[图解]小白都能看懂的FASTER R-CNN – 原理和实现细节
Posted 浩瀚之水_csdn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[图解]小白都能看懂的FASTER R-CNN – 原理和实现细节相关的知识,希望对你有一定的参考价值。
Contents [hide]
论文原文
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
介绍
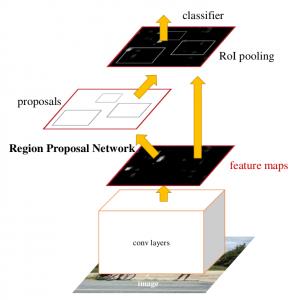
Faster RCNN由Ross B. Girshick在2016年提出,是RCNN系列的延续和经典版本。由于图像中的目标数量和位置并不确定,卷积神经网络本身是难以处理检测这样的问题的。
为了解决这个问题,Faster RCNN使用Anchor和分类器将原本的检测任务巧妙地转换成了卷积神经网络善于处理的分类和回归任务。数以万计事先指定好位置和大小的Anchor在图像上滑动,由一个RPN (Region Proposal Network) 来判断每个Anchor中是否有物体,这样就将不确定数量的目标检测问题变成了一个确定的几万个子区域的二分类问题。
RPN网络接收的输入是图像经过backbone(如resnet50)的特征图,根据事先指定好的Anchor,输出这些Anchor中有物体的概率,要注意RPN只能够区分有没有物体,而无法知道物体具体是什么类别的,这也是两阶段检测器的特性。

(上图为Anchor在图片中滑动)
由于Anchor的大小是事先指定的,可能并不完全与目标的位置重合,因此RPN还有另外一项重要的任务:给输出的检测框做回归,修正Anchor的位置。最终RPN的输出结果是这样的:(为了便于演示省略了很多概率为0的区域)

在论文中,RPN网络为CNN后面接一个3×3的卷积层,再接两个并列的(sibling)1×1的卷积层,其中一个是用来给softmax层进行分类(2分类,有物体还是没有物体),另一个用于给候选区域精确定位(框位置的偏移)。
Anchors
Anchors是一些预设大小的框,论文中Anchors的面积有三种 ANCHOR_AREAS = [128**2,256**2,512**2], 长宽比也有三种 ANCHOR_RATios = [0.5,1,2],所以一共有9种大小的Anchors,即k=9。Anchors的大小如下图所示:
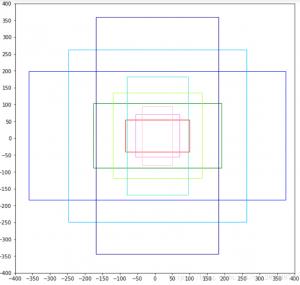
写成坐标的形式为:
| 1 2 3 4 5 6 7 8 9 10 | [[ -84. -40. 99. 55.] [-176. -88. 191. 103.] [-360. -184. 375. 199.] [ -56. -56. 71. 71.] [-120. -120. 135. 135.] [-248. -248. 263. 263.] [ -36. -80. 51. 95.] [ -80. -168. 95. 183.] [-168. -344. 183. 359.]] |
原文中Anchors的stride为16,也就是Anchor以步长16在原图中滑动。对于一张1000*600的图像,总共大约有20000个anchors(≈60×40×9),如果忽略越过图像边界的anchor,在训练时每张图像总共有约6000个anchor。
一张图片中有这么多的Anchor,一次全部训练是不太现实的,这相当于6000张小图像的二分类问题在一个batch中完成,(当然你要是有几百个G的显存可以忽略)。另外,这些Anchor的正负样本也是不均匀的,大部分的Anchor都是没有物体的背景,如果同时训练可能会造成偏差。
解决这两个问题的方法是每次只随机选取一部分Anchor进行训练,在原论文中,每次在所有的Anchor中随机选取256个,并让它们尽量保持正样本和负样本为1:1,这个参数可以看成是每张图片的batch_size,在程序中也一般命名为batch_size_per_image。
如何确定一个anchor是正样本还是负样本?
一个anchor如果满足以下两个条件之一的被认为是正样本:
(i) 这个anchor和ground truth的方框有着最大的IoU重叠。
(ii) 这个anchor和ground truth的方框有超过0.7的IoU重叠。

一个anchor如果满足以下条件的被认为是负样本:
(i) 这个anchor和ground truth的方框的IoU重叠小于0.3。

既不是正样本也不是负样本的anchor在训练中不被使用。
实现细节
1.所有输入图像都被缩放成短边600像素(长边不超过1000像素)。
假设输入图像尺寸为354(宽)×480,会被缩放为600×814,(记为image_scale),然后按照[batch, height, width, channel]即[1, 814, 600, 3]的尺寸输入网络。
2.对于vgg16网络,输入图像会被映射成512维的特征图。
由vgg网络的代码(conv5层之前):
| 1 2 3 4 5 6 7 8
9 10 11 12
13 14 15 | net = slim.repeat(self._image, 2, slim.conv2d, 64, [3, 3], trainable=False, scope='conv1') net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool1')
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], trainable=False, scope='conv2') net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool2') net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], trainable=is_training, scope='conv3') net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool3') net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], trainable=is_training, scope='conv4') net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool4') net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], trainable=is_training, scope='conv5') |
image_scale经过了4个池化层(卷积层由于有padding不会改变feature maps长和宽),所以得到的feature maps的尺寸为image_scale的1/16,也就是[1, 51, 38, 512]。
3.Anchors的个数为51×38×9(已知k=9)。
因此rpn网络分类的输出尺寸为[1, 51, 38, 18],其中后一半[:, :, :, 9:]表示正样本的概率,前一半[:, :, :, :9]表示负样本的概率。
而矩形框偏移回归的输出尺寸为[1, 51, 38, 36],(36=9×4),每个proposed region的4个参数是输出的矩形框(roi)相对于anchor进行平移缩放的4个系数。
rpn网络最终输出的矩形框位置是anchor的位置和偏移位置计算出来的,具体计算方式见参考资料。
由于roi网络输出的方框很多(51×38×9≈17000个),原文中的做法是先clip_boxes,即去掉与边界交叉的方框(剩下5000个左右的anchor),然后使用非极大值抑制(NMS)来去掉重叠的方框,最终只保留2000或300个方框(取决于训练还是测试)。
非极大值抑制(NMS)的原理:

用普通话翻译一下非极大值抑制就是:不是局部的最大值的那些值都滚蛋
由于score越大越接近期待值,因此将与score最大的方框IoU>0.7的都去除。
4.ROI pooling的详细过程。
由于分类器的输入尺寸需要是统一的,但是RPN给出的检测框大小并不相同,因此需要ROI pooling的操作。
将rpn输出的300个大小不同的方框从feature maps上对应的位置裁剪(crop)下来,然后缩放(resize)成14×14大小,这时候所有的方框可以表示为尺寸为[300, 14, 14, 512]的张量,再使用一个2×2的max_pool,得到的roi_pooling的结果尺寸为[300, 7, 7, 512]。
5.测试的详细过程。
测试过程中,输入的图像经过预测模型会输出[300 21]的分值以及[300 84]的方框位置。(设置网络保留300个方框,需要预测的种类为20类(pascal voc),加上背景一类)。
然后设定一个得分的阈值(比如0.95),大于该阈值的方框会被保留。如下图所示:

最后再使用一次NMS,对于多个重合的方框只保留一个。结果如下图所示:

调试信息
| 1 2 3 4 5 6 7 8 9 | _image shape: (1, 814, 600, 3) feature_maps shape: [ 1 51 38 512] rpn_cls_score shape: [ 1 51 38 18] # 2k=18 rpn_bbox_pred shape: [ 1 51 38 36] # 4k=36 rois shape: [300 5] # [:,0]全是0 roi_pooling shape: [300 7 7 512] cls_prob shape: [300 21] bbox_pred shape: [300 84] |
参考资料
GitHub - endernewton/tf-faster-rcnn: Tensorflow Faster RCNN for Object Detection
https://web.cs.hacettepe.edu.tr/~aykut/classes/spring2016/bil722/slides/w05-FasterR-CNN.pdf
一文读懂Faster RCNN - 知乎
以上是关于[图解]小白都能看懂的FASTER R-CNN – 原理和实现细节的主要内容,如果未能解决你的问题,请参考以下文章