Flink必知必会的重要基本知识
Posted Z-hhhhh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink必知必会的重要基本知识相关的知识,希望对你有一定的参考价值。
一、Flink基本知识
1.1、Flink介绍
Apache Flink 是一个框架和分布式处理引擎,用于在无界和有界数据流上进行有状态计算。
Flink 官网:https://flink.apache.org/
Flink 的中文官网:https://flink.apache.org/zh/
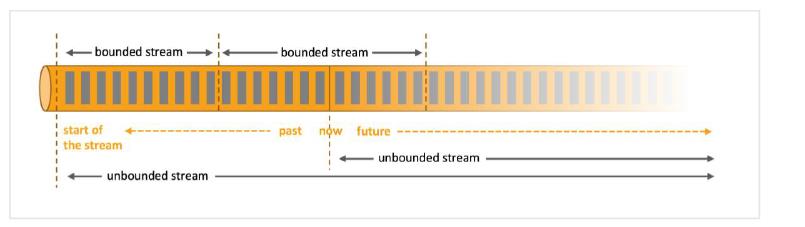
1.2、有界与无界
1.2.1、有界数据集
有头有尾。处理的数据一定会在某个时间范围内,有可能是一天,也有可能是一分钟,像这样有开始有结束的数据集,叫做有界数据集。对有界数据集的处理叫批处理。
1.2.2、无界数据集
有头无尾。数据从开始就源源不断的产生新的数据。对无界数据集的处理叫做流处理。
有界和无界是一个相对的概念,主要根据时间范围来定。
目前开源的大数据处理框架中,能够同时支持批流计算的,就是Spark和Flink。
1.2.3、流处理和批处理
流处理就像商场里的电梯,人们不用等待,直接就可以上。
批处理就像小区里的直梯,需要等待一段时间,一次能乘坐多个人。
1.3、Flink 对比 Spark
- 处理数据的本质不同:
Spark和Flink都希望能用一套技术把流批处理统一起来,但是实现的本质不一样,Spark是以批处理技术为根本,讲数据切成一个一个微小的批次从而实现流式处理,而Flink是完全的流式处理,只要数据一来,就会马上对其进行处理。
-
数据模式不同:
Spark采用RDD,SparkStreaming中的DStream也就是一组一组的小批次RDD。
Flink的基本数据模型时数据流,以及事件(Event)。 -
运行时架构不同:
Spark是批计算,讲DAG切分成多个Stage,一个Stage做完,才能计算下一个。
Flink是流执行模型,一个事件在一个节点处理完以后直接发往下一个节点进行处理。
1.4、Flink的优势
1.4.1、优势
-
同时支持高吞吐、低延迟、高性能
Flink是目前大数据框架中唯一以淘实现高吞吐、低延迟、高性能的分布式数据处理框架;Spark由于式基于批处理实现的伪流处理,无法保证低延迟;Storm保证了低延迟和高性能,但是无法实现高吞吐。 -
支持Event Time
在大部分的数据处理框架中,采用的都是系统事件,而不是事件产生的事件,而Flink支持使用Event Time进行窗口计算,避免了由于网络传输而使数据顺序混乱。 -
支持有状态的计算
状态:就是指将计算过程中的中间结果数据保存在内存或者文件系统中。并且支持精确一次(exactly-once)的状态一致性保证。 -
高度灵活的窗口计算
Flink支持三种窗口模式:时间、数量、会话。 -
支持轻量级分布式快照
通过使用分布式快照的Checkpoints,将执行过程中的状态信息进行持久化存储,遇到节点宕机、网络传输问题时,可通过Checkpoints进行任务的自动恢复。 -
基于JVM实现独立的内存管理
Flink实现了自身管理内存的机制,尽可能的减少JVM和GC对系统的影响。 -
保存点
我们的流计算很可能一直都在运行的,一段时间的终止就有可能导致数据丢失或者计算出错,如:集群版本的升级、停机维护操作,可以利用Save Point将任务执行的快照保存在存储介质上,当任务重启的时候,就能恢复到原来计算的状态。 -
带有反压的连虚模型
下游的算子处理跟不上的时候,可以通过流空的方式将信号船体给上流的算子,上游的算子再将信号传递给source,从而实现sink反向到source,控制source的消费速度,保证系统的稳定运行。
1.4.2、特点
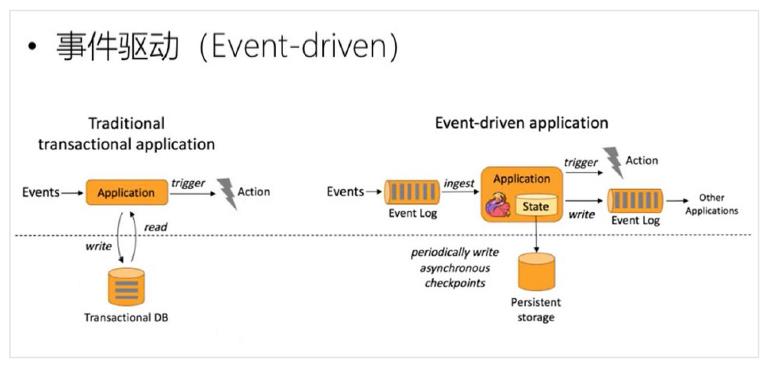
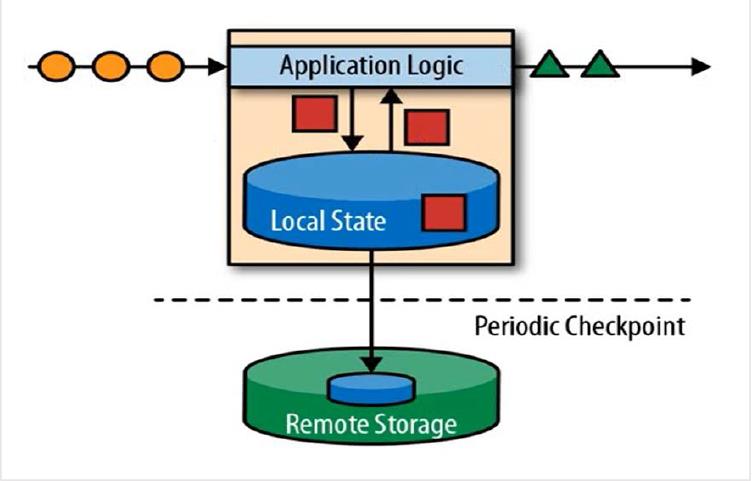
有状态的计算:以本地内存的中状态代替了关系型数据中存储的数据。但是保存到内存的数据容易丢失,所以我们使用Checkpoint做容灾处理。相当于给状态做了快照,把它保存到远程的一个存储空间去。
1.5、Flink中的角色

Flink也遵循主从原则,主节点为JobManager,从节点为TaskManager。
- 客户端
将任务提交到JobManager,并和JobManager进行任务交互获取任务执行状态。 - JobManager
负责任务的调度和资源的管理。负责Checkpoint的协调过程。
获取到客户端的任务后,会根据集群中TaskManager上TaskSlot的使用情况,为提交的任务分配相应的TaskSlots资源,并命令TaskManager启动。
JobManager在执行任务过程中,会触发Checkpoints操作,每个TaskManager收到Checkpoint指令后,完成Checkpoint操作。完成任务后,Flink会将结果反馈给客户端,并释放掉TaskManager中的资源。 - TaskManager
负责任务的执行。负责对任务的每个节点上的资源申请与管理。
TaskManager从JobManager接受到任务后,使用Slot资源启动Task,开始接受并处理数据。 - ResourceManager
ResourceManager负责Flink集群中的资源提供、回收、分配、管理task slots。Flink为不同的环境和资源提供者(如:YARN,Mesos,Kubernetes和standalone部署)实现了对应的ResourceManager。在standalone设置中,ResourceManager指能分配可用TaskManager的slots,而不能自行启动新的TaskManager。 - Dispatcher
Dispacher提供了一个REST接口,用来提交Flink应用程序执行,并未每一个提交的作业启动一个新的JobMaster。它还运行Flink WebUI 用来提供作业执行信息。 - JobMaster
JobMaster负责管理单个JobGraph的执行。Flink集群中可以同时运行多个作业,每个作业都有自己的JobMaster。
以上是关于Flink必知必会的重要基本知识的主要内容,如果未能解决你的问题,请参考以下文章