浅谈Spring中的循环依赖
Posted 默辨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈Spring中的循环依赖相关的知识,希望对你有一定的参考价值。
写在最前面,在写这篇文章之前,我也参考了很多别人对于Spring循环依赖的讲解,大部分人都是按照先使用二级缓存,再使用三级缓存的思路去讲解。在阅读了Spring源码中关于循环依赖的整体流程的源码后,对于他们说的先使用二级缓存的那部分讲解在我看来是不严谨的(尽管本文也是按照这个顺序讲解,但是我会反复强调在我看来的不严谨,因为使用三级缓存后的流程会推翻部分使用二级缓存的流程)。也许是为了讲解一个技术点,需要由浅入深吧。
说说自己的观点吧,我觉得Spring使用三级缓存来解决循环依赖这部分的概念,应是一个整体的理解,这就是一个整体的设计(当然,我无从考证是否Spring的缓存Map是否有一个演进过程),没有所谓的先怎么再怎么。只是这个设计最初的时候,综合考虑了Spring可能出现的循环依赖、Spring的生命周期、AOP的动态代理以及Spring中Bean默认是单例的等因素,所以直接使用了三个不同的Map来进行存储。
通过本文你将了解到:
- Spring循环依赖的出现及解决流程
- 一级缓存、二级缓存、三级缓存的作用
- Spring底层源码对于循环依赖关键部分的代码逻辑
- 懒加载的合理使用可以避免循环依赖
- 原型Bean的不恰当使用会引发循环依赖
- 构造方法导致的循环依赖无法解决
一、共识
在了解循环依赖之前,我希望我们能有以下几个共识
1、共识一
Spring中循环依赖出现的场景有很多种,本文只重点讲述Bean成员变量之间相互引用出现的循环依赖
换句话说,Spring循环依赖没有所谓的特定场景,只要出现两个类之间循环调用,就可以称之为循环依赖。
循环依赖场景:
- Bean成员变量之间相互引用,导致出现循环依赖
- 构造方法中出现变量之间相互引用,导致出现循环依赖。
- @DepondOn注解的使用,导致两个类出现循环依赖
- … …
2、共识二
以下两个案例都可以理解为类A和类B之间出现循环依赖,但是:
案例一是能够完成对象的赋值,因为它们在赋值时使用的是内存地址的引用
案例二是会出现StackOverflowError,因为它们在类的实例化阶段就开始赋值,此时堆内存中还未为本对象分配内存地址
案例一:
// A依赖了B
class A{
public B b;
}
// B依赖了A
class B{
public A a;
}
public class Test {
public static void main(String[] args) {
A a = new A();
B b = new B();
b.a = a;
a.b = b;
}
}
案例二:
public class A {
public B b;
public A() {
b = new B();
}
}
public class B {
public A a;
public B() {
a = new A();
}
}
public class Test {
public static void main(String[] args) {
A a = new A();
}
}
3、共识三
了解Spring中Bean的生命周期,起码你需要知道:
Bean实例化阶段:推断构造方法,实例化对应的类;
Bean实例化之后:完成属性的注入,此时Spring会根据类上的注入点(@Autwired、@Resource等类型注解),完成属性的赋值
Bean初始化之后:根据生成的Bean信息,决定是否需要AOP操作
想了解Spring生命周期的可以参考该篇文章:浅谈Spring中Bean的生命周期,尽管文中对于生命周期有很多步骤没有提及,但是生命周期的大部分内容都有涉及。
4、共识四
明白AOP的原理
AOP是在Bean生命的初始化之后执行的操作,AOP底层使用动态代理,为我们生成一个代理对象,代理的逻辑分别放在我们真实逻辑的前面或者后面。
但我们一定要区分,这个代理对象和我们真实的最开始完成Bean初始化之后的Bean是不一样。
5、共识五
明白spring单例池的基本逻辑
spring容器中的单例池为一个map结构:

key是Bean的名字,value就是我们的Bean对象
二、Spring循环依赖讲解
请时刻回忆上面的几个共识,后文会反复使用到它们。
1、二级缓存的使用
以上面的案例切入:
class A{
public B b;
}
class B{
public A a;
}
public class Test {
public static void main(String[] args) {
A a = new A();
B b = new B();
b.a = a;
a.b = b;
}
}
在Spring中想要达到这样的效果,代码为:
@Component
public class A {
@Autwired
public A a;
}
@Component
public class B {
@Autwired
public A a;
}
实例化A类的Bean的时候
当Spring在初始化所有非懒加载Bean时,会遍历beanDefinitionNames(简单理解为一个存放了所有Bean名字的Map),当遍历到A类对应的Bean的时候,它会去调用getBean方法获取Bean,由于这时在容器的初始化阶段,所以getBean肯定获取不到对应的Bean信息,然后将将此时会去createBean。然后去执行A类对应Bean的生命周期。
接下来就开始A类对应的Bean的生命周期,当Bean在实例化后,也就是属性填充的时候,它发现该Bean依赖B类对应的Bean的生命周期,于是它又重复上面的步骤,先去get,get不到,就去create,然后再执行B类对应的Bean的生命周期,对应的Bean在属性填充的时候发现它又需要A,于是此处就出现了死循环。
针对此,Spring的解决办法是,类A对应的Bean在创建的时候,将该Bean标记为正在创建,并且添加到对应的二级缓存(二级缓存存放的是类A对应的不完整的Bean对象,因为属性还没有完成填充)
该说法理论上说并不严谨,理解过程即可
回到上面的步骤,在执行B类对应的Bean的生命周期的时候,对应的Bean在属性填充阶段发现它又需要类A对应的Bean,此时它去查看A类对应的Bean是否为正在创建,如果是,则去对应的二级缓存中将对应的不完整的类A对应的Bean赋值给B类对应Bean的成员变量,接着走完B剩下的生命周期步骤,然后B类对应的Bean创建完成,返回完成A类对应的Bean的生命周期。

将上面的步骤抽象出来,就是共识一中的这段代码:
- 首先实例化A类
- 然后给a对象的b变量赋值,此时发现它需要A类的对象
- 于是中间又插入一步实例化B的操作
- b对象创建出来后,给对应的a变量进行赋值
- 然后执行最后一步给a对象的b变量赋值
以上案例仅是一个入门案例,上面的说法有一些不够完善和准确,后文会有一个总结进行完成的说明
类A、a对象、类A对应的Bean对象这是三个不同的概念,但这不在本文的讨论范围之内,所以后文出现这三个概念的时候,为了方便描述,我就统称为Bean
还是在上面案例的基础上,我们添加一个C类,理顺了上面的描述关系,此时它们的关系可就以描述为:
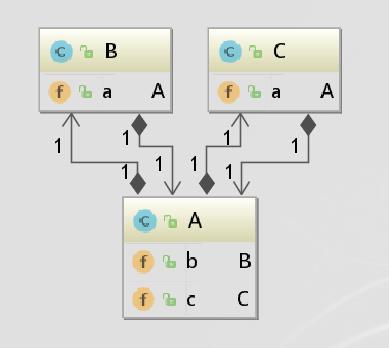
那么紧接上面的步骤,Bean a中成员变量b的赋值已经完成,此时轮到变量c赋值了。
此时去单例池中获取,还是获取不到,那么就会去创建create Bean对象,然后执行Bean对象c的生命周期步骤。还是老规矩,先实例化出Bean c对象,然后对Bean c进行属性填充,此时它发现他又需要Bean a,然后发现Bean a是正在创建,所以就去二级缓存中获取,然后将二级缓存中不完整的Bean a(Bean a没有进行属性注入)赋值给c,然后完成Bean c的生命周期并返回。然后Bean a就能够完成自己的生命周期。整个过程结束。
再次说明,上面的步骤很多细节地方不准确,理解思路即可
2、三级缓存的使用
观察上面的例子,其实二级缓存就已经可以解决循环依赖,那为什么又需要三级缓存呢?
直接说结论:为AOP生成的代理对象服务
在Bean的生命周期初始化后阶段,Spring会为创建的Bean添加AOP操作,即生成一个代理对象,那么问题来了。但是在上面的二级缓存中,存放的仅仅是一个原始对象(还没有完成属性填充的对象),而如果Bean a有对应的代理逻辑,那么赋值给Bean b的成员变量Bean a就是有问题的,因为后面Bean a对象在实例化后通过AOP处理,Bean对象内容发生了改变。这是与Spring设计相违背的。
在我看来,问题的关键,就是把AOP和原始对象关联起来,让它在赋值的时候又能够进行对应的AOP处理。
应该是存在很多种不同的实现,但是Spring最终选择使用三级缓存来解决这个问题,将AOP和原始对象关联起来的操作则是使用一段lambda表达式来处理,即三级缓存存放的是一个含有lambda表达式的集合(存放相关处理逻辑的集合,其肯定会返回一个对象然后添加到二级缓存,至于这个对象就可能还是原始对象,也有可能是经过AOP处理后的对象,到底是哪种对象,根据具体的Spring生命周期后中初始化之后的AOP逻辑而定)。
3、完整流程(本文核心)
重要、重要、重要、重要
请忘记上面说的二级缓存获取对象的步骤
现在完整的对该过程进行一个描述:
-
Bean a在创建的时候,它会先去单例池中get,调用getSingleton方法
-
先去一级缓存中获取,我们Bean a第一次创建,所以单例池中肯定没有
-
然后判断是否为正在创建,此时为第一次创建,所以为false

-
接着去createBean,将Bean a设置为正在创建中,该方法的入口为创建单例Bean的地方。
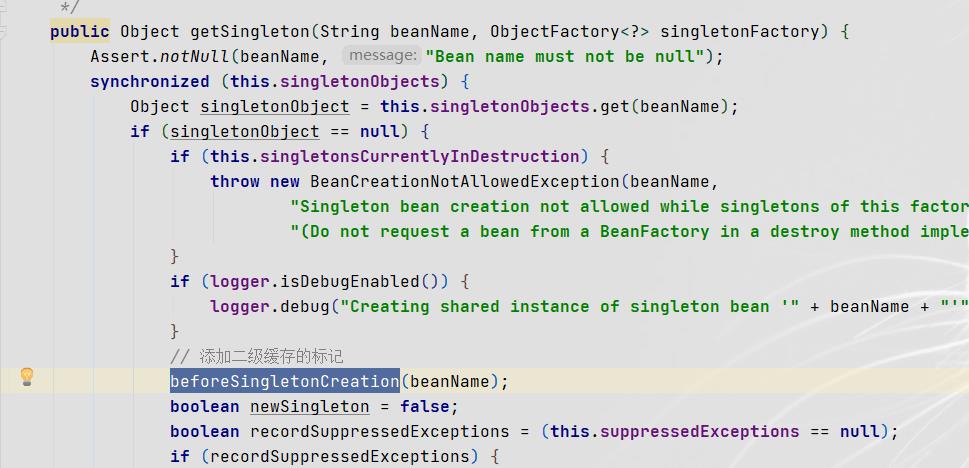
-
在实例化步骤结束(根据构造方法实例化Bean a),初始化后前(属性填充),会将Bean a与AOP之间的关系,即对应的执行逻辑,以lambda表达式的形式添加到三级缓存
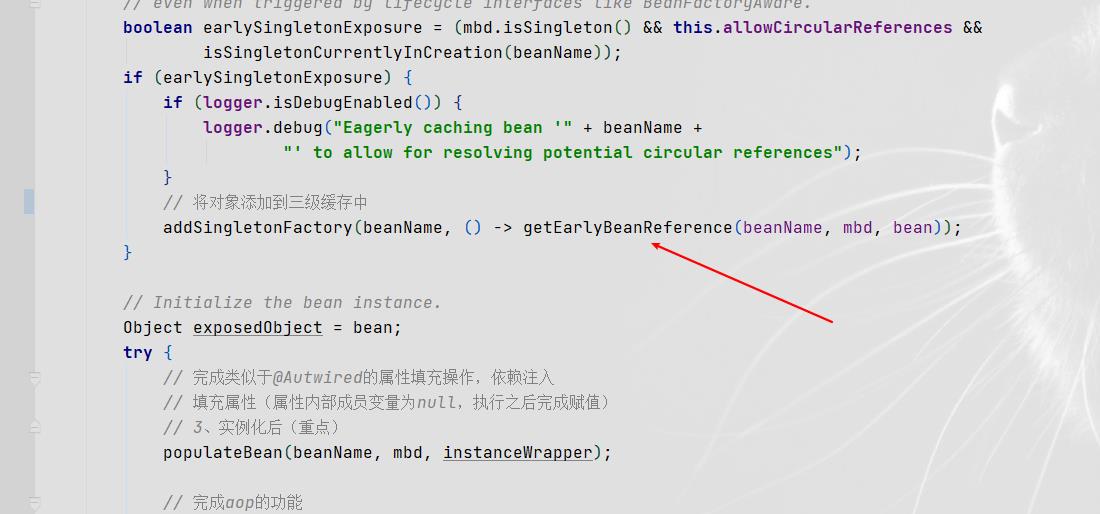
-
然后进行Bean a的属性填充,此时它发现需要Bean b
-
那么会重复上面的步骤,然后将Bean b与AOP的执行逻辑放入到三级缓存(此时三级缓存中有两条数据,二级缓存还没有使用到)
-
当在属性填充Bean b对象的时候,它发现它需要Bean a对象(即出现循环依赖)
-
那么它又会去获取Bean a对象,此时的执行逻辑为,先去一级缓存获取没有,然后看是否正在创建中,如果是就看二级缓存中有没有,肯定都没有。再看是否允许循环依赖,如果为true,那么就会去调用getObject方法,而这个方法就是我们放在三级缓存中的lambda表达式。然后将执行后的对象放到二级缓存,并且移除三级缓存中的lambda表达式,返回对应的经过AOP处理后的对象。

-
对Bean b而言,此时属性填充完毕,返回。即Bean a中对于b成员变量的属性填充完毕。(在将Bean b对象添加到单例池的时候,还会对Bean在各级缓存中做移除或添加操作)
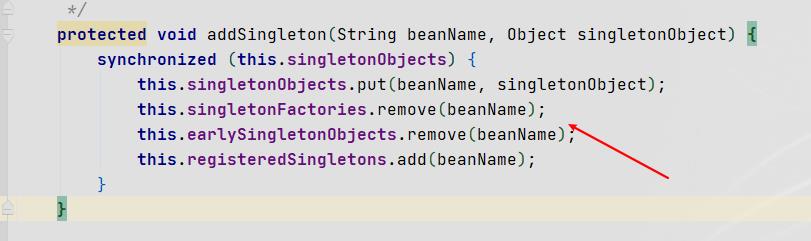
-
接下来开始对Bean c进行属性填充。
-
同样是上面的操作,此时大体步骤与Bean b相同,当我们Bean c对象在填充属性的时候,发现自己依赖Bean a,这个时候就会去获取Bean a
-
还是同样的逻辑,先去一级缓存中获取,由于我们的Bean还没有进行完整的生命周期,所以单例池肯定获取不到。然后判断是否正在创建,判定为true。然后去二级缓存中获取
-
上面在处理Bean b的生命周期的时候,由于执行过Bean a的生命周期,并且放到了二级缓存中,所以此时的二级缓存中是含有对应的Bean a的信息的,只是此时的Bean a是不完整的Bean(还没有执行自己的生命周期)。二级缓存能够获取到,就返回给Bean c,用于Bean c的属性填充处理。
-
最后,Bean c的生命周期执行完毕,返回,Bean a的生命周期顺利进行
-
前面已经说过,三级缓存中那段lambda表达式已经对Bean a进行了对应的AOP处理,那么此时当Bean a执行到其本来就有的生命周期中的AOP步骤时,则会进行对应map中的key进行判定,继而不再执行对应的AOP操作。第一张图为执行lambda表达式时的AOP操作方法入口,可以理解为提前进行AOP,第二张为正常的执行AOP的操作方法入口

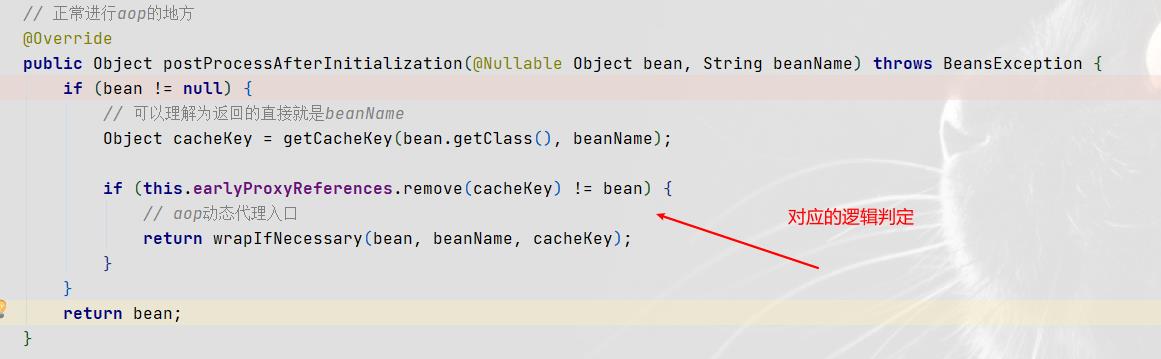
-
至此,整个流程执行完毕
回头来看,循环依赖的理解不能从一级缓存、二级缓存、三级缓存这个顺序来理解,更多的是站在更全局的一个角度上看。并且我认为从三级缓存往回理解二级缓存貌似更加合理,我们再理一理对应的关系:
- 一级缓存存放的是完整的单例Bean对象
- 同一个Bean先添加到三级缓存,再将三级缓存的逻辑存放到二级缓存
- 二级缓存中的对象也是单例的,并且是不完整的
那么对应的三个Map的作用也可以描述为:
一级缓存的作用是存放完整的单例Bean对象
二级缓存的是用来存放不完整的Bean,并且能够用来保证我们创建的Bean是一个单例的
三级缓存是用来存放AOP与Bean对象之间的关系,并且能够做到当一级二级缓存中没有对象的时候,三级缓存中一定有对象,换句话说,打破循环依赖的终点,因为获取到这一步,就不会因为没有Bean对象而继续再往下去create
请记住这三个Map的长相。

三、其他
1、懒加载为什么可以避免循环依赖
Spring中对于懒加载的Bean(添加@Lazy注解),在实例化对应的对象时,为创建一个代理对象给该属性,只有在真正调用懒加载Bean对应逻辑的时候,该Bean才会根据懒加载生成的代理对象中的逻辑去完成自己的生命周期。
即在整个过程中,代理对象是不会反向依赖依赖它的Bean的属性填充,即也就不会出现循环依赖
2、Bean为原型时可能会引发循环依赖
我们要明确,Spring打破循环依赖的最关键的要素是三级缓存,因为如果一级二级缓存取不到数据,三级缓存必能获取到数据。可原型Bean自始至终都没有不会使用一级缓存来进行存储,更别说三级缓存了。原型Bean的循环依赖就真的是无线套娃下去。
3、构造方法导致的循环依赖无法解决
回头看看共识二中的案例二,构造方法导致的循环依赖和它相同。
实例化Bean对象是在Bean的生命周期的初始化阶段进行的,而此时我们的不完整的Bean对象都还没有创建出来,即缓存中也不会有添加数据,所以Spring无法处理。类比案例二进行理解,不能说是毫无关系,只能说是一模一样
如果本文对你有帮助,期待你点个赞再走!!!
以上是关于浅谈Spring中的循环依赖的主要内容,如果未能解决你的问题,请参考以下文章