hadoop大数据优化之数据倾斜
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop大数据优化之数据倾斜相关的知识,希望对你有一定的参考价值。
💫一直想写一篇关于数据倾斜的问题,面试必问,可自己又没有碰见过,一直难以下手,最近公司大佬讲述了一节关于数据倾斜的课程,对数据倾斜有了更深的理解,于是想记录一下,关于hadoop的shuffle和spark的shuffle可以查看下面的文章👇:
- hadoop的shuffle: hadoop之MR核心shuffle.
- spark的shuffle: Spark之RDD算子.
🌻关于数据倾斜的原因,其实最容易地就是发生在shuffle过程,在hadoop中,只有单一的MR任务,MR任务会发生shuffle,而spark中有多种丰富的rdd算子,在很多算子中都会发生shuffle过程。本文还是主要讲述hadoop的数据倾斜,也就是我们常说的shuffle过程的数据倾斜,spark数据倾斜的原因和hadoop也差不多。
1. 发生数据倾斜的现象
在数据加工过程中,数据的产出时效要比预期的差很多,加工时间过长,这时候就需要我们对问题进行分析,处理相关问题,由于引擎自带一部分计算策略,加工时间过长问题,大部分是由于数据倾斜造成的:
- spark绝大数task任务执行非常快,几分钟结束任务,但是极个别的task任务执行非常非常慢,会超过一个小时或者更久的时间。
- 用Hive算数据的时候reduce阶段卡在99.99%。
- 在spark作业时候,原本可以正常运行的任务,突然有一天内存溢出而其他的executor内存使用率缺很低。
如图:我们查看hadoop的日志,发现map的任务数是7完成7个,reduce的个数是6完成5个。
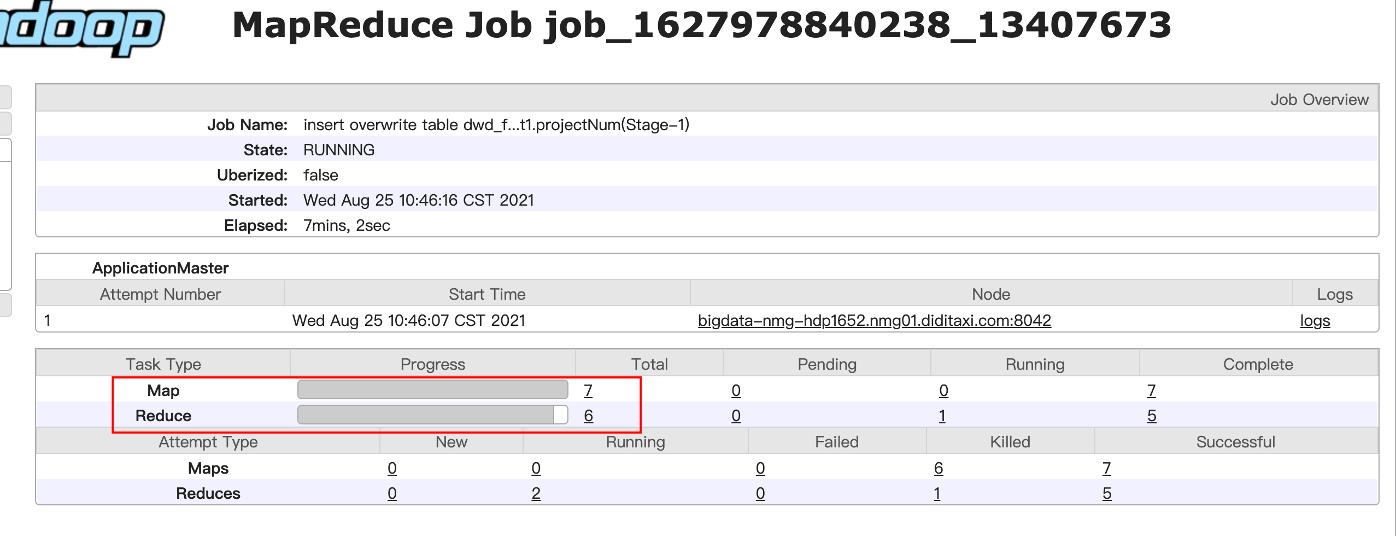
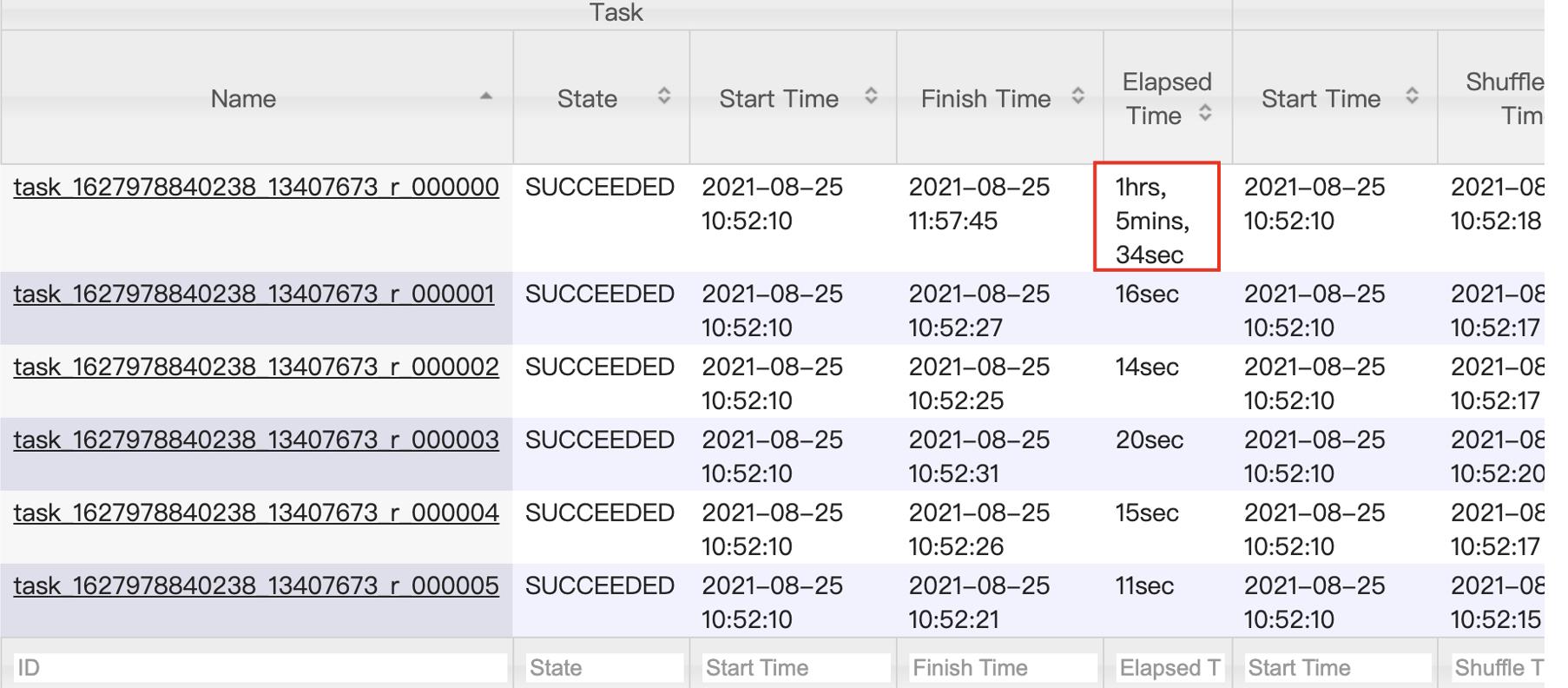
我们再看看任务的明细:我们发现以一个reduce任务时间长度远远超过其他reduce任务,很明显发生了数据倾斜。
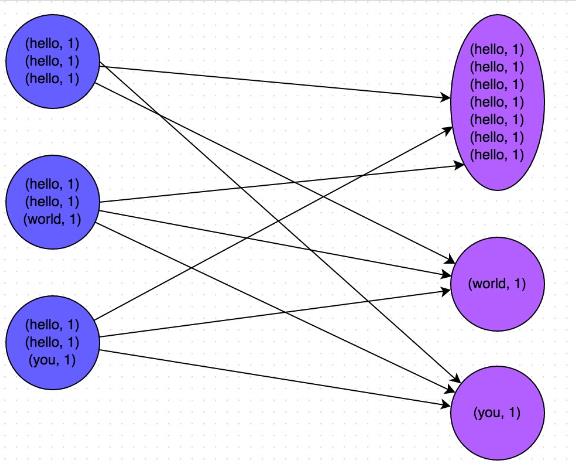
一般发生数据倾斜的地方都是发生shuffle的地方,典型的rdd算子有:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等,发生倾斜时大家注意一下这些地方。
2. 发生数据倾斜的原理(MR任务)
在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作。此时如果某个key对应的数据量特别大的话,就会发生数据倾斜。比如大部分key对应10条数据,但是个别key却对应了100万条数据,那么大部分task可能就只会分配到10条数据,然后1秒钟就运行完了;但是个别task可能分配到了100万数据,要运行一两个小时。
3. 解决方式
3.1 将不均匀的key值打散
这种情况就是绝大部分的key对应10%的数据,而很少部分的key对应90%的数据。
对于这种情况,我们可以给key值加上随机数,将数据量过多的key值打散。这种方式特别适合数据的key为空时,数据量特别大,但在做join连接时,key值为空的数据本身就没有意义,还需要分配一个reduce进行计算,而且数据量还很大,所以我们就可以采用拼接的方式,拼接一个字符串。这样子就可以将不同的为空的key打散到不同的reduce中进行计算,提高效率。
concat('字段名',rand())--拼接随机数
3.2 mapjoin的方式
通常我们join的计算方式都是放到reduce端进行计算。
如图所示:下表是reduce join的shuffle过程。(数据倾斜)
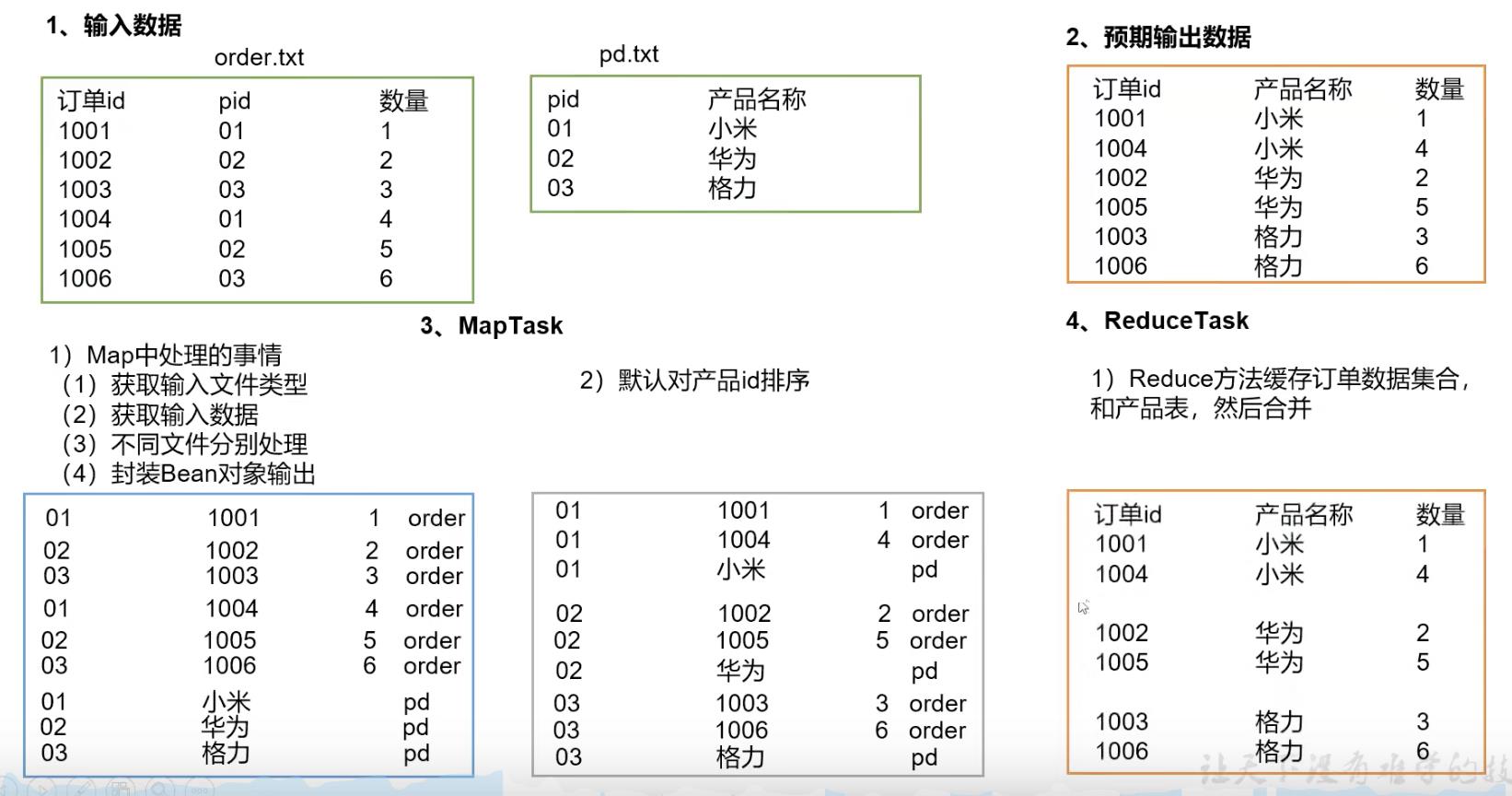
- 第一步:将两张表的链接字段作为key值,其他的数据作为value。
- 第二步:将key值相同的进入同一个分区。
- 第三步:reduce拉取对应分区,进行join操作,完成join过程。
这里容易产生数据倾斜的原因是因为join的过程实在reduce过程完成的,如果某个reduce处理数据过多,就会产生倾斜。
解决方式就是采用mapjoin,小表join大表,将小表放在内存。
之所以采用mapjoin的方式,是因为maptask的任务数取决于切片(大小128m)的个数,我们在每一个maptask里面就将join操作完成,后续就不需要reduce端进行处理,这样子就能够避免shuffle操作,从而避免数据倾斜。但是mapjoin的表不能太大,因为小表一般存储在内存中,然后maptask里面的数据通过hash取余的方式选择小表中对应的key值,进行join完成map join的操作。
3.3 利用group by 代替 distinct
我们在统计数量的时候经常会用到:
count(distinct name)
这里并不建议采用distinct,采用distinct会将所有的name的key都shuffle到一个reduce里面,就容易产生数据倾斜。采用group by+聚合函数的方式会将数据根据key值分配到不同的reduce中,避免数据倾斜。
4. 参考资料
- 滴滴数仓开发分享课程(一些案例图片没放,涉及数据隐私)
- 尚硅谷大数据之Hadoop
- hadoop权威指南
以上是关于hadoop大数据优化之数据倾斜的主要内容,如果未能解决你的问题,请参考以下文章