python爬虫 正则表达式 re.finditer 元字符 贪婪匹配 惰性匹配
Posted 皓月盈江
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫 正则表达式 re.finditer 元字符 贪婪匹配 惰性匹配相关的知识,希望对你有一定的参考价值。
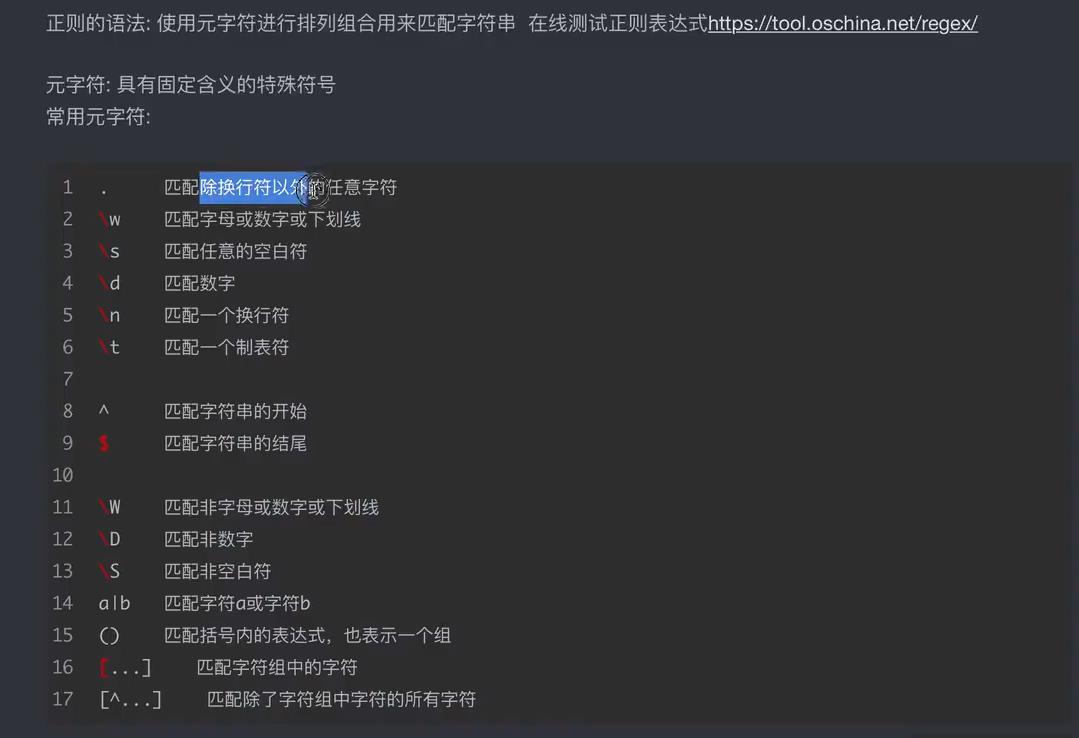
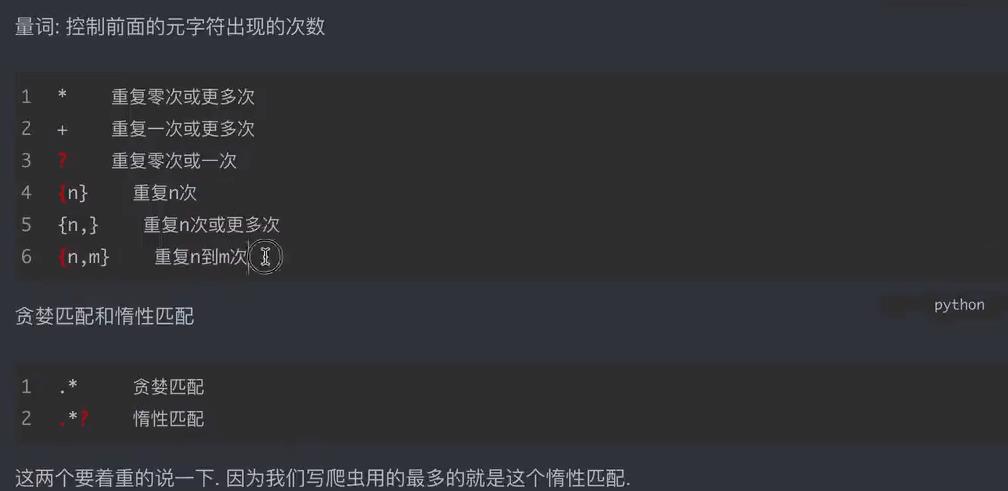

测试代码1:
main5.py
# -*- coding: utf-8 -*-
import re
if __name__ == '__main__':
# findall匹配字符串中所有的符合正则的内容
lst = re.findall(r"\\d+", "濮阳电话区号:0393,郑州电话区号:0371")
print(lst)
# 【推荐】finditer匹配字符串中所有的内容[返回的是迭代器],从迭代器中拿到内容需要.group()
it = re.finditer(r"\\d+", "濮阳电话区号:0393,郑州电话区号:0371")
for i in it:
print(i.group())
# search,找到一个结果就返回,返回的结果是match对象,拿到数据需要.group()
s = re.search(r"\\d+", "濮阳电话区号:0393,郑州电话区号:0371")
print(s.group())
# match,从头开始匹配
s = re.match(r"\\d+", "0393,郑州电话区号:0371")
print(s.group())
# 【推荐】finditer匹配字符串中所有的内容[返回的是迭代器],从迭代器中拿到内容需要.group()
# 预加载正则表达式
obj = re.compile(r"\\d+")
it = obj.finditer("濮阳电话区号:0393,郑州电话区号:0371")
for i in it:
print(i.group())
测试代码2:python爬虫很常用的从网页提取数据例子
main6.py
# -*- coding: utf-8 -*-
import re
if __name__ == '__main__':
s = """
<div class= 'tom'><span id= '1'>汤姆</span></div>
<div class= 'kali'><span id= '2'>凯丽</span></div>
<div class= 'lnr'><span id= '3'>罗恩</span></div>
"""
# 【推荐】finditer匹配字符串中所有的内容[返回的是迭代器],从迭代器中拿到内容需要.group()
# 预加载正则表达式,(?P<分组名称>正则表达式)可以单独从正则匹配的内容中进一步提取内容,标志处添加re.S是让.匹配换行符,即匹配任意字符。
obj = re.compile(r"<div class= '(?P<class>.*?)'><span id= '(?P<id>\\d)'>(?P<name>.*?)</span></div>", re.S)
result = obj.finditer(s)
for i in result:
print(i.group("class")+" "+i.group("id")+" "+i.group("name"))
效果:
tom 1 汤姆
kali 2 凯丽
lnr 3 罗恩
关注公众号,获取更多资料

以上是关于python爬虫 正则表达式 re.finditer 元字符 贪婪匹配 惰性匹配的主要内容,如果未能解决你的问题,请参考以下文章