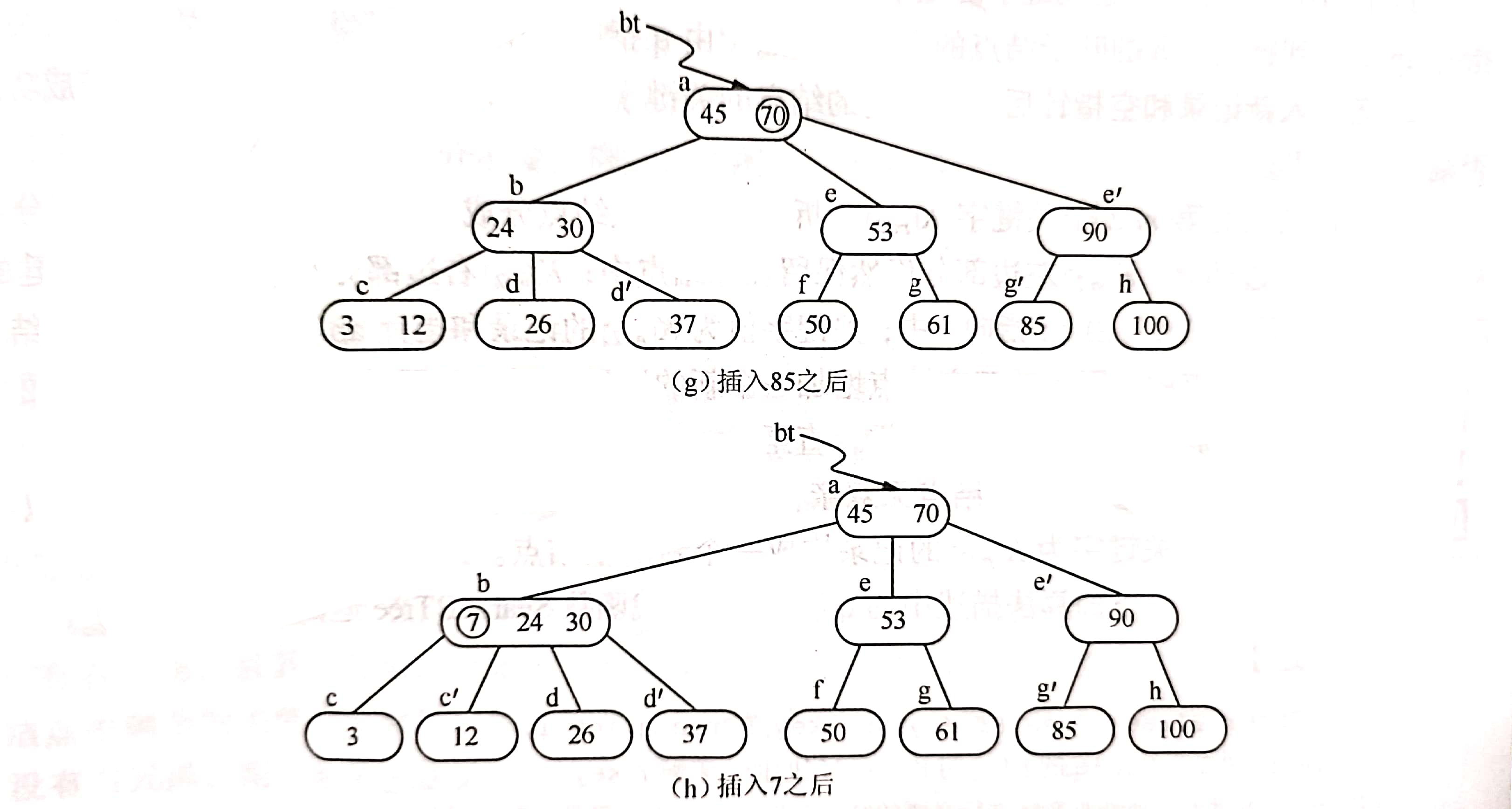
类似地,在*g中插入85之后需要分裂成两个结点,而当70继而插入到双亲结点中时,由于*e中关键字数目超过2,则再次分裂为结点*e 和*e’,如图(g)所示。
最后在插入关键字7时,*c、*b和*a相继分裂,并生成一个新的根结点*m,如图(h)~(j)所示。
2.4 B-树的删除
m阶B-树的删除操作是在B-树的某个结点中删除制定的关键字及其邻近的一个指针,删除后应进行调整使该树仍然满足B-树的定义,也就是要保证每个结点的关键字数目范围为[[m/2]-1,m]。删除记录后,结点的关键字个数如果小于[m/2]-1,则要进行“合并”结点的操作。除了删除记录,还要删除该记录邻近的指针。
- 若该结点为最下层的非终端结点,由于其指针均为空,删除后不会影响其他结点,可直接删除;
- 若该结点不是最下层的非终端结点,邻近的指针则指向一棵子树,不可直接删除。此时可做如下处理:将要删除记录用其右(左)边邻近指针指向的子树中关键字最小(大)的记录(该记录必定在最下层的非终端结点中)替换。采用这种方法进行处理,无论要删除的记录所在的结点是否为最下层的非终端结点,都可归结为在最下层的非终端结点中删除记录的情况。
例如,在下图所示的B-树上删去45,可以用*f结点中的50替代45,然后在*f结点中删去50。因此,下面可以只讨论删除最下层非终端结点中的关键字的情形。以下有3种可能:
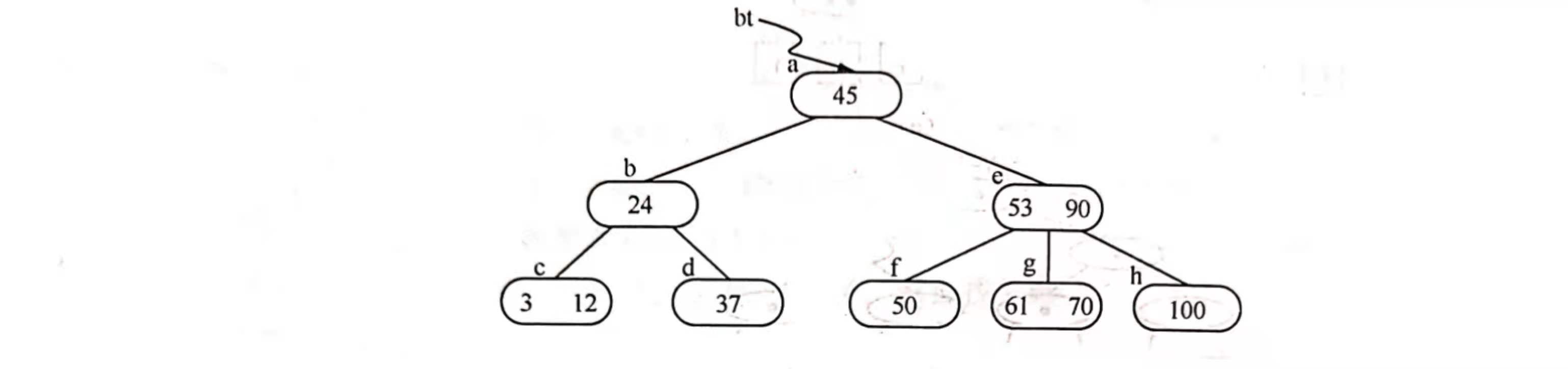
- (1)被删关键字所在结点中的关键字数目不小于[m/2],则只需从该结点中删去该关键字Ki和相应指针Pi,树的其他部分不变。例如,从上图所示B-树中删去关键字12,删除后的B-树如图(a)所示。
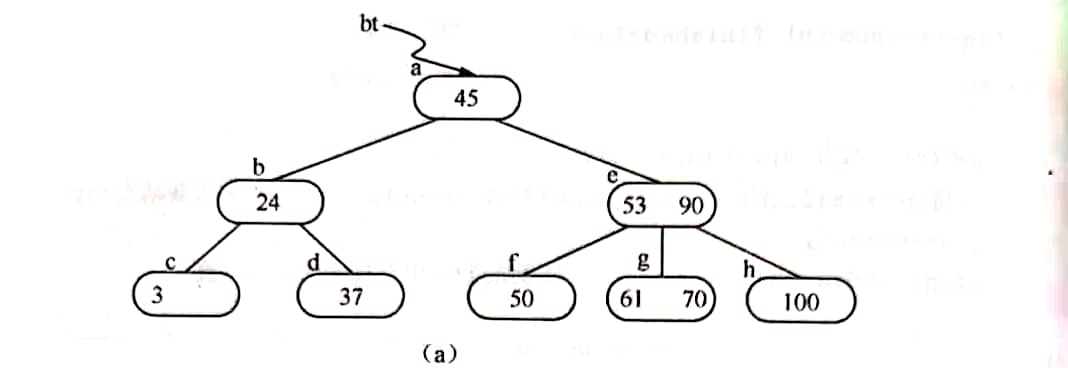
- (2)被删关键字所在结点中的关键字数目等于[m/2]-1,而与该结点相邻的右兄弟(或左兄弟)结点中的关键字数目大于[m/2]-1,则需将其兄弟结点中的最小(或最大)的关键字上移至双亲结点中,而将双亲结点中小于(或大于)且紧靠该上移关键字的关键字下移至被删关键字所在结点中。例如,从上图(a)中删去50,需将其右兄弟结点中的61上移至*e结点中,而将*e结点中的53移至*f,从而使*f和*g中关键字数目均不小于[m/2]-1,而双亲结点中的关键字数目不变,如图(b)所示。
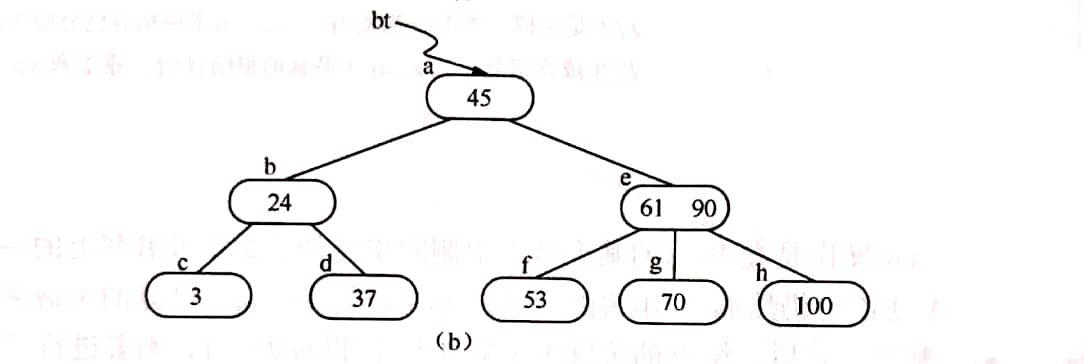
- (3)被删关键字所在结点和其相邻的兄弟结点中的关键字数目均等于[m/2]-1。假设该结点有右兄弟,且右兄弟结点地址由双亲结点中的指针Pi所指,则在删去关键字之后,它所在结点中剩余的关键字和指针,加上双亲结点中的关键字Ki一起,合并到Pi所指兄弟结点中(若没有右兄弟,则合并至左兄弟结点中)。例如,从上图(b)中删去53,则应删去*f结点,并将*f的剩余信息(指针“空”)和双亲*e结点中的61一起合并到右兄弟结点*g中,删除后的树如图(c)所示。
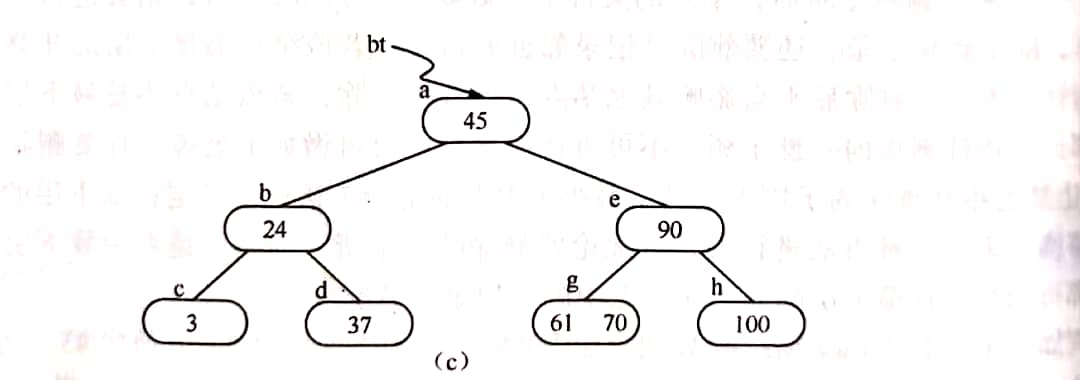
- (4)如果因此使双亲结点中关键字数目小于[m/2]-1,则依次类推做相应处理。例如,在图(c)的B-树中删去关键字37之后,双亲*b结点中剩余信息(指针c)应和其双亲*a结点中关键字45一起合并至右兄弟结点*e中,删除后的B-树如图(d)所示。
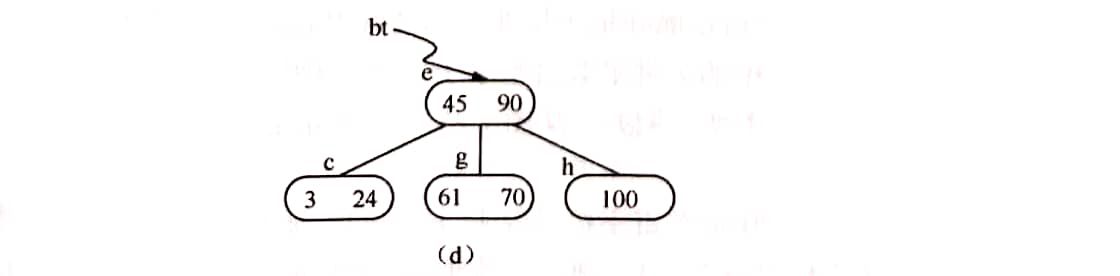
大作业四:完成B-树的操作
构建一个B-树的结点类和一个B-树类:
- 实现查找操作
- 实现插入操作
- 实现删除操作
最后输出结果要求:
测试列表为[45, 12, 53, 70, 3, 24, 37, 50, 61, 90, 100],生成的B-树为:
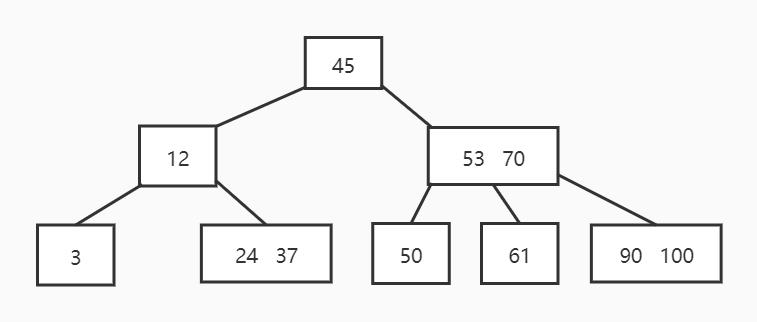
输出形式不限,参考格式为:

代码思路:(仅供参考,思路不限)
查找操作:将给定值key与根结点的各个关键字K1,K2,…,Kj(1<= j <= m-1)进行比较,由于该关键字序列是有序的,所以查找时可采用顺序查找,也可采用折半查找。查找时:
(1)若key = Ki(1<= i <=j),则查找成功;
(2)若key < K1,则顺着指针Po所指向的字数继续向下查找;
(3)若Ki < key < Ki+1(1<=i<=j-1),则顺着指针Pi所指向的子树继续向下查找;
(4)若key > Kj,则顺着指针Pj所指向的子树继续向下查找。
如果再自上而下的查找过程中,找到了值为key的关键字,则查找成功;如果直到叶子结点也未找到,则查找失败。
插入操作:
(1)在B-树中查找给定关键字的记录,若查找成功,则插入操作失败;否则将新纪录作为空指针ap插入到查找失败的叶子结点的上一层结点(由q指向)中。
(2)若插入新纪录和空指针后,q指向的结点的关键字个数未超过m-1,则插入操作成功,否则转入步骤(3).
(3)以该结点的第[m/2]个关键字K[m/2]为拆分点,将该结点分成3个部分:K[m/2]左边部分、K[m/2]、K[m/2]右边部分。K[m/2]部分仍然保留在原结点中;K[m/2]右边部分存放在一个新创建的结点(由ap指向)中;关键字值为K[m/2]的记录和指针ap插入到q的双亲结点中。因q的双亲结点增加一个新的记录,所以必须对q的双亲结点重复(2)和(3)的操作,依次类推,直至由q指向的结点是根结点,转入步骤(4)。
(4)由于根结点无双亲,则由其分裂产生的两个结点的指针ap和q,以及关键字为K[m/2]的记录构成一个新的根结点。此时,B-树的高度增加1。
删除操作:
(1)删除结点在叶子结点上
-
结点内的关键字个数大于d-1,可以直接删除(大于关键字个数下限,删除不影响 B - 树特性)
-
结点内的关键字个数等于d-1(等于关键字个数下限,删除后将破坏 特性),此时需观察该节点左右兄弟结点的关键字个数:
a. 旋转: 如果其左右兄弟结点中存在关键字个数大于d-1 的结点,则从关键字个数大于 d-1 的兄弟结点中借关键字:(这里看了网上的很多说法, 都是在介绍关键字的操作,而没有提到孩子结点. 我实现的时候想了很久才想出来: 借关键字时, 比如从右兄弟借一个关键字(第一个), 此时即为左旋, 将父亲结点对应关键字移到当前结点, 再将右兄弟的移动父亲结点(因为要满足排序性质, 类似二叉树的选择) 然后进行孩子操作, 将右兄弟的 插入到 当前结点的孩子指针末尾) 左兄弟类似, 而且要注意到边界条件, 比如当前结点是第0个/最后一个孩子, 则没有 左兄弟/右兄弟)
b. 合并: 如果其左右兄弟结点中不存在关键字个数大于 t-1 的结点,进行结点合并:将其父结点中的关键字拿到下一层,与该节点的左右兄弟结点的所有关键字合并,同样要注意到边界条件, 比如当前结点是第0个/最后一个孩子, 则没有 左兄弟/右兄弟
自底向上地检查来到这个叶子结点的路径上的结点是否满足关键字数目的要求, 只要关键字少于d-1,则进行旋转(2a)或者合并(2b)操作
(2)删除结点在非叶子结点上
查到到该结点, 然后转化成 上述 叶子结点中情况转化过程:
a. 找到相邻关键字:即需删除关键字的左子树中的最大关键字或右子树中的最小关键字
b. 用相邻关键字来覆盖需删除的非叶子节点关键字,再删除原相邻关键字(在;叶子上,这即为上述情况)。
from collections import deque
import math
m = 3
# m = 4
class MbtNode:
def __init__(self):
self.parent = None
self.key_num = 0
self.keys = deque()
self.sub_trees = deque()
# keys中keys[0]不会使用,keys[1]到keys[m-1]用于存储m-1个关键字,keys[m]用于插入第m个时结点会进行分裂,
# sub_trees[0]-sub_trees[m-1]用于存储m个子树,sub_trees[m]用于存储第m个时结点会进行分裂,
for i in range(m+1):
self.keys.append(None)
self.sub_trees.append(None)
self.info = None
class MbTree:
def __init__(self):
self.root = None
def search(mbt_node: MbtNode, key) -> int:
"""
在结点mbt_node中,寻找小于等于key的最大关键字序号
:param mbt_node: 在bmt_node中查找关键字key
:param key: 所查找关键字
:return: 返回key在mbt_node的keys中的所在位置或应插位置
"""
key_num = mbt_node.key_num
i = 1
while i <= key_num and mbt_node.keys[i] <= key:
i += 1
return i-1 # 返回key在mbt_node的keys中的所在位置或应插位置
def search_mb_tree(mb_tree: MbTree, key):
"""
在bm_tree的B树中查找关键字为key的结点,若查找成功,则将(所在结点、所在结点中的位置、True)返回;否则
将(key应插入的结点,插入结点的插入位置,False)返回
:param mb_tree: 查找的B树
:param key: 所查找的关键字
:return: 成功返回(所在结点、所在结点中的位置、True),失败返回(key应插入的结点,插入结点的插入位置,False)
"""
p = mb_tree.root
fp = None # p的双亲结点,当p为空时,fp就是key应插入的结点
i = 0 # 成功时i为key在所在结点中的位置,失败时为key应插入结点的插入位置
found = False # 表示是否找到key所在的结点
while p and not found:
# 退出循环时有两种情况
# (1) p为None时表示树中没有结点的keys中包含key
# (2) found为True时表示在树中找到key所在结点
i = search(p, key) # 查找key在p结点中的所在位置或应插位置
if p.keys[i] == key:
# 表示已找到key所在结点,需要退出循环
found = True
else:
# 表示为找到应到p.sub_trees[i]中去继续查找key
fp = p
p = p.sub_trees[i]
if found:
return p, i, True # 成功返回(所在结点、所在结点中的位置、True)
else:
return fp, i, False # 失败返回(key应插入的结点,插入结点的插入位置,False)
def insert(mbp: MbtNode, ipos: int, key, rp: MbtNode):
"""
在mbp结点的keys[ipos+1]处插入关键字key,sub_trees[ipos+1]处插入子结点rp
:param mbp:
:param ipos:
:param key:
:param rp:
:return: None
"""
mbp.keys.insert(ipos+1, key)
mbp.keys.pop()
mbp.sub_trees.insert(ipos+1, rp)
mbp.sub_trees.pop()
mbp.key_num += 1
def split(oldp: MbtNode):
"""
对oldp结点进行分裂
:param oldp: 所需分裂的旧结点
:return: # 返回根据旧结点右半部分所创建的新结点
"""
s = math.ceil(m/2) # 获取oldp的⌈m/2⌉的位置
n = m-s # 计算oldp的右半部分的key的个数
newp = MbtNode() # 创建新结点
newp.parent = oldp.parent # 新结点的双亲为旧结点的双亲
newp.key_num = n # 新结点的key的个数
if oldp.sub_trees[s]:
newp.sub_trees[0] = oldp.sub_trees[s] # 新结点的第0个子结点为oldp的第s个子结点
oldp.sub_trees[s] = None
newp.sub_trees[0].parent = newp # 将新结点的第一个子结点的双亲结点改为新结点
for i in range(1, n+1):
# 为新结点的keys和sub_trees赋值,新结点从下标为1处开始,旧结点从下标为s+1处开始
newp.keys[i] = oldp.keys[s+i]
oldp.keys[s + i] = None # 将旧结点的keys从s+1处变为None
if oldp.sub_trees[s+i]:
newp.sub_trees[i] = oldp.sub_trees[s+i]
oldp.sub_trees[s + i] = None # 将旧结点的sub_trees从s+1处变为None
newp.sub_trees