MySQL系列专题-MySQL的SQL语句和高级特性
Posted 波波烤鸭
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL系列专题-MySQL的SQL语句和高级特性相关的知识,希望对你有一定的参考价值。

一、 DML 操作【重点】
1.1 新增(INSERT)
1.1.1 添加一条信息
#添加一条工作岗位信息
INSERT INTO t_jobs(JOB_ID,JOB_TITLE,MIN_SALARY,MAX_SALARY) VALUES('JAVA_Le','JAVA_Lecturer',2500,9000);
#添加一条员工信息
INSERT INTO `t_employees`
(EMPLOYEE_ID,FIRST_NAME,LAST_NAME,EMAIL,PHONE_NUMBER,HIRE_DATE,JOB_ID,SALARY,COMMISSION_PCT,MANAGER_ID,DEPARTMENT_ID)
VALUES
('194','Samuel','McCain','SMCCAIN', '650.501.3876', '1998-07-01', 'SH_CLERK', '3200', NULL, '123', '50');
1.2 修改(UPDATE)
UPDATE 表名 SET 列 1=新值 1 ,列 2 = 新值 2,…WHERE 条件;
1.2.1 修改一条信息
#修改编号为100 的员工的工资为 25000
UPDATE t_employees SET SALARY = 25000 WHERE EMPLOYEE_ID = '100';
#修改编号为135 的员工信息岗位编号为 ST_MAN,工资为3500
UPDATE t_employees SET JOB_ID=ST_MAN,SALARY = 3500 WHERE EMPLOYEE_ID = '135';
1.3 删除(DELETE)
DELETE FROM 表名 WHERE 条件;
1.3.1 删除一条信息
#删除编号为135 的员工
DELETE FROM t_employees WHERE EMPLOYEE_ID='135';
#删除姓Peter,并且名为 Hall 的员工
DELETE FROM t_employees WHERE FIRST_NAME = 'Peter' AND LAST_NAME='Hall';
1.4 清空整表数据(TRUNCATE)
TRUNCATE TABLE 表名; 该语法不属于DML语句.
1.4.1 清空整张表
#清空t_countries整张表
TRUNCATE TABLE t_countries;
2、数据查询【重点】
2.1 数据库表的基本结构
关系结构数据库是以表格(Table)进行数据存储,表格由“行”和“列”组成
-- 员工表 employee
employee_id --编号
first_name --名字
email --邮箱
salary --月薪
commission_pct --提成
manager_id --所属经理编号
department_id --部门id
job_id --工作编号
-- 部门表 department
department_id --部门编号
department_name --部门名称
-- 工作表 job
job_id --工作id
job_name --工作名称
job_desc --工作内容
--经理表 manager
manager_id --经理编号
manager_name --经理名字
2.2 基本查询
| 关键字 | 描述 |
|---|---|
| SELECT | 指定要查询的列 |
| FROM | 指定要查询的表 |
2.2.1 查询部分列
#查询员工表中所有员工的编号、名字、邮箱
SELECT employee_id,first_name,email
FROM t_employees;
2.2.2 查询所有列
#查询员工表中所有员工的所有信息(所有列)
SELECT 所有列的列名 FROM t_employees;
SELECT * FROM t_employees;
2.2.3 对列中的数据进行运算
#查询员工表中所有员工的编号、名字、年薪
SELECT employee_id , first_name , salary*12
FROM t_employees;
| 算数运算符 | 描述 |
|---|---|
| + | 两列做加法运算 |
| - | 两列做减法运算 |
| * | 两列做乘法运算 |
| / | 两列做除法运算 |
2.2.4 列的别名
列 as ‘列名’
#查询员工表中所有员工的编号、名字、年薪(列名均为中文)
SELECT employee_id as "编号" , first_name as "名字" , salary*12 as "年薪"
FROM t_employees;
2.2.5 查询结果去重
DISTINCT 列名
#查询员工表中所有经理的ID。
SELECT DISTINCT manager_id
FROM t_employees;
2.3排序查询
语法: SELECT 列名 FROM 表名 ORDER BY 排序列 [排序规则]
| 排序规则 | 描述 |
|---|---|
| ASC | 对前面排序列做升序排序 |
| DESC | 对前面排序列做降序排序 |
2.3.1 依据单列排序
#查询员工的编号,名字,薪资。按照工资高低进行降序排序。
SELECT employee_id , first_name , salary
FROM t_employees
ORDER BY salary DESC;
2.3.2 依据多列排序
#查询员工的编号,名字,薪资。按照工资高低进行升序排序(薪资相同时,按照编号进行升序排序)。
SELECT employee_id , first_name , salary
FROM t_employees
ORDER BY salary DESC , employee_id ASC;
2.4 条件查询
语法:SELECT 列名 FROM 表名 WHERE 条件
| 关键字 | 描述 |
|---|---|
| WHERE 条件 | 在查询结果中,筛选符合条件的查询结果,条件为布尔表达式 |
2.4.1 等值判断(=)
#查询薪资是11000的员工信息(编号、名字、薪资)
SELECT employee_id , first_name , salary
FROM t_employees
WHERE salary = 11000;
2.4.2 逻辑判断(and、or、not)
#查询薪资是11000并且提成是0.30的员工信息(编号、名字、薪资)
SELECT employee_id , first_name , salary
FROM t_employees
WHERE salary = 11000 AND commission_pct = 0.30;
2.4.3 不等值判断(> 、< 、>= 、<= 、!= 、<>)
#查询员工的薪资在6000~10000之间的员工信息(编号,名字,薪资)
SELECT employee_id , first_name , salary
FROM t_employees
WHERE salary >= 6000 AND salary <= 10000;
2.4.4 区间判断(between and)
#查询员工的薪资在6000~10000之间的员工信息(编号,名字,薪资)
SELECT employee_id , first_name , salary
FROM t_employees
WHERE salary BETWEEN 6000 AND 10000; #闭区间,包含区间边界的两个值
2.4.5 NULL 值判断(IS NULL、IS NOT NULL)
- IS NULL
列名 IS NULL- IS NOT NULL
列名 IS NOT NULL
#查询没有提成的员工信息(编号,名字,薪资 , 提成)
SELECT employee_id , first_name , salary , commission_pct
FROM t_employees
WHERE commission_pct IS NULL;
2.4.6 枚举查询( IN (值 1,值 2,值 3 ) )
#查询部门编号为70、80、90的员工信息(编号,名字,薪资 , 部门编号)
SELECT employee_id , first_name , salary , department_id
FROM t_employees
WHERE department_id IN(70,80,90);
注:in的查询效率较低,可通过多条件拼接。
2.4.7 模糊查询
- LIKE _ (单个任意字符)
列名 LIKE ‘张_’- LIKE %(任意长度的任意字符)
列名 LIKE ‘张%’
#查询名字以"L"开头的员工信息(编号,名字,薪资 , 部门编号)
SELECT employee_id , first_name , salary , department_id
FROM t_employees
WHERE first_name LIKE 'L%';
#查询名字以"L"开头并且长度为4的员工信息(编号,名字,薪资 , 部门编号)
SELECT employee_id , first_name , salary , department_id
FROM t_employees
WHERE first_name LIKE 'L___';
2.4.8 分支结构查询
CASE
WHEN 条件1 THEN 结果1
WHEN 条件2 THEN 结果2
WHEN 条件3 THEN 结果3
ELSE 结果
END
#查询员工信息(编号,名字,薪资 , 薪资级别<对应条件表达式生成>)
SELECT employee_id , first_name , salary , department_id ,
CASE
WHEN salary>=10000 THEN 'A'
WHEN salary>=8000 AND salary<10000 THEN 'B'
WHEN salary>=6000 AND salary<8000 THEN 'C'
WHEN salary>=4000 AND salary<6000 THEN 'D'
ELSE 'E'
END as "LEVEL"
FROM t_employees;
2.5 时间查询
语法:SELECT 时间函数([参数列表])
| 时间函数 | 描述 |
|---|---|
| SYSDATE() | 当前系统时间(日、月、年、时、分、秒) |
| CURDATE() | 获取当前日期 |
| CURTIME() | 获取当前时间 |
| WEEK(DATE) | 获取指定日期为一年中的第几周 |
| YEAR(DATE) | 获取指定日期的年份 |
| HOUR(TIME) | 获取指定时间的小时值 |
| MINUTE(TIME) | 获取时间的分钟值 |
| DATEDIFF(DATE1,DATE2) | 获取DATE1 和 DATE2 之间相隔的天数 |
| ADDDATE(DATE,N) | 计算DATE 加上 N 天后的日期 |
2.5.1 获得当前系统时间
#查询当前时间
SELECT SYSDATE();
#查询当前时间
SELECT NOW();
#获取当前日期
SELECT CURDATE();
#获取当前时间
SELECT CURTIME();
2.6 字符串查询
语法: SELECT 字符串函数 ([参数列表])
| 字符串函数 | 说明 |
|---|---|
| CONCAT(str1,str2,str…) | 将 多个字符串连接 |
| INSERT(str,pos,len,newStr) | 将str 中指定 pos 位置开始 len 长度的内容替换为 newStr |
| LOWER(str) | 将指定字符串转换为小写 |
| UPPER(str) | 将指定字符串转换为大写 |
| SUBSTRING(str,num,len) | 将str 字符串指定num位置开始截取 len 个内容 |
2.6.1 字符串应用
#拼接内容
SELECT CONCAT('My','S','QL');
#字符串替换
SELECT INSERT('这是一个数据库',3,2,'mysql');#结果为这是 MySql 数据库
#指定内容转换为小写
SELECT LOWER('MYSQL');#mysql
#指定内容转换为大写
SELECT UPPER('mysql');#MYSQL
#指定内容截取
SELECT SUBSTRING('JavaMySQLOracle',5,5);#MySQL
2.7 聚合函数
语法:SELECT 聚合函数(列名) FROM 表名;
| 聚合函数 | 说明 |
|---|---|
| SUM() | 求所有行中单列结果的总和 |
| AVG() | 平均值 |
| MAX() | 最大值 |
| MIN() | 最小值 |
| COUNT() | 求总行数 |
2.7.1 单列总和
#统计所有员工每月的工资总和
SELECT sum(salary)
FROM t_employees;
2.7.2 单列平均值
#统计所有员工每月的平均工资
SELECT AVG(salary)
FROM t_employees;
2.7.3 单列最大值
#统计所有员工中月薪最高的工资
SELECT MAX(salary)
FROM t_employees;
2.7.4 单列最小值
#统计所有员工中月薪最低的工资
SELECT MIN(salary)
FROM t_employees;
2.7.5 总行数
#统计员工总数
SELECT COUNT(*)
FROM t_employees;
#统计有提成的员工人数
SELECT COUNT(commission_pct)
FROM t_employees;
2.8 分组查询
语法:SELECT 列名 FROM 表名 WHERE 条件 GROUP BY 分组依据(列);
| 关键字 | 说明 |
|---|---|
| GROUP BY | 分组依据,必须在 WHERE 之后生效 |
2.8.1 查询各部门的总人数
#思路:
#1.按照部门编号进行分组(分组依据是 department_id)
#2.再针对各部门的人数进行统计(count)
SELECT department_id,COUNT(employee_id)
FROM t_employees
GROUP BY department_id;
2.8.2 查询各部门的平均工资
#思路:
#1.按照部门编号进行分组(分组依据department_id)。
#2.针对每个部门进行平均工资统计(avg)。
SELECT department_id , AVG(salary)
FROM t_employees
GROUP BY department_id
2.8.3 查询各个部门、各个岗位的人数
#思路:
#1.按照部门编号进行分组(分组依据 department_id)。
#2.按照岗位名称进行分组(分组依据 job_id)。
#3.针对每个部门中的各个岗位进行人数统计(count)。
SELECT department_id , job_id , COUNT(employee_id)
FROM t_employees
GROUP BY department_id , job_id;
2.8.4 常见问题
#查询各个部门id、总人数、first_name
SELECT department_id , COUNT(*) , first_name
FROM t_employees
GROUP BY department_id; #error
2.9 分组过滤查询
语法:SELECT 列名 FROM 表名 WHERE 条件 GROUP BY 分组列 HAVING 过滤规则
| 关键字 | 说明 |
|---|---|
| HAVING 过滤规则 | 过滤规则定义对分组后的数据进行过滤 |
2.9.1 统计部门的最高工资
#统计60、70、90号部门的最高工资
#思路:
#1). 确定分组依据(department_id)
#2). 对分组后的数据,过滤出部门编号是60、70、90信息
#3). max()函数处理
SELECT department_id , MAX(salary)
FROM t_employees
GROUP BY department_id
HAVING department_id in (60,70,90)
# group确定分组依据department_id
#having过滤出60 70 90部门
#select查看部门编号和max函数。
2.10 限定查询
SELECT 列名 FROM 表名 LIMIT 起始行,查询行数
| 关键字 | 说明 |
|---|---|
| LIMIT offset_start,row_count | 限定查询结果的起始行和总行数 |
2.10.1 查询前 5 行记录
#查询表中前五名员工的所有信息
SELECT * FROM t_employees LIMIT 0,5;
2.10.2 查询范围记录
#查询表中从第四条开始,查询 10 行
SELECT * FROM t_employees LIMIT 3,10;
2.10.3 LIMIT典型应用
分页查询:一页显示 10 条,一共查询三页
#思路:第一页是从 0开始,显示 10 条
SELECT * FROM LIMIT 0,10;
#第二页是从第 10 条开始,显示 10 条
SELECT * FROM LIMIT 10,10;
#第三页是从 20 条开始,显示 10 条
SELECT * FROM LIMIT 20,10;
2.11 查询总结
2.11.1 SQL 语句编写顺序
SELECT 列名 FROM 表名 WHERE 条件 GROUP BY 分组 HAVING 过滤条件 ORDER BY 排序列(asc|desc)LIMIT 起始行,总条数
2.11.2 SQL 语句执行顺序
1.FROM :指定数据来源表
2.WHERE : 对查询数据做第一次过滤
3.GROUP BY : 分组
4.HAVING : 对分组后的数据第二次过滤
5.SELECT : 查询各字段的值
6.ORDER BY : 排序
7.LIMIT : 限定查询结果
2.12 子查询(作为条件判断)
SELECT 列名 FROM 表名 Where 条件 (子查询结果)
2.12.1 查询工资大于Bruce 的员工信息
#1.先查询到 Bruce 的工资(一行一列)
SELECT SALARY FROM t_employees WHERE FIRST_NAME = 'Bruce';#工资是 6000
#2.查询工资大于 Bruce 的员工信息
SELECT * FROM t_employees WHERE SALARY > 6000;
#3.将 1、2 两条语句整合
SELECT * FROM t_employees WHERE SALARY > (SELECT SALARY FROM t_employees WHERE FIRST_NAME = 'Bruce' );
2.13 子查询(作为枚举查询条件)
SELECT 列名 FROM 表名 Where 列名 in(子查询结果);
2.13.1 查询与名为’King’同一部门的员工信息
#思路:
#1. 先查询 'King' 所在的部门编号(多行单列)
SELECT department_id
FROM t_employees
WHERE last_name = 'King'; //部门编号:80、90
#2. 再查询80、90号部门的员工信息
SELECT employee_id , first_name , salary , department_id
FROM t_employees
WHERE department_id in (80,90);
#3.SQL:合并
SELECT employee_id , first_name , salary , department_id
FROM t_employees
WHERE department_id in (SELECT department_id cfrom t_employees WHERE last_name = 'King'); #N行一列
2.13.2 工资高于60部门所有人的信息
#1.查询 60 部门所有人的工资(多行多列)
SELECT SALARY from t_employees WHERE DEPARTMENT_ID=60;
#2.查询高于 60 部门所有人的工资的员工信息(高于所有)
select * from t_employees where SALARY > ALL(select SALARY from t_employees WHERE DEPARTMENT_ID=60);
#。查询高于 60 部门的工资的员工信息(高于部分)
select * from t_employees where SALARY > ANY(select SALARY from t_employees WHERE DEPARTMENT_ID=60);
2.14 子查询(作为一张表)
SELECT 列名 FROM(子查询的结果集)WHERE 条件;
2.14.1 查询员工表中工资排名前 5 名的员工信息
#思路:
#1. 先对所有员工的薪资进行排序(排序后的临时表)
select employee_id , first_name , salary
from t_employees
order by salary desc
#2. 再查询临时表中前5行员工信息
select employee_id , first_name , salary
from (临时表)
limit 0,5;
#SQL:合并
select employee_id , first_name , salary
from (select employee_id , first_name , salary from t_employees order by salary desc) as temp
limit 0,5;
2.15 合并查询(了解)
2.15.1 合并两张表的结果(去除重复记录)
#合并两张表的结果,去除重复记录
SELECT * FROM t1 UNION SELECT * FROM t2;
2.15.2 合并两张表的结果(保留重复记录)
#合并两张表的结果,不去除重复记录(显示所有)
SELECT * FROM t1 UNION ALL SELECT * FROM t2;
2.16 表连接查询
2.16.1 内连接查询(INNER JOIN ON)
#1.查询所有有部门的员工信息(不包括没有部门的员工) SQL 标准
SELECT * FROM t_employees INNER JOIN t_jobs ON t_employees.JOB_ID = t_jobs.JOB_ID
#2.查询所有有部门的员工信息(不包括没有部门的员工) MYSQL
SELECT * FROM t_employees,t_jobs WHERE t_employees.JOB_ID = t_jobs.JOB_ID
2.16.2 三表连接查询
#查询所有员工工号、名字、部门名称、部门所在国家ID
SELECT * FROM t_employees e
INNER JOIN t_departments d
on e.department_id = d.department_id
INNER JOIN t_locations l
ON d.location_id = l.location_id
2.16.3 左外连接(LEFT JOIN ON)
#查询所有员工信息,以及所对应的部门名称(没有部门的员工,也在查询结果中,部门名称以NULL 填充)
SELECT e.employee_id , e.first_name , e.salary , d.department_name FROM t_employees e
LEFT JOIN t_departments d
ON e.department_id = d.department_id;
2.16.4 右外连接(RIGHT JOIN ON)
#查询所有部门信息,以及此部门中的所有员工信息(没有员工的部门,也在查询结果中,员工信息以NULL 填充)
SELECT e.employee_id , e.first_name , e.salary , d.department_name FROM t_employees e
RIGHT JOIN t_departments d
ON e.department_id = d.department_id;
三、数据库高级
3.1 存储过程
MySQL 5.0 版本开始支持存储过程。存储过程思想上很简单,就是数据库 SQL 语言层面的代码封装与重用。
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。存储过程是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
DELIMITER $$ 或 DELIMITER // 这个代表当前sql语句的结尾符号不是 ; 而是变成了指定的 $$ 或者 // 因为在存储过程的创建过程中,我们会有;代表一行语句的结尾
3.1.1 创建存储过程
CREATE
[DEFINER = { user | CURRENT_USER }]
PROCEDURE sp_name ([proc_parameter[,...]])
[characteristic ...] routine_body
proc_parameter:
[ IN | OUT | INOUT ] param_name type
characteristic:
COMMENT 'string'
| LANGUAGE SQL
| [NOT] DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
routine_body:
Valid SQL routine statement
[begin_label:] BEGIN
[statement_list]
……
END [end_label]
DELIMITER $$
CREATE PROCEDURE pro_test1()
BEGIN
INSERT INTO t2(tname) VALUES('haha');
UPDATE t1 SET tname='jack1' WHERE tid=1;
SELECT * FROM t1;
END $$
call pro_test1()
3.1.2 存储过程参数
IN | OUT | INOUT 类型 名称 类型
in参数的使用
DELIMITER $$
CREATE PROCEDURE pro_test2(IN t2_name VARCHAR(20) , IN t1_id INT)
BEGIN
INSERT INTO t2(tname) VALUES(t2_name);
UPDATE t1 SET tname='jack1' WHERE tid=t1_id;
SELECT * FROM t1;
END $$
CALL pro_test2('hehe',2)
out参数的使用
DELIMITER $$
CREATE PROCEDURE pro_test3(OUT tname VARCHAR(20))
BEGIN
SET tname = 'xixi';
END $$
CALL pro_test3(@tname);
SELECT @tname;
inout参数的使用;尽量分开使用in和out,不使用inout
DELIMITER $$
CREATE PROCEDURE pro_test4(INOUT tname VARCHAR(20))
BEGIN
SELECT tname;
SELECT CONCAT(tname,"hello") INTO tname;
END $$
SET @tname='jack';
CALL pro_test4(@tname);
SELECT @tname;
3.1.3 存储过程变量
局部变量 DECLARE var_name[, var_name] … type [DEFAULT value];
set和默认值
declare num2 int default 100;
select num2;
DELIMITER $$
CREATE PROCEDURE pro_test5()
BEGIN
DECLARE num INT DEFAULT 100;
SELECT num;
set num = 200;
select num;
END $$
CALL pro_test5
使用 into 进行赋值
DELIMITER $$
CREATE PROCEDURE pro_test6()
BEGIN
DECLARE num INT DEFAULT 100;
SELECT num;
SELECT tid INTO num FROM t1 WHERE tname='jack';
SELECT num;
END $$
CALL pro_test6
用户变量 @变量名 不需要申明可直接使用;类似于Java全局变量
DELIMITER $$
CREATE PROCEDURE pro_test7()
BEGIN
SET @param_t1 = 300;
SELECT @param_t1;
SELECT tid INTO @param_t1 FROM t1 WHERE tname='jack';
SELECT @param_t1;
END $$
CALL pro_test7
系统变量 @@变量名
根据系统变量的作用域分为:全局变量与会话变量(两个@符号)
全局变量(@@global.)
在MySQL启动的时候由服务器自动将全局变量初始化为默认值;
全局变量的默认值可以通过更改MySQL配置文件(my.ini、my.cnf)来更改。
会话变量(@@session.)
在每次建立一个新的连接的时候,由MySQL来初始化;
MYSQL会将当前所有全局变量的值复制一份来做为会话变量(也就是说,如果在建立会话以后,没有手动更改过会话变量与全局变量的值,那所有这些变量的值都是一样的)。
全局变量与会话变量的区别:对全局变量的修改会影响到整个服务器,但是对会话变量的修改,只会影响到当前的会话。
3.1.4 条件语句
if-then-else 语句
IF expression THEN
statements;
END IF;
----------------------------------------
IF expression THEN
statements;
ELSE
else-statements;
END IF;
----------------------------------------
IF expression THEN
statements;
ELSEIF elseif-expression THEN
elseif-statements;
...
ELSE
else-statements;
END IF;
DELIMITER $$
CREATE PROCEDURE pro_test8(IN tid INT)
BEGIN
IF tid = 1 THEN
INSERT INTO t1(tname) VALUES('tom');
END IF;
END $$
CALL pro_test8(1);
-----------------------------------------------------------------
DELIMITER $$
CREATE PROCEDURE pro_test8(IN tid INT)
BEGIN
IF tid = 1 THEN
INSERT INTO t1(tname) VALUES('tom');
ELSE
SELECT CONCAT(tid,'xixi');
END IF;
END $$
CALL pro_test8(2);
---------------------------------------------------------------------
DELIMITER $$
CREATE PROCEDURE pro_test8(IN tid INT)
BEGIN
IF tid = 1 THEN
INSERT INTO t1(tname) VALUES('tom');
ELSEIF tid = 2 THEN
SELECT CONCAT(tid,'xixi');
ELSEIF tid = 3 THEN
SELECT CONCAT(tid,'xxxxxx');
END IF;
END $$
CALL pro_test8(3);
3.1.5 循环语句
WHILE……DO……END WHILE
REPEAT……UNTIL END REPEAT
LOOP……END LOOP
GOTO 不建议用
WHILE……DO……END WHILE
DELIMITER $$
CREATE PROCEDURE pro_test9(IN number INT)
BEGIN
-- 满足什么条件继续循环
WHILE number > 0 DO
SELECT number;
SET number=number-1;
END WHILE;
END $$
CALL pro_test9(6);
REPEAT……UNTIL END REPEAT
DELIMITER $$
CREATE PROCEDURE pro_test10(IN number INT)
BEGIN
REPEAT
INSERT INTO t1(tname) VALUES(CONCAT('aa',number));
SET number=number-1;
UNTIL number < 0 -- 这里不需要加分号 这个是满足什么条件退出循环
END REPEAT;
END $$
CALL pro_test10(6);
LOOP…LEAVE…END LOOP
DELIMITER $$
CREATE PROCEDURE pro_test11()
BEGIN
BEGIN
DECLARE i INT DEFAULT 0;
loop_x : LOOP
INSERT INTO t1(tname) VALUES(CONCAT('bb',i));
SET i=i+1;
IF i > 5 THEN
LEAVE loop_x;
END IF;
END LOOP;
END;
END $$
CALL pro_test11
3.1.6 分支语句
DELIMITER $$
CREATE PROCEDURE pro_test12(IN var INT)
BEGIN
CASE var
WHEN 1 THEN
SELECT 'a';
WHEN 2 THEN
SELECT 'b';
ELSE
SELECT 'c';
END CASE;
END $$
CALL pro_test12(2);
3.2 函数(了解)
自定义函数,和concat等内置函数意义一致
CREATE FUNCTION func_name ([param_name type[,...]])
RETURNS type
[characteristic ...]
BEGIN
routine_body
END;
(1)func_name :存储函数的名称。
(2)param_name type:可选项,指定存储函数的参数。
(3)RETURNS type:指定返回值的类型。
(4)characteristic:可选项,指定存储函数的特性。
(5)routine_body:SQL代码内容。
调用函数
SELECT func_name([parameter[,…]]);
DELIMITER //
CREATE FUNCTION fc_test(id INT)
RETURNS VARCHAR(20)
BEGIN
SELECT tname INTO @name FROM t1 WHERE tid=id;
RETURN @name;
END //
SELECT fc_test(2);
3.3 触发器Trigger(了解)
3.3.1 主外键级联操作

Cascade 在主表上update/delete记录时,同步update/delete掉子表的匹配记录
No Action 如果子表中有匹配的记录,则不允许对父表对应候选键进行update/delete操作
Restrict 同no action, 都是立即检查外键约束
Set null 在主表上update/delete记录时,将子表上匹配记录的列设为null
注: trigger不会受外键cascade行为的影响,即不会触发trigger
NULL、RESTRICT、NO ACTION
删除:从表记录不存在时,主表才可以删除。删除从表,主表不变
更新:从表记录不存在时,主表才可以更新。更新从表,主表不变
CASCADE
删除:删除主表时自动删除从表。删除从表,主表不变
更新:更新主表时自动更新从表。更新从表,主表不变
SET NULL
删除:删除主表时自动更新从表值为NULL。删除从表,主表不变
更新:更新主表时自动更新从表值为NULL。更新从表,主表不变
3.3.2 Trigger
触发器是与表有关的数据库对象,在满足定义条件时触发,并执行触发器中定义的语句集合。触发器的这种特性可以协助应用在数据库端确保数据的完整性。
CREATE TRIGGER trigger_name trigger_time trigger_event ON tb_name FOR EACH ROW trigger_stmt
trigger_name:触发器的名称
tirgger_time:触发时机,为BEFORE或者AFTER
trigger_event:触发事件,为INSERT、DELETE或者UPDATE
tb_name:表示建立触发器的表明,就是在哪张表上建立触发器
trigger_stmt:触发器的程序体,可以是一条SQL语句或者是用BEGIN和END包含的多条语句
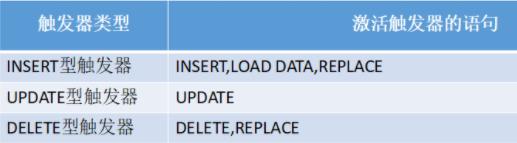
所以可以说MySQL创建以下六种触发器:
BEFORE INSERT,BEFORE DELETE,BEFORE UPDATE
AFTER INSERT,AFTER DELETE,AFTER UPDATE
BEFORE和AFTER参数指定了触发执行的时间,在事件之前或是之后
FOR EACH ROW表示任何一条记录上的操作满足触发事件都会触发该触发器
CREATE TRIGGER 触发器名 BEFORE|AFTER 触发事件
ON 表名 FOR EACH ROW
BEGIN
执行语句列表
END
DELIMITER $$
CREATE TRIGGER tri_test1 AFTER DELETE
ON t1 FOR EACH ROW
BEGIN
INSERT INTO t2(tname) VALUES('ssss');
END$$
SELECT * FROM t1;
SELECT * FROM t2;
UPDATE t1 SET tname = 'aaa' WHERE tid = 1;
DELETE FROM t1 WHERE tid=1;
3.4 视图(了解)
视图是一个虚拟表,是sql的查询结果,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据,在使用视图时动态生成。视图的数据变化会影响到基表,基表的数据变化也会影响到视图
1)简单:使用视图的用户完全不需要关心后面对应的表的结构、关联条件和筛选条件,对用户来说已经是过滤好的复合条件的结果集。
2)安全:使用视图的用户只能访问他们被允许查询的结果集,对表的权限管理并不能限制到某个行某个列,但是通过视图就可以简单的实现。
3)数据独立:一旦视图的结构确定了,可以屏蔽表结构变化对用户的影响,源表增加列对视图没有影响;源表修改列名,则可以通过修改视图来解决,不会造成对访问者的影响。
总而言之,使用视图的大部分情况是为了保障数据安全性,提高查询效率。
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
CREATE VIEW view_test1
AS
SELECT * FROM t1;
CREATE VIEW view_test2
AS
SELECT employee_id,first_name,manager_name FROM employee LEFT JOIN manager ON employee.`manager_id` = manager.`manager_id`;
3.5 索引和约束
3.5.1 约束
作用:是为了保证数据的完整性而实现的摘自一套机制,它具体的根据各个不同的数据库的实现而有不同的工具(约束);
1、非空约束:not null; 指示某列不能存储 NULL 值
2、唯一约束:unique(); unique约束的字段,要求必须是唯一的,但null除外;
3、主键约束:primary key(); 主键约束=not null + unique,确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
4、外键约束:foreign key ;保证一个表中的数据匹配另一个表中的值的参照完整性。
5、自增约束:auto_increment
6、默认约束:default 给定默认的值
7、检查性约束:check 保证列中的值符合指定的条件。
3.5.2 索引
作用: **快速定位特定数据,提高查询效率,确保数据的唯一性,快速定位特定数据;**可以加速表和表之间的连接,实现表与表之间的参照完整性,使用分组和排序语句进行数据检索时,可以显著减少分组和排序的时间全文检索字段进行搜索优化;
1、主键索引(primary key);
2、唯一索引(unique);
3、常规索引(index);
4、全文索引(full text);
全文索引是MyISAM的一个特殊索引类型,它查找的是文本中的关键词,主要用于全文检索。
MySQL InnoDB从5.6开始已经支持全文索引,但InnoDB内部并不支持中文、日文等,因为这些语言没有分隔符。可以使用插件辅助实现中文、日文等的全文索引。
SHOW INDEX FROM table_name;
索引字段尽量使用数字型(简单的数据类型)
尽量不要让字段的默认值为NULL
使用唯一索引
使用组合索引代替多个列索引
注意重复/冗余的索引、不使用的索引
不使用索引
1.查询中很少使用到的列 不应该创建索引,如果建立了索引然而还会降低mysql的性能和增大了空间需求.
2.很少数据的列也不应该建立索引,比如 一个性别字段 0或者1,在查询中,结果集的数据占了表中数据行的比例比较大,mysql需要扫描的行数很多,增加索引,并不能提高效率
3.定义为text和image和bit数据类型的列不应该增加索引,
4.当表的修改(UPDATE,INSERT,DELETE)操作远远大于检索(SELECT)操作时不应该创建索引,这两个操作是互斥的关系
搞定~
以上是关于MySQL系列专题-MySQL的SQL语句和高级特性的主要内容,如果未能解决你的问题,请参考以下文章