ZooKeeper监控数据采集方案——Telegraf Plugin
Posted 徐同学呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ZooKeeper监控数据采集方案——Telegraf Plugin相关的知识,希望对你有一定的参考价值。
首发CSDN:徐同学呀,原创不易,转载请注明源链接。我是徐同学,用心输出高质量文章,希望对你有所帮助。
文章目录
一、前言
1、五种官方监控方案
Zookeeper官方提供了五种监控数据采集方案:
- Prometheus,运行
Prometheus监控服务是获取和记录ZooKeeper指标的最简单方法。需要在zoo.cfg中设置参数metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider、metricsProvider.httpPort=7000(默认端口7000)。Prometheus启动后每10秒记录一次ZooKeeper数据。 - Grafana,
Grafana有内置的Prometheus支持,只需添加一个Prometheus数据源。如果Grafana作为图表展示终端,安装Prometheus收集Zookeeper监控数据比较合适。 - Apache Zookeeper Telegraf Plugin + InfluxDB,安装启动Telegraf Plugin插件,定时收集ZooKeeper监控数据,并导入InfluxDB中。
- JMX,使用JMX方式监控Zookeeper,需要对JMX有一定了解。
- Four letter words,运行四字命令获取Zookeeper运行数据,可以自己写收集脚本,定时对某些Zookeeper集群执行四字命令(如
mntr),将数据写入mysql或者InfluxDB。
2、选择Telegraf Plugin采集zk运行时数据
经过对比,最终选择Telegraf Plugin作为zk运行时数据采集方案,选择理由:
- 生产环境用的influxdb存储数据,
Telegraf Plugin完美契合。 Telegraf是Go写的脚本,这意味着它是一个编译的独立二进制文件,可以在任何系统上运行,无需其他依赖,占用内存小,性能高。Telegraf是插件驱动的数据收集和输出,易扩展。Telegraf采集zk指标的原理是定时执行四字命令mntr,默认频率是10s一次。Telegraf上手简单,只需要配置输入源zk,输出源influxdb即可。
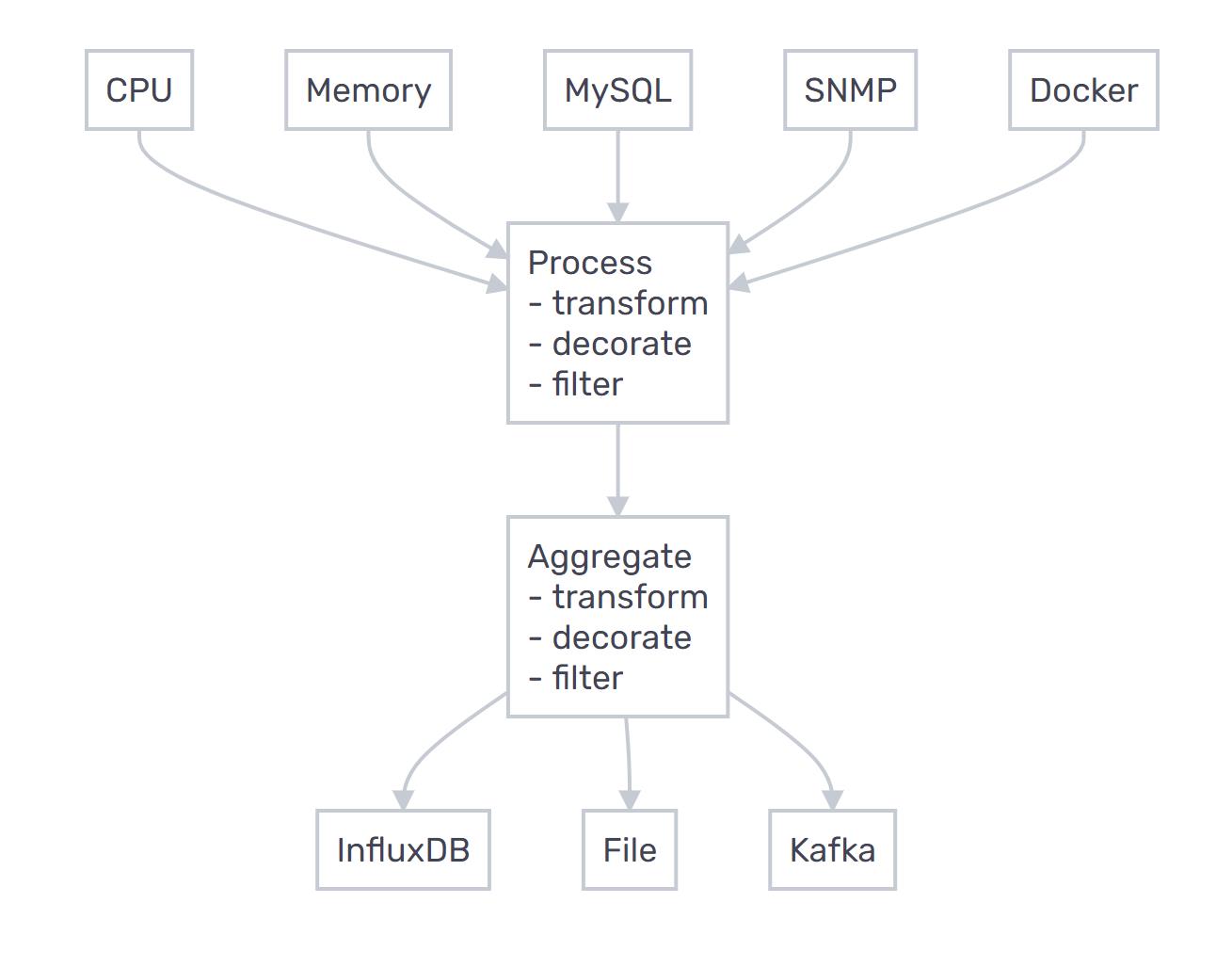
Telegraf 的缺点:
- 上手容易,过滤、聚合配置较复杂,有一定学习成本。
- 默认收集
mntr,暂未找到可以配置四字命令的地方。 - 入到
influxdb的表名默认是zookeeper,暂未找到可以自定义表名的地方。 - 暂未找到配置过滤指标的地方,比如某些指标不想入库。
如果不想用Telegraf,也可以自行根据mntr等四字命令开发定时脚本,技术掌握和灵活性大。

二、四字命令
1、mntr
mntr可以输出zk集群健康状态数据,如果想获取zk节点的配置信息,用conf。
[xxx@stefan~]$ echo mntr | nc 127.0.0.1 2181
zk_version 3.4.6-1569965, built on 02/20/2014 09:09 GMT
zk_avg_latency 0
zk_max_latency 1078
zk_min_latency 0
zk_packets_received 3956911
zk_packets_sent 3957032
zk_num_alive_connections 20
zk_outstanding_requests 0
zk_server_state follower
zk_znode_count 4220
zk_watch_count 32
zk_ephemerals_count 42
zk_approximate_data_size 16452676
zk_open_file_descriptor_count 47
zk_max_file_descriptor_count 409600
[xxx@stefan ~]$ echo mntr | nc 127.0.0.1 2181
zk_version 3.4.6-1569965, built on 02/20/2014 09:09 GMT
# 平均延迟
zk_avg_latency 0
# 最大延迟
zk_max_latency 549
# 最小延迟
zk_min_latency 0
# 收包
zk_packets_received 3683733
# 发包
zk_packets_sent 3684169
# 连接数
zk_num_alive_connections 24
# 堆积请求数
zk_outstanding_requests 0
# 状态(角色)
zk_server_state leader
# znode数量
zk_znode_count 4220
# watch数量
zk_watch_count 2790
# 临时节点数量
zk_ephemerals_count 42
# 数据大小
zk_approximate_data_size 16452676
# 打开的文件描述符数量
zk_open_file_descriptor_count 52
# 最大文件描述符数量
zk_max_file_descriptor_count 409600
# leader 会多出如下3个信息
# follower数量
zk_followers 2
# 已经同步的follower数量
zk_synced_followers 2
# 正在同步的数量
zk_pending_syncs 0
2、mntr监控告警说明
zk_server_statezk服务节点类型(leaderorfollower),集群中有且只能有一个leader,没有leader,则集群无法正常工作;两个或以上的leader,则视为脑裂,会导致数据不一致问题。需要对一个集群的leader数量做告警设置,超过1个则告警。zk_followers、zk_synced_followers,如果这两个值不相等,就表示部分 follower 异常了需要立即处理,需要对其做告警设置,二者差值不等于0则告警。zk_outstanding_requests,常态下该值应该持续为 0,不应该有未处理请求。需要对其做告警设置,一段时间(1分钟)内持续不等于0,则告警。zk_pending_syncs,常态下该值应该持续为 0,不应该有未同步的数据。需要对其做告警设置,一段时间(1分钟)内持续不等于0,则告警。zk_znode_count,节点数越多,集群的压力越大,性能会随之急剧下降,根据经验不要超过100万,当节点数过多时,需要考虑以机房/地域/业务等维度进行拆分。zk_approximate_data_size,当快照体积过大时,ZK 的节点重启后,会因为在initLimit的时间内无法同步完快照而无法加入集群。根据经验不要超过 1GB,建议不要把 ZK 当做文件存储系统来使用,可以对该值做告警设置,快照大小超过1GB就告警。zk_open_file_descriptor_count、zk_max_file_descriptor_count,当这两个值相等时,集群无法接收并处理新的请求,建议修改修改/etc/security/limits.conf,将线上账号的文件句柄数调整到 100 万。zk_watch_count,watch 的数量越多,zk变更后的通知压力就越大。zk_packets_received、zk_packert_sent,每个节点的具体值均不同,通过求和的方式来获取集群的整体值。zk_num_alive_connections,ZK 节点的客户端连接数量,每个节点的具体值均不同,通过求和的方式来获取集群的整体值。zk_avg_latency、zk_max_latency、zk_min_latency,需要关注平均延时的剧烈变化,业务上对延时有明确要求的,则可以针对具体阈值进行设置。
3、其他四字命令
conf(New in 3.3.0)输出相关服务配置的详细信息。比如端口、zk数据及日志配置路径、最大连接数,session 超时时间、serverId 等。cons(New in 3.3.0)列出所有连接到这台服务器的客户端连接/会话的详细信息。包括“接受/发送”的包数量、session id 、操作延迟、最后的操作执行等信息。crst(New in 3.3.0)重置当前这台服务器所有连接/会话的统计信息。dump列出未经处理的会话和临时节点(只在 leader 上有效)。envi输出关于服务器的环境详细信息(不同于 conf 命令),比如host.name、java.version、java.home、user.dir=/data/zookeeper-3.4.6/bin之类信息。ruok测试服务是否处于正确运行状态。如果正常返回"imok",否则返回空。srst重置服务器的统计信息。srvr(New in 3.3.0)输出服务器的详细信息。zk版本、接收/发送包数量、连接数、模式(leader/follower)、节点总数。stat输出服务器的详细信息:接收/发送包数量、连接数、模式(leader/follower)、节点总数、延迟。 所有客户端的列表。wchs(New in 3.3.0)列出服务器 watches 的简洁信息:连接总数、watching 节点总数和 watches 总数。wchc(New in 3.3.0)通过 session 分组,列出 watch 的所有节点,它的输出是一个与 watch 相关的会话的节点列表。如果 watches 数量很大的话,将会产生很大的开销,会影响性能,小心使用。wchp(New in 3.3.0)通过路径分组,列出所有的 watch 的 session id 信息。它输出一个与 session 相关的路径。如果 watches 数量很大的话,将会产生很大的开销,会影响性能,小心使用。mntr(New in 3.4.0)列出集群的健康状态。包括“接受/发送”的包数量、操作延迟、当前服务模式(leader/follower)、节点总数、watch总数、临时节点总数。
三、Telegraf Plugin安装(CentOS)
参考官方链接:https://www.influxdata.com/get-influxdb/
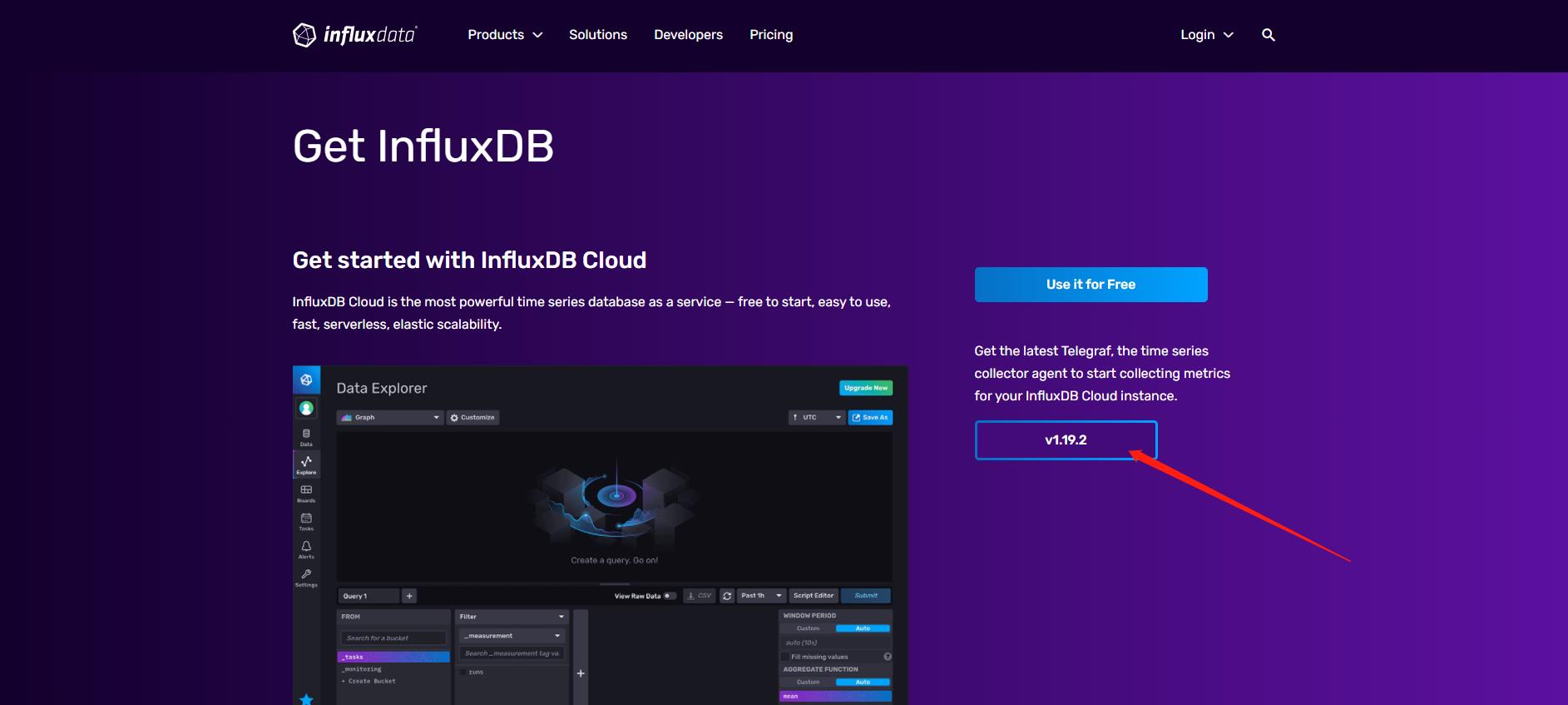

cd /usr/local
mkdir telegraf
cd telegraf
wget https://dl.influxdata.com/telegraf/releases/telegraf-1.19.2-1.x86_64.rpm
sudo yum localinstall telegraf-1.19.2-1.x86_64.rpm
执行如上命令即可安装成功,运行telegraf --version查看安装版本:
[root@Thu Sep 09 /usr/local]# telegraf --version
Telegraf 1.19.2 (git: HEAD 3cb135b6)

四、Telegraf Plugin启动与调试
1、调试
Telegraf一旦启动并运行,它将开始收集指标,并每10秒将数据写入本地的inflxdb。在启动之前可以用如下命令测试脚本是否正常:
# 运行下脚本,将收集的信息打印在控制台
telegraf --test
# 运行下脚本,将收集的cpu、mem信息打印在控制台(:分割)
telegraf --input-filter cpu:mem --test
# 只打印zookeeper收集信息
telegraf --input-filter zookeeper --test
2、启动与停止
sudo service telegraf start
sudo service telegraf stop
sudo service telegraf restart
如果直接输入telegraf,也是运行脚本,但不是后台运行,日志会同步打印在控制台,前期测试可以使用。
3、telegraf --help
Telegraf, The plugin-driven server agent for collecting and reporting metrics.
Usage:
telegraf [commands|flags]
The commands & flags are:
config print out full sample configuration to stdout
version print the version to stdout
# 筛选要启用的聚合器,分隔符为:
--aggregator-filter <filter> filter the aggregators to enable, separator is :
# 要加载的配置文件
--config <file> configuration file to load
--config-directory <directory> directory containing additional *.conf files
--watch-config Telegraf will restart on local config changes. Monitor changes
using either fs notifications or polling. Valid values: 'inotify' or 'poll'.
Monitoring is off by default.
--plugin-directory directory containing *.so files, this directory will be
searched recursively. Any Plugin found will be loaded
and namespaced.
# 打开调试日志
--debug turn on debug logging
--input-filter <filter> filter the inputs to enable, separator is :
--input-list print available input plugins.
--output-filter <filter> filter the outputs to enable, separator is :
--output-list print available output plugins.
--pidfile <file> file to write our pid to
--pprof-addr <address> pprof address to listen on, don't activate pprof if empty
--processor-filter <filter> filter the processors to enable, separator is :
--quiet run in quiet mode
--section-filter filter config sections to output, separator is :
Valid values are 'agent', 'global_tags', 'outputs',
'processors', 'aggregators' and 'inputs'
--sample-config print out full sample configuration
--once enable once mode: gather metrics once, write them, and exit
--test enable test mode: gather metrics once and print them
--test-wait wait up to this many seconds for service
inputs to complete in test or once mode
--usage <plugin> print usage for a plugin, ie, 'telegraf --usage mysql'
--version display the version and exit
五、telegraf.conf
Telegraf Plugin安装之后启动配置默认为/etc/telegraf/telegraf.conf,其中可以配置脚本的基本属性,如数据收集的时间间隔,输出源influxdb配置,输入源zookeeper配置等,如下仅截取关心的部分配置:
1、agent
[agent]
## Default data collection interval for all inputs
interval = "10s"
## Rounds collection interval to 'interval'
## ie, if interval="10s" then always collect on :00, :10, :20, etc.
round_interval = true
## Telegraf will send metrics to outputs in batches of at most
## metric_batch_size metrics.
## This controls the size of writes that Telegraf sends to output plugins.
metric_batch_size = 1000
## Maximum number of unwritten metrics per output. Increasing this value
## allows for longer periods of output downtime without dropping metrics at the
## cost of higher maximum memory usage.
metric_buffer_limit = 10000
## Collection jitter is used to jitter the collection by a random amount.
## Each plugin will sleep for a random time within jitter before collecting.
## This can be used to avoid many plugins querying things like sysfs at the
## same time, which can have a measurable effect on the system.
collection_jitter = "0s"
## Default flushing interval for all outputs. Maximum flush_interval will be
## flush_interval + flush_jitter
flush_interval = "10s"
## Jitter the flush interval by a random amount. This is primarily to avoid
## large write spikes for users running a large number of telegraf instances.
## ie, a jitter of 5s and interval 10s means flushes will happen every 10-15s
flush_jitter = "0s"
## By default or when set to "0s", precision will be set to the same
## timestamp order as the collection interval, with the maximum being 1s.
## ie, when interval = "10s", precision will be "1s"
## when interval = "250ms", precision will be "1ms"
## Precision will NOT be used for service inputs. It is up to each individual
## service input to set the timestamp at the appropriate precision.
## Valid time units are "ns", "us" (or "µs"), "ms", "s".
precision = ""
## Log at debug level.
# debug = false
## Log only error level messages.
# quiet = false
## Log target controls the destination for logs and can be one of "file",
## "stderr" or, on Windows, "eventlog". When set to "file", the output file
## is determined by the "logfile" setting.
# logtarget = "file"
## Name of the file to be logged to when using the "file" logtarget. If set to
## the empty string then logs are written to stderr.
# logfile = ""
## The logfile will be rotated after the time interval specified. When set
## to 0 no time based rotation is performed. Logs are rotated only when
## written to, if there is no log activity rotation may be delayed.
# logfile_rotation_interval = "0d"
## The logfile will be rotated when it becomes larger than the specified
## size. When set to 0 no size based rotation is performed.
# logfile_rotation_max_size = "0MB"
## Maximum number of rotated archives to keep, any older logs are deleted.
## If set to -1, no archives are removed.
# logfile_rotation_max_archives = 5
## Pick a timezone to use when logging or type 'local' for local time.
## Example: America/Chicago
# log_with_timezone = ""
## Override default hostname, if empty use os.Hostname()
hostname = ""
## If set to true, do no set the "host" tag in the telegraf agent.
omit_hostname = false
2、outputs.influxdb
# Configuration for sending metrics to InfluxDB
[[outputs.influxdb]]
## The full HTTP or UDP URL for your InfluxDB instance.
##
## Multiple URLs can be specified for a single cluster, only ONE of the
## urls will be written to each interval.
# urls = ["unix:///var/run/influxdb.sock"]
# urls = ["udp://127.0.0.1:8089"]
# urls = ["http://127.0.0.1:8086"]
## The target database for metrics; will be created as needed.
## For UDP url endpoint database needs to be configured on server side.
# database = "telegraf"
## The value of this tag will be used to determine the database. If this
## tag is not set the 'database' option is used as the default.
# database_tag = ""
## If true, the 'database_tag' will not be included in the written metric.
# exclude_database_tag = false
## If true, no CREATE DATABASE queries will be sent. Set to true when using
## Telegraf with a user without permissions to create databases or when the
## database already exists.
# skip_database_creation = false
## Name of existing retention policy to write to. Empty string writes to
## the default retention policy. Only takes effect when using HTTP.
# retention_policy = ""
## The value of this tag will be used to determine the retention policy. If this
## tag is not set the 'retention_policy' option is used as the default.
# retention_policy_tag = ""
## If true, the 'retention_policy_tag' will not be included in the written metric.
# exclude_retention_policy_tag = false
## Write consistency (clusters only), can be: "any", "one", "quorum", "all".
## Only takes effect when using HTTP.
# write_consistency = "any"
## Timeout for HTTP messages.
# timeout = "5s"
## HTTP Basic Auth
# username = "telegraf"
# password = "metricsmetricsmetricsmetrics"
## HTTP User-Agent
# user_agent = "telegraf"
## UDP payload size is the maximum packet size to send.
# udp_payload = "512B"
## Optional TLS Config for use on HTTP connections.
# tls_ca = "/etc/telegraf/ca.pem"
# tls_cert = "/etc/telegraf/cert.pem"
# tls_key = "/etc/telegraf/key.pem"
## Use TLS but skip chain & host verification
# insecure_skip_verify = false
## HTTP Proxy override, if unset values the standard proxy environment
## variables are consulted to determine which proxy, if any, should be used.
# http_proxy = "http://corporate.proxy:3128"
## Additional HTTP headers
# http_headers = {"X-Special-Header" = "Special-Value"}
## HTTP Content-Encoding for write request body, can be set to "gzip" to
## compress body or "identity" to apply no encoding.
# content_encoding = "gzip"
## When true, Telegraf will output unsigned integers as unsigned values,
## i.e.: "42u". You will need a version of InfluxDB supporting unsigned
## integer values. Enabling this option will result in field type errors if
## existing data has been written.
# influx_uint_support = false
3、inputs.zookeeper
# # Reads 'mntr' stats from one or many zookeeper servers
# [[inputs.zookeeper]]
# ## An array of address to gather stats about. Specify an ip or hostname
# ## with port. ie localhost:2181, 10.0.0.1:2181, etc.
#
# ## If no servers are specified, then localhost is used as the host.
# ## If no port is specified, 2181 is used
# servers = [":2181"]
#
# ## Timeout for metric collections from all servers. Minimum timeout is "1s".
# # timeout = "5s"
#
# ## Optional TLS Config
# # enable_tls = true
# # tls_ca = "/etc/telegraf/ca.pem"
# # tls_cert = "/etc/telegraf/cert.pem"
# # tls_key = "/etc/telegraf/key.pem"
# ## If false, skip chain & host verification
# # insecure_skip_verify = true
更多配置可参考:https://github.com/influxdata/telegraf

六、注意事项
1、四字命令不在白名单
[root@Thu Sep 09 ~]# echo mntr | nc 127.0.0.1 2192
mntr is not executed because it is not in the whitelist.
执行某些四字命令报了not in the whitelist.,需要在zk配置zoo.conf中加一行4lw.commands.whitelist=*,重启zk即可。
2、zk指标会因为zk版本而不同
mntr在zk3.7.0指标会很多。而且未在Telegraf的配置中看到可以过滤指标的方式(Tag Limit Processor Plugin是过滤tag key的)。默认measurement名称为zookeeper,未看到重命名的地方。
3、不要安装influxDB 2.0
influxDB 2.0太新了,和influxDB1.8有比较大的差别,influx命令变了,启动配置路径也变了,翻了半天文档也没找到默认配置路径在哪里。。。,所以还是暂时老老实实安装influxDB1.8,可参考influxdb基础(一)——influxdb安装与基本配置(centos)。
4、Telegraf好像只能收集mntr
未在Telegraf配置中找到配置zk四字命令的地方,默认是mntr。
5、Telegraf学习成本
Telegraf上手成本低,除了输入插件和输出插件外,Telegraf还包括聚合器和处理器插件,它们用于聚合和处理通过Telegraf收集的指标,想对数据做复杂操作,有一定学习成本。
七、其他监控
1、进程监控(JVM 监控),zk是一个运行的java进程,可以对其JVM做监控。
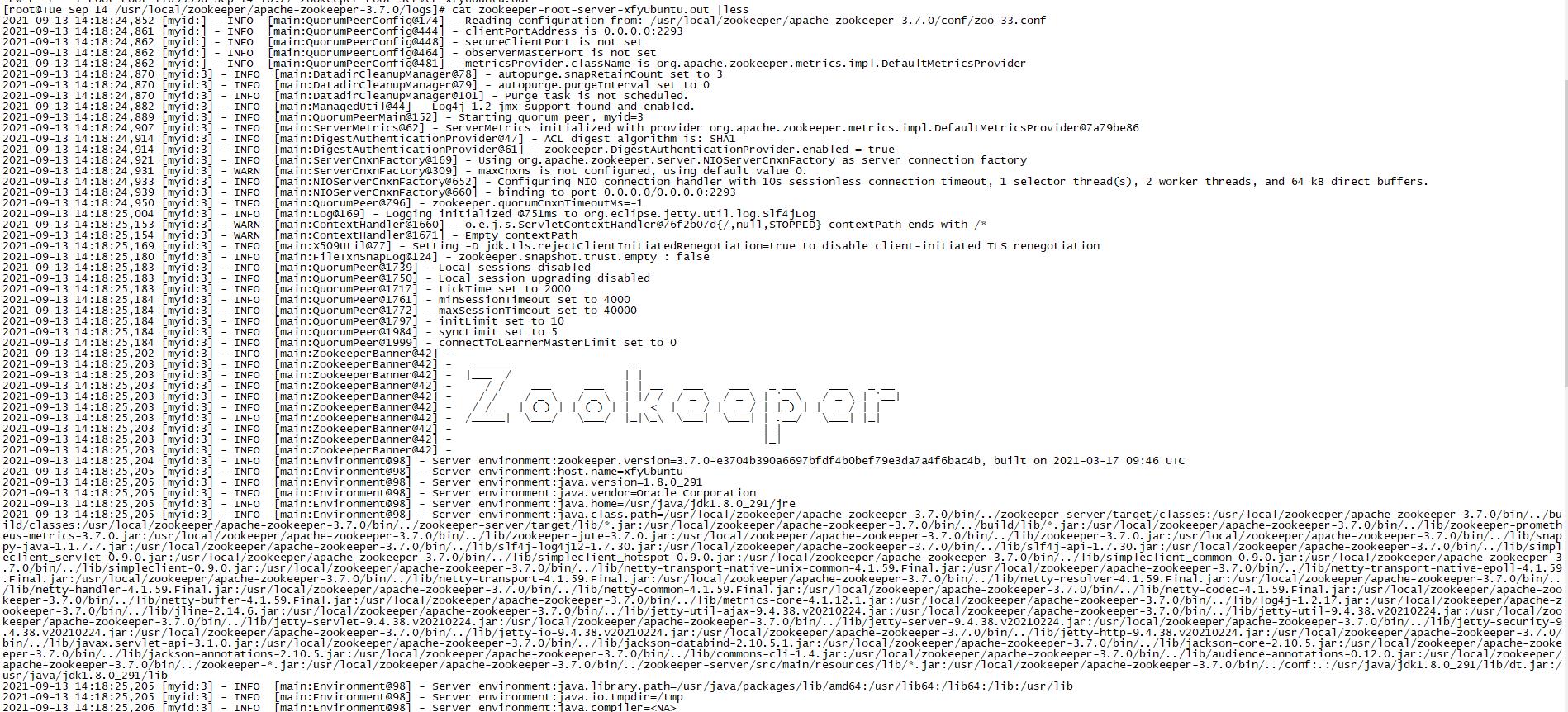
2、日志监控,zk出了问题,比如启动失败等,可以查看其运行日志 /usr/local/zookeeper/apache-zookeeper-3.7.0/logs/zookeeper-root-server-xfyUbuntu.out。
3、主机监控,需要对部署zk的机器做监控(Telegraf默认是开启机器监控的),CPU、负载、网络等。
八、参考文献
- https://zookeeper.apache.org/doc/current/zookeeperMonitor.html
- https://github.com/influxdata/telegraf
- https://rootnroll.com/d/telegraf/
- https://www.influxdata.com/integration/apache-zookeeper/
- https://docs.influxdata.com/telegraf/v1.19/
- https://www.infoq.cn/article/7yGNFUU*au8AhrzFkX3z
如若文章有错误理解,欢迎批评指正,同时非常期待你的留言和点赞。如果觉得有用,不妨来个一键三连,让更多人受益。
以上是关于ZooKeeper监控数据采集方案——Telegraf Plugin的主要内容,如果未能解决你的问题,请参考以下文章