C# 网络爬虫 抓取“北京标准时间“ 网页请求
Posted 小马哥棺材板
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C# 网络爬虫 抓取“北京标准时间“ 网页请求相关的知识,希望对你有一定的参考价值。
很多时候需要使用到北京时间,例如一些签到功能 过了24小时就可以签到一次 如果直接获取用户本地时间 因为本机时间是可以自行修改的 这就造成非常大的BUG 当然也可以使用服务器本机的时间 看个人需求
效果图:
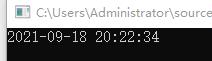
在C#中已经封装好了两个类
简单介绍下
HttpWebRequest -主要用于模拟客户端发送网络请求
HttpWebResponse -用来接收服务器返回的数据

演示网站:北京时间
请求多了也并不会限制访问
分析网页源代码:

上图看出 时间在中上部
name=“description” content="天气网时差频道(time.tianqi.com)介绍中国北京时间,北京时间在线校准,北京现在时间:2021-09-18 -20:15:41。查世界各大城市时差,知最新时间,来天气网时差频道。
而在时间的两边有一个" : " 和一个 " 。 " 符号 且只有一个
时间刚刚好在中间 可以以这两个符号为终点
代码:
定义URL(也就是目标地址) :
string url = "http://time.tianqi.com/";
也可以直接在 HttpWebRequest 的括号参数填写都是字符串类型
发起请求:
HttpWebRequest a = (HttpWebRequest)WebRequest.Create(url);
响应请求:
HttpWebResponse b = (HttpWebResponse)a.GetResponse();
返回的网页源代码 需要一个“流”进行接收
返回流:
using (Stream s = b.GetResponseStream())
using (StreamReader r = new StreamReader(s, Encoding.UTF8))
StreamReaad-因流不能直接转成字符,所以需要SreamRead进行转换
第1个参数:流
第2个参数:字符编码 如出现乱码,看网页编码是否和你程序编码对应
using-因为文件流会消耗大量的资源 而文件流比较特殊 并不能被GC(垃圾回收) 给释放 必须手动关闭 也可以使用using 关键字进行自动释放
字符串分割:
因为只需要他的时间 返回的一大堆不需要的数据 使用就需要进行分割 把不要的字符全部过滤 可以使用 字符串的方法 或者 正则表达式 因为正则表达式不好定义 所以使用的字符串的方法
代码:
string str = r.ReadToEnd(); //读取文件流赋值给字符串
int n = str.IndexOf(':');//找 : 在的第几个字
str = str.Substring(n + 1);// 从那里分割 因为是0开始的使用所以+1 不然不完整
n = str.IndexOf('。'); // 。 在第几个字符
str = str.Substring(0, n); //0开始 一直到 n个 也就是 “。”
Console.WriteLine(str); //输出
完整代码:
string url = "http://time.tianqi.com/";
HttpWebRequest a = (HttpWebRequest)WebRequest.Create(url);
HttpWebResponse b = (HttpWebResponse)a.GetResponse();
using (Stream s = b.GetResponseStream()) {
using (StreamReader r = new StreamReader(s, Encoding.UTF8))
{
string str = r.ReadToEnd();
int n = str.IndexOf(':');
str = str.Substring(n + 1);
n = str.IndexOf('。');
str = str.Substring(0, n);
Console.WriteLine(str);
}
}
Console.Read();
还是挺简单的 只有简单的几行
效果图:
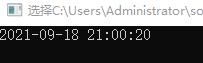
纯手打,点个赞呗~
以上是关于C# 网络爬虫 抓取“北京标准时间“ 网页请求的主要内容,如果未能解决你的问题,请参考以下文章