❤️ Python爬虫实现:评论区抽奖(上期开奖) ❤️
Posted 不吃西红柿丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了❤️ Python爬虫实现:评论区抽奖(上期开奖) ❤️相关的知识,希望对你有一定的参考价值。
🍅 作者:不吃西红柿
🍅 简介:CSDN博客专家🏆、HDZ核心组成员💪、C站总榜前10名✌
🍅 粉丝专属福利:简历模板、PPT模板、学习资料、面试题库。文末领取
🍅 如觉得文章不错,欢迎点赞、收藏、评论
今日重点:
① 掌握简单的python技术:爬虫+抽奖
② 文末领取粉丝专属福利
③ 本文为抽奖实现方式和后续计划说明,不进行抽奖

背景
为了回馈一直默默支持我的粉丝们,我决定后续定期发起【抽奖活动】,我想了2种方式:
1、微信群抽奖(感谢2000+群友的一直支持)
2、CSDN评论区抽奖,在蝉联周榜榜一的过程,少不了你的大力支持,所以必须抽起来,也希望结识更多小伙伴,一起交流技术,互帮互助,团结有爱。
为了保证抽奖公平公正公开:
微信群抽奖采用第三方小程序,CSDN评论区抽奖,西红柿🍅自己写了一个爬虫+抽奖程序。
一、爬虫获取所有评论
首先我用到了一下 python包
# encoding: utf-8
from bs4 import BeautifulSoup
import requests
import random
import time,os
import configparser
import json
cf = configparser.RawConfigParser()
cf.read(os.path.join(os.path.dirname(__file__)+"/csdn.conf"))
cookie = cf.get("csdn", "cookie")
不会安装小伙伴自己百度一下哈~
传入的参数:
# main begin
if __name__ == '__main__':
# 文章id,天选人数量(比如抽2本书)
articleId ,lucky_cnt = '120337051' , 2
# 天选人数
comment_list = get_comments(articleId)
lucky = random.sample(comment_list,lucky_cnt)
print('获得实体书的%s位幸运小伙伴是:'%str(lucky_cnt),lucky)
文章id:文章id看自己的链接哈!
天选人数量:即抽奖数量,本期西红柿抽2个人!包邮宋实体书,想要什么书,大家也可以选!
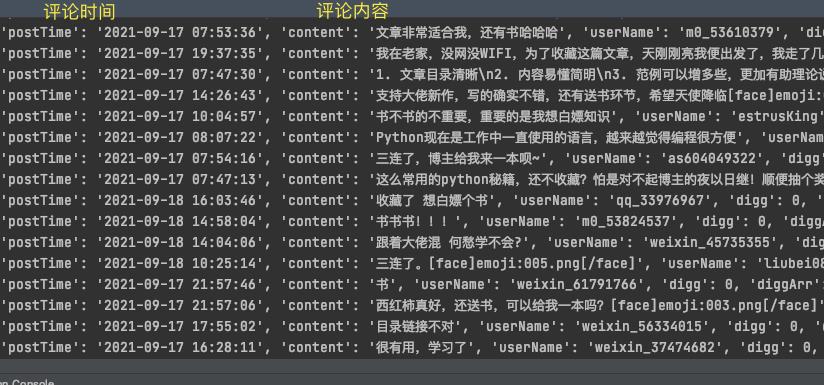
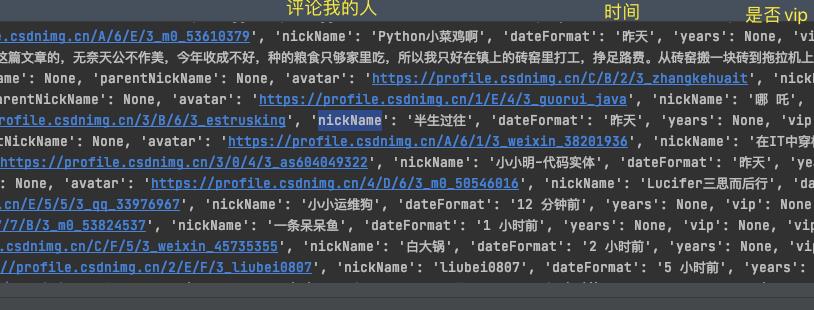
获取所有的评论
def get_comments(articleId):
# 确定评论的页数
main_res = get_commentId(articleId,1)
pageCount = json.loads(main_res)['data']['pageCount']
comment_list = []
for p in range(1,pageCount+1):
res = get_commentId(articleId, p)
commentIds = json.loads(res)['data']['list']
for i in commentIds:
nickName = i['info']['nickName']
comment_list.append(nickName)
print(comment_list)
print('文章:' + str(articleId) + ' 丨 评论数:' + str(len(comment_list)))
return comment_list
抽奖
lucky = random.sample(comment_list,lucky_cnt)
# 完整代码私聊我
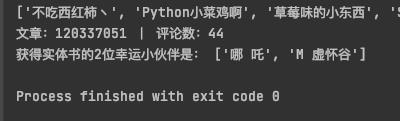
2020-09-18 期开奖结果:
1本小程序:
2本CSDN评论区:

🍅 行业资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 交流加群:大佬指点迷津,你的问题往往有人遇到过,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 学习资料:含编程语言、算法、大数据生态圈组件(mysql、Hive、Spark、Flink)、数据仓库、前端等。👇👇👇更多粉丝福利👇👇👇
以上是关于❤️ Python爬虫实现:评论区抽奖(上期开奖) ❤️的主要内容,如果未能解决你的问题,请参考以下文章