超详细案例讲解如何寻求产品的市场增长点?线性回归&数据可视化
Posted 报告,今天也有好好学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了超详细案例讲解如何寻求产品的市场增长点?线性回归&数据可视化相关的知识,希望对你有一定的参考价值。
如果你是一名数据分析师,要让你为你们公司的某类产品寻求市场增长点,你会怎么做呢?
下图是我用xmind整理的一个分析框架:
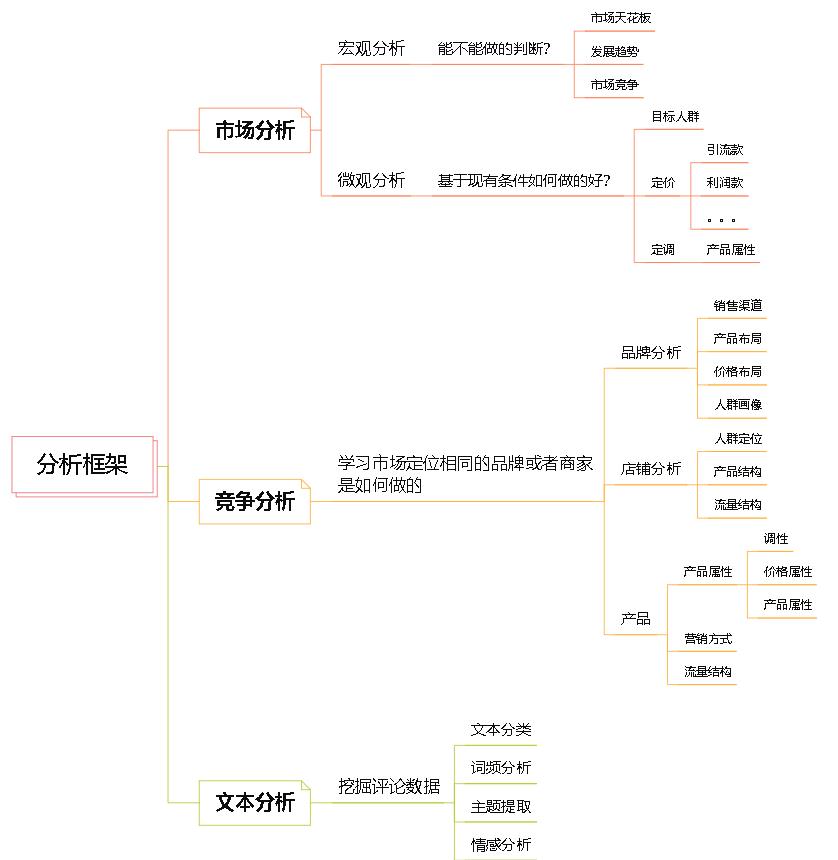
本次项目具体内容大家可以从1.1小节的项目背景开始进行了解,而前言这一部分是我这段时间在学习数据分析这一领域知识的过程中慢慢整理总结出来的,有任何错误还请大家不吝赐教。
目录
前言:数据分析思维与业务流程
前言这一部分是我这段时间在学习数据分析这一领域知识的过程中慢慢整理总结出来的,有任何错误还请大家不吝赐教。
分析流程概述
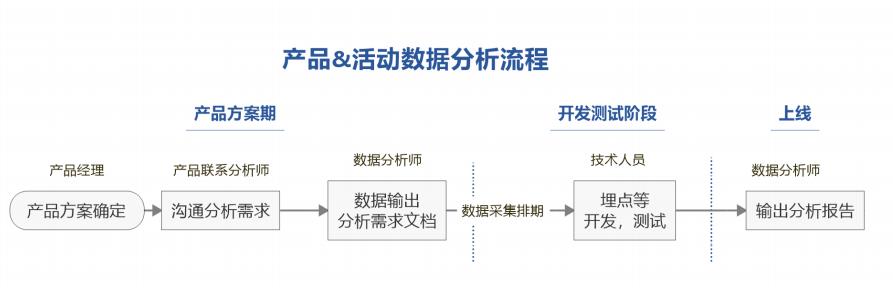
上图是一些电商平台的数据分析流程,大家可以看下。
其中这个数据采集排期的话中小公司用的比较多一点,而大公司是有自己的灰度发布系统的(已经埋好点了)。
另外,通过建模等分析后输出分析报告之后,也要再和产品经理反复沟通确定结论。
- 每个环节都有具体的要求,例如需求文档要求包含:目的、分析思路、预期效果。
- 业务部门出问题和需求,以及对算法&数据部门输出报告的理解和应用。
市场分类
评判市场和品牌的发展趋势和增长情况,从宏观到微观,从大市场到细分市场:
- 互联网产品由关注用户增量到用户存量,判断产品或市场是用户增量还是存量,只需要判断有新的需求出现即可:
○ 增量市场(又叫蓝海市场):从无到有,以前关注哪些需求没有被满足,快速迭代抢占市场,考虑最多的不是用户体验。
流量=新增客户。例如:智能手机潮开始时的市场,小米面对的是增量。
○ 存量市场(又叫红海市场):从有到优,现在关注如何更好的满足需求,考虑更多的是用户体验(如拼多多就是从红海市场杀出来的)。
产品价值=新体验-旧体验-替换成本,新体验没有突破性大幅增加,产品价值很难实现。
流量=用户时间(停留时间越久,利益价值越大)。
例如:现在人手一台智能手机,小米面对存量市场,如何让需要换手机的用户换成小米,从有到优。 - 创新:想要用产品价值撬动一个用户,同纬度竞争别家的先发优势门槛太高,如果别家体量很大,基本可以放弃。
创新可能就是剩下的活路,而面对互联网的高速发展,线下需求基本都被互联网化,切入点可能就转移到细分市场。
例如:微信QQ是社交领域的霸主,陌陌探探在陌生人社交上也分了一杯羹,这些已存在的需求,没有被充分实现,也算增量市场。
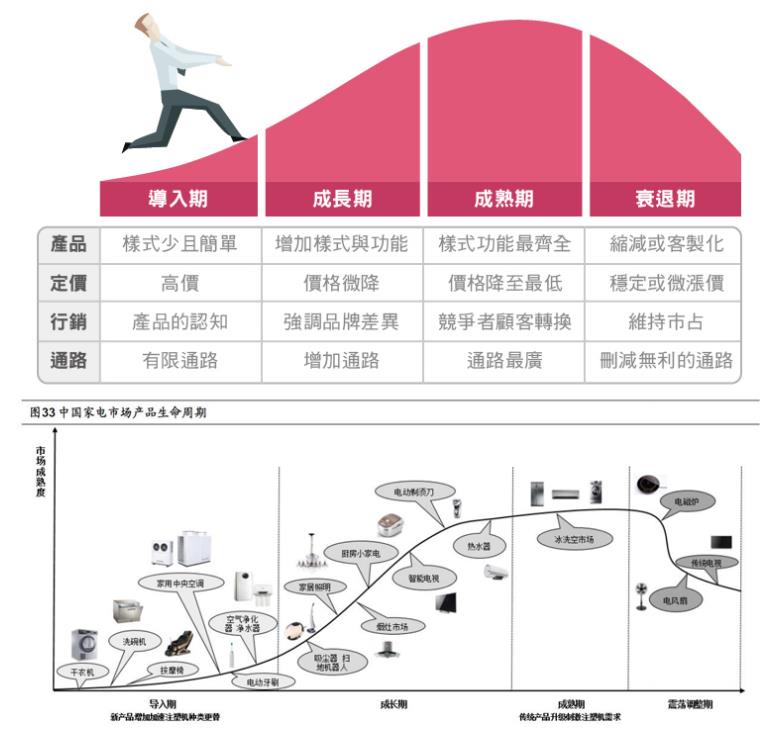
产品生命周期
● 客户生命周期
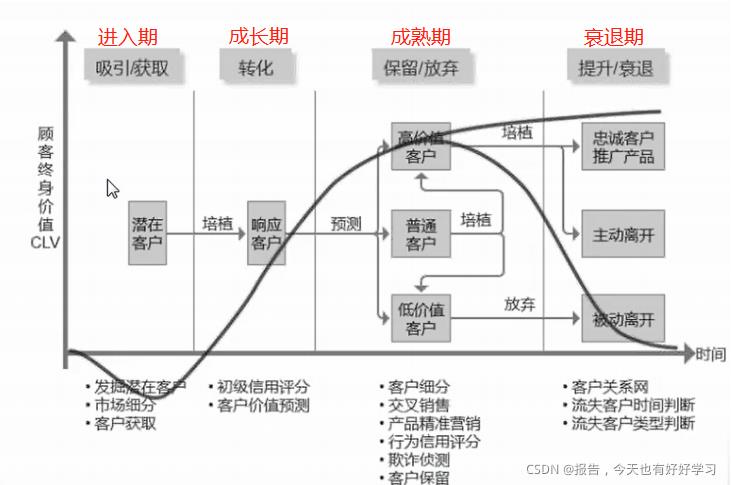
- 初级信用评分(京东的白条、支付宝的花呗)、客户价值预测可以用分类算法去实现(像大家常遇到的大数据杀熟这种情况,就是基于分类的结果——富人卖贵,穷人卖的便宜点,两头赚)
- 客户细分可以用聚类算法实现,交叉销售可以用关联规则,产品精准营销可以考虑用户画像(分类),行为信用评分也可以用分类方法实现,欺诈侦测(比方说防止你恶意薅羊毛)可以用异常值分析;
- 客户关系网、流失客户时间判断、流失客户类型判断这些也可以用分类算法实现(流失客户时间判断这里会涉及时间序列)
这里大家也可以发现,这里很多的业务都是可以用分类的算法来实现的。
产品结构-波士顿矩阵(BCG Matrix)
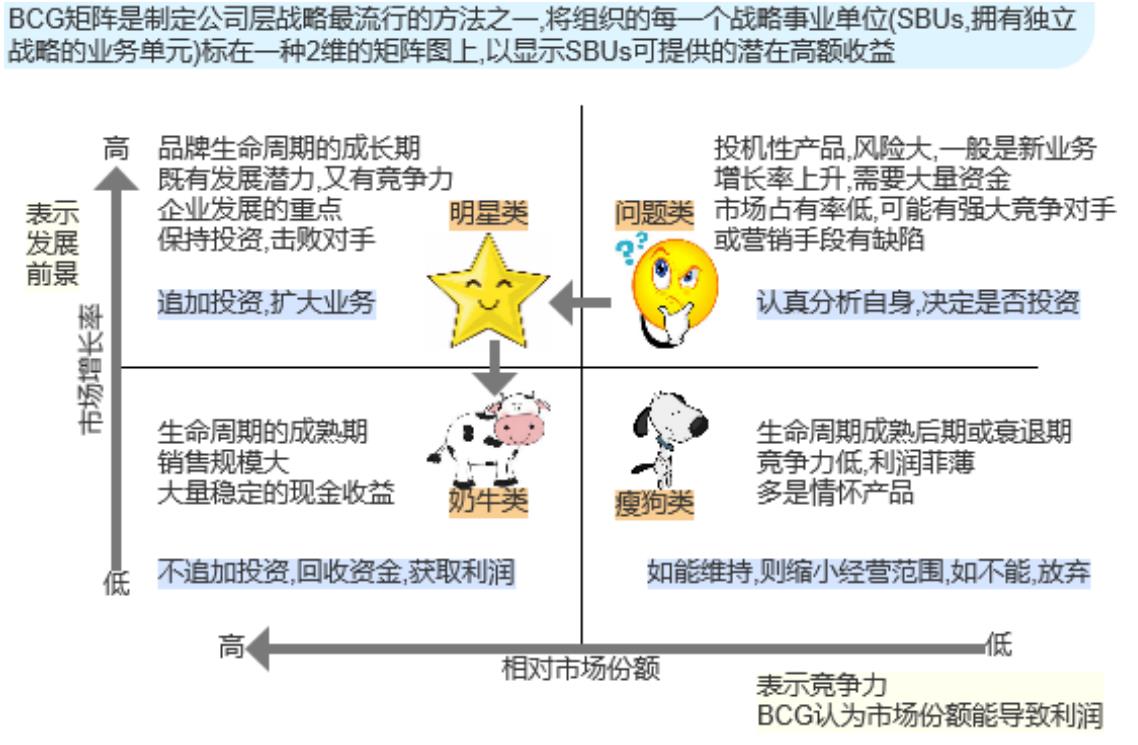
我们来看下上图的波士顿矩阵。
这里的相对市场份额我们可以理解为销售额。
我们可以把产品都分成四种类型:问题类(成长期)、明星类(成熟期)、奶牛类(稳定期)、瘦狗类(衰退期)。
我们拿到产品的数据后我们就可以判断产品是属于哪一类的,判断是不是有提升空间。
像腾讯旗下的手游王者荣耀就属于奶牛类产品,当它想要一些稳定的现金流的话,就可以出个活动,相当于挤挤奶,这就是奶牛类产品。
处理项目需求的基本思路
这里我们简单了解一下就可以了。
- 了解项目公司的背景和对接人员情况。
○ 公司的产品结构,市场环境,对接人的角色和权利等级等。 - 沟通明确实际的项目需求。
○ 团队内部理解项目需求。
○ 和业务方沟通需求:从业务的角度理解需求可能的解决方案。
○ 优化项目需求。
○ 和业务核对项目需求。 - 根据项目需求梳理分析思路:每一步分析的目标,需要的数据支持,反复优化。
- 确定分析工具和人员配置,进行数据分析。
- 撰写分析结论和方案
项目需求例子
问题:销售额下降,怎么办?
这个问题其实很大,比方说电商类的产品方法有:优化老客户、扩大流量、提高转化率等等。这种问题也是需要我们一步步来拆分的。具体操作可以如下:
- 了解涉及项目相关的所有的业务部门的需求,逻辑,问题点
- 拆分:销售额=流量转化率客单价
- 待沟通部门:营销部门(活动),推广部门(流量),客服,售后,供应链
○ 营销:精准营销(找到高价值客户),客户行为分析(响应效果),组合营销(购物篮)
○ 推广:竞价排名,买广告位,点击付费(需要很强的经验)
○ 退款和评论分析:优化产品,优化服务质量 - 沟通之前出想法,沟通之后优化,确认项目需求。
- 数据收集:确认每一步需求的数据(可能用到爬虫)。
像上面提到的流量,还可以接着细分成站内流量和站外流量,而站内流量还可以分成全部流量和每个商品流量(详情页的访问),我们需要不断的拆分问题,直至不能拆分为止。
1 业务背景
那下面我们开始正式介绍我们此次项目的背景啦。
1.1 项目背景&产品架构
接着我介绍一下本次项目的背景与其产品架构。
- 客户介绍: 拜耳官方旗舰店(拜耳公司,总部位于德国的勒沃库森,在六大洲的200个地点建有750家生产厂;拥有120,000名员工及350家分支机构,几乎遍布世界各国。高分子医药保健,化工以及农业是公司的四大支柱产业.公司的产品种类超过10000种)。
- 客户需求:寻求市场增长点。
- 产品架构:
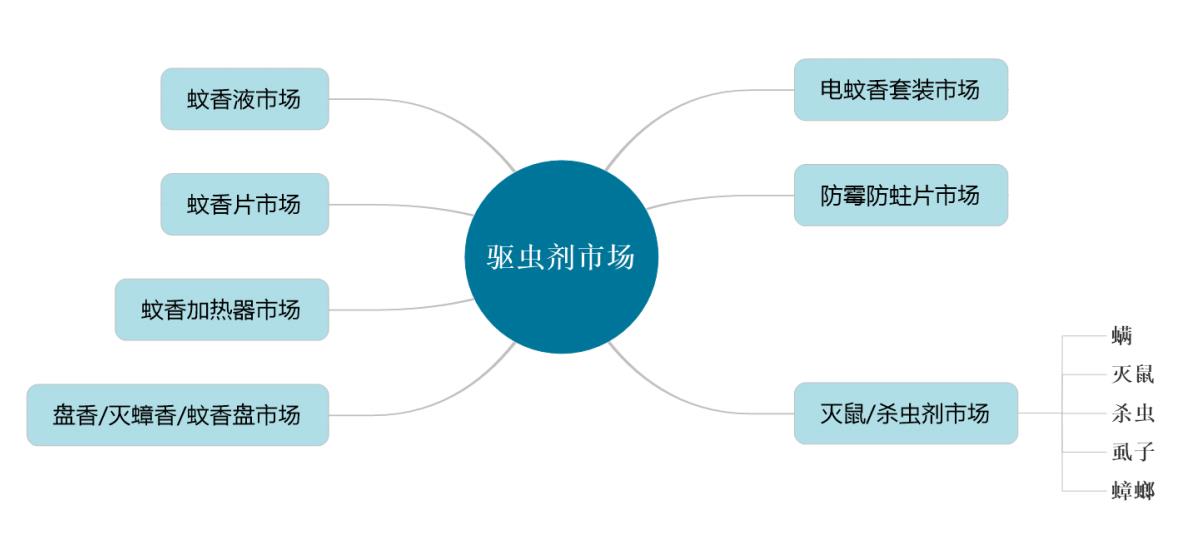
其实上图也有体现出拆分问题的思想,我们可以把中间这个看成一级市场,左右这7个市场看成二级市场,右下角的可以看出三级市场。
1.2 数据说明
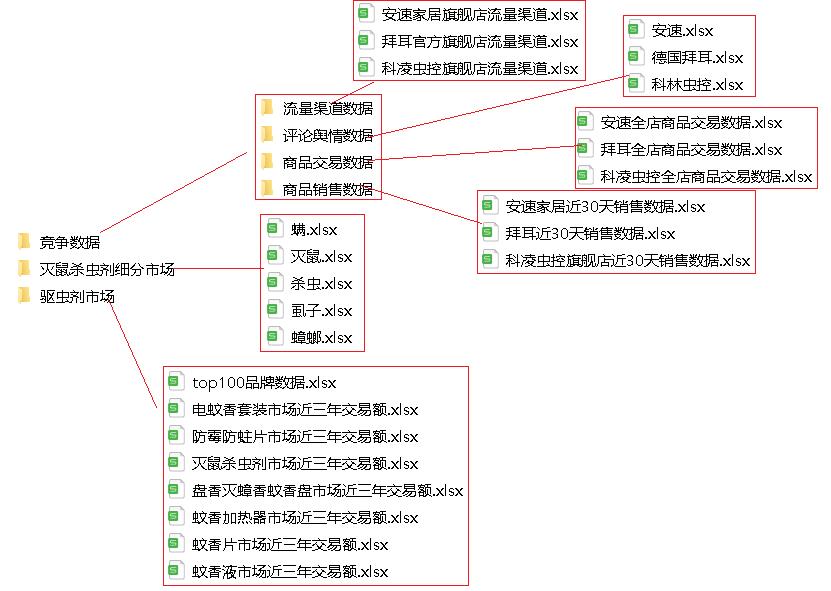
本次项目已有的数据十分齐全。
2 驱虫市场的潜力分析
老规矩,先导包,设置一下中文编码。
import glob #读文件
import os #设置工作路径
import pandas as pd
import re #正则表达式
import numpy as np
import datetime as dt #时间包
from sklearn.linear_model import LinearRegression
import seaborn as sns
from matplotlib import pyplot as plt
import jieba #分词
import jieba.analyse
import imageio #配合做词云的
from wordcloud import WordCloud #词云
# 中文编码
plt.rcParams['font.sans-serif']='simhei'
plt.rcParams['axes.unicode_minus']=False
sns.set_style("darkgrid",{"font.sans-serif":['simhei','Droid Sans Fallback']})
os.chdir('E:\\Data-analysis-project\\电商文本挖掘\\data/') # 工作路径
os.chdir('./驱虫剂市场')
2.1 分析目的&加载数据
2.1.1 分析目的
- 分析目的:针对各个子类目市场近三年的交易额数据,以及top100品牌数据(2017年11月到2018年10月),通过描述性分析,在年变化的维度上:
○ 分析整个市场的总体趋势
○ 分析各子类目市场占比及变化趋势
○ 分析市场集中度,即是否存在垄断 - 分析过程:
○ 读取各子类目市场近三年交易额数据
○ 依时间汇总成各子类目在时间线上的交易金额数据
2.1.2 加载数据
- 读取各子类交易额数据并合并
filenames = glob.glob('*市场近三年交易额.xlsx')
filenames
输出结果:
['灭鼠杀虫剂市场近三年交易额.xlsx',
'电蚊香套装市场近三年交易额.xlsx',
'盘香灭蟑香蚊香盘市场近三年交易额.xlsx',
'蚊香加热器市场近三年交易额.xlsx',
'蚊香液市场近三年交易额.xlsx',
'蚊香片市场近三年交易额.xlsx',
'防霉防蛀片市场近三年交易额.xlsx']
- 自定义函数读取单个xlsx文件:提取文件名,作为列名,修改时间格式
re.search(r'.*(?=市场)',"盘香灭蟑香蚊香盘市场近三年交易额.xlsx",).group() # 匹配市场之前的wenb
‘盘香灭蟑香蚊香盘’
def load_xlsx(filename):
#抽取子类目的名字
colname = re.search(r'.*(?=市场)',filename).group()
#读取文件
df = pd.read_excel(filename)
#修改日期的格式(原本是文本格式)
if df['时间'].dtypes == 'int64':
df['时间'] = pd.to_datetime(df['时间'],unit='D',origin=pd.Timestamp('1899-12-30')) # 系统默认的时间格式
#重命名列名为子类目名
df.rename(columns={df.columns[1]:colname},inplace=True)
#设置时间列作为索引
df = df.set_index('时间')
return df
dfs = [load_xlsx(i) for i in filenames]
df = pd.concat(dfs,axis=1).reset_index() # 拼接一下数据
df.head()
2.2 清洗&补全数据
- 由于其中的时间列是从2015年11月到2018年10月,而我们需要的是2016-2018年每月完整的数据(方便从年变化的角度分析产品)
- 这里我们假设:
○ 每年各月之间没有明显规律的周期性变化(近似认为月和月之间的相关性不大)
○ 每年对应月份的数据是线性变化的(一是因为数据少,二是认为随着年份的增长,交易额在大环境下是稳步变化的) - 故这里我们可以简单的用线性回归预测
即对于每个子类目市场,用15、16、17年的11/12月销售金额预测18年的对应月份
抽取月份方便建模索引:
month = df['时间'].dt.month
month
输出结果如下:
0 10
1 9
2 8
3 7
4 6
5 5
6 4
7 3
8 2
9 1
10 12
11 11
12 10
13 9
14 8
15 7
16 6
17 5
18 4
19 3
20 2
21 1
22 12
23 11
24 10
25 9
26 8
27 7
28 6
29 5
30 4
31 3
32 2
33 1
34 12
35 11
Name: 时间, dtype: int64
- 循环预测2018年11月和12月的销售额
for i in [11,12]:
# 抽取对月份的数据
dm = df[month == i] #2015.11 2016.11 2017.11
# 训练x是年份
xtrain = np.array(dm['时间'].dt.year).reshape(-1,1)
# 测试y是新增的行,对应的日期
ytest = [pd.datetime(2018,i,1)]
for j in range(1,len(dm.columns)):
# 训练y是指定的列
ytrain = np.array(dm.iloc[:,j]).reshape(-1,1)
# 回归建模
lm = LinearRegression().fit(xtrain,ytrain)
# 预测当测试x为2018时销售额 yhat
yhat = lm.predict(np.array([2018]).reshape(-1,1))
ytest.append(round(yhat[0][0],2))
#给预测结果赋值对应的列名
newrow = pd.DataFrame([dict(zip(df.columns,ytest))])
#预测结果行加在数据前,所以说用newrow来append,不是df来append
df = newrow.append(df)
df.head()
- 去掉原始索引
df.reset_index(drop=True,inplace=True)
# 上图中的索引是0 0 1 ,用drop=True去掉,而inplace=True的作用是不创建新的对象,直接对原始对象进行修改;
- 去掉15年的数据
df = df[df['时间'].dt.year != 2015]
df.tail()
接下来我们可以进行以下操作:
- 分析整个市场的总体趋势
- 分析各子类市场销售额占比及变化趋势
- 分析市场集中度,是否存在垄断
2.3 市场变化趋势描述
- 每行所有市场的交易金额总和生成新列
- 抽取年份生成新列
df['colsums'] = df.sum(1) #交易金额总和列
df.head()
df.insert(1,'year',df['时间'].dt.year) #年份列
df.head()
byyear = df.groupby('year').sum().reset_index()
byyear

sns.relplot('year','colsums',kind='line',marker='o',data=byyear,height=4)
plt.title('近三年的市场趋势')
plt.xticks(byyear.year,rotation=45) # rotation是旋转角度
plt.xlabel('年份')
plt.ylabel('总交易额')
plt.show()
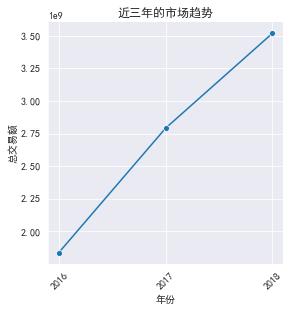
可以看出:近三年呈增长趋势,整个市场倾向于成长期和成熟期。
2.4 各市场变化趋势
查看各类目市场三年内销售额总和的变化趋势:
# 图形大小
f,ax = plt.subplots(figsize=(10,6)) # f代表整个图像,ax代表坐标轴和画的图,保存图像时需要用到fig
#dashes=False 不区分线型
sns.lineplot(data=byyear.set_index('year').iloc[:,:-1],dashes=False,marker='^')
plt.title('近三年各类市场销售趋势')
plt.xticks(byyear.year,rotation=45)
#在指定位置加文本
for a,b in zip(byyear.year,byyear['灭鼠杀虫剂']):
plt.text(a,b,'%.3e'% b, ha='center',va='bottom',size=12)
plt.xlabel('年份')
plt.ylabel('总交易额')
plt.show()
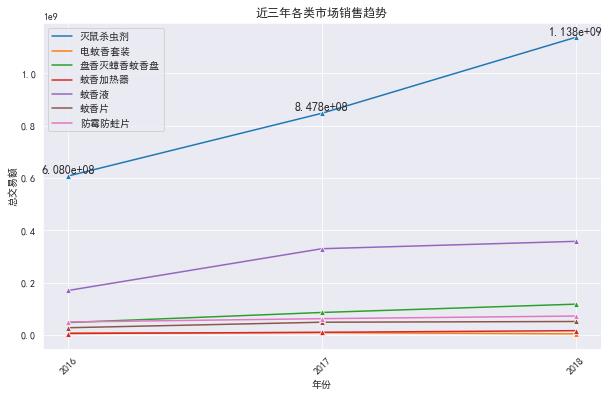
直观的看灭鼠杀虫剂和蚊香液都有较大的机会。
- 查看灭鼠杀虫剂近三年的增长趋势
g = sns.FacetGrid(byyear,height=5)
g.map(sns.barplot,'year','灭鼠杀虫剂',color='wheat')
g.map(sns.pointplot,'year','灭鼠杀虫剂')
for a,b in zip(range(len(byyear)),byyear['灭鼠杀虫剂']):
plt.text(a,b,'%.3e'% b, ha='center',va='bottom',size=12)
plt.xlabel('年份')
plt.ylabel('灭鼠杀虫剂近三年的增长趋势')
plt.xticks(rotation=45)
plt.show()
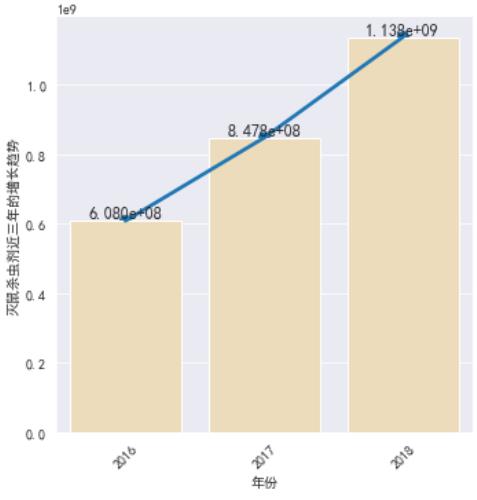
2.5 各市场占比
查看各类目市场三年内销售额总和的占比:
#计算每年每个子市场的比例
byyear_per = byyear.iloc[:,1:-1].div(byyear.colsums,axis=0)
byyear_per.index = byyear.year
byyear_per
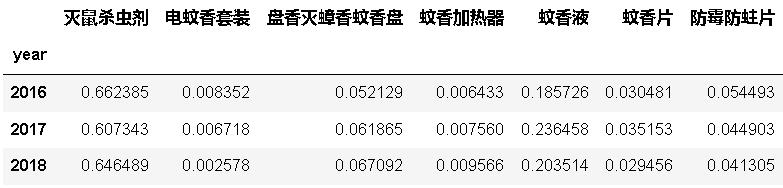
#stacked=True
byyear_per.plot(kind='bar',stacked=True,figsize=(10,8),colormap='tab10')
for a,b in zip(range(len(byyear_per)),byyear_per['灭鼠杀虫剂']):
plt.text(a,b/2,f'{b*100:.2f}%', ha='center',va='bottom',size=12,color='white')
plt.xlabel('年份')
plt.ylabel('总交易额占比')
plt.title('近三年各子类市场销量占比')
plt.show()
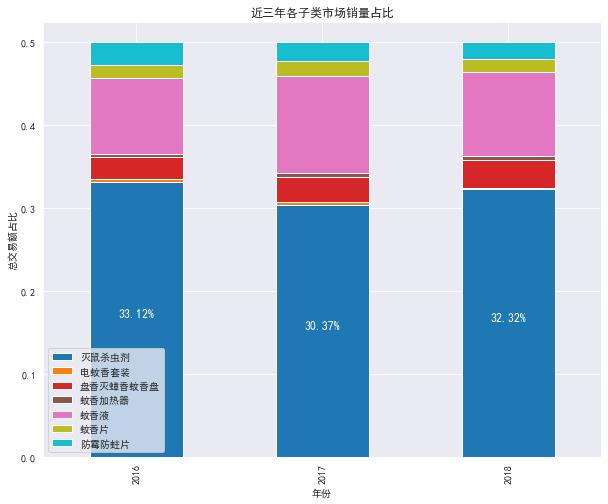
可见灭鼠杀虫剂和蚊香液可进一步扩展,就需要与甲方业务人员进一步沟通。
这里我们假设沟通后我们重点关注的是灭鼠杀虫剂。
2.6 各市场年增幅
byyear

#拿到中间7列
byyear0 = byyear.iloc[:,1:-1]
byyear0.diff()#一阶差分 17-16 18-17

#计算年增幅
byyear0 = byyear.iloc[:,1:-1]
byyear_diff = byyear0.diff().iloc[1:,:].reset_index(drop=True)/byyear0.iloc[:2,:]
byyear_diff.index = ['16-17','17-18']
byyear_diff

#作图查看
f,ax = plt.subplots(figsize=(10,8))
sns.lineplot(data=byyear_diff,dashes=False)
plt.title('近三年各子类市场销量年增幅')
plt.xlabel('年份')
plt.ylabel('总交易额年增幅')
plt.show()
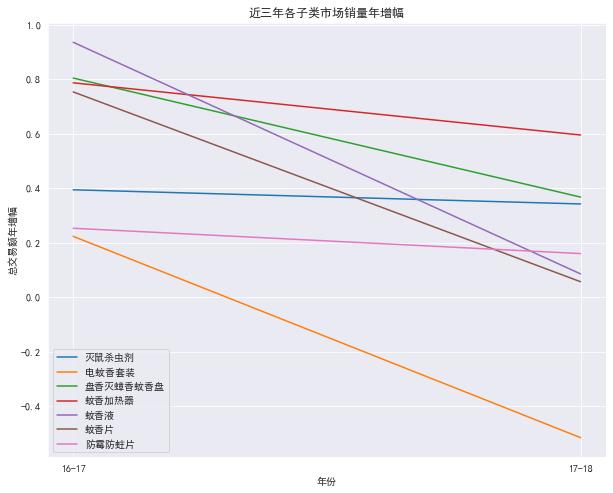
可见除了灭鼠杀虫剂和蚊香液增幅比较稳定,其它都有下降甚至变负。
2.7 市场集中度描述(垄断)
这里我们先介绍一下什么是垄断,以及常见的评估指标有哪些:
- 垄断程度,或者说市场势力的重要量化指标是行业集中度。
- 常见的指标有行业集中率:CRn指数,赫芬达尔指数(Herfindahl-Hirschman Index,缩写HHI)。
- 公式:
H
=
∑
i
=
1
N
s
i
2
)
i
H=\\sum^N_{i=1}s^2_i)i
H=∑i=1Nsi2)i(有些地方s前乘100或结果乘10000),N:公司数量; 第i个公司的市场份额。
例子:六家最大的公司市场上生产90%的商品,剩余的10%由10个规模相等的生产者分配,六家公司中,最大的公司生产80%,其余各2%。 H H I = 0. 8 2 + 5 ∗ 0.0 2 2 + 10 ∗ 0.0 1 2 = 0.643 ( 64.2 HHI=0.8^2+5*0.02^2+10*0.01^2=0.643(64.2%) HHI=0.82+5∗0.022+