ConcurrentHashMap 实现原理
Posted 盛夏温暖流年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ConcurrentHashMap 实现原理相关的知识,希望对你有一定的参考价值。
一. ConcurrentHashMap 是什么
在并发编程中,ConcurrentHashMap 是一个经常被使用的数据结构,相比于 Hashtable 以及Collections.synchronizedMap() 来说,ConcurrentHashMap 在线程安全的基础上提供了更好的写并发能力,同时还降低了对读一致性的要求,是 java.util.concurrent 包里面提供的一个线程安全并且高效的 HashMap。
二. ConcurrentHashMap 的不同版本实现
JDK 1.7 中的实现
JDK 1.7 中 的 ConcurrentHashMap 采用了分段锁的设计,只有在同一个分段内才存在竞态关系,不同的分段锁之间没有锁竞争。相比于对整个 Map 加锁,分段锁大大提高了高并发环境下的处理能力。
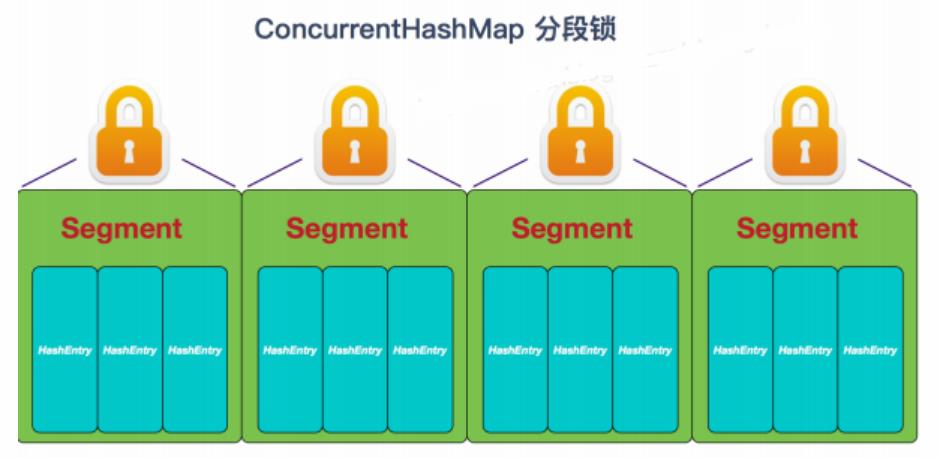
如上图所示,ConcurrentHashMap 底层是由一个 Segment 数组组成的,每个 Segment 元素包含一个 HashEntry 数组,而每个 HashEntry 元素都是一个链表结构的节点。
提到 HashEntry,很容易会联想到 HashMap 中的 Entry,它们有什么区别呢?
来看一下 HashEntry 的代码实现:
static final class HashEntry {
final int hash;
final K key;
volatile V value;
volatile HashEntry next;
}可以看出,HashEntry 和 HashMap 非常类似,唯一的区别就是其中的核心数据 value 以及 next 都被 volatile 修饰,以此保证了多线程读写过程中对应变量的可见性。
接下来,我们再来看一下 JDK 1.7 中的 ConcurrentHashMap 的核心方法 put 方法 和 get 方法 的实现:
put 方法
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
// 计算key的hash值
int hash = hash(key);
// 根据 hash 值,segmentShift,segmentMask 定位 Segment
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null)
s = ensureSegment(j);
// 将键值对保存到对应的 Segment 中
return s.put(key, hash, value, false);
}可以看到,首先通过 key 定位到 Segment,之后在对应的 Segment 中才会调用具体的 put 方法,对应 put 的源码如下:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 如果 tryLock 成功,就返回 null
// 否则尝试去获取锁,获取锁失败的情况下,为了节约时间提前去新建或获取 HashEntry
// 如果超过一定次数就强制加锁
HashEntry<K, V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K, V>[] tab = table;
// 根据table数组的长度和hash值计算index下标
int index = (tab.length - 1) & hash;
// 找到table数组在index偏移处链表的头部
HashEntry<K, V> first = entryAt(tab, index);
// 从first开始遍历链表
for (HashEntry<K, V> e = first; ; ) {
if (e != null) {
K k;
// 如果key相同
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
// 获取旧值
oldValue = e.value;
// 若absent=false即允许覆盖
if (!onlyIfAbsent) {
// 覆盖旧值
e.value = value;
++modCount;
}
// 若已经找到,就退出链表遍历
break;
}
// 若key不相同,继续遍历
e = e.next;
} else {
// 如果直到链表尾部也没有找到相同的key
if (node != null)
// 将元素放到链表头部
node.setNext(first);
else
// 创建新的Entry
node = new HashEntry<K, V>(hash, key, value, first);
// count记录元素个数
int c = count + 1;
// 如果数组元素个数超过threshold,并且table长度小于最大容量
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
// 将table的长度扩容为原来的两倍
rehash(node);
else // 如果没有超过阈值
// 就在index偏移处添加链表节点
setEntryAt(tab, index, node);
// 修改操作数
++modCount;
// 将count+1
count = c;
oldValue = null;
break;
}
}
} finally {
// 执行完操作后,释放锁
unlock();
}
// 返回oldValue
return oldValue;
}总的来说,put 的流程如下:
- 通过 key 的 hashcode 定位到 Segment 中对应的 HashEntry;
- 遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value 值。
- 为空则需要新建一个 HashEntry 并加入到 Segment 中,在此之前,会先判断是否需要扩容。
- 最后解除获取当前 Segment 的锁。
get 方法
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
// 首先计算出segment数组的下标
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) { // 根据下标找到segment
// 根据 (tab.length - 1) & h) 得到对应HashEntry数组的下标,遍历链表获取对应的 value
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}get 方法的流程如下:
- 根据 key 的 hash 值通过位运算以及基础偏移量的相加获取具体的 key 偏移量 u;
- 通过偏移量 u 去 Segment 数组中获取 u 位置处的 Segment 对象;
- 在有对象的情况下,通过 for 循环链表的方式获取 Segment 对象的 HashEntry 值进行比较;
- 如果存在则返回对应 value 值,否则返回 null 值表示不存在;
JDK 1.8 中的实现
JDK 1.8 的 ConcurrentHashMap 取消了 Segment 分段锁,采取 CAS 和 synchronized 来保证并发的安全性。synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发问题。
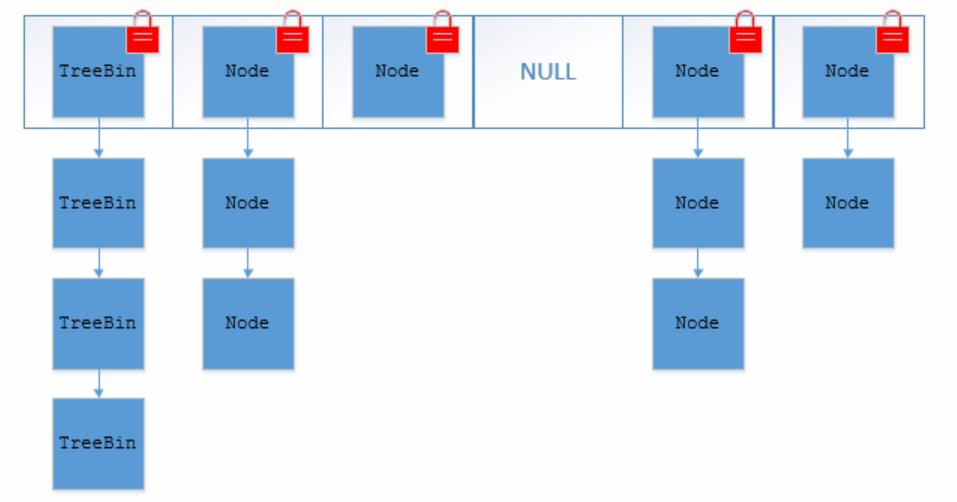
如图所示,也将 JDK 1.7 中存放数据的 HashEntry 改为了 Node,代码如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString(){ return key + "=" + val; }
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
public final boolean equals(Object o) {
Object k, v, u; Map.Entry<?,?> e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry<?,?>)o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
Node<K,V> find(int h, Object k) {
Node<K,V> e = this;
if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
}Node 是最核心的内部类,它包装了 key-value 键值对,所有插入 ConcurrentHashMap 的数据都包装在这里面。它与 HashMap 中的定义相似,差别在于,它对 value 和 next 属性设置了volatile 同步锁(与 JDK 1.7 的 Segment 相同),不允许调用 setValue 方法直接改变 Node 的value 域,还增加了 find 方法辅助 map.get() 方法的实现。
接下来,来看一下 JDK 1.8 中的 ConcurrentHashMap 的核心方法 put 方法 和 get 方法 的实现:
put 方法
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
//不允许 key 或 value 为 null
if (key == null || value == null) throw new NullPointerException();
//计算hash值
int hash = spread(key.hashCode());
int binCount = 0;
//死循环,插入成功才跳出(自旋锁)
for (Node[] tab = table;;) {
Node f; int n, i, fh;
//如果table为空的话,初始化table
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//根据hash值计算出在table里面的位置
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//用CAS操作i偏移处的元素,table中位置为i处元素为空的时候,不需要加锁
if (casTabAt(tab, i, null, new Node(hash, key, value, null)))
break;
}
//当遇到正在扩容的时候
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//头结点上锁(这里的结点可以理解为hash值相同组成的链表的头结点)
synchronized (f) {
if (tabAt(tab, i) == f) {
//节点是链表的节点
if (fh >= 0) {
binCount = 1;
//遍历链表所有的结点
for (Node e = f;; ++binCount) {
K ek;
//如果hash值和key值相同,则修改对应结点的value值
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node pred = e;
//遍历到最后一个结点,说明新的节点需要插入,将其插入在链表尾部
if ((e = e.next) == null) {
pred.next = new Node(hash, key, value, null);
break;
}
}
}
//如果这个节点是树节点,就按照树的方式插入值
else if (f instanceof TreeBin) {
Node p;
binCount = 2;
if ((p = ((TreeBin)f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
//如果链表长度已经达到临界值8,就需要把链表转换为树结构
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//将当前ConcurrentHashMap的元素数量+1
addCount(1L, binCount);
return null;
}put 方法的流程如下:
- 判断对应的 key 和 value 是否为空,为空则直接抛出异常;
- 判断 table 数组是否为空,空则进行初始化操作;
- 当 table 不为空时,判断在下标 i 的位置是否存在值,不存在则通过 CAS 方式直接在对应位置进行更新,更新成功则直接退出;
- 如果下标 i 的位置不为空,且正在准备扩容,则调用 helpTransfer() 方法帮忙 table 进行扩容;
- 如果未处于扩容状态,则进行 synchronized 加锁操作给头节点加锁,同时判断当前偏移处的值是否是前面判断时的值;
- 判断头节点是否为链表,需要通过链表的方式循环判断是否有与当前 key 相同的值,有则在允许覆盖的情况下进行覆盖,没有则新建一个 Node 值放在链表最后;
- 如果当前的 Node 节点为树节点,则进行树节点的相关操作;
- 当节点个数 binCount 长度超过8时,就对当前 Node 节点链表进行红黑树的转换;
- 最后根据 binCount 值,通过 addCount() 方法增加元素个数,同时检测是否需要进一步扩容;
get 方法
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}get 方法的流程如下:
- 对 key 进行 hash 取值,然后判断在 table 中的 hash 值计算偏移量后的位置是否有值;
- 有值则首先判断当前偏移处的 hash 值是否与传入的 key 的 hash 值相同;
- 相同则判断当前 key 是否就是传入的 key,如果是则直接取值返回;
- 否则判断当前的偏移处的 hash 值是否小于 0,如果 eh < 0,代表是红黑树,按照红黑树的方式 find 返回;
- 如果大于0,则通过链表的方式循环当前偏移处的 Node 对象,直到获取到有相同的 key 值或者链表结束为止;
- 获取到值则直接返回,否则返回 null 表示不存在;
参考博客如下:
2w+长文带你剖析ConcurrentHashMap~!_慕课手记
Java并发编程笔记之ConcurrentHashMap原理探究 - 国见比吕 - 博客园
ConcurrentHashMap在jdk1.7和1.8中put和get源码的实现原理_XinhuaShuDiao的博客-CSDN博客
以上是关于ConcurrentHashMap 实现原理的主要内容,如果未能解决你的问题,请参考以下文章