CS224W摘要05.Message passin and Node classification
Posted oldmao_2000
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CS224W摘要05.Message passin and Node classification相关的知识,希望对你有一定的参考价值。
文章目录
CS224W: Machine Learning with Graphs
公式输入请参考: 在线Latex公式
今天学习message passing框架:
Relational classification
Iterative classification
Belief propagation
Homophily和Influence
Homophily: The tendency of individuals to associate and bond with similar others
个人影响网络
例子:People with the same interest are more closely connected due to homophily
Influence: Social connections can influence the individual characteristics of a person.
网络影响个人
例子:I recommend my musical preferences to my friends, until one of them grows to like my same favorite genres!
如何利用上面两个特点来预测图中未知标签的点?
Motivation
Similar nodes are typically close together or directly connected in the network:
- Guilt-by-association: If I am connected to a node with label 𝑋, then I am likely to have label 𝑋 as well.
相邻点通常会有相同的标签 - Classification label of a node 𝑣 in network may depend on:
节点v的特征;节点v的邻居的标签;节点v的邻居的特征。
注意:这里只考虑1阶邻居。
半监督学习:Collective Classification
Intuition: Simultaneous classification of interlinked nodes using correlations.
Markov Assumption: the label
Y
v
Y_v
Yv of one node
v
v
v depends on the labels of its neighbors
N
v
N_v
Nv.
P
(
Y
v
)
=
P
(
Y
v
∣
N
v
)
P(Y_v)=P(Y_v|N_v)
P(Yv)=P(Yv∣Nv)
三个步骤:
- Local Classifier: Used for initial label assignment
• Predicts label based on node attributes/features
• Standard classification task
• Does not use network information - Relational Classifier: Capture correlations between nodes
• Learns a classifier to label one node based on the labels and/or attributes of its neighbors
• This is where network information is used - Collective Inference: Propagate the correlation through network
• Apply relational classifier to each node iteratively
• Iterate until the inconsistency between neighboring labels is minimized
• Network structure affects the final prediction
Collective Classification Model共三种:
Relational classifiers
Iterative classification
Loopy belief propagation
下面分别介绍
Probabilistic Relational classifiers
Basic idea: Class probability
Y
v
Y_v
Yv of node 𝑣 is a weighted average of class probabilities of its
neighbors
标签节点的标签是ground-truth label
未标签节点初始化
Y
v
=
0.5
Y_v=0.5
Yv=0.5
不断按随机顺序update所有节点的标签概率,直到收敛。
更新公式为:
P
(
Y
v
=
c
)
=
1
∑
(
v
,
u
)
∈
E
A
v
,
u
∑
(
v
,
u
)
∈
E
A
v
,
u
P
(
Y
v
=
c
)
P(Y_v=c)=\\cfrac{1}{\\sum_{(v,u)\\in E}A_{v,u}}\\sum_{(v,u)\\in E}A_{v,u}P(Y_v=c)
P(Yv=c)=∑(v,u)∈EAv,u1(v,u)∈E∑Av,uP(Yv=c)
这里的公式是没有考虑边的权重的,如果有权重可以直接带入邻接矩阵A中即可。
问题:
不保障收敛
不能使用节点特征
例子
初始化:
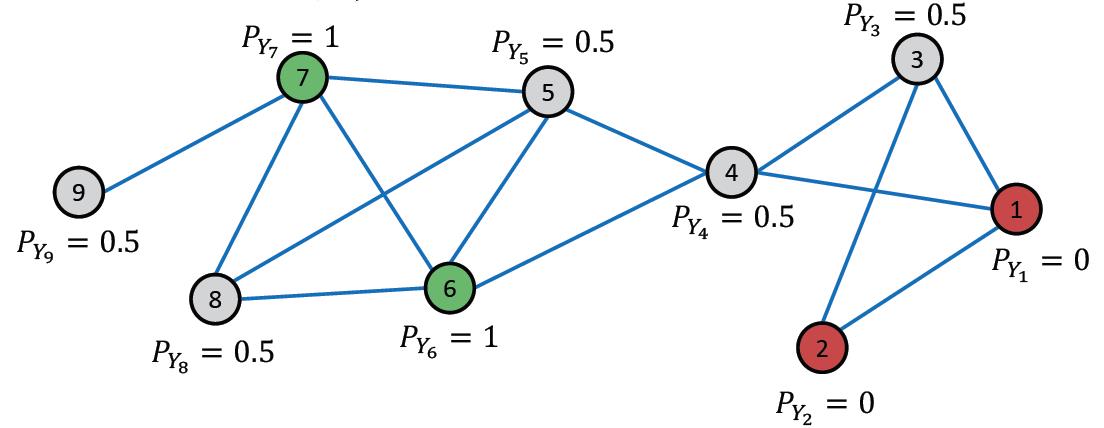 第一次迭代,随机顺序,例如从3号节点开始:
第一次迭代,随机顺序,例如从3号节点开始:
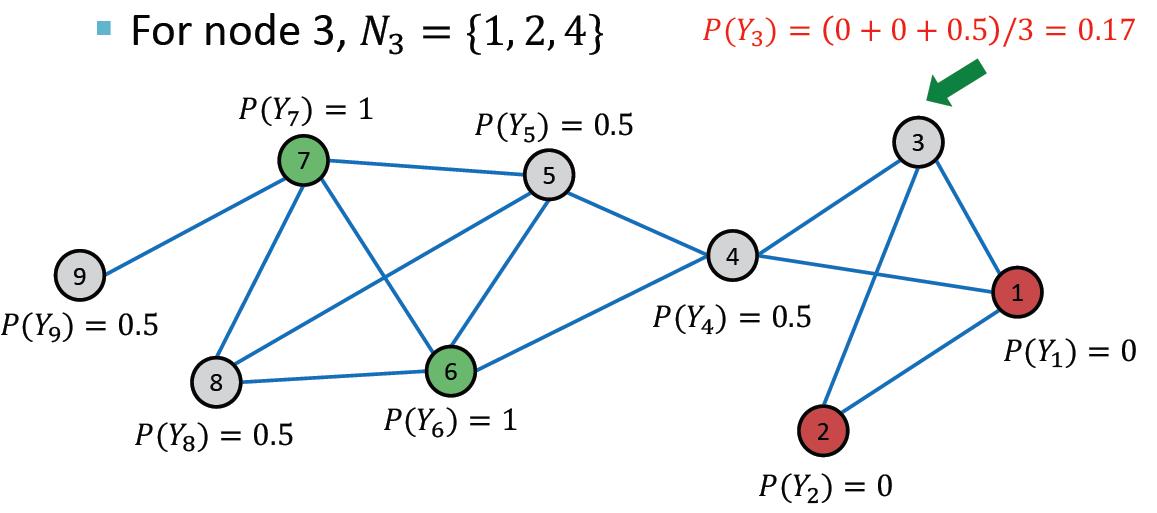
然后是节点4
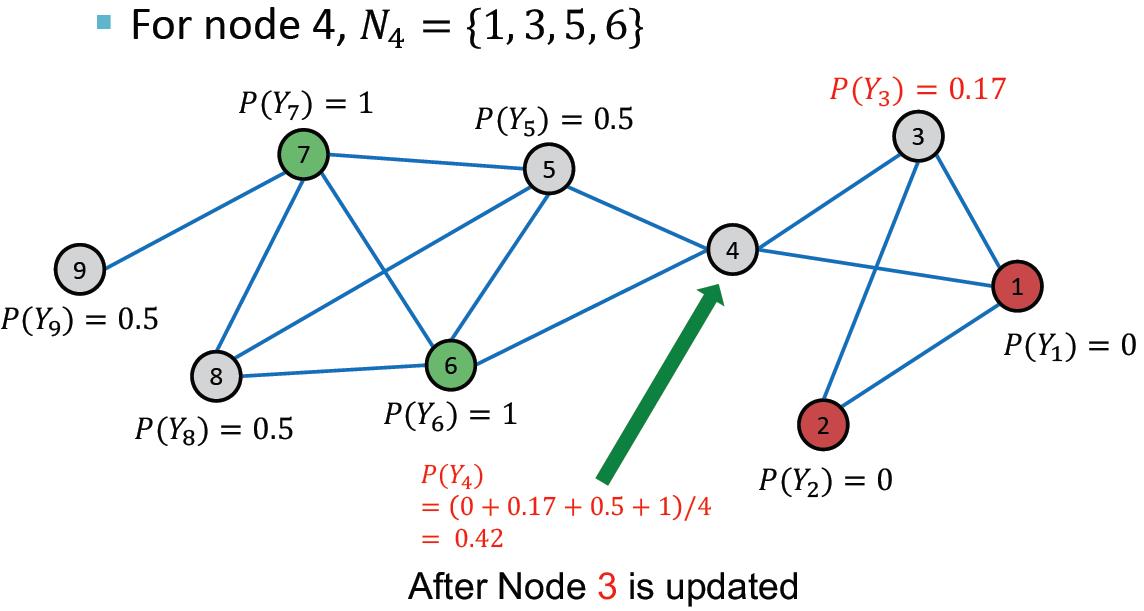
以此类推:
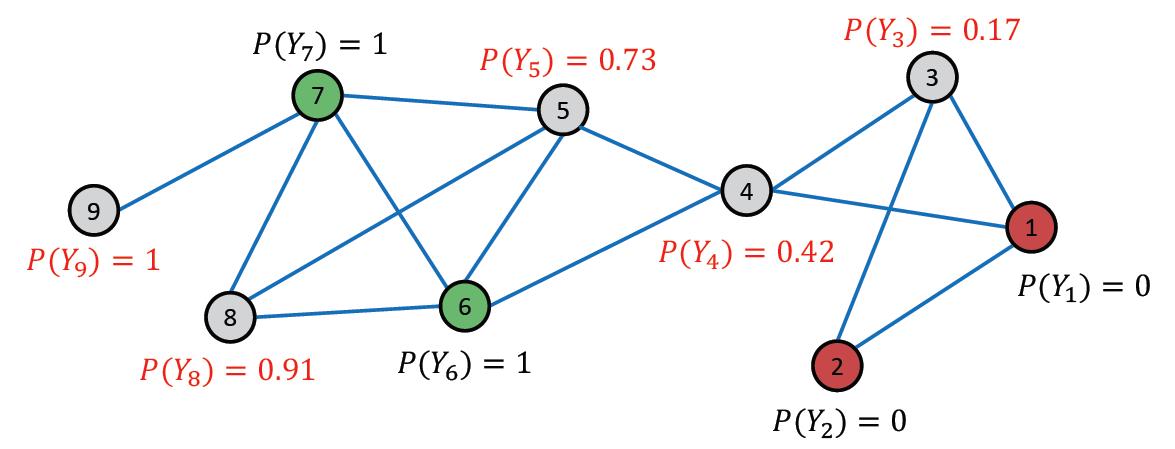
接下来第二次迭代,最后结果为:
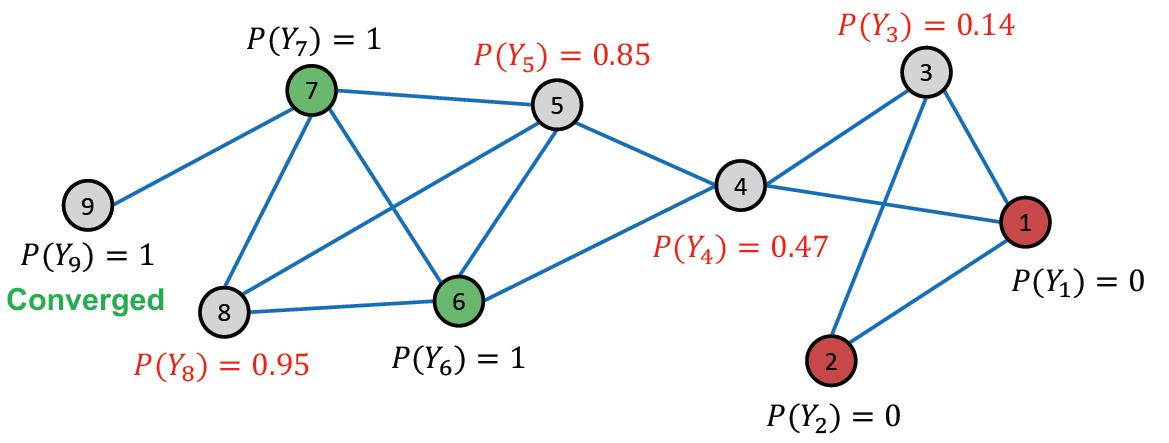
可以发现节点9收敛了
第三次迭代后:
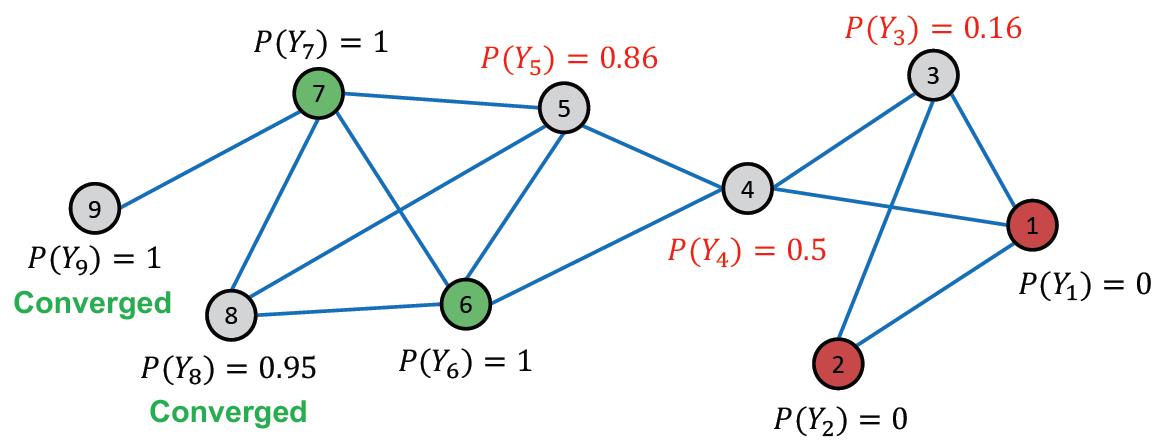
第四次迭代后:
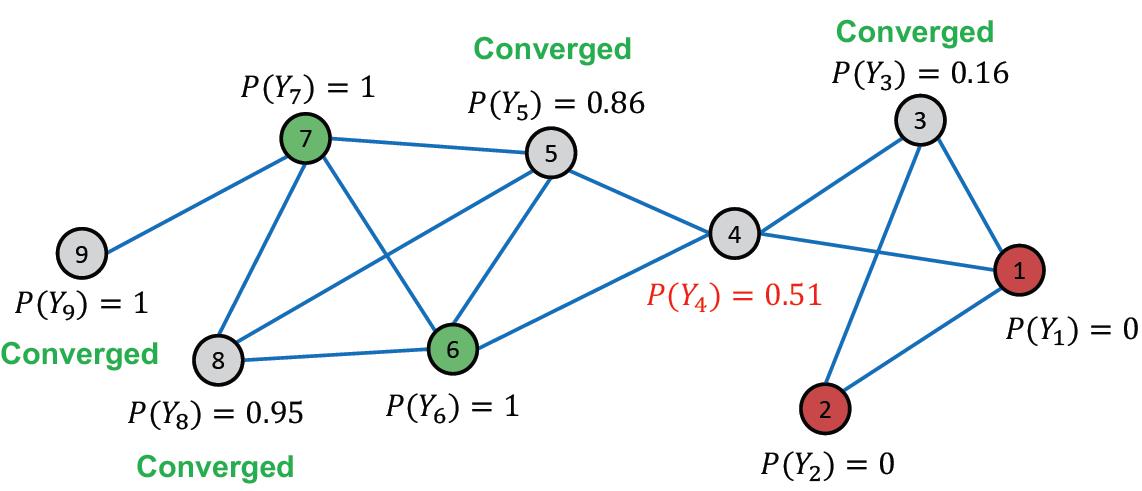
结果:
Nodes 4, 5, 8, 9 belong to class 1 (
𝑃
Y
v
>
0.5
𝑃_{Y_v} > 0.5
PYv>0.5)
Nodes 3 belong to class 0 (
𝑃
Y
v
<
0.5
𝑃_{Y_v} < 0.5
PYv<0.5)
Iterative classification
这个算法的比上节的算法(Relational classifiers)好在可以同时利用节点自身的特征以及邻居的label来进行分类计算。
算法用到两个分类器:
ϕ
1
(
f
v
)
\\phi_1(f_v)
ϕ1(fv)根据节点特征
f
v
f_v
fv预测节点的类别
ϕ
2
(
f
v
,
z
v
)
\\phi_2(f_v,z_v)
ϕ2(fv,zv)根据节点特征
f
v
f_v
fv以及节点邻居label的summary
z
v
z_v
zv预测节点的类别
对于计算向量
z
v
z_v
zv有很多种summary 方法:
例如下面这个图:
Histogram of the number (or fraction) of each label in
𝑁
v
𝑁_v
Nv 结果就是:2绿1红
Most common label in
𝑁
v
𝑁_v
Nv结果就是绿
Number of different labels in
𝑁
v
𝑁_v
Nv:结果就是2,1
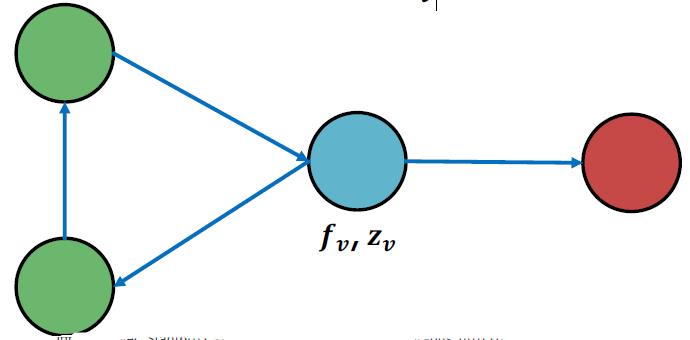
有了上面的基础知识,那么算法描述如下:
Phase 1: Classify based on node attributes alone
On a training set(这里是带标签的), train classifier (e.g., linear classifier, neural networks, …):
ϕ
1
(
f
v
)
\\phi_1(f_v)
ϕ1(fv) to predict
𝑌
v
𝑌_v
Yv based on
f
v
f_v
fv
ϕ
2
(
f
v
,
z
v
)
\\phi_2(f_v,z_v)
ϕ2(fv,zv) to predict
𝑌
v
𝑌_v
Yv based on
f
v
f_v
fv and summary
𝑧
v
𝑧_v
zv of labels of
𝑣
𝑣
v’s neighbors
Phase 2: Iterate till convergence(不一定收敛,设置迭代次数)
On test set(这里只有部分标签), set labels
𝑌
v
𝑌_v
Yvbased on the classifier
ϕ
1
\\phi_1
ϕ1, compute
𝑧
v
𝑧_v
zv and predict the labels with
ϕ
2
\\phi_2
ϕ2
Repeat for each node
𝑣
𝑣
v
Update
𝑧
v
𝑧_v
zv based on
𝑌
v
𝑌_v
Yv for all 𝑢 ∈ 𝑁!
Update
𝑌
v
𝑌_v
Yv based on the new
𝑧
v
𝑧_v
zv(
ϕ
1
\\phi_1
ϕ1)
Iterate until class labels stabilize or max number of iterations is reached
例子
Input: Graph of web pages
Node: Web page
Edge: Hyper-link between web pages
Directed edge: a page points to another page
Node features: Webpage description (思想是相同主题的网页通常会有链接指向)
For simplicity, we only consider 2 binary features
Task: Predict the topic of the webpage
先训练一个
ϕ
1
\\phi_1
ϕ1吃二维特征
f
v
f_v
fv得到节点label,当然这个分类器不用训练得很好或用很复杂的分类器,这里可以用线性分类器就ok。
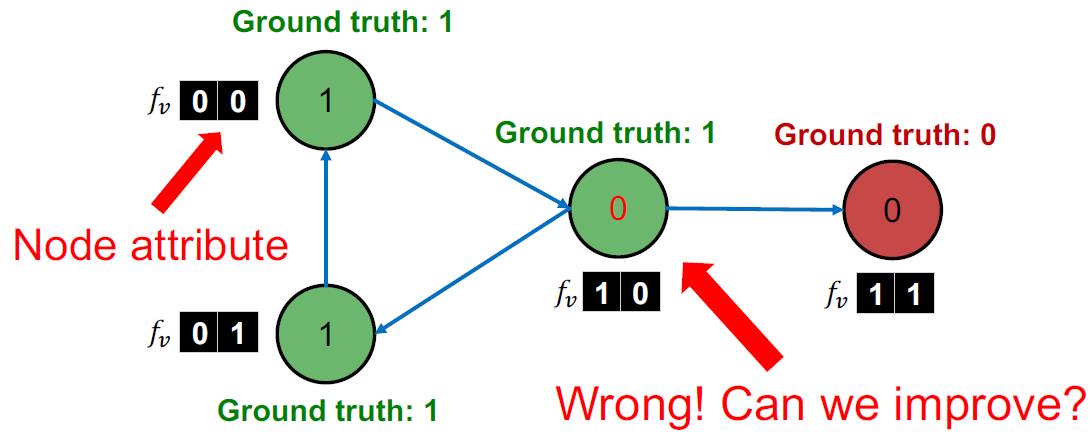
由于这里是有向图,用四个维度来表示
z
v
z_v
zv
I表示入度
O表示出度
I
0
=
1
I_0=1
I以上是关于CS224W摘要05.Message passin and Node classification的主要内容,如果未能解决你的问题,请参考以下文章