大数据Hive窗口函数应用实例
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Hive窗口函数应用实例相关的知识,希望对你有一定的参考价值。
目录
1 连续登陆用户
1.1 需求
当前有一份用户登录数据如下图所示,数据中有两个字段,分别是userId和loginTime。
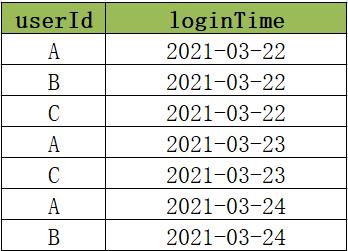
userId表示唯一的用户ID,唯一标识一个用户,loginTime表示用户的登录日期,例如第一条数据就表示A在2021年3月22日登录了。
现在需要对用户的登录次数进行统计,得到连续登陆N(N>=2)天的用户。
例如统计连续两天的登录的用户,需要返回A和C,因为A在22/23/24都登录了,所以肯定是连续两天登录,C在22和23号登录了,所以也是连续两天登录的。
例如统计连续三天的登录的用户,只能返回A,因为只有A是连续三天登录的。
1.2 分析
基于以上的需求根据数据寻找规律,要想得到连续登陆用户,必须找到两个相同用户ID的行之间登陆日期之间的关系。
例如:统计连续登陆两天的用户,只要用户ID相等,并且登陆日期之间相差1天即可。基于这个规律,我们有两种方案可以实现该需求。
方案一:实现表中的数据自连接,构建笛卡尔积,在结果中找到符合条件的id即可
方案二:使用窗口函数来实现
1.3 建表
➢ 创建表
--切换数据库
use db_function;
--建表
create table tb_login(
userid string,
logintime string
) row format delimited fields terminated by '\\t';
➢ 创建数据:vim /export/data/login.log\\
A 2021-03-22
B 2021-03-22
C 2021-03-22
A 2021-03-23
C 2021-03-23
A 2021-03-24
B 2021-03-24
➢ 加载数据
load data local inpath ‘/export/data/login.log’ into table tb_login;
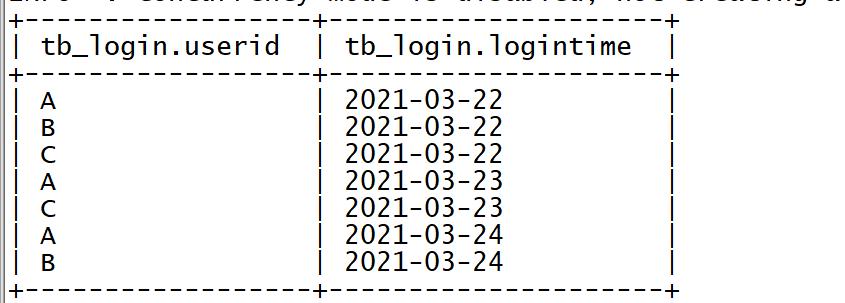
➢ 查询数据
select * from tb_login;
1.4 方案一:自连接过滤实现
➢ 构建笛卡尔积
select
a.userid as a_userid,
a.logintime as a_logintime,
b.userid as b_userid,
b.logintime as b_logintime
from tb_login a,tb_login b;
➢ 查看数据
+-----------+--------------+-----------+--------------+
| A_USERID | A_LOGINTIME | B_USERID | B_LOGINTIME |
+-----------+--------------+-----------+--------------+
| A | 2021-03-22 | A | 2021-03-22 |
| B | 2021-03-22 | A | 2021-03-22 |
| C | 2021-03-22 | A | 2021-03-22 |
| A | 2021-03-23 | A | 2021-03-22 |
| C | 2021-03-23 | A | 2021-03-22 |
| A | 2021-03-24 | A | 2021-03-22 |
| B | 2021-03-24 | A | 2021-03-22 |
| A | 2021-03-22 | B | 2021-03-22 |
| B | 2021-03-22 | B | 2021-03-22 |
| C | 2021-03-22 | B | 2021-03-22 |
| A | 2021-03-23 | B | 2021-03-22 |
| C | 2021-03-23 | B | 2021-03-22 |
| A | 2021-03-24 | B | 2021-03-22 |
| B | 2021-03-24 | B | 2021-03-22 |
| A | 2021-03-22 | C | 2021-03-22 |
| B | 2021-03-22 | C | 2021-03-22 |
| C | 2021-03-22 | C | 2021-03-22 |
| A | 2021-03-23 | C | 2021-03-22 |
| C | 2021-03-23 | C | 2021-03-22 |
| A | 2021-03-24 | C | 2021-03-22 |
| B | 2021-03-24 | C | 2021-03-22 |
| A | 2021-03-22 | A | 2021-03-23 |
| B | 2021-03-22 | A | 2021-03-23 |
| C | 2021-03-22 | A | 2021-03-23 |
| A | 2021-03-23 | A | 2021-03-23 |
| C | 2021-03-23 | A | 2021-03-23 |
| A | 2021-03-24 | A | 2021-03-23 |
| B | 2021-03-24 | A | 2021-03-23 |
| A | 2021-03-22 | C | 2021-03-23 |
| B | 2021-03-22 | C | 2021-03-23 |
| C | 2021-03-22 | C | 2021-03-23 |
| A | 2021-03-23 | C | 2021-03-23 |
| C | 2021-03-23 | C | 2021-03-23 |
| A | 2021-03-24 | C | 2021-03-23 |
| B | 2021-03-24 | C | 2021-03-23 |
| A | 2021-03-22 | A | 2021-03-24 |
| B | 2021-03-22 | A | 2021-03-24 |
| C | 2021-03-22 | A | 2021-03-24 |
| A | 2021-03-23 | A | 2021-03-24 |
| C | 2021-03-23 | A | 2021-03-24 |
| A | 2021-03-24 | A | 2021-03-24 |
| B | 2021-03-24 | A | 2021-03-24 |
| A | 2021-03-22 | B | 2021-03-24 |
| B | 2021-03-22 | B | 2021-03-24 |
| C | 2021-03-22 | B | 2021-03-24 |
| A | 2021-03-23 | B | 2021-03-24 |
| C | 2021-03-23 | B | 2021-03-24 |
| A | 2021-03-24 | B | 2021-03-24 |
| B | 2021-03-24 | B | 2021-03-24 |
+-----------+--------------+-----------+--------------+
➢ 保存为表
create table tb_login_tmp as
select
a.userid as a_userid,
a.logintime as a_logintime,
b.userid as b_userid,
b.logintime as b_logintime
from tb_login a,tb_login b;
➢ 过滤数据:用户id相同并且登陆日期相差1
select
a_userid,a_logintime,b_userid,b_logintime
from tb_login_tmp
where a_userid = b_userid
and cast(substr(a_logintime,9,2) as int) - 1 = cast(substr(b_logintime,9,2) as int);

➢ 统计连续登陆两天的用户
select
distinct a_userid
from tb_login_tmp
where a_userid = b_userid
and cast(substr(a_logintime,9,2) as int) - 1 = cast(substr(b_logintime,9,2) as int);
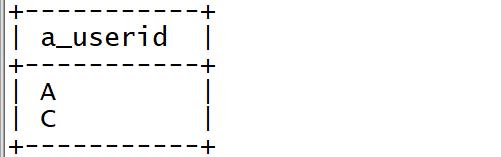
➢ 问题
如果现在需要统计连续3天的用户个数,如何实现呢?或者说需要统计连续5天、连续7天、连续10天、连续30天登陆的用户如何进行计算呢?
如果使用自连接的方式会非常的麻烦才能实现统计连续登陆两天以上的用户,并且性能很差,所以我们需要使用第二种方式来实现。
1.5 方案二:窗口函数实现
➢ 窗口函数lead
➢ 功能:用于从当前数据中基于当前行的数据向后偏移取值
➢ 语法:lead(colName,N,defautValue)
➢colName:取哪一列的值
➢N:向后偏移N行
➢ defaultValue:如果取不到返回的默认值
➢分析
当前数据中记录了每个用户每一次登陆的日期,一个用户在一天只有1条信息,我们可以基于用户的登陆信息,找到如下规律:
连续两天登陆 : 用户下次登陆时间 = 本次登陆以后的第二天
连续三天登陆 : 用户下下次登陆时间 = 本次登陆以后的第三天
……依次类推。
我们可以对用户ID进行分区,按照登陆时间进行排序,通过lead函数计算出用户下次登陆时间,通过日期函数计算出登陆以后第二天的日期,如果相等即为连续两天登录。
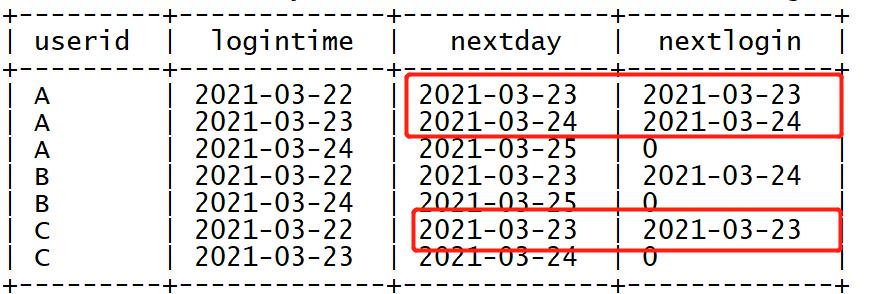
➢ 统计连续2天登录
select
userid,
logintime,
--本次登陆日期的第二天
date_add(logintime,1) as nextday,
--按照用户id分区,按照登陆日期排序,取下一次登陆时间,取不到就为0
lead(logintime,1,0) over (partition by userid order by logintime) as nextlogin
from tb_login;
with t1 as (
select
userid,
logintime,
–本次登陆日期的第二天
date_add(logintime,1) as nextday,
–按照用户id分区,按照登陆日期排序,取下一次登陆时间,取不到就为0
lead(logintime,1,0) over (partition by userid order by logintime) as nextlogin
from tb_login )
select distinct userid from t1 where nextday = nextlogin;
➢ 统计连续3天登录
select
userid,
logintime,
--本次登陆日期的第三天
date_add(logintime,2) as nextday,
--按照用户id分区,按照登陆日期排序,取下下一次登陆时间,取不到就为0
lead(logintime,2,0) over (partition by userid order by logintime) as nextlogin
from tb_login;

with t1 as (
select
userid,
logintime,
--本次登陆日期的第三天
date_add(logintime,2) as nextday,
--按照用户id分区,按照登陆日期排序,取下下一次登陆时间,取不到就为0
lead(logintime,2,0) over (partition by userid order by logintime) as nextlogin
from tb_login )
select distinct userid from t1 where nextday = nextlogin;
➢ 统计连续N天登录
select
userid,
logintime,
–本次登陆日期的第N天
date_add(logintime,N-1) as nextday,
–按照用户id分区,按照登陆日期排序,取下下一次登陆时间,取不到就为0
lead(logintime,N-1,0) over (partition by userid order by logintime) as nextlogin
from tb_login;
2 级联累加求和
2.1 需求
当前有一份消费数据如下,记录了每个用户在每个月的所有消费记录,数据表中一共有三列:

➢userId:用户唯一id,唯一标识一个用户
➢mth:用户消费的月份,一个用户可以在一个月多次消费
➢money:用户每次消费的金额
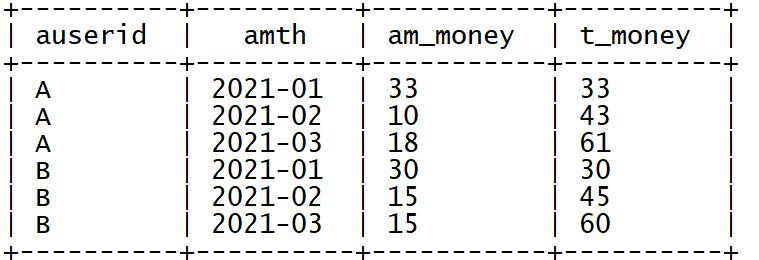
现在需要基于用户每个月的多次消费的记录进行分析,统计得到每个用户在每个月的消费总金额以及当前累计消费总金额,最后结果如下:
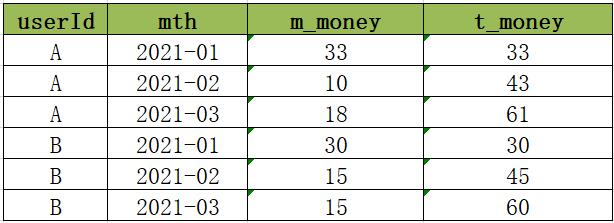
以用户A为例:
A在2021年1月份,共四次消费,分别消费5元、15元、8元、5元,所以本月共消费33元,累计消费33元。
A在2021年2月份,共两次消费,分别消费4元、6元,所以本月共消费10元,累计消费43元。
2.2 分析
如果要实现以上需求,首先要统计出每个用户每个月的消费总金额,分组实现集合,但是需要按照用户ID,将该用户这个月之前的所有月份的消费总金额进行累加实现。该需求可以通过两种方案来实现:
方案一:分组统计每个用户每个月的消费金额,然后构建自连接,根据条件分组聚合
方案二:分组统计每个用户每个月的消费金额,然后使用窗口聚合函数实现
2.3 建表
➢ 创建表
--切换数据库
use db_function;
--建表
create table tb_money(
userid string,
mth string,
money int
) row format delimited fields terminated by '\\t';
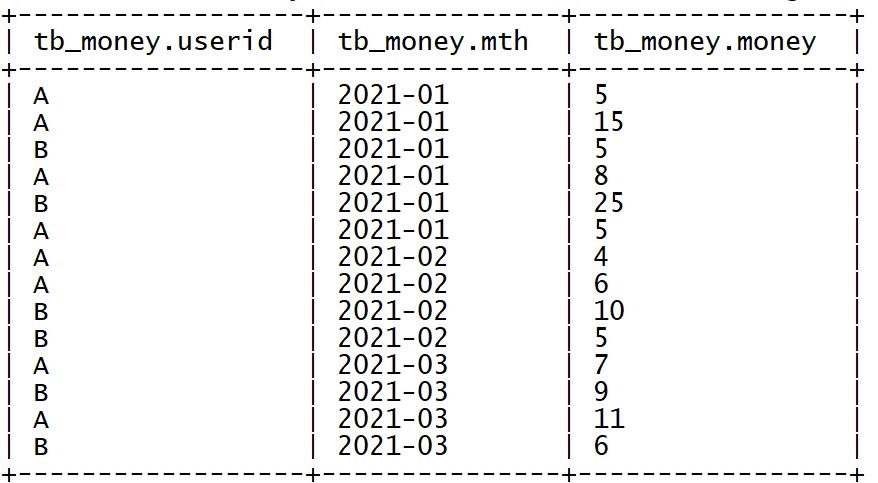
➢ 创建数据:vim /export/data/money.tsv
A 2021-01 5
A 2021-01 15
B 2021-01 5
A 2021-01 8
B 2021-01 25
A 2021-01 5
A 2021-02 4
A 2021-02 6
B 2021-02 10
B 2021-02 5
A 2021-03 7
B 2021-03 9
A 2021-03 11
B 2021-03 6
➢加载数据
load data local inpath ‘/export/data/money.tsv’ into table tb_money;
➢ 查询数据
select * from tb_money;
 ➢ 统计得到每个用户每个月的消费总金额
➢ 统计得到每个用户每个月的消费总金额
create table tb_money_mtn as
select
userid,
mth,
sum(money) as m_money
from tb_money
group by userid,mth;

2.4 方案一:自连接分组聚合
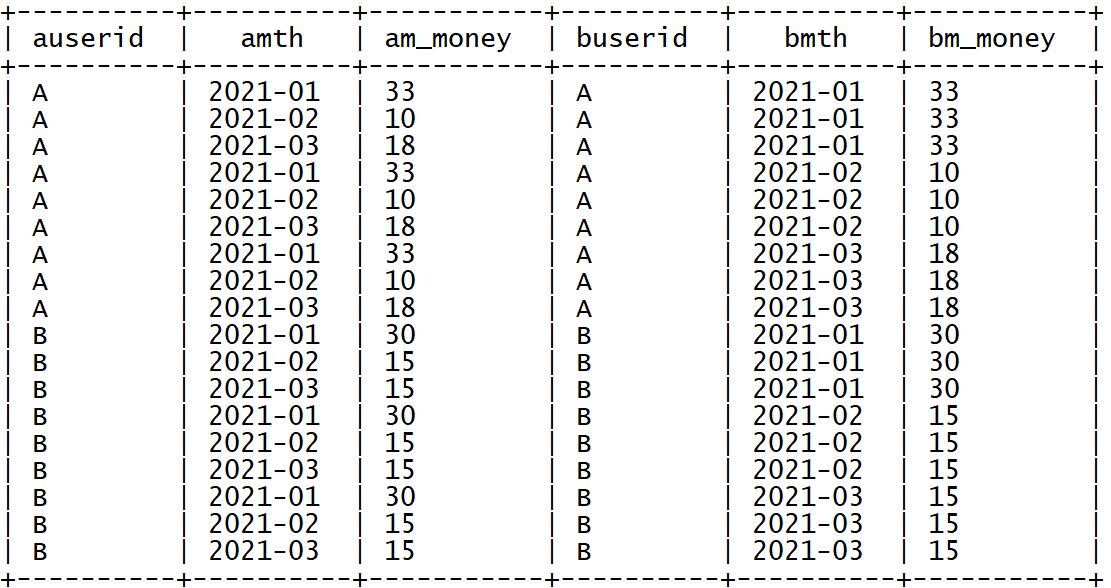
➢ 基于每个用户每个月的消费总金额进行自连接
select
a.userid as auserid,
a.mth as amth,
a.m_money as am_money,
b.userid as buserid,
b.mth as bmth,
b.m_money as bm_money
from tb_money_mtn a join tb_money_mtn b on a.userid = b.userid;
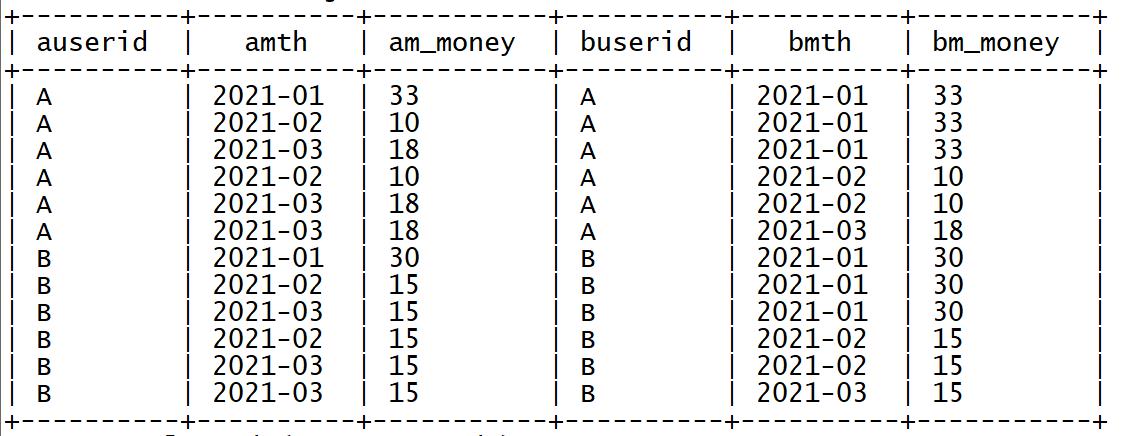
➢ 将每个月之前月份的数据过滤出来
select
a.userid as auserid,
a.mth as amth,
a.m_money as am_money,
b.userid as buserid,
b.mth as bmth,
b.m_money as bm_money
from tb_money_mtn a join tb_money_mtn b on a.userid = b.userid
where a.mth >= b.mth;
➢ 对每个用户每个月的金额进行分组,聚合之前月份的消费金额
select
a.userid as auserid,
a.mth as amth,
a.m_money as am_money,
sum(b.m_money) as t_money
from tb_money_mtn a join tb_money_mtn b on a.userid = b.userid
where a.mth >= b.mth
group by a.userid,a.mth,a.m_money;
2.5 方案二:窗口函数实现
➢ 窗口函数sum
➢ 功能:用于实现基于窗口的数据求和
➢ 语法:sum(colName) over (partition by col order by col)
➢colName:对某一列的值进行求和
➢分析
基于每个用户每个月的消费金额,可以通过窗口函数对用户进行分区,按照月份排序,然后基于聚合窗口,从每个分区的第一行累加到当前和,即可得到累计消费金额。
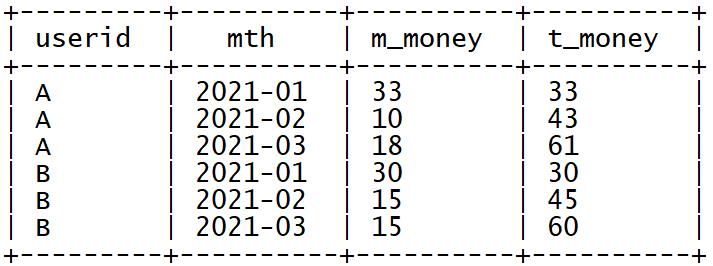
➢ 统计每个用户每个月消费金额及累计总金额
select
userid,
mth,
m_money,
sum(m_money) over (partition by userid order by mth) as t_money
from tb_money_mtn;
3 分组TopN
3.1 需求
工作中经常需要实现TopN的需求,例如热门商品Top10、热门话题Top20、热门搜索Top10、地区用户Top10等等,TopN是大数据业务分析中最常见的需求。
普通的TopN只要基于数据进行排序,然后基于排序后的结果取前N个即可,相对简单,但是在TopN中有一种特殊的TopN计算,叫做分组TopN。
分组TopN指的是基于数据进行分组,从每个组内取TopN,不再基于全局取TopN。如果要实现分组取TopN就相对麻烦。
例如:现在有一份数据如下,记录这所有员工的信息: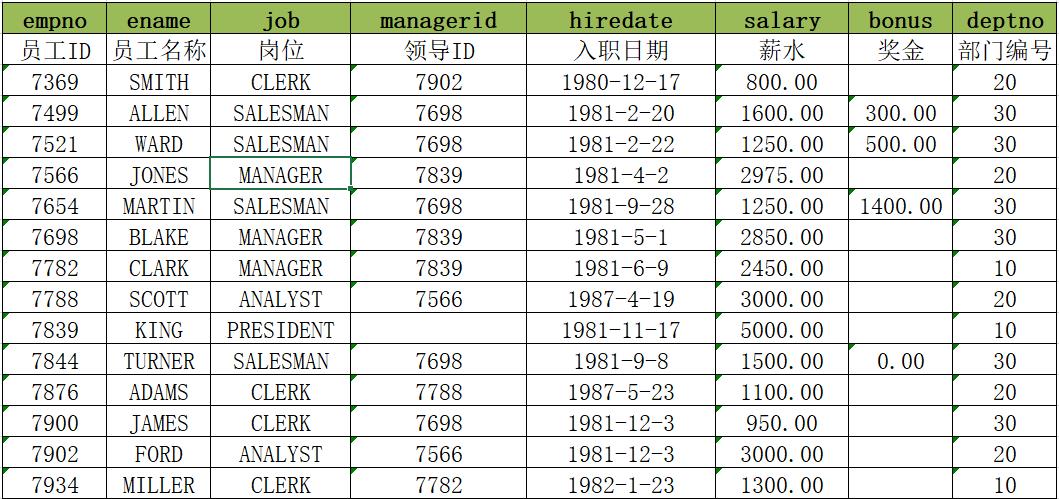
如果现在有一个需求:查询每个部门薪资最高的员工的薪水,这个可以直接基于表中数据分组查询得到
select deptno,max(salary) from tb_emp group by deptno;
但是如果现在需求修改为:统计查询每个部门薪资最高的前两名员工的薪水,这时候应该如何实现呢?
3.2 分析
根据上述需求,这种情况下是无法根据group by分组聚合实现的,因为分组聚合只能实现返回一条聚合的结果,但是需求中需要每个部门返回薪资最高的前两名,有两条结果,这时候就需要用到窗口函数中的分区来实现了。
3.3 建表
➢ 创建表
--切换数据库
use db_function;
--建表
create table tb_emp(
empno string,
ename string,
job string,
managerid string,
hiredate string,
salary double,
bonus double,
deptno string
) row format delimited fields terminated by '\\t';
➢创建数据:vim /export/data/emp.txt
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10
➢ 加载数据
load data local inpath ‘/export/data/emp.txt’ into table tb_emp;
➢查询数据
select empno,ename,salary,deptno from tb_emp;
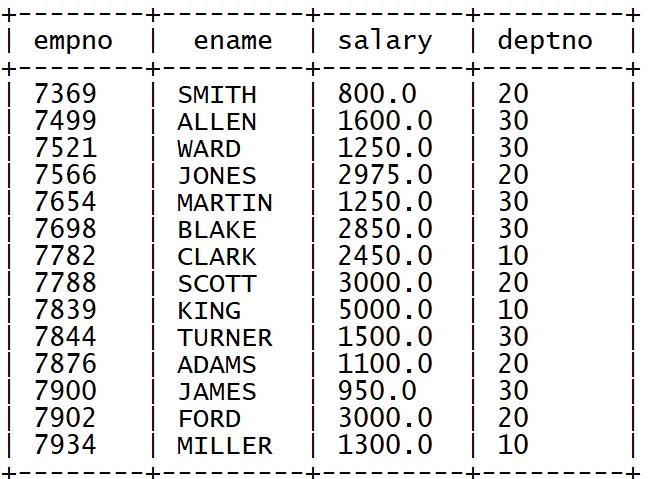
3.4 实现
➢ TopN函数:row_number、rank、dense_rank
➢ row_number:对每个分区的数据进行编号,如果值相同,继续编号
➢ rank:对每个分区的数据进行编号,如果值相同,编号相同,但留下空位
➢ dense_rank:对每个分区的数据进行编号,如果值相同,编号相同,不留下空位
➢ 基于row_number实现,按照部门分区,每个部门内部按照薪水降序排序
select
empno,
ename,
salary,
deptno,
row_number() over (partition by deptno order by salary desc) as rn
from tb_emp;
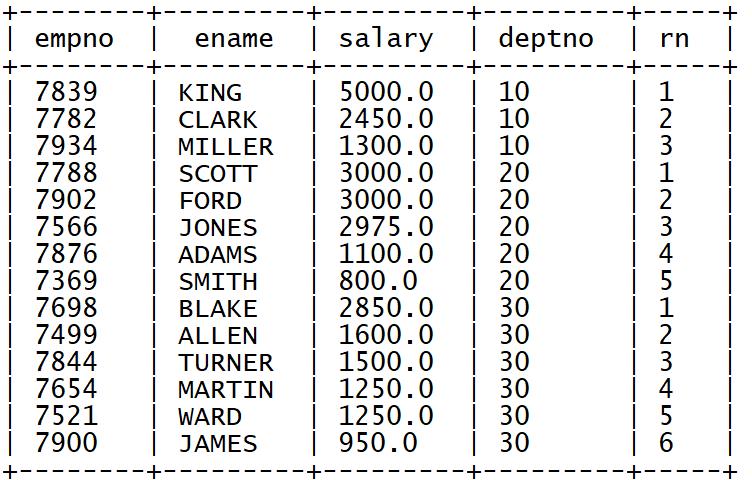
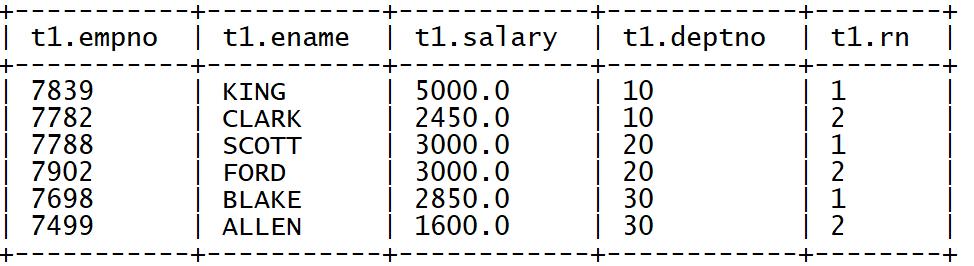
➢ 过滤每个部门的薪资最高的前两名
with t1 as (
select
empno,
ename,
salary,
deptno,
row_number() over (partition by deptno order by salary desc) as rn
from tb_emp )
select * from t1 where rn < 3;
以上是关于大数据Hive窗口函数应用实例的主要内容,如果未能解决你的问题,请参考以下文章