并行编程框架MapRduce(下)
Posted shi_zi_183
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了并行编程框架MapRduce(下)相关的知识,希望对你有一定的参考价值。
MapReduce解析
I/O序列化
序列化 serialization就是将结构化的对象转为字节流的过程,以便在网络上传输或者写入磁盘进行永久存储。
反序列化 deserialization是序列化的逆过程,将字节流转换回结构化对象。
序列化和反序列化的主要应用是进程间的通信和持久化存储。
在Hadoop集群中,多节点之间的通信时通过远程过程调用RPC协议完成的。RPC协议将消息序列化成二进制RPC对序列化有如下要求:
1)紧凑:紧凑格式能充分利用网络带宽
2)快速:进程间通信形成了分布式系统的骨架,所有需要尽量减少序列化和反序列化的性能开销
3)可拓展性:为了满足新的需求,通信协议在不断变化,在控制客户端和服务器的过程中,需要直接引入新的协议,因此序列化必须满足可拓展的要求。
4)支持互操作:对于某些系统来说,希望能支持以不同编程语言编写的客户端与服务器交互,所以需要设计一种特定的格式来满足这一需求。
Hadoop并没有采用Java的序列化机制,而是引入了Writable接口,建立了自己的序列化机制,具有紧凑、速度快的特点,但不太容易用Java以为的编程语言去扩展。
不用Java的序列化机制的原因是因为
java的序列化是一个重量级序列化框架,一个对象被序列化后,会会带很多额外的信息(各种校验信息,Header,继承体系等),不便于在网络中高效传输。所以,Hadoop自己开发了一套序列化机制。
常用数据序列化类型
| Java类型 | Hadoop Writable类型 |
|---|---|
| Boolean | BooleanWritable |
| Byte | BtyeWritable |
| Int | IntWritable |
| Float | FloatWritable |
| Long | LongWritable |
| Double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
Writable接口
Writable接口
Writable接口是基于DataInput和DataOutput实现的序列化协议。MapReduce中的key和value必须是可序列化的,也就是说,key和value要求是实现了Writable接口的对象。key还要求必须实现WritableComparable接口,以便进行排序。
package org.apache.hadoop.io;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.classification.InterfaceAudience.Public;
import org.apache.hadoop.classification.InterfaceStability.Stable;
@Public
@Stable
public interface Writable {
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}
write方法的功能是将对象写入二进制流Dataoutput,readFields的功能是从二进制流DataInput读取对象。参数中的DataInput和DataOutput是java.io包中定义的接口,分别用来表示二进制流的输入和输出。
WritableComparable接口
WritableComparable接口继承自Writable接口和java.lang.Comparable接口,是可序列化并且可比较的接口
package org.apache.hadoop.io;
import org.apache.hadoop.classification.InterfaceAudience.Public;
import org.apache.hadoop.classification.InterfaceStability.Stable;
@Public
@Stable
public interface WritableComparable<T> extends Writable, Comparable<T> {
}
由于继承自Writable,所以WritableComparable是可序列化的,需要实现write()和readFields()这两个序列化和反序列化方法。WritableComparable由于继承了Comparable接口,所以其也是可比较的,还需要compareTo()方法。
package java.lang;
import java.util.*;
public interface Comparable<T> {
public int compareTo(T o);
}
WritableComparator类
Java的RewComparator接口允许比较从流中读取的未被反序列化为对象的记录,省去创建对象的所有开销,从而更有效率。WritableComparator是继承自WritableComparable类的RewComparator类的通用实现,提供了两个重要的功能。
1)提供了对原始compare()方法的一个默认实现,该方法能够反序列化在流中比较的对象,调用对象的compare()方法进行比较。
2)它充当RawCompatator实例的一个工厂(已注册Writable的实现)。
例如,获取一个IntWritable的comparator,可以直接调用其get方法。
RawComparator<IntWritable>comparator=WritableComparator.get(IntWritable.class);
这个comparator可以比较两个IntWritable对象
package com.ex.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.RawComparator;
import org.apache.hadoop.io.WritableComparator;
public class Text {
public static void main(String[] args){
WritableComparator comparator= WritableComparator.get(IntWritable.class);
IntWritable w1=new IntWritable(163);
IntWritable w2=new IntWritable(67);
System.out.println(comparator.compare(w1,w2));
}
}

这里因为163大于67所以返回1。
compatator直接比较序列化后的对象的实现代码,不需要再将数据流反序列化为对象,从而避免了额外的开销。
package com.ex.mapreduce.wordcount;
import com.fasterxml.jackson.databind.ObjectWriter;
import org.apache.commons.lang.SerializationUtils;
import org.apache.hadoop.io.*;
import org.apache.hadoop.io.Text;
import org.apache.zookeeper.server.util.SerializeUtils;
import java.io.*;
public class TextWritable {
public static void byteCompareTest() throws IOException {
WritableComparator comparator= WritableComparator.get(IntWritable.class);
IntWritable w1=new IntWritable(163);
IntWritable w2=new IntWritable(67);
byte[] b1= serialize(w1);
byte[] b2=serialize(w2);
System.out.println(comparator.compare(b1,0,b1.length,b2,0,b2.length));
}
public static byte[] serialize(Writable writable) throws IOException{
ByteArrayOutputStream out=new ByteArrayOutputStream();
DataOutputStream dataOut=new DataOutputStream(out);
writable.write(dataOut);
dataOut.close();
return out.toByteArray();
}
//反序列化
public static byte[] deserialize(Writable writable,byte[]bytes) throws IOException{
ByteArrayInputStream in=new ByteArrayInputStream(bytes);
DataInputStream dataIn=new DataInputStream(in);
writable.readFields(dataIn);
dataIn.close();
return bytes;
}
}
WritableComparable排序(接口)
首先,WritableComparable是Hadoop的排序方式之一,而排序是MapReduce框架中最重要的操作之一,它就是用来给数据排序的(按照Key排好),常发生在MapTask与ReduceTask的传输过程中(就是数据从map方法写到reduce方法之间)
任何应用程序中的数据均会被排序,不管逻辑上是否需要,都排序
MapTask和ReduceTask均会对数据进行排序,此操作属于Hadoop的默认行为
默认行为是按照字典顺序排序,且实现该排序的方法是快速排序,例如环形缓冲区中将数据写入分区后会进行区内的局部排序,使用的就是快排。
WritableComparator
它是用来给Key分组的
它在ReduceTask中进行,默认的类型是GroupingComparator也可以自定义
WritableComparator为辅助排序手段提供基础(继承它),用来应对不同的业务需求。
比如GroupingComparator会ReduceTask将文件写入磁盘并排序后按照Key进行分组,判断下一个key是否相同,将同组的key传给reduce()执行。
Writable封装类
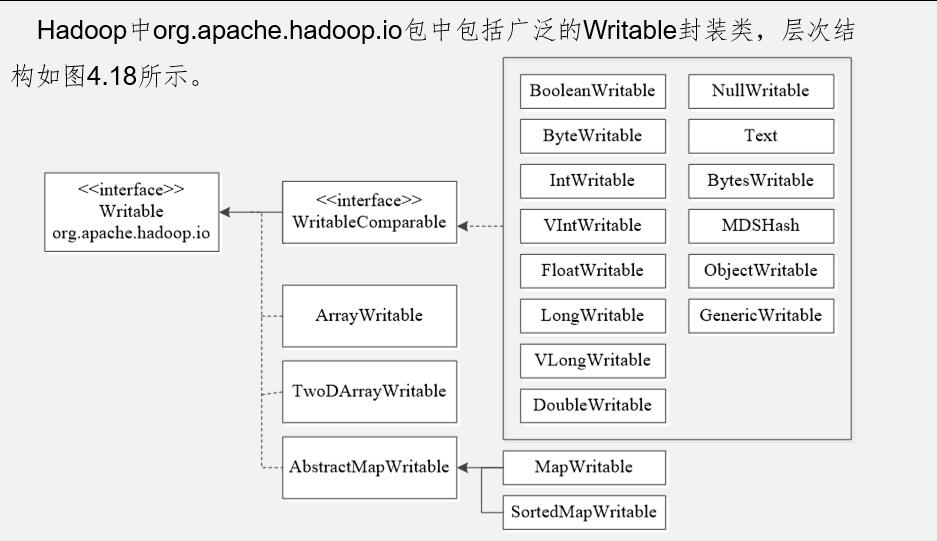
Java基本类型的Writable封装器
Writable类提供了除char类型以外的Java基本类型的封装。所有的类都可通过get()和set()方法进行读取或者存储封装的值。
| Java基本类型 | Writable类 | 序列化大小(byte) |
|---|---|---|
| 布尔型 | BooleanWritable | 1 |
| 字节型 | ByteWritable | 1 |
| 短整型 | ShortWritable | 2 |
| 整形 | IntWritable | 4 |
| 整形(可变长度) | VIntWritable | 1-5 |
| 浮点型 | FloatWritable | 4 |
| 长整型 | LongWritable | 8 |
| 长整型(可变长度) | VlongWritable | 1-9 |
| 双精度浮点型 | DoubleWritable | 8 |
进行整数编码时,可以有两种选择:
- 定长格式(IntWritable和LongWritable)
- 变长格式(VIntWritable和VlongWritable)
定长格式适合对整个值域空间中分布均匀的数值进行编码,例如阿希方法等。
对于数值变量分布不均匀的,采用变长格式更加节省空间。
Text类型
Text类使用修订的标准UTF-8编码来存储文本,它提供了在字节级别上序列化、反序列化和比较文本的方法,基本可以看作Java的String类的Writable封装。Text类的前1-4个字节,采用变长整形来存储字符串编码中所需要的字节数,所以Text类型的最大存储为2G。Text可以方便地其他更够理解UTF-8编码地工具交互。Text类与JavaString 类在检索、Unicode和迭代等方面是有差别地。
1)charAt方法
int charAt(int position)
Text的chatAt返回的是一个表示Unicode编码位置的整型值。当position不在范围之内时返回-1。
2)find方法
int find(String what)
int find(String what,int start)
Text类型中的find方法返回字节偏移量,当查找内容不存在时返回-1。而String类的indexOf方法返回char编码单元中的索引位置。
3)set方法
void set(String string)
void set(byte[] utf8)
给Text对象设置值
4)decode方法
static String decode(byte[] utf8)
static String decode(byte[] utf8,int start,int length)
static String decode(byte[] utf8,int start,int length,boolean replace)
decode方法的功能是将UTF-8编码的字节数组转化为字符串
5)encode方法
static ByteBuffer encode(String string)
static ByteBuffer encode(String string,boolean replace)
将字符串转换为UTF-8编码的字节数组
6)String toString()
返回值对应的字符串。Text类不像Java String类有丰富的字符串操作API,在很多情况下需要将Text对象转化成String对象,这可以通过调用toString()方法来实现。
7)byte[] getBytes()
返回对应的字节数组。
8)int getLength()
返回字节数组里字节的数量。
Text方法的使用示例
public static void textTest(){
Text text=new Text("\\u0041\\u00DF\\u6C49");
System.out.println(text.toString());
System.out.println(text.getLength());
System.out.println(text.charAt(0));
System.out.println(text.charAt(1));
System.out.println(text.charAt(2));
System.out.println(text.charAt(3));
System.out.println(text.find("\\u00DF"));
System.out.println(text.find("\\u6C49"));
}
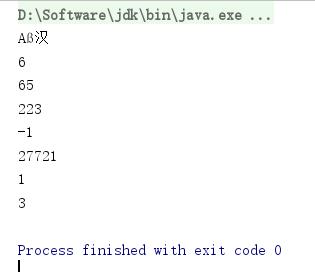
字符串对应的UTF-8编码长度6(6=1+2+3)。text.charAt(0)、text.charAt(1)和text.charAt(3)返回所在位置字符的Unicode编码的整型值,分别是65,223和27721。由于text.charAt(2)指定的位置2错误,所以返回-1。text.find("\\u00DF")返回字符\\u00DF所在位置偏移量1,而text.find("\\u6C49")偏移量为3。
ByteWritable
ByteWritable是对二进制数组的封装。它的序列化格式以一个4个字节的整数作为开始,表示数据的长度,也就是字符串本身。例如,长度为3的字节数组包含7、8、9,则其序列化形式为一个4字节的整数(00000003)和随后3个字节(07、08、09)。
ByteWritable是可变的,其值可以使用set(byte[] newData,int offset,int length)方法修改;toString()方法转换为十六进制并以空格分开;可以通过setCapacity()方法设置容量;getLength()方法返回对象的实际数据长度;getBytes().length返回字节数组的长度,即该对象的当前容量。
public static void byteTest(){
BytesWritable b=new BytesWritable("ABCD".getBytes());
System.out.println(b.toString());
System.out.println(b.getLength());
System.out.println(b.getBytes().length);
b.setCapacity(10);
System.out.println(b.toString());
System.out.println(b.getLength());
System.out.println(b.getBytes().length);
b.setCapacity(2);
System.out.println(b.toString());
System.out.println(b.getLength());
System.out.println(b.getBytes().length);
}

NullWritable
NullWritable的序列化长度为0,不包含任何字符,它仅仅充当占位符的角色,不会从数据流中读取和写出数据。例如,Map或Reduce阶段的输出,当key或value不需要输出时,就可以将其设置为NullWritable,一般调用NullWritable.get()来获取NullWritable类的实例。
ObjectWritable和GenericWritable
当一个字段中包含多种类型的数据时,就可以采用ObjectWritable进行封装,ObjectWritable是对String、Enum、Writable、null等类型的一种通用封装。ObjectWritable在RPC中用于方法的参数和返回类型的封装和解封类。
public static void objectTest(){
ObjectWritable o= new ObjectWritable("ABCD");
System.out.println(o.toString());
Class c=o.getDeclaredClass();
System.out.println(c);
String s=(String) o.get();
System.out.println(s);
}

ObjectWritable每次进行序列化时,要写入封装类型的名称以及保存封装之前的类型,这样势必会占用很大的空间,造成资源浪费。针对这种不足,MapReduce又提供了GenericWritable类。它的机制是当封装类型数量比较小,并且可以提取知道的情况下,可以使用静态类型的数组,通过使用对序列化后的类型的引用来提升性能。GenericWritable的用法是,继承这个类,然后把要输出value的Writable类型加进它的Class静态变量里。
public static void genericWritable(){
MyGenericWritable m=new MyGenericWritable(new Text("ABCD"));
System.out.println(m.toString());
Class c=m.get().getClass();
System.out.println(c);
Text t=(Text)m.get();
System.out.println(t);
}

Writable集合类
在org.apache.hadoop.io包中含有6个Writable集合类,分别是ArrayWritable,TwoDArrayWritable、ArrayPrimitiveWritable、MapWritable、SortedMapWritable以及EnumMapWritable。
ArrayWritable表示数组的Writable类型,TwoDArrayWritable表示二维数组的Writable类型。这两个类中所包含的元素必须是同一类型。数组的类型可以在构造方法里设置
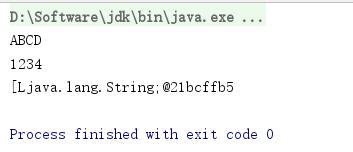
public static void arrayWritable(){
ArrayWritable a=new ArrayWritable(Text.class);
a.set(new Writable[]{new Text("ABCD"),new Text("1234")});
for(Writable t:a.get()){
System.out.println(t);
}
System.out.println(a.toStrings());
}
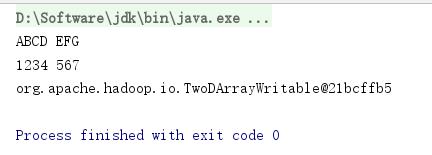
public static void twoDArrayWritable(){
TwoDArrayWritable t=new TwoDArrayWritable(Text.class);
t.set(new Writable[][]{{new Text("ABCD"),new Text("EFG")},{new Text("1234"),new Text("567")}});
for(Writable[] one:t.get()){
for(Writable a:one){
System.out.print(a.toString()+' ');
}
System.out.println();
}
System.out.println(t.toString());
}
ArrayWritable和TwoDArrayWritable这两个类都有get()、set()和toArray()方法。toArray()方法用于创建数组的浅副本,不会为每个数组元素产生新的对象,也不构成底层数组的副本。
ArrayPrimtiveWritable是一个封装类,是对Java基本类型的数组(int[]、long[]等)的Writable类型的封装。调用set方法时,可以识别组件类型,无须像ArrayWritable那样通过继承该类来设置类型。
public static void arrayPrimitiveWritableText(){
ArrayPrimitiveWritable a=new ArrayPrimitiveWritable();
int[] i={123,456};
a.set(i);
for(Object l:(int[])a.get()){
System.out.println(l);
}
}

MapWritable实现了java.util.Map<Writable,Writable>,SortedMapWritable实现了java.util.SortedMap<WritableComparable,Writable>。上述每个<key,value>字段使用的类型是相应字段序列化的一部分。
public static void mapWritableTest(){
MapWritable m=new MapWritable();
HashMap<Text,IntWritable> h=new HashMap<Text,IntWritable>();以上是关于并行编程框架MapRduce(下)的主要内容,如果未能解决你的问题,请参考以下文章