由浅入深,谈谈文件上传的优化思路
Posted 前端开发博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了由浅入深,谈谈文件上传的优化思路相关的知识,希望对你有一定的参考价值。
前言
在日常开发中我们少不了接触文件上传的功能,在某些业务场景中甚至需要我们上传较大的文件,如果文件体积比较大,或者网络条件不好时,上传的时间会比较长,用户不能刷新页面,也无法中断上传,只能耐心等待请求完成,这样的用户体验肯定是不好的。文章将由浅入深,整理文件上传的优化思路,相当于一个阶段性总结。前台界面使用vue-cli + element搭建,毕竟侧重点不在这里,服务端的功能比较单一,只需要接收传上来的文件流,使用KOA自己折腾一个,顺便回顾一下这部分知识。👊
首先明确一点,element的upload控件本身就集成了文件拖拽上传,限制格式以及上传个数等好用的功能,毕竟自己折腾出来印象还是深刻一些,所以这里就是不用,就是玩儿。
来个最简单的提提神v1
<form action="http://localhost:3000/upload" method="POST" enctype="multipart/form-data">
<input type="file" name="file" id="file"/>
<input type="submit" value="提交">
</form>值得一提的是这里的请求头有所变化,multipart/form-data专门用于有效的传输文件。默认的application/x-www-form-urlencoded类型不适合用于传输大型二进制数据或者包含非ASCII字符的数据。平常我们使用这个类型都是把表单数据使用url编码后传送给后端,二进制文件没办法一起编码进去。再看看Koa如何接受这个文件流保存在static/file目录下:
router.post("/upload", async (ctx) => {
// 获取上传文件
const file = ctx.request.files.file;
// 读取文件流
const fileReader = fs.createReadStream(file.path);
// 设置文件保存路径
const filePath = path.join(__dirname, `/static/file/`);
// 判断文件夹是否存在,如果不在的话就创建一个
if (!fs.existsSync(filePath)) {
fs.mkdirSync(filePath);
}
// 保存的文件名
const fileResource = filePath + `/${file.name}`;
const writeStream = fs.createWriteStream(fileResource);
fileReader.pipe(writeStream);
ctx.body = {
code: 0,
message: "上传成功",
};
});以上就是一个最简单的form post提交文件功能
一个凑合能用的版本v2
基于用户体验考虑,我们发现v1版本存在以下问题:
form提交会进行url跳转
没有上传进度条以及成功失败提示
还不算完,此时产品经理🔨提出:3. 请支持拖拽区域
对于第一,二点,可以考虑使用诸如axios等请求库,或者原生XMLHttpRequest,支持支持上传进度的监听,只需要监听 upload.onprogress 即可。
第三点,我们可以监听一个dom节点的拖放drop事件,在回调函数的参数可以获取到上传的文件。
话不多说,马上开整🎬
<template>
<div style="width: 400px">
<div class="content" ref="drop">
<i class="el-icon-upload" style="font-size: 26px"></i>
拖拽文件到此处上传
</div>
<el-progress :stroke-width="16" :percentage="progress"></el-progress>
</div>
</template>
<script>
export default {
data() {
return {
progress: 0,
};
},
mounted() {
const dropbox = this.$refs.drop;
//监听拖拽事件
dropbox.addEventListener(
"dragleave",
() => {
dropbox.style.backgroundColor = "transparent";
},
false
);
dropbox.addEventListener(
"dragenter",
(e) => {
e.stopPropagation();
e.preventDefault();
},
false
);
dropbox.addEventListener(
"dragover",
(e) => {
e.stopPropagation();
e.preventDefault();
dropbox.style.backgroundColor = "rgba(64,158,255,0.8)";
},
false
);
dropbox.addEventListener(
"drop",
(e) => {
e.stopPropagation();
e.preventDefault();
//获取文件
let file = e.dataTransfer.files[0];
//处理上传逻辑
this.handleUpload(file);
dropbox.style.backgroundColor = "transparent";
},
false
);
},
methods: {
/**
* 上传
*/
handleUpload(file) {
let formData = new FormData();
formData.append("file", file);
let xhr = new XMLHttpRequest();
//监听进度
xhr.upload.onprogress = (e) => {
this.progress = parseInt(String((e.loaded / e.total) * 100));
};
xhr.open("post", "http://localhost:3000/upload");
xhr.send(formData);
xhr.onreadystatechange = () => {
if (xhr.readyState == 4 && xhr.status == 200) {
console.log(xhr.responseText);
this.$message({
message: "上传成功",
type: "success",
});
}
};
},
},
};
</script>算是完成了一个凑合的版本🎉,在这里休息一下,回顾上面的知识点,还是稍微简单了一点。大部分人都会想做到这里就可以完成功能了,抓紧应付交差完事儿~这也是笔者之前的惯有思维,但如果我们想在项目上更加突出的话还应该对自己有更高的要求,尽量体现自己的竞争力,这样找工作时简历也不会无亮点可写,泯然众人🏁。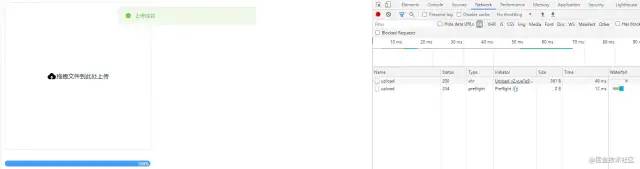
大文件切片v3
现在来看看在文章一开始提出的实现大文件上传会遇见的超时问题,大文件上传最主要的问题就在于:在同一个请求中,要上传大量的数据,导致整个过程会比较漫长,且失败后需要重头开始上传。试想,如果我们将这个请求拆分成多个请求,每个请求的时间就会缩短,且如果某个请求失败,只需要重新发送这一次请求即可,无需从头开始。那么如何将文件切片拆分呢? 在javascript中,文件FIle对象是Blob对象的子类,Blob对象包含一个重要的方法slice,通过这个方法,我们就可以对二进制文件进行拆分。首先解决第一点,拆分简单,但是在服务端接收到切片之后,由于接口请求是异步并发的,无法控制每个切片的顺序,如何将文件还原呢?我们还需要一个标识当前切片位置的索引,通过索引我们按顺序拼接切片,还原成文件。
/**
* 文件切片方法
* 文件
* 切片大小
*/
sliceFile(file, chunkSize = 1024 * 1024 * 5) {
let total = file.size;
let start = 0,
end = 0;
let chunks = []; //存储切片的数组
while (end < total) {
start = end;
end += chunkSize;
let chunkData = file.slice(start, end);
chunks.push(chunkData);
}
return chunks;
}
//切片名字用文件名+下标标识
requestUpload(data) {
let formData = new FormData();
formData.append("chunk", data.chunk);
formData.append("index", data.index);
formData.append("filename", data.filename);
let xhr = new XMLHttpRequest();
// 监听进度
// xhr.upload.onprogress = (e) => {
// this.progress = parseInt(String((e.loaded / e.total) * 100));
// };
xhr.open("post", "http://localhost:3000/upload");
xhr.send(formData);
xhr.onreadystatechange = () => {
if (xhr.readyState == 4 && xhr.status == 200) {
console.log(xhr.responseText);
this.$message({
message: "上传成功",
type: "success",
});
}
};
}
/**
* 上传
*/
handleUpload() {
let file = document.getElementById("file").files[0];
console.log(file);
let chunks = this.sliceFile(file);
for (let index = 0; index < chunks.length; index++) {
// const element = array[index];
this.requestUpload({
chunk: chunks[index],
index,
filename: file.name,
});
}
}同理服务端也得做对应的改变,注意这里的IO操作全是异步的,该await的地方记得await
router.post("/upload", async (ctx) => {
// 获取上传文件
const file = ctx.request.files.chunk;
const { filename, index } = ctx.request.body;
// 读取文件流
const fileReader = fs.createReadStream(file.path);
// 设置文件保存路径
const filePath = path.join(__dirname, `/static/${filename}/`);
// 判断文件夹是否存在,如果不在的话就创建一个
if (!fs.existsSync(filePath)) {
fs.mkdirSync(filePath);
}
// 保存的文件名 eg: 0-demo.txt,1-demo.txt...
const fileResource = filePath + `${index}-${filename}`;
const writeStream = fs.createWriteStream(fileResource);
fileReader.pipe(writeStream);
ctx.body = {
code: 0,
message: "上传成功",
};
});结果如下,到这里我们已经完成初步的拆解,接下来就是将chunk合并。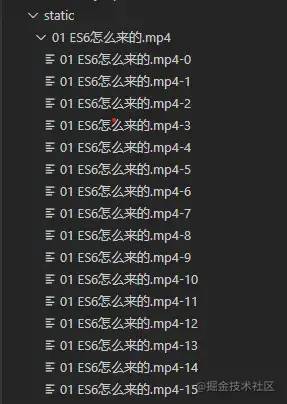 合并倒也简单,我们已经标识好了切片顺序,只需要按照排序重新创造可写流createReadStream写入文件,但是怎么确定何时合并呢? 在所有切片上传完成之后,每一次上传都是一次异步任务,这时我们自然想到使用Promise.all,可以将多个Promise实例包装成一个新的Promise实例,这样我们可以在promise.then发起合并切片的请求。 PS: 下面的链接记录了作者学习promise的探索过程,有兴趣者可以共同探讨🍎
合并倒也简单,我们已经标识好了切片顺序,只需要按照排序重新创造可写流createReadStream写入文件,但是怎么确定何时合并呢? 在所有切片上传完成之后,每一次上传都是一次异步任务,这时我们自然想到使用Promise.all,可以将多个Promise实例包装成一个新的Promise实例,这样我们可以在promise.then发起合并切片的请求。 PS: 下面的链接记录了作者学习promise的探索过程,有兴趣者可以共同探讨🍎
手写promise记录[1]
我们将代码改进一下:
上传方面改变了进度条的获取逻辑,新增progressArr数组,数组每一项表示每一个切片的上传进度,因此我们计算方式为:求出progressArr数组和,除以文件大小,即是当前的上传进度了。增加一个fileCtx变量指向文件对象,在input change事件触发时赋值,上传需要判断文件是否存在
<template>
<div>
<div class="content" ref="drop">
<input type="file" name="file" id="file" @change="addFile2Ctx" />
<el-button size="small" type="primary" @click="handleUpload"
>点击上传</el-button
>
</div>
<el-progress
:text-inside="true"
:stroke-width="16"
:percentage="progress"
></el-progress>
</div>
</template>
<script>
export default {
data() {
return {
fileCtx: null, //文件对象
progressArr: [], //每个切片的进度
};
},
methods: {
/**
* change事件
*/
addFile2Ctx() {
this.fileCtx = document.getElementById("file").files[0];
},
/**
* 文件切片方法
* 文件
* 切片大小 默认5M
*/
sliceFile(file, chunkSize = 1024 * 1024 * 5) {
let total = file.size;
let start = 0,
end = 0;
let chunks = []; //存储切片的数组
while (end < total) {
start = end;
end += chunkSize;
let chunkData = file.slice(start, end);
chunks.push(chunkData);
}
return chunks;
},
/**
* 请求上传
*/
requestUpload(data) {
return new Promise((resolve) => {
let formData = new FormData();
formData.append("chunk", data.chunk);
formData.append("index", data.index);
formData.append("filename", data.filename);
let xhr = new XMLHttpRequest();
this.progressArr = [];
// 把每个切片的进度收集起来
xhr.upload.onprogress = (e) => {
this.$set(this.progressArr, data.index, e.loaded); //加载了多少
};
xhr.open("post", "http://localhost:3000/upload");
xhr.send(formData);
xhr.onreadystatechange = () => {
if (xhr.readyState == 4 && xhr.status == 200) {
resolve(xhr.responseText);
}
};
});
},
/**
* 处理upload
*/
handleUpload() {
let file = this.fileCtx;
if (file == null) {
alert("无文件");
return;
}
let chunks = this.sliceFile(file);
let tasks = [];
for (let index = 0; index < chunks.length; index++) {
tasks.push(
this.requestUpload({
chunk: chunks[index],
index,
filename: file.name,
})
);
}
console.time();
//发起合并请求
Promise.all(tasks).then(() => {
console.timeEnd();
let xhr = new XMLHttpRequest();
xhr.open("post", "http://localhost:3000/merge");
xhr.send(
JSON.stringify({ filename: this.fileCtx.name, size: chunks[0].size })
);
xhr.onreadystatechange = () => {
if (xhr.readyState == 4 && xhr.status == 200) {
this.$message({
message: "合并成功",
type: "success",
});
}
};
});
},
},
computed: {
progress() {
if (!this.fileCtx || !this.progressArr.length) return 0;
let loaded = this.progressArr.reduce((toal, cur) => toal + cur);
return parseInt(((loaded * 100) / this.fileCtx.size).toFixed(2));
},
},
};
</script>接收端,createWriteStream可以传入start参数,允许我们在指定位置写入流。在读写完成后,把文件切片一并删除,避免占用服务器磁盘空间。
router.post("/merge", async (ctx) => {
let { filename, size } = JSON.parse(ctx.request.body);
const filePath = path.join(__dirname, `/static/${filename}/`);
//读取目录下切片
let chunks = fs.readdirSync(filePath);
chunks = chunks.sort((a, b) => {
return a.split("-")[0] - b.split("-")[0];
});
let tasks = [];
for (let index = 0; index < chunks.length; index++) {
const chunk = chunks[index];
let p = new Promise((resolve) => {
const fileReader = fs.createReadStream(`${filePath}/${chunk}`);
const writeStream = fs.createWriteStream(
path.join(__dirname, `/static/file/${filename}`),
{
start: index * size,
}
);
fileReader.pipe(writeStream);
fileReader.on("end", function() {
//1删掉切片
fs.unlinkSync(`${filePath}/${chunk}`);
resolve();
});
});
tasks.push(p);
}
//2切片传输完成,删除文件夹
Promise.all(tasks)
.then(() => {
fs.rmdirSync(filePath);
})
.catch((e) => {
console.log(e);
});
// fs.readdir(filePath, () => {});
ctx.body = {
code: 0,
message: "合并成功",
};
});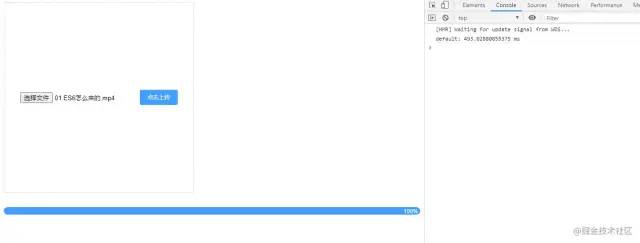 如此一来,大文件切片这个功能算是完成了,发现上传速度提升并不明显💚💚。。可能是文件还不够大的缘故,无论如何可见这个设计思路是正确的,剩下的就都是需要优化改进的地方了。
如此一来,大文件切片这个功能算是完成了,发现上传速度提升并不明显💚💚。。可能是文件还不够大的缘故,无论如何可见这个设计思路是正确的,剩下的就都是需要优化改进的地方了。
文件格式校验v3.5
input标签自带accept可以限制上传的文件格式,但是只能和input配合使用,类似拖拽上传区域就不行了,官方也不建议使用。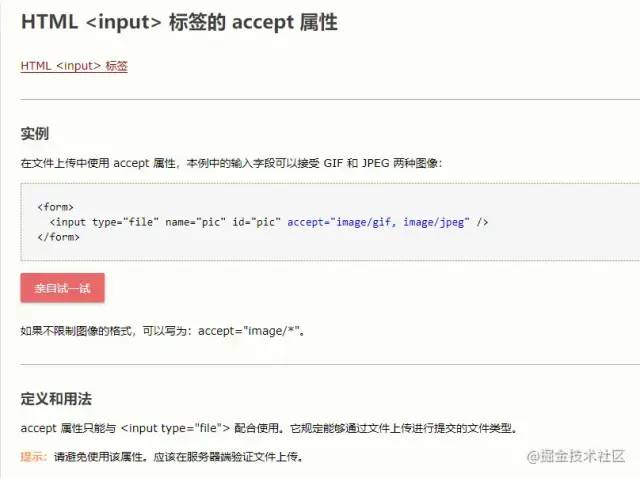 我们残忍抛弃了他,选择另外更好的方案:
我们残忍抛弃了他,选择另外更好的方案:
方案1:剩下最容易想到的,也是相对常用的,是直接使用文件的拓展名。但依靠文件拓展名是不精准的,用户可以手动修改拓展名,比如把一个word文档由.doc改为.pdf。
方案2:将上传文件转为二进制,再获取其头文件的十六进制编码,根据这个就可以精准判定上传文件类型。
所有类型校验为了安全性需要在前后端都做处理,单纯的前端限制是可以被很多方式绕过的,为了偷懒这里我只做了前端的格式校验
采用了方案2,在使用的过程发现了一点问题:
对照了文件类型头信息,我上传了两个同样格式的mp4文件,「截取的文件头却是不一样的」,有没有懂王可以提点意见🐛🐛,请在楼下指出,万分感谢。
不同格式文件头的长度是不一样的(大部分是8位),举个例子png是八位
89504E47,但是JPEG 则是六位FFD8FF
⚡文件头信息给Notepad++安装插件hex-editor即可查看  核心代码如下:增加文件校验方法,判断文件是否是MP4格式
核心代码如下:增加文件校验方法,判断文件是否是MP4格式
//校验文件格式
validateFileType(file) {
const map = new Map();
map.set("0000001C66747970", "mp4"); //mp4
map.set("0000001866747970", "mp4"); //mp4
let reader = new FileReader();
reader.readAsArrayBuffer(file); //读取二进制流
return new Promise((resolve) => {
reader.onload = function (event) {
try {
let buffer = new Uint8Array(event.target.result);
buffer = buffer.slice(0, 8);
let headBuffer = Array.from(buffer)
.map((e) => {
return e.toString(16).toUpperCase().padStart(2, "0");
})
.join("");
let type = map.get(headBuffer);
resolve(type);
} catch (error) {
throw new Error(error);
}
};
});
}根据文件头判断文件的类型[2]
文件唯一性v4
此前我们通过 切片下标+文件名 的方式作为切片的标识,但是这样做是不稳妥的。断点续传时修改了文件名的情况下,服务端保存的切片就无法利用起来,因此正确的做法是根据文件内容生成 hash。为了计算hash,引入了另一个库 spark-md5,它可以根据文件内容计算出文件的 hash 值。考虑到如果上传一个超大文件,读取文件内容计算 hash 是非常耗费时间的,尝试了一下计算300M的文件hash就需要差不多5s的时间,并且会引起 UI 的阻塞,导致页面假死状态,。解决方案有两种:
使用 web-worker 在 worker 线程计算 hash
requestidlecallback,浏览器实验api,可以利用空闲时段,主事件循环上执行后台和低优先级工作,而不会影响延迟关键事件,据说React 16的Fiber的调度策略就是基于requestIdleCallback和requestAnimationFrame两个API。
这里采用方案1,日后再搞一搞第二种方案。直接把spark-md5示例代码拿过来用,不断读入新的切片直至完成,通过spark.end()返回计算结果。监听web-worker的onmessage事件,拿到计算后的hash,上传时用hash + 索引代替文件名+索引。
self.importScripts("/spark-md5.min.js");
self.onmessage = function(d) {
let { chunks } = d.data;
const spark = new self.SparkMD5.ArrayBuffer();
let index = 0;
let fileReader = new FileReader();
fileReader.onerror = function() {
console.warn("oops, something went wrong.");
};
fileReader.onload = function(e) {
console.log("read chunk nr", index + 1);
spark.append(e.target.result); // Append array buffer
index++;
if (index < chunks.length) {
loadNext();
self.postMessage({
msg: index + " loaded",
});
} else {
console.log("finished loading");
console.info("computed hash", spark.end()); // Compute hash
self.postMessage({
hash: 100,
});
}
};
function loadNext() {
fileReader.readAsArrayBuffer(chunks[index]);
}
loadNext();
}; 有了唯一标识之后,我们开始考虑怎么做断点续传,顾名思义,可以暂停,可以恢复上传。我们把问题分解一下,也就是要做到如下两点:
有了唯一标识之后,我们开始考虑怎么做断点续传,顾名思义,可以暂停,可以恢复上传。我们把问题分解一下,也就是要做到如下两点:
中断,这个简单,中断xhr请求就可以
恢复上传,从哪里开始恢复是关键。
第一点,调用xhr的abort方法可以中断请求,我们使用数组requestArr存储多个请求的xhr对象,请求完成时在自身的onreadystatechange回调中从数组中把这个请求删除,剩下还没完成的请求。点击暂停键,遍历数组requestArr,调用abort暂停上传。 第二点,每一个请求完成后切片都会保存在服务器暂存区目录下,也就是说我们可以知道当前那些切片是上传完成,新增一个接口,返回这些切片。在上传时做一层过滤,避免重复上传,达到续传效果。请求段代码:
/**
* 请求上传
*/
requestUpload(data) {
return new Promise((resolve) => {
let formData = new FormData();
formData.append("chunk", data.chunk);
formData.append("index", data.index);
formData.append("hash", data.hash);
let xhr = new XMLHttpRequest();
//监听进度
xhr.upload.onprogress = (e) => {
this.$set(this.progressArr, data.index, e.loaded); //每个切片进度
};
xhr.open("post", "http://localhost:3000/upload");
xhr.send(formData);
xhr.onreadystatechange = () => {
if (xhr.readyState == 4 && xhr.status == 200) {
let idx = this.requestArr.findIndex((e) => e == xhr);
this.requestArr.splice(idx, 1); //删除请求
resolve(xhr.responseText);
}
};
this.requestArr.push(xhr);
});
}
/**
* 处理upload
*/
async handleUpload() {
// check
let file = this.fileCtx;
if (file == null) {
alert("无文件");
return;
}
// get file type
let type = await this.validateFileType(file);
if (type !== "mp4") {
alert("格式不支持");
return;
}
// get file slice
let chunks = this.sliceFile(file);
// calc hash
let hash = await this.calcHashByWebWorker(chunks);
// get remain files
let remainfiles = await this.getRemainFile(hash);
let tasks = [];
for (let index = 0; index < chunks.length; index++) {
try {
if (remainfiles.includes(`${hash}-${index}`)) continue;
tasks.push(
this.requestUpload({
chunk: chunks[index],
index,
hash: hash,
})
);
} catch (error) {
console.log(error);
}
}
//发起合并请求
Promise.all(tasks).then(() => {
let xhr = new XMLHttpRequest();
xhr.open("post", "http://localhost:3000/merge");
// // let type = this.fileCtx.name;
// console.log(this.fileCtx);
xhr.send(
JSON.stringify({
hash: hash,
size: chunks[0].size,
format: type //文件保存: hash + 文件格式
})
);
xhr.onreadystatechange = () => {
if (xhr.readyState == 4 && xhr.status == 200) {
this.$message({
message: "合并成功",
type: "success",
});
}
};
});
}点击暂停,发现有两个请求被中断了,切片也没有全部上传,符合我们的预期 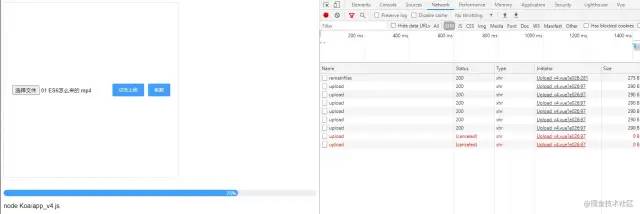
 点击恢复上传,先获取了服务端保存的切片,过滤掉已上传切片,第二次请求upload只调用两次,因为我们只需要把剩余部分传上去即可,符合预期,至此断点续传的功能完成。
点击恢复上传,先获取了服务端保存的切片,过滤掉已上传切片,第二次请求upload只调用两次,因为我们只需要把剩余部分传上去即可,符合预期,至此断点续传的功能完成。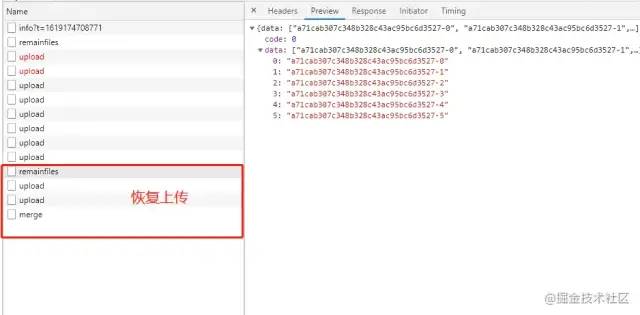
继续优化的一些方向
此前测试一直是使用70多M的一个文件,切片大小为10M,这件会产生八个切片,这只是文件较小的情况,1G的文件将会有100个切片数,所以需要考虑的一个情况是文件切片数量过多,上传请求太多也会导致卡帧,这时候怎么处理? 看了一下network,发现并发进行的请求数最多是六个,图中绿色部分请求先开始,灰色部分的等待前面请求完成,资源释放。原来是浏览器对对同一域名下的最大连接数做了限制,这里chrome4+对应的就是6个并发。对客户端操作系统而言,过多的并发涉及到端口数量和线程切换开销。HTTP/1.1有Keep Alive,支持复用现有连接,等请求返回回来后,再复用连接请求可以快很多。
看了一下network,发现并发进行的请求数最多是六个,图中绿色部分请求先开始,灰色部分的等待前面请求完成,资源释放。原来是浏览器对对同一域名下的最大连接数做了限制,这里chrome4+对应的就是6个并发。对客户端操作系统而言,过多的并发涉及到端口数量和线程切换开销。HTTP/1.1有Keep Alive,支持复用现有连接,等请求返回回来后,再复用连接请求可以快很多。 假设现在由于网络等原因,想将最大并发数改为3个该怎么做呢?不妨也从这个角度入手想一想,可以建一个最大并发数为3的队列,存储着task1,task2,task3,里面task2先完成了,task4取代了2的位置,所以队列里变成了task1,task4,task3,下一轮里面task1先完成了,task5补位,依此类推...主要代码如下:
假设现在由于网络等原因,想将最大并发数改为3个该怎么做呢?不妨也从这个角度入手想一想,可以建一个最大并发数为3的队列,存储着task1,task2,task3,里面task2先完成了,task4取代了2的位置,所以队列里变成了task1,task4,task3,下一轮里面task1先完成了,task5补位,依此类推...主要代码如下:
let imgList = []
for (let i = 0; i < 20; i++) {
imgList.push({
name: 'url' + i
})
}
// console.log(imgList);
function loadImg(url) {
return new Promise((resolve, reject) => {
setTimeout(() => {
console.log(url.name + "loaded");
resolve()
}, Math.random() * 3000)
})
}
/**
*
* @param {*} urls
* @param {*} handle
* @param {*} limit
*/
function limitLoad(urls,handle, limit) {
let _copy = [].concat(urls)
let loadQuque = []
loadQuque = _copy.splice(0, limit).map((e, i) => {
return handle(e).then(() => {
return i
})
})
let p = Promise.race(loadQuque)
for (let index = 0; index < _copy.length; index++) {
p = p.then((res) => {
loadQuque[res] = handle(_copy[index]).then(() => {
return res
})
return Promise.race(loadQuque)
})
}
}
limitLoad(imgList, loadImg, 3)大概讲讲思路:核心在于return Promise.race(loadQuque) ,race()可以帮我们找到最先完成的任务,也就是说:p返回的永远都是当前队列里最先完成的那一个,通过then获取任务在队列的下标,把新任务挂上去占位。还能优化的地方包括但不限于:
上传报错重试机制,可能是由于超时,也可能是其他
切片大小自动计算。目前是写死的,但是理想状态应该根据包大小以及网络状态动态调整
断点续传,重新打开页面进度就没有了,应该进入页面获取一次,进度条逻辑得改一改。
......
代码的东西都是虚拟的,这里面水太深,我年纪小,把握不住
后记
至此,我们分析了对文件上传的处理,分别做了几个版本的上传功能,版本的迭代可以说是越做越好的🎉🎉,在完成需求的同时也提高了自己📈。不满足于现状是驱使人进步的动力,也是我们应当保持的心态。尽管后面还有一些功能未能完善,我还是厚着脸皮求赞🔥🔥🔥,有空会继续更新。如有疑问或者错误,请各位评论区批评指正,共同进步。参考链接:
字节跳动面试官:请你实现一个大文件上传和断点续传[3]
作者:violetrosez
https://juejin.cn/post/6954636033895956493
参考资料
[1]
https://juejin.cn/post/6937553777369022501
[2]https://www.jianshu.com/p/afc7a777e764
[3]https://juejin.cn/post/6844904046436843527#heading-17
推荐阅读
关注下方「前端开发博客」,回复 “加群”
加入我们一起学习,天天进步

如果觉得这篇文章还不错,来个【分享、点赞、在看】三连吧,让更多的人也看到~
以上是关于由浅入深,谈谈文件上传的优化思路的主要内容,如果未能解决你的问题,请参考以下文章