Kibana:使用 Elastic Stack 来分析 COVID 数据
Posted 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kibana:使用 Elastic Stack 来分析 COVID 数据相关的知识,希望对你有一定的参考价值。
在我之前的文章:
我使用 Beats 来分析了 COVID 数据。在今天的练习中,我将使用一种不同的方法来分析 COVID 数据。在今天的练习中,我将使用欧洲的数据来进行分析。你可以访问网站 COVID-19 situation update for the EU/EEA, as of 15 September 2021 以获得 COVID 数据。在今天的练习中,我将下载网页 Data on the daily number of new reported COVID-19 cases and deaths by EU/EEA country 中的 CSV 数据。通过对这个数据的分析,我们可以熟练掌握 Kibana 中的 Lens 的使用以及 Maps 的使用。在本练习中,我将以 7.14 发布版的界面来做介绍。
安装
你首先需要安装 Elastic Stack 的如下软件栈:
Elasticsearch
我们首先按照文章 “如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch” 来安装 Elasticsearch。
Kibana
我们按照文章 “Kibana:如何在 Linux,MacOS 及 Windows上安装 Elastic 栈中的 Kibana” 来安装 Kibana。
摄入 COVID 数据
我们首先到地址下载 CSV 格式的 COVID 数据。它的格式如下:
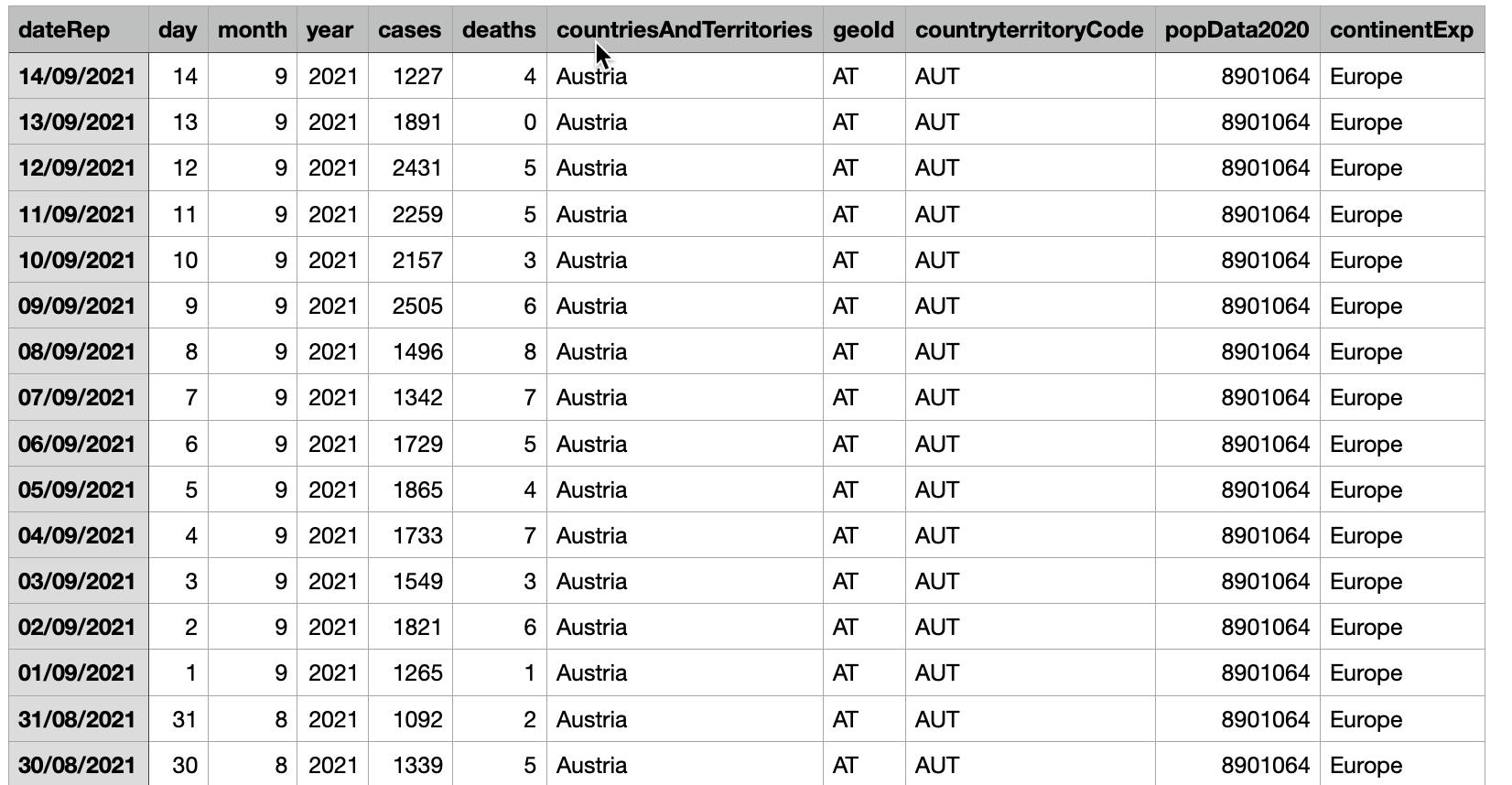
如上所示,它共有11个字段:
- dateRep:timestamp。它代表数据的时间。我们需要在导入数据时把这个字段转换为 @timestamp
- day: 每个月中的 天
- month:月
- year:年
- cases:多少个病例
- deaths:死亡的人数
- countriesAndTerritories:国家名称
- geoId:两个字母代表的国家名称
- countryTeriritoryCode:三个字母代码的国家名称
- popData2020:这个代表 2020 年该国家的人口数量
- continentExp:代表 7 大洲中的州
我们打开 Kibana:

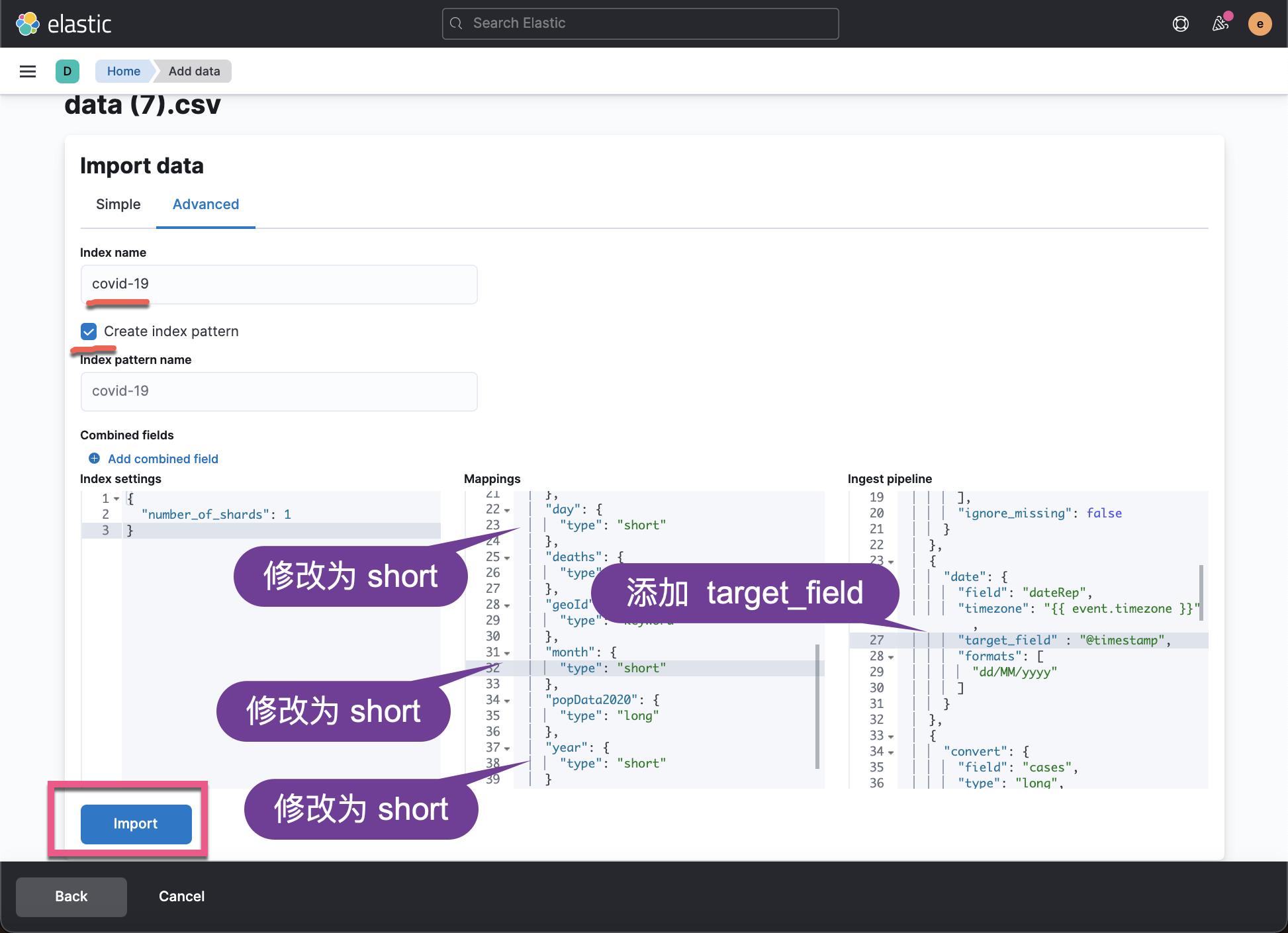
在上面,我们对 mapping 做少许的修改。我们把 year,month 及 day 修改为 short。这样做的目的是为了省存储空间,尽管在本练习中是不必要的。对于大量数据来说,这个还是非常必要的。同时我们修改了 Ingest pipeline 中的 date processor。我们想把 dateRep 这个字段最终变成为 @timestamp 字段,这个表明是时序数据。
点击上面的 Import 按钮:
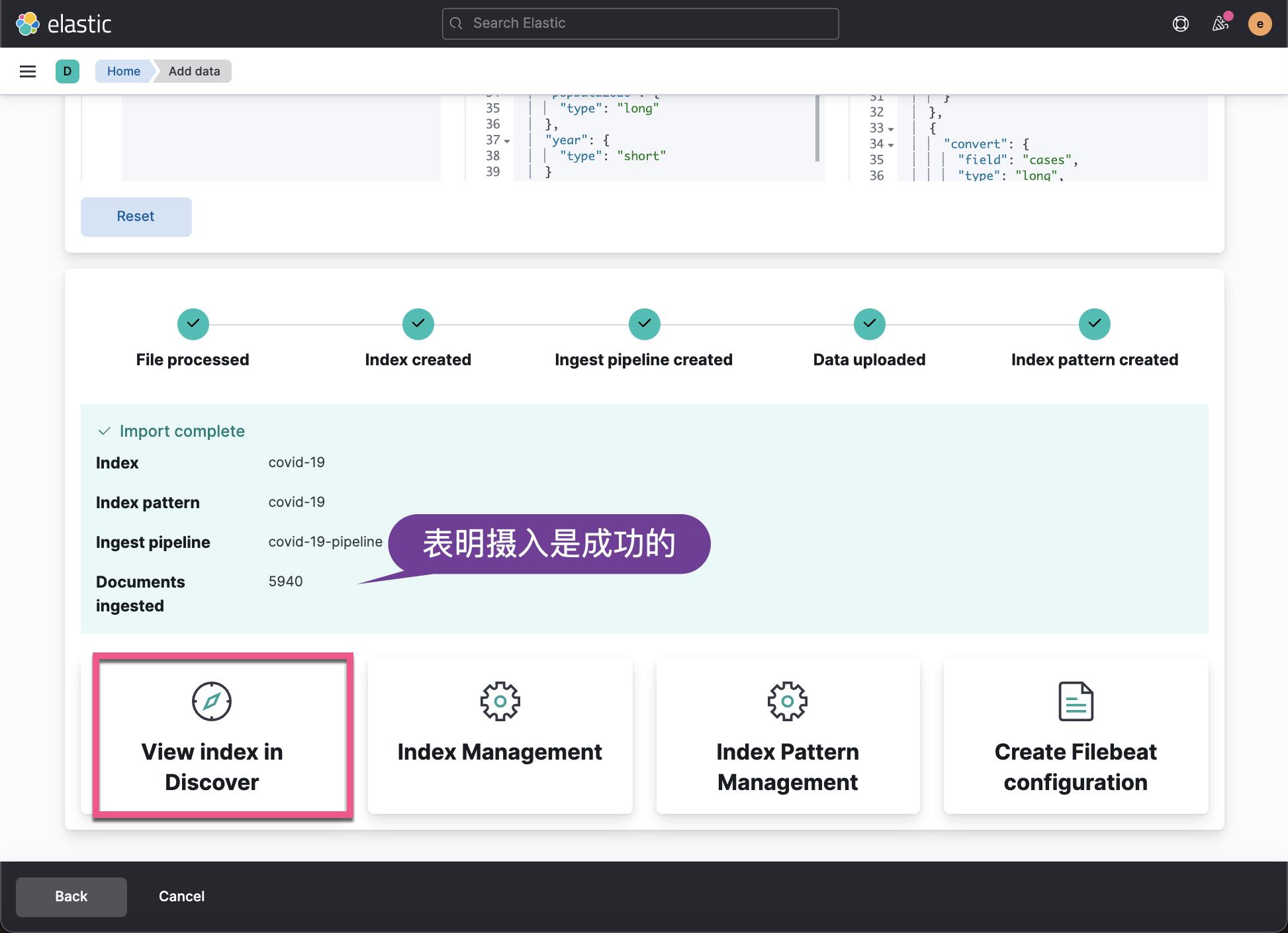
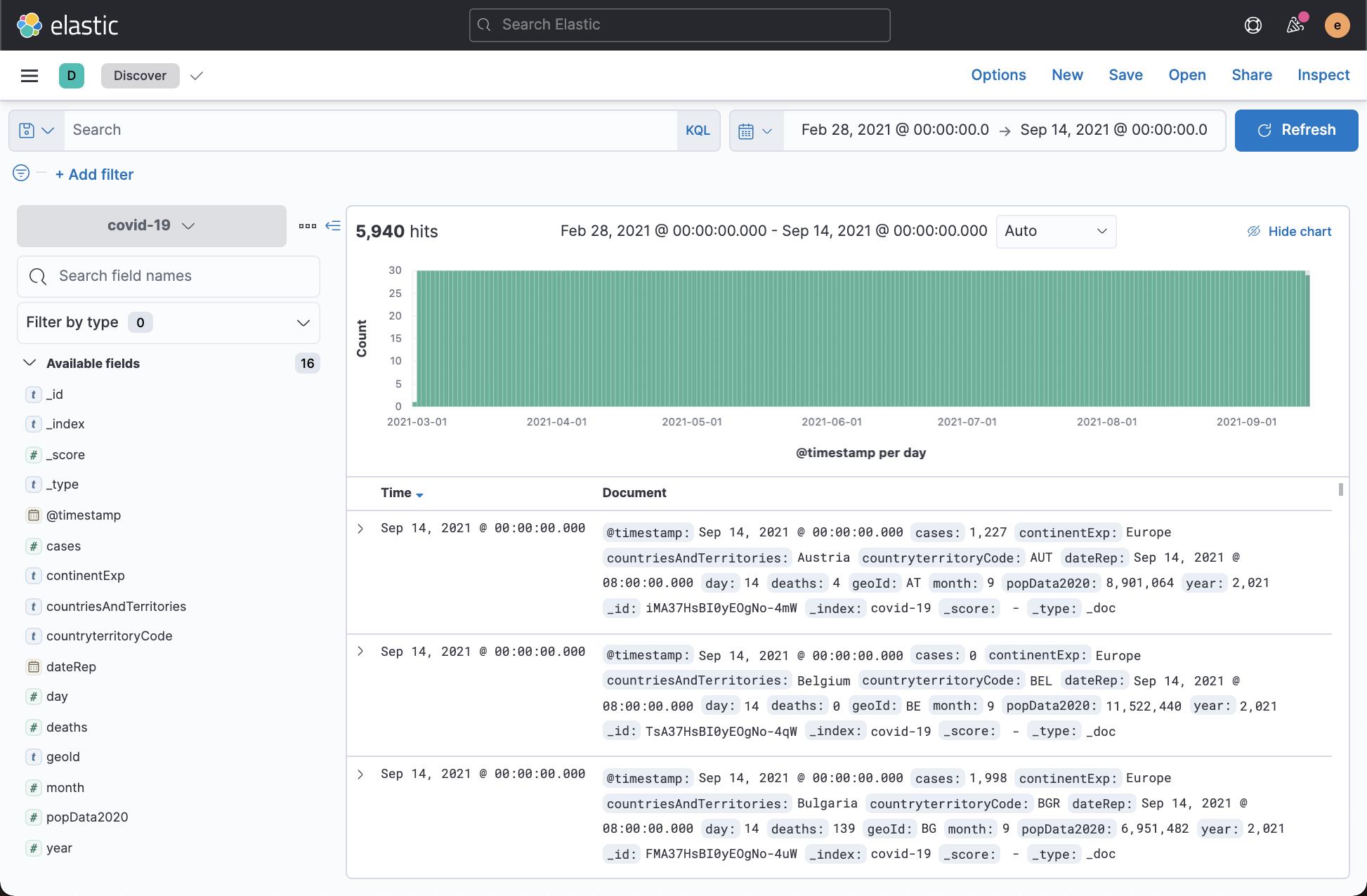
从上面我们可以看出来,我们的数据摄入是成功的。
可视化数据
接下来,我们来对摄入的数据进行可视化。首先,我们打开 Dashboard:

我们首先想通过地图的方式来显示哪个国家的案例是最多的。我们通过如下的方法来实现。选择 Maps:
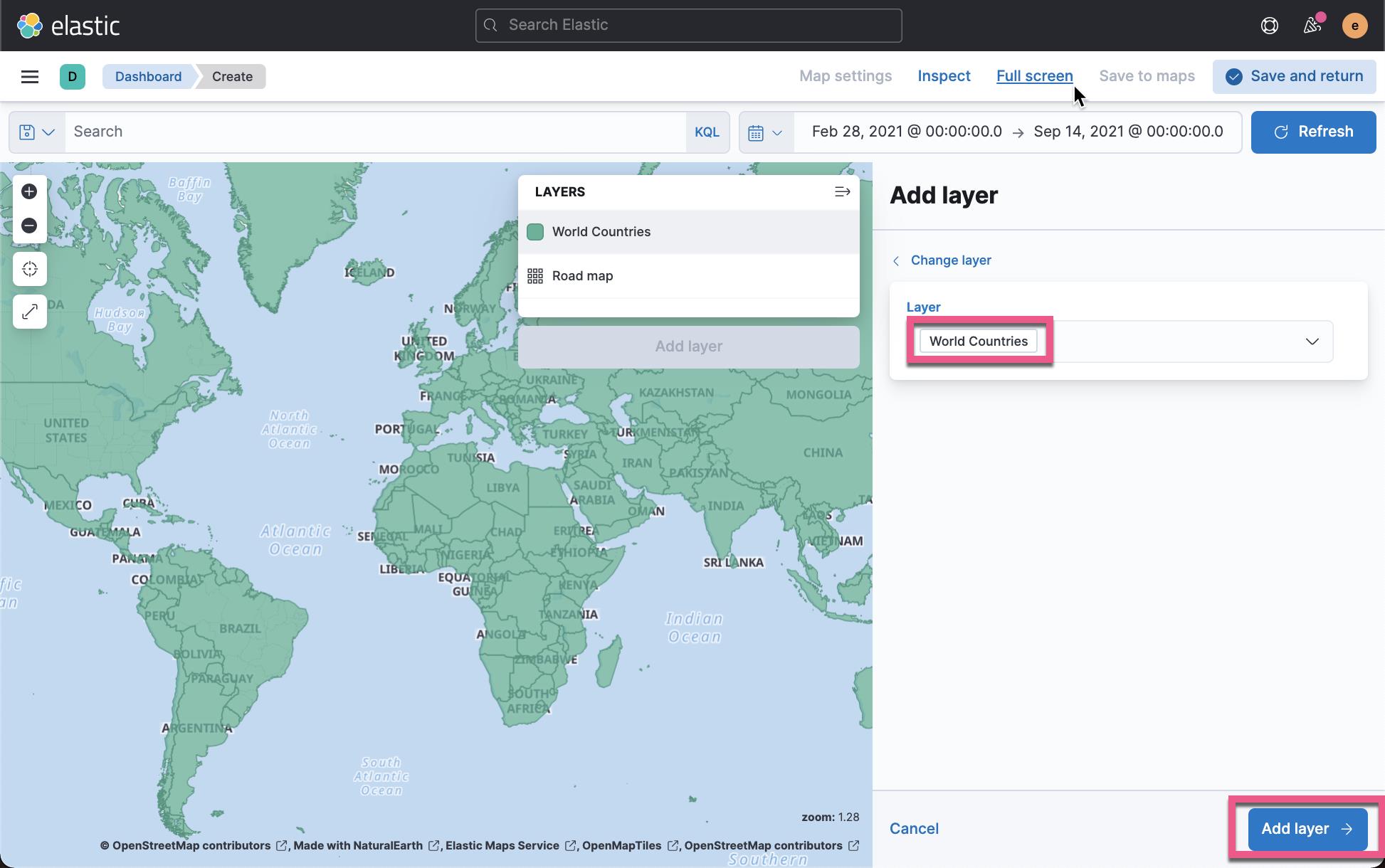
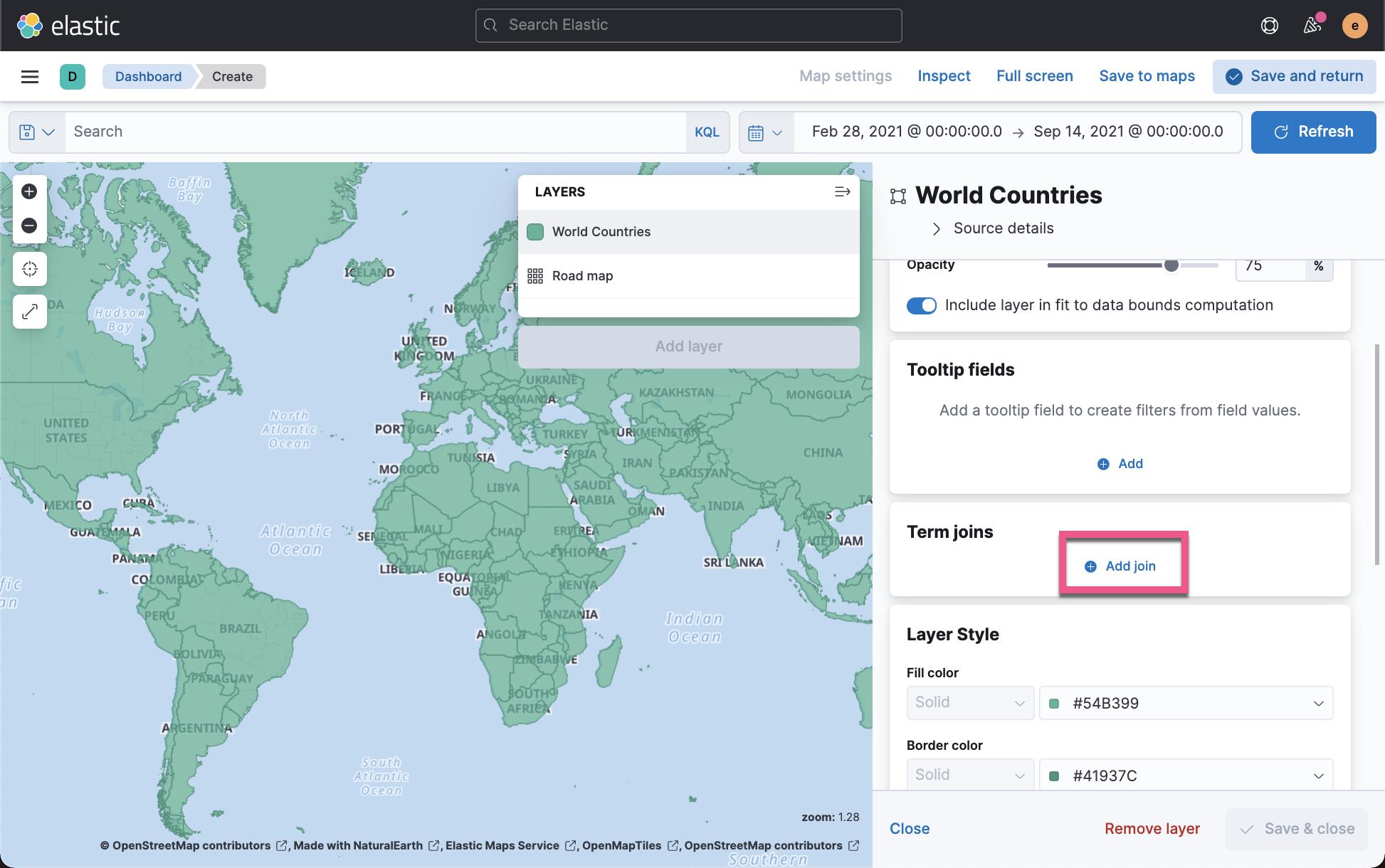
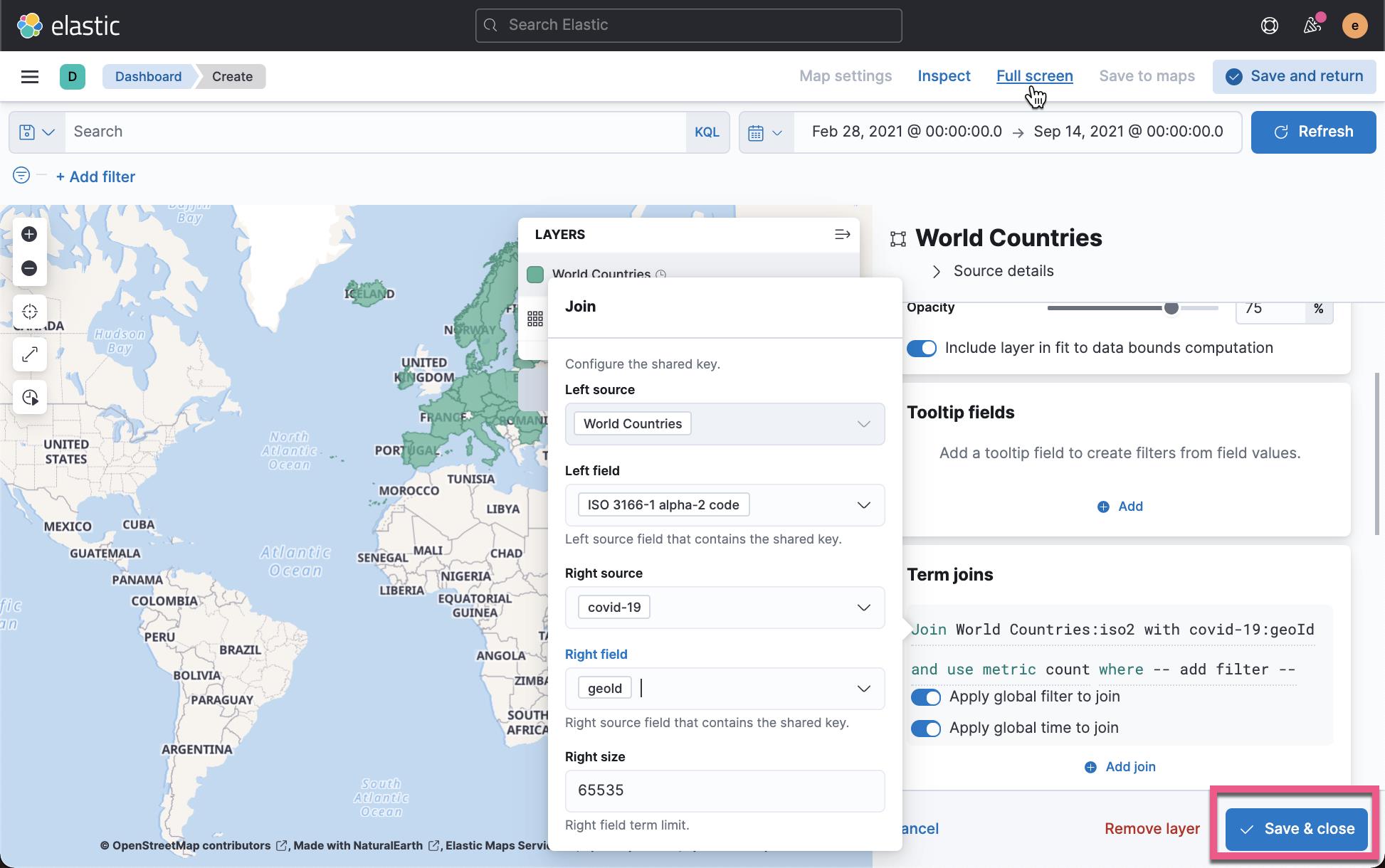
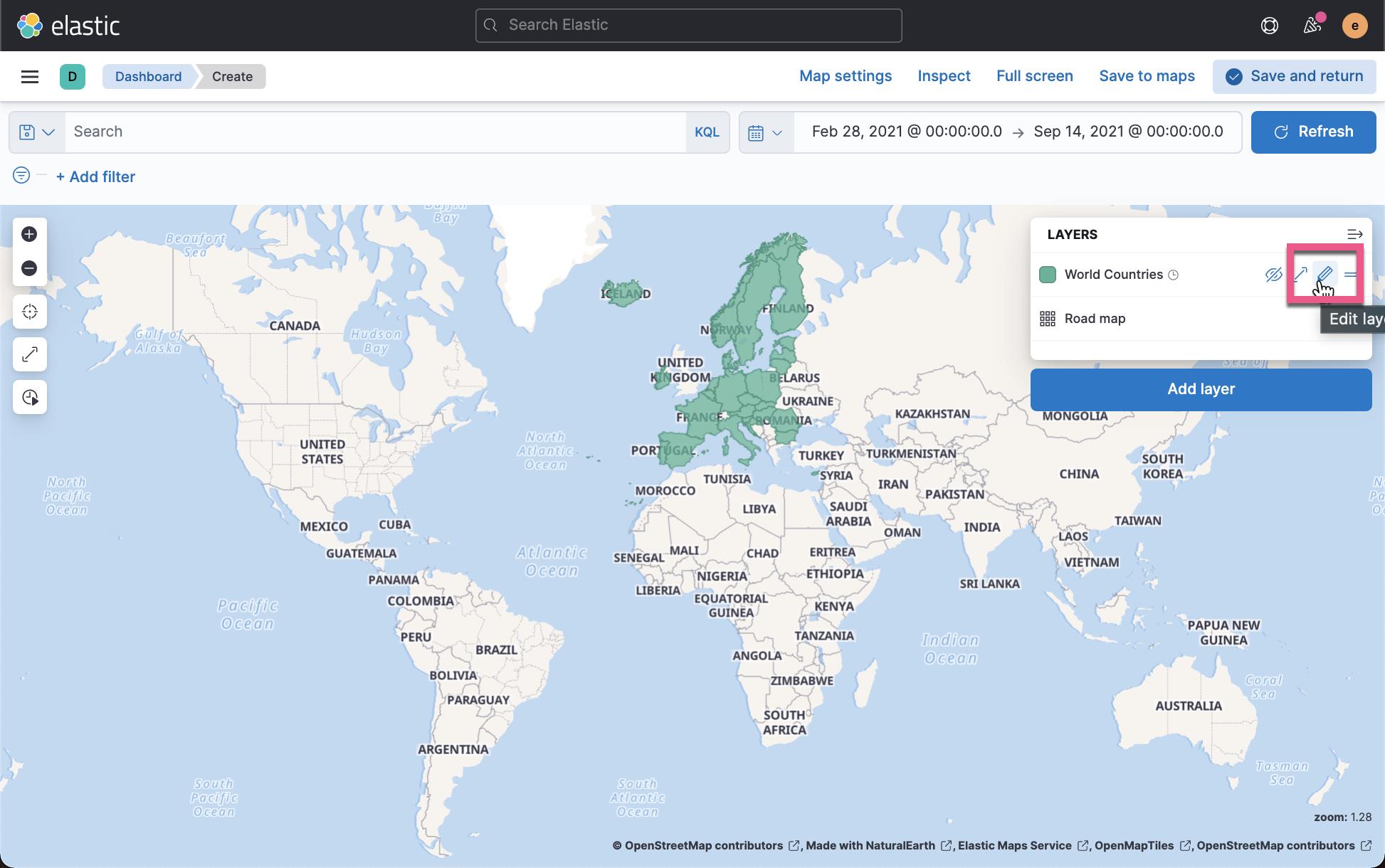
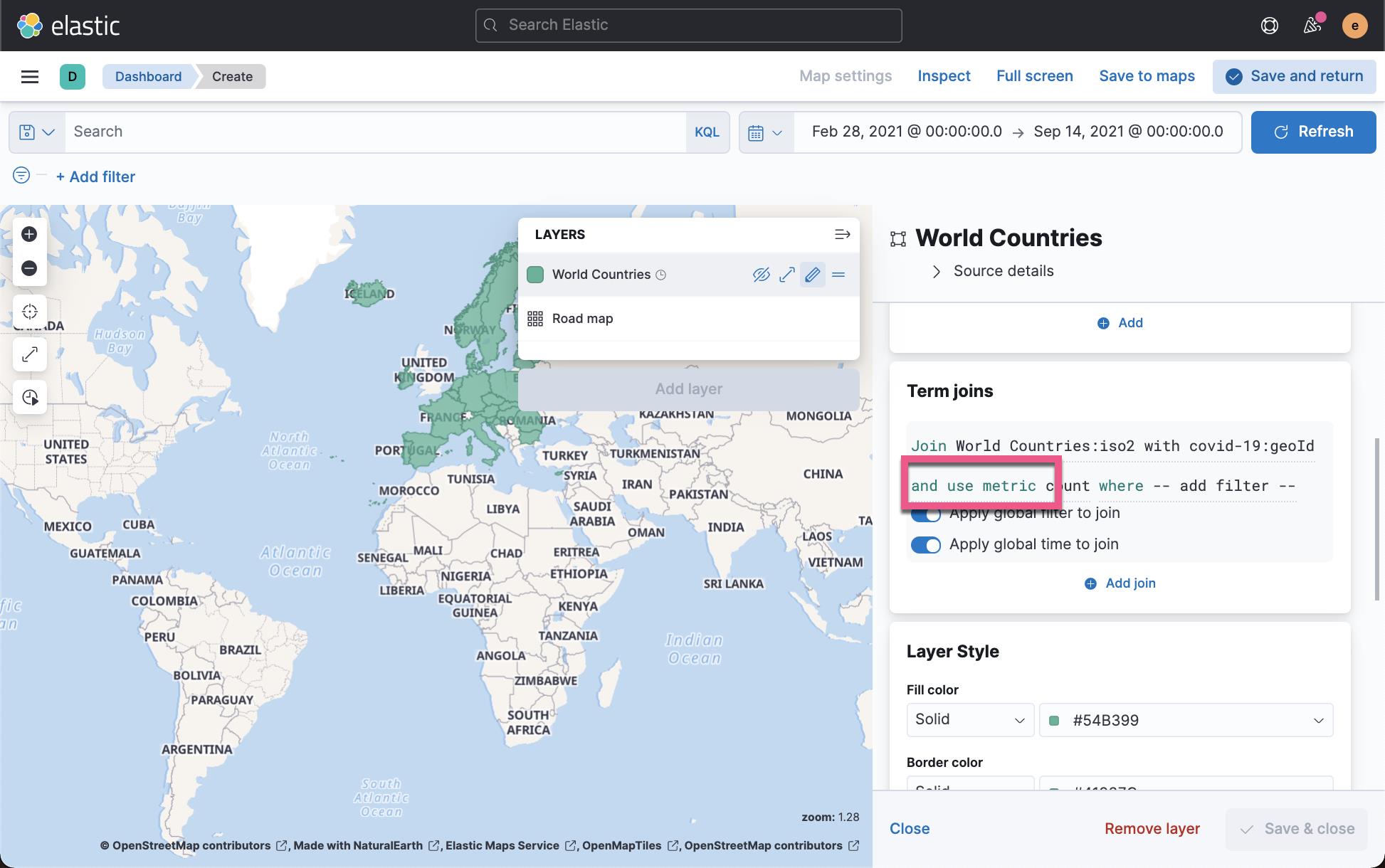
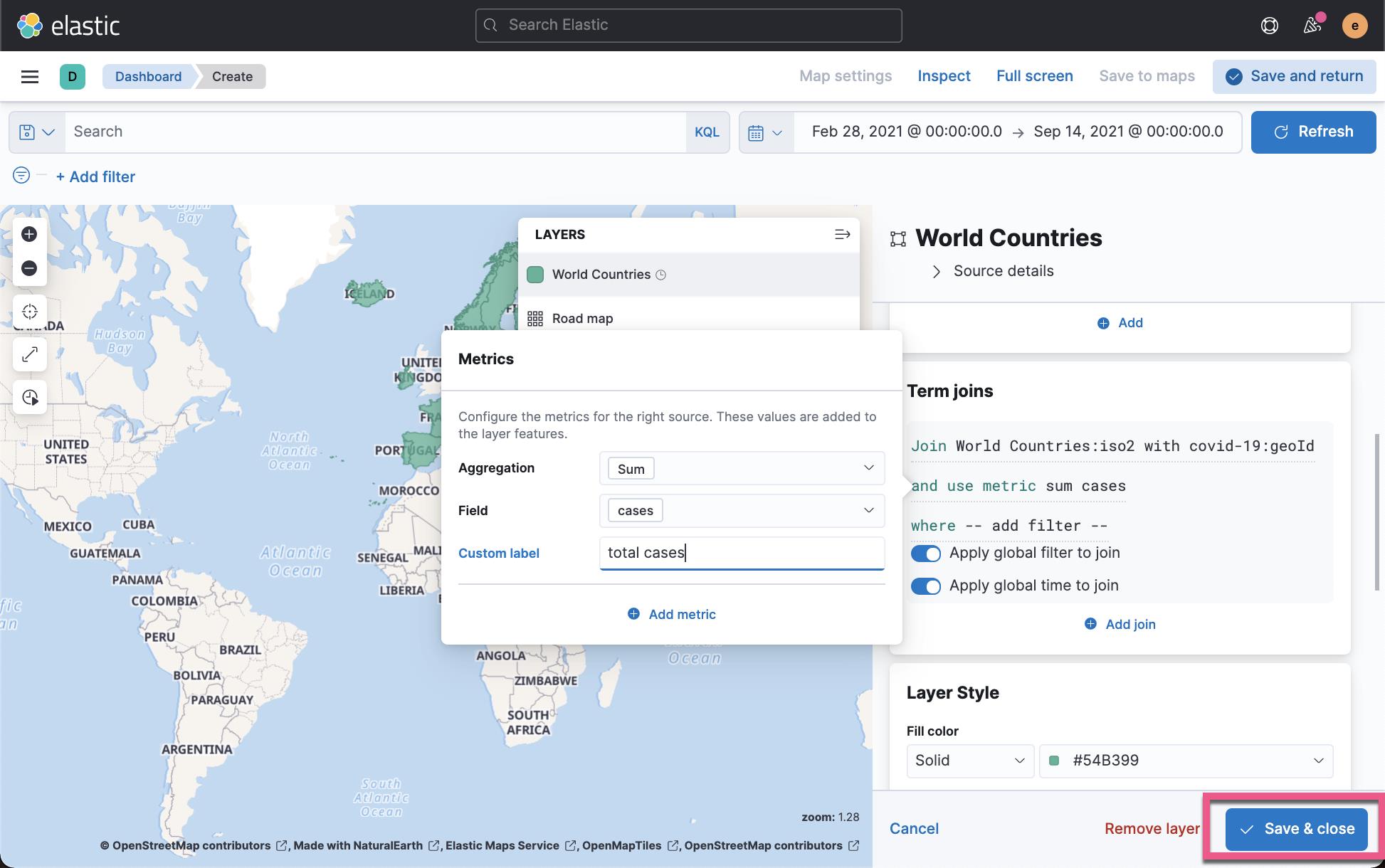
点击上面的 Save & close 后,我们再接着编辑上面的地图:
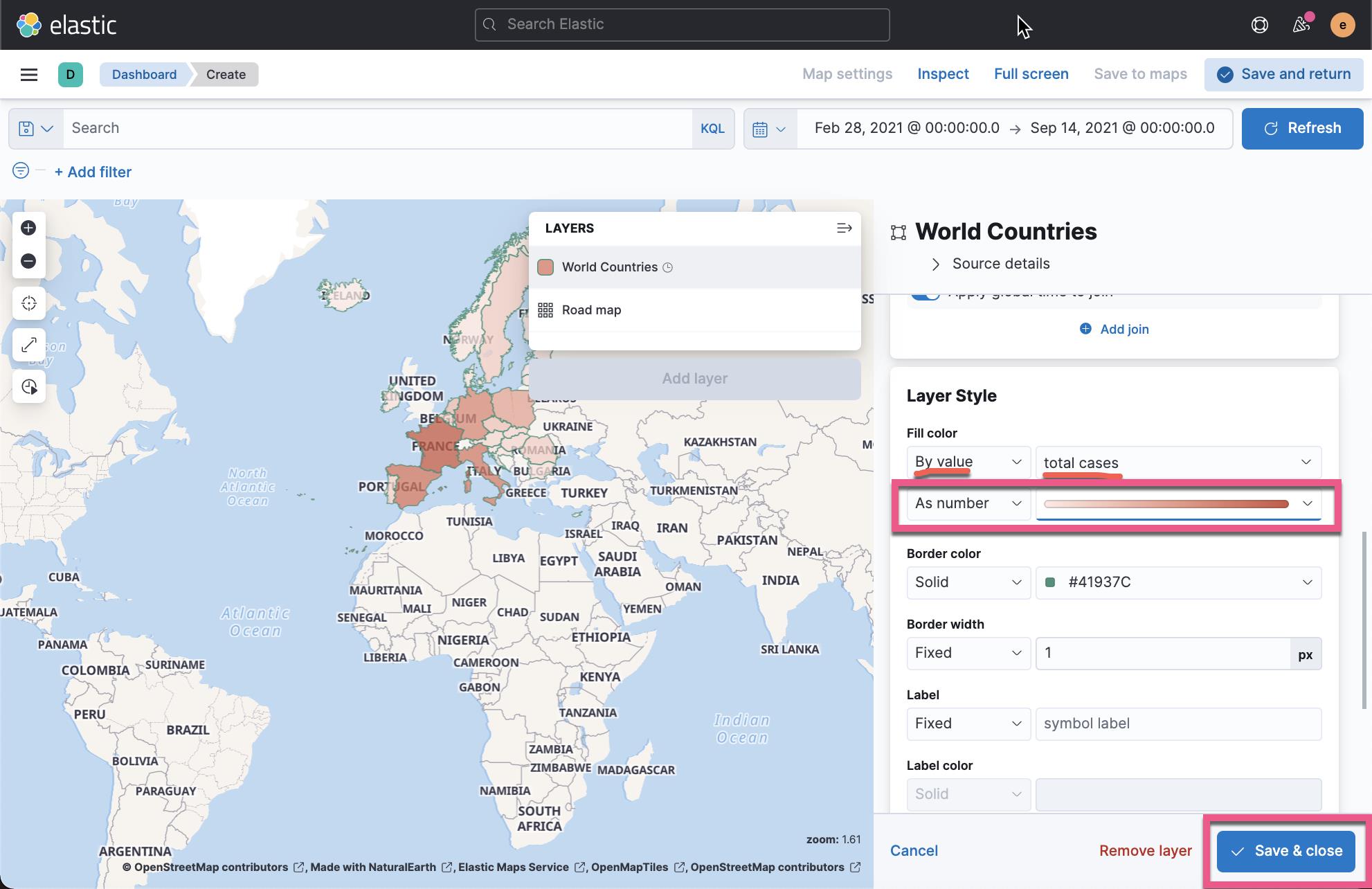
在上面,我们选择颜色是由 total cases 来定义的。点击 Save & close 按钮:
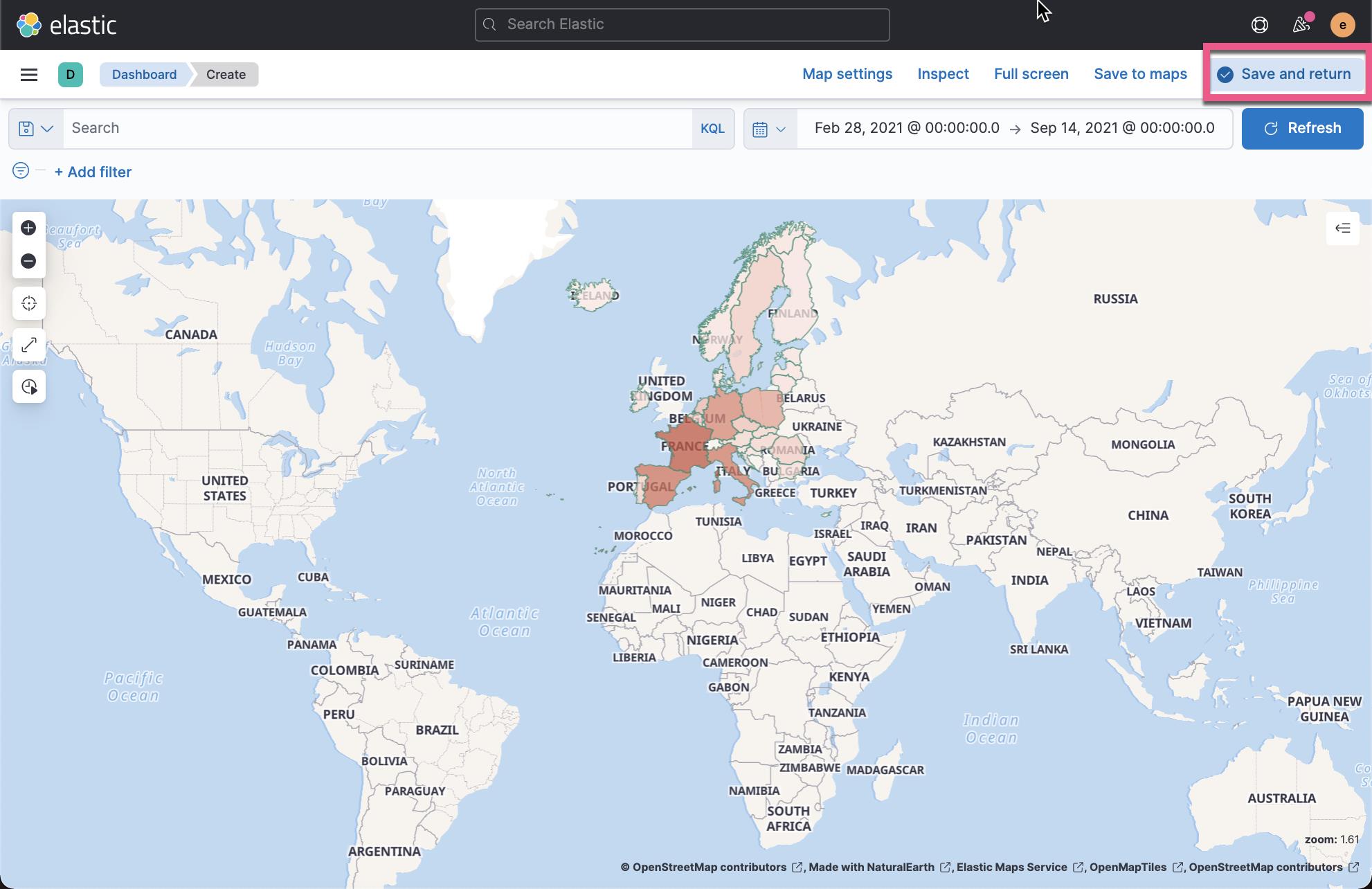
从上面,我们可以看出来 France 还是比较严重的地区。 我们点击 Save and return:
这样我们就完成了第一个可视化。同样地,我们也可以按照类似的步骤来创建一个以 deaths 为统计的地理分布图:
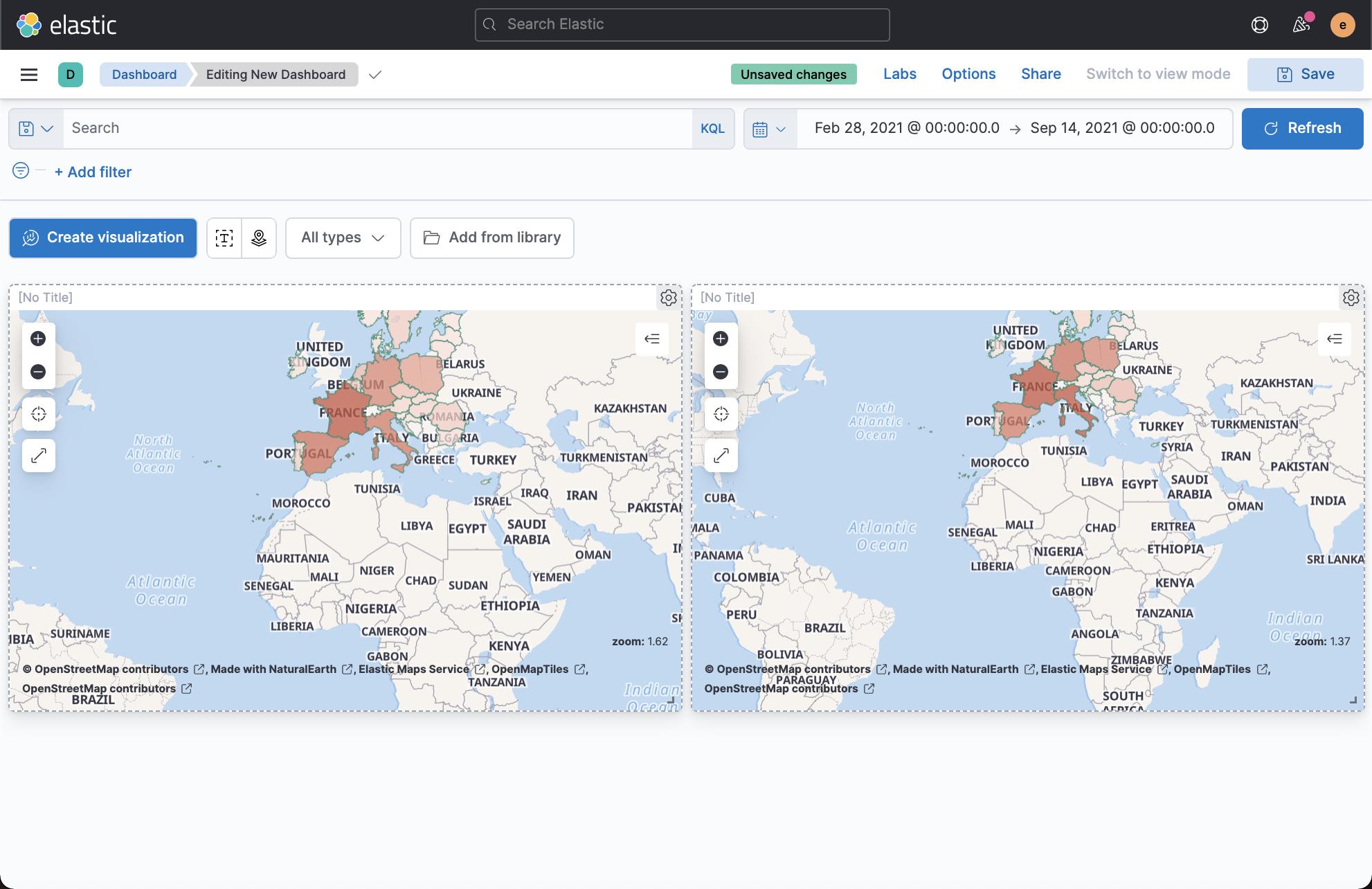
在上面的图中,我们可以看出来死亡的人数在各个国家的分布。显然和案例的分布略有不同。
也许有人问,有的国家人数多,有的国家人数少。尽管案例的人数一样多,总人口数多的国家的感染的比率就少。显然这个数据在我们的原始数据中没有。那么我该如何来得到这个数据呢?我们可以使用 runtime field。
我们先打开 Lens:
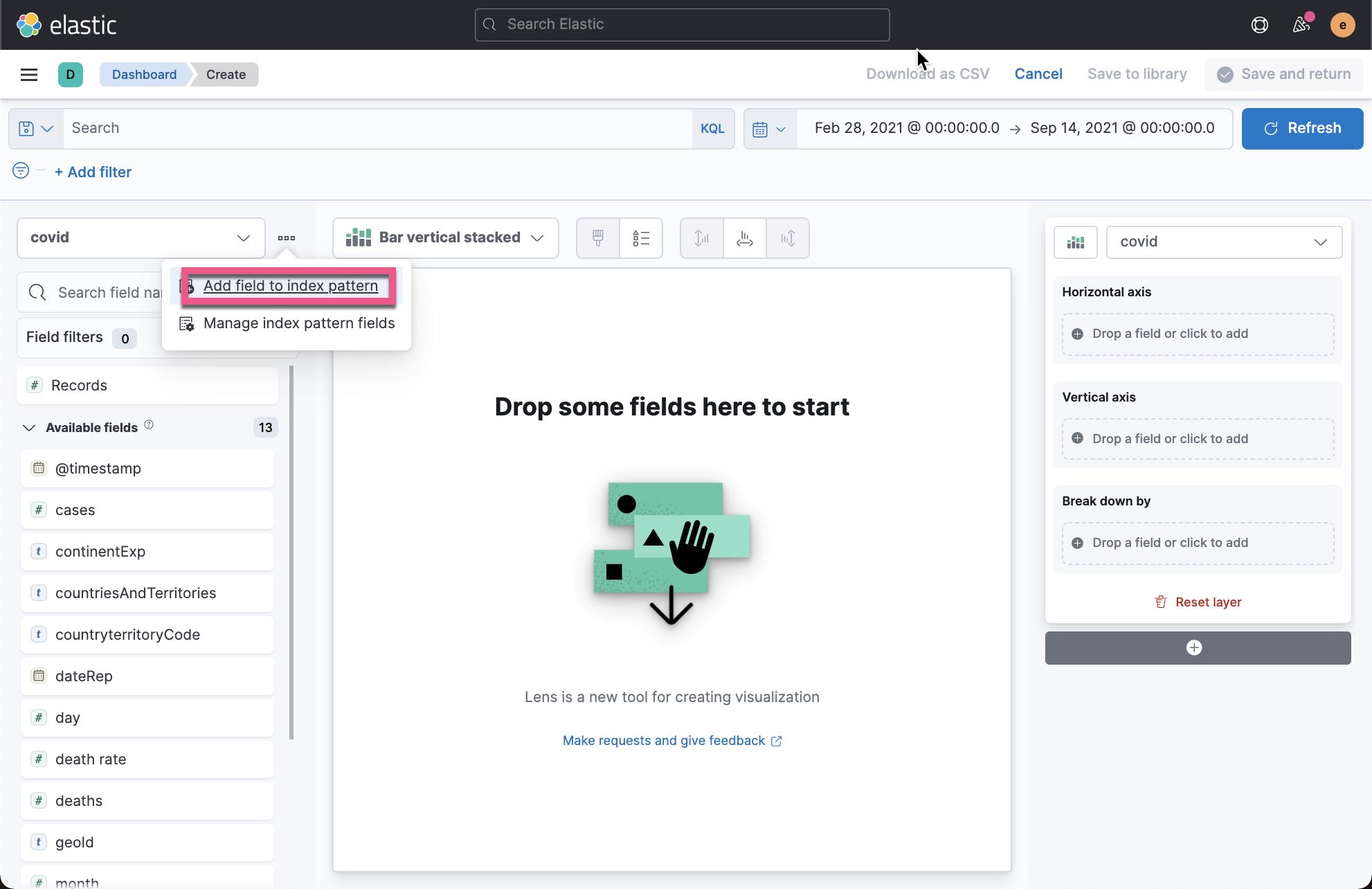
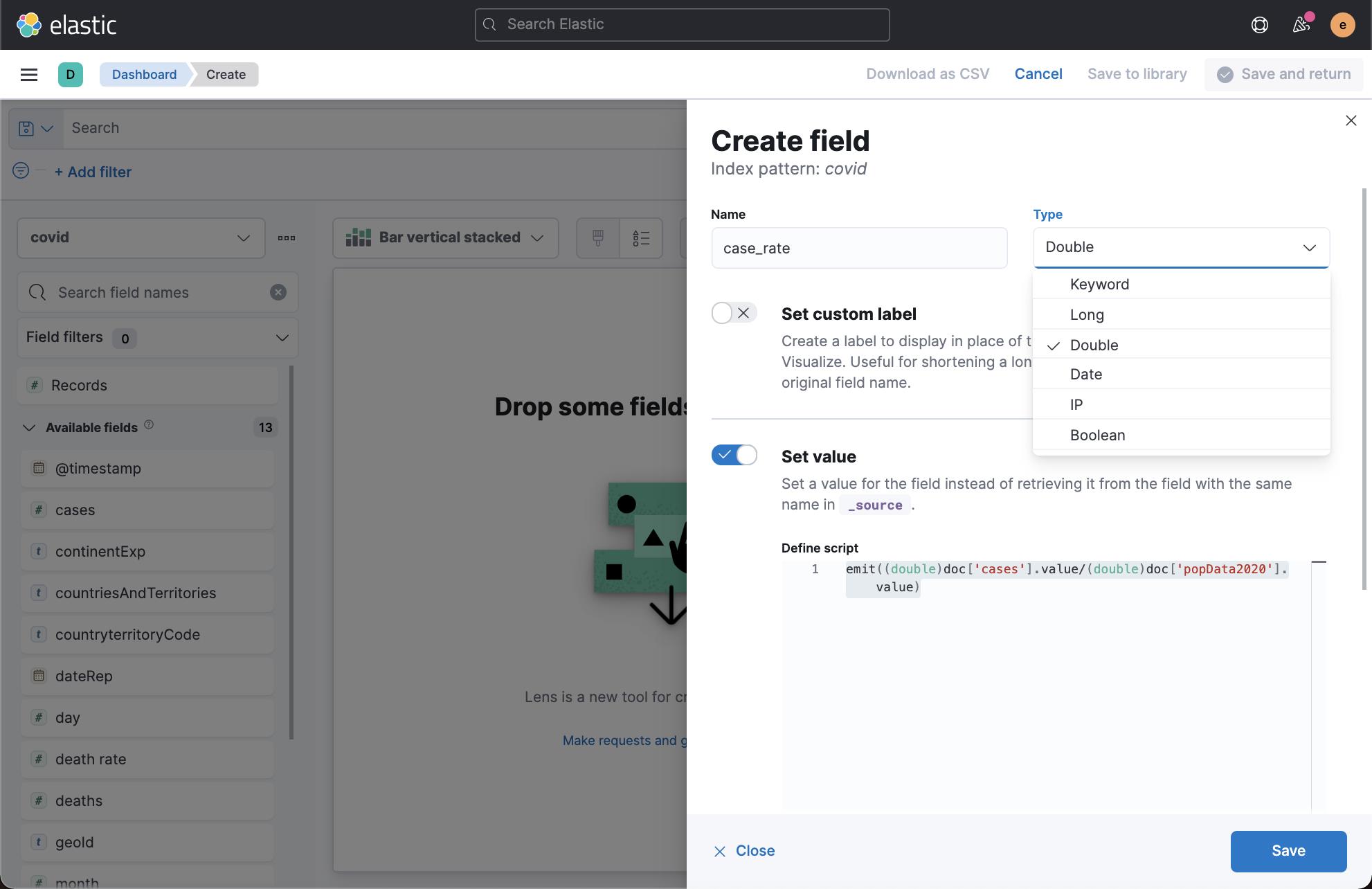
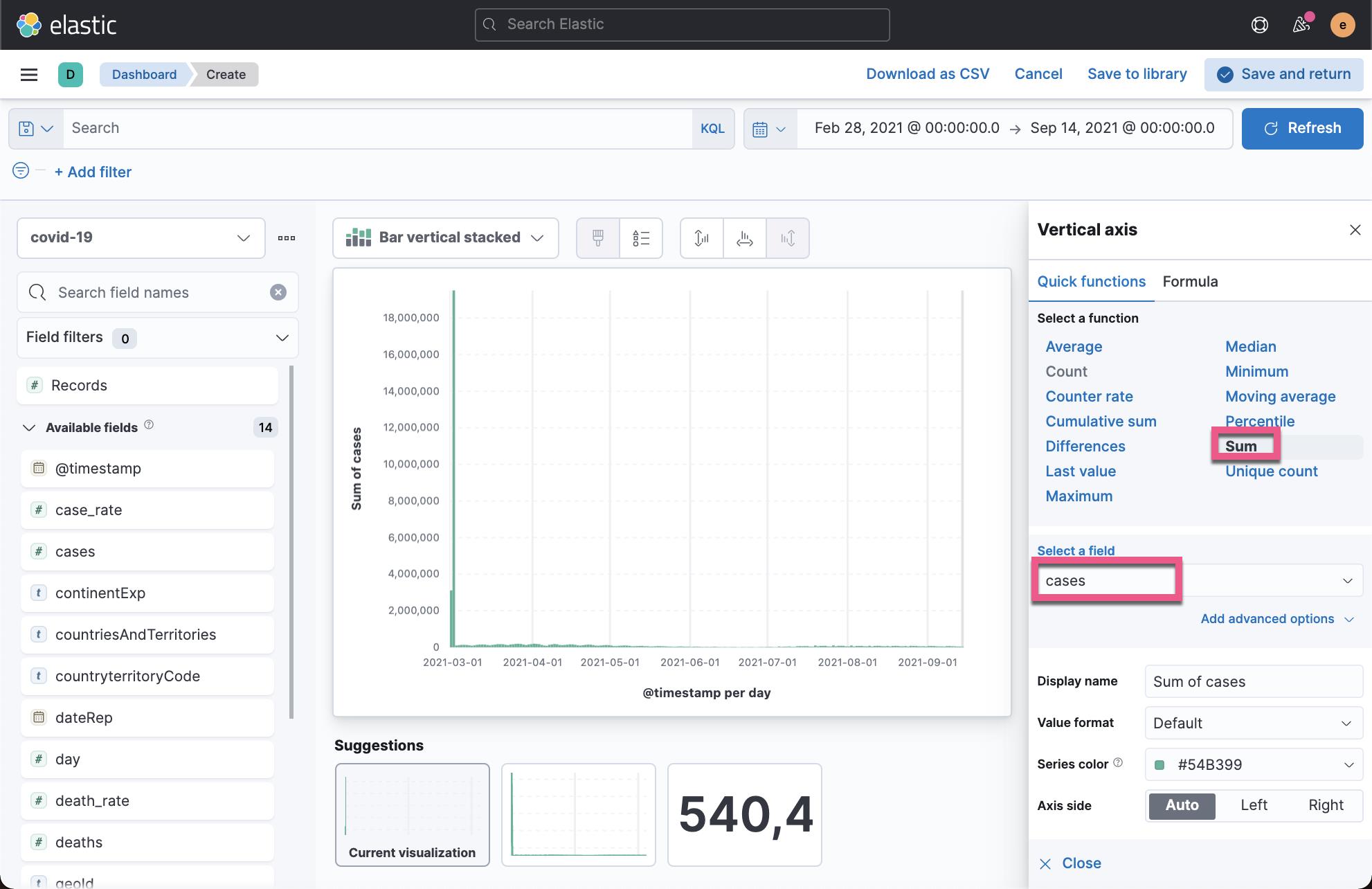
我们在上面创建一个叫做 case_rate 的字段。在 define script 中定义如下的脚本:
emit((double)doc['cases'].value/(double)doc['popData2020'].value)点击 Save 按钮:
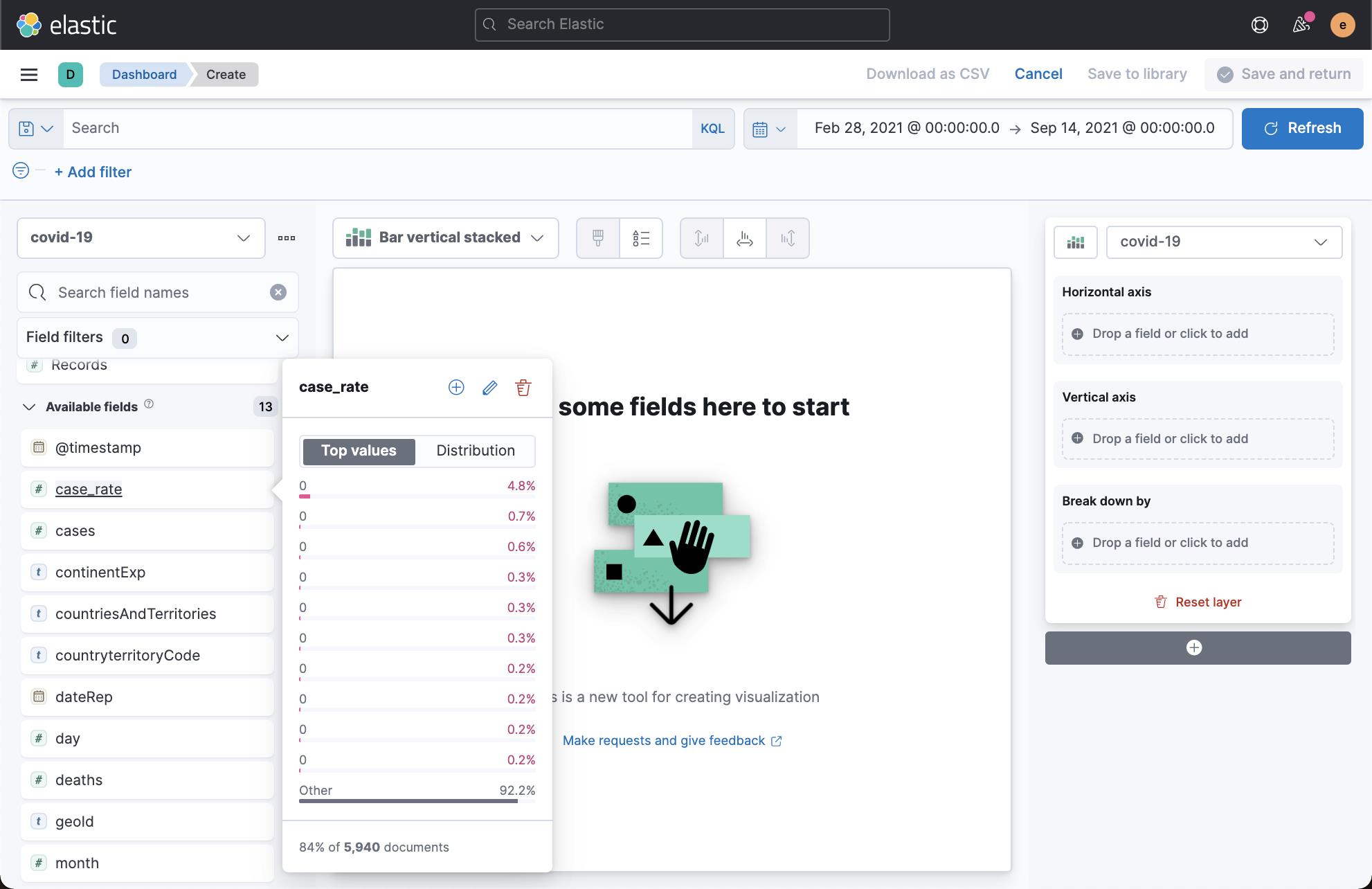
在上面我们可以看到一个叫做 case_rate 的字段。按照同样的方法,我们可以创建另外一个叫做 death_rate 的 runtime 字段:
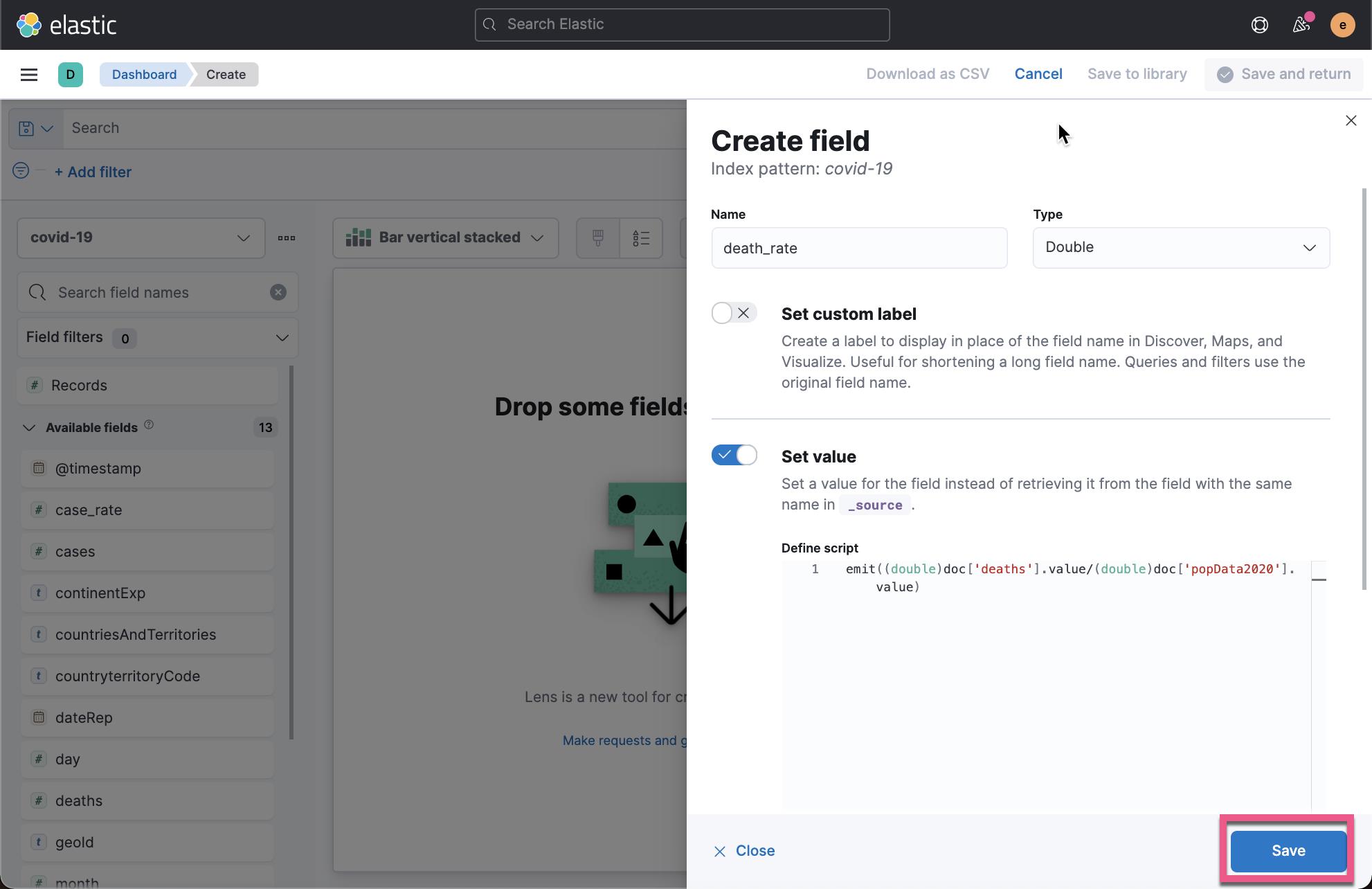
在上面,我输入如下的脚本:
emit((double)doc['deaths'].value/(double)doc['popData2020'].value)点击 Save 按钮:
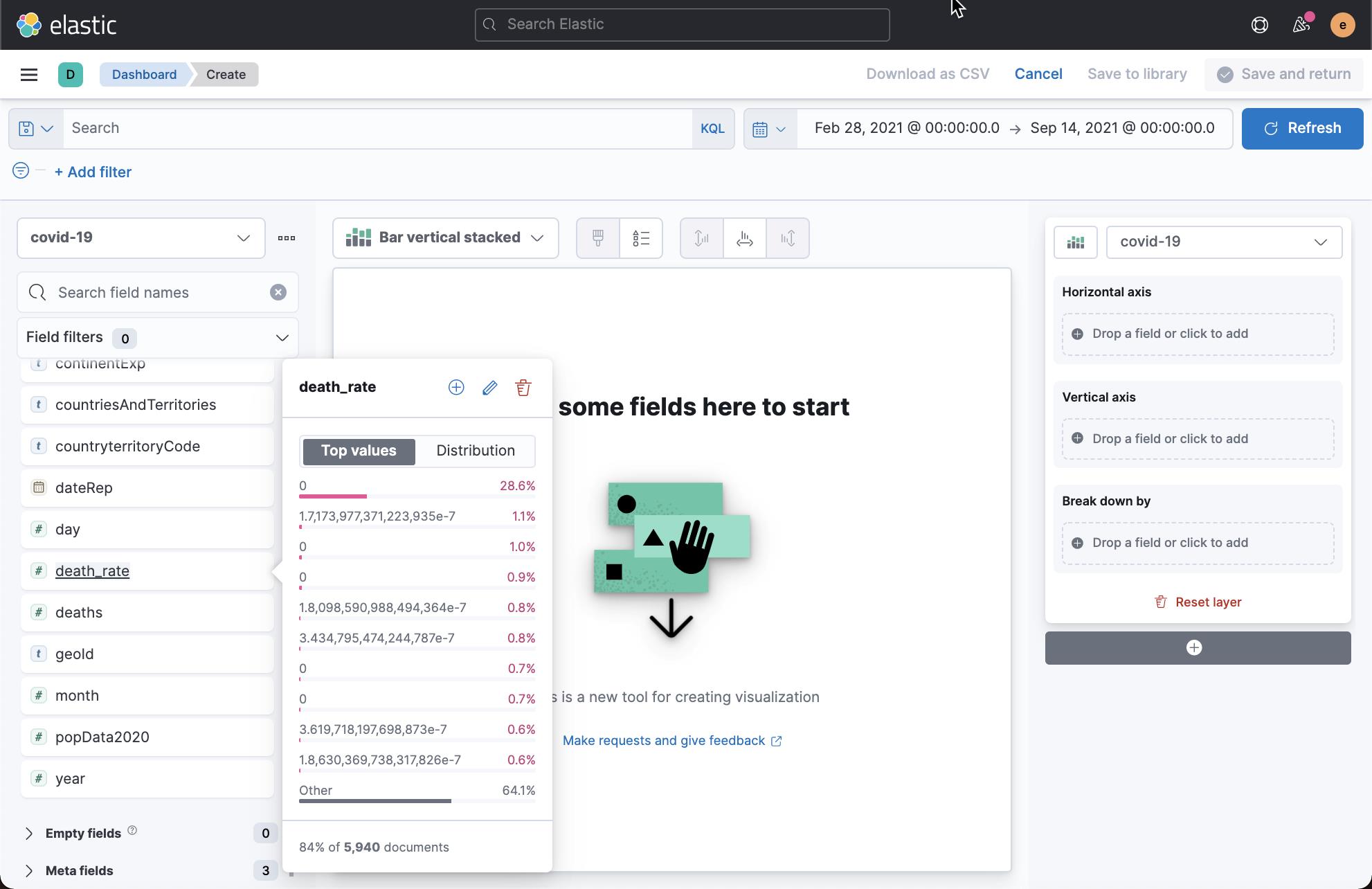
这样我们就成功地创建了两个 runtime 字段:case_rate 及 death_rate。
按照同样的方法,我们来对上面的两个 runtime 字段做 2 个 Maps 的可视化:
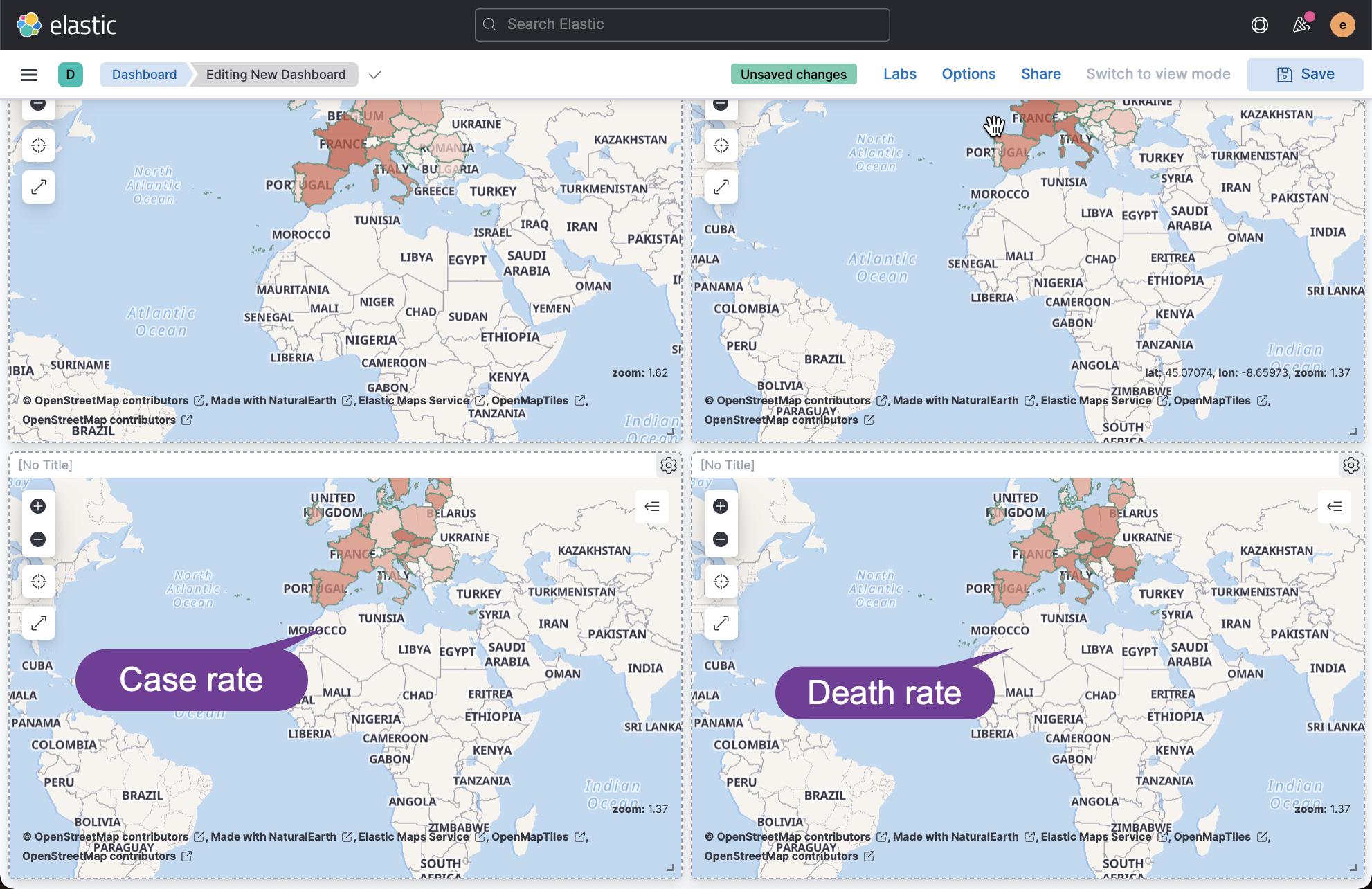
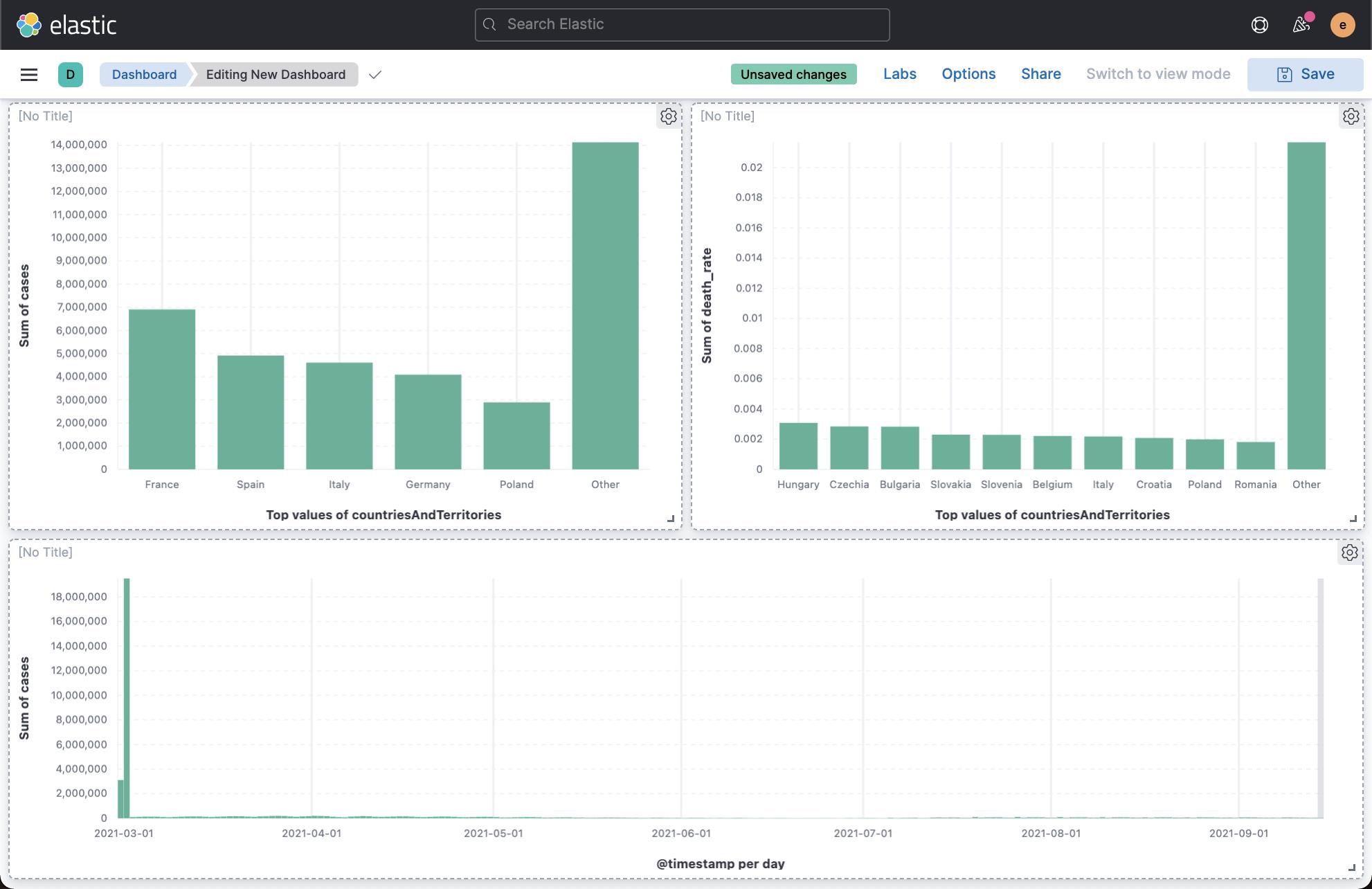
从上面的两个图中可以看出来:死亡率高的并不是发病率高的地方。
我们找出来病例最多的5个国家:
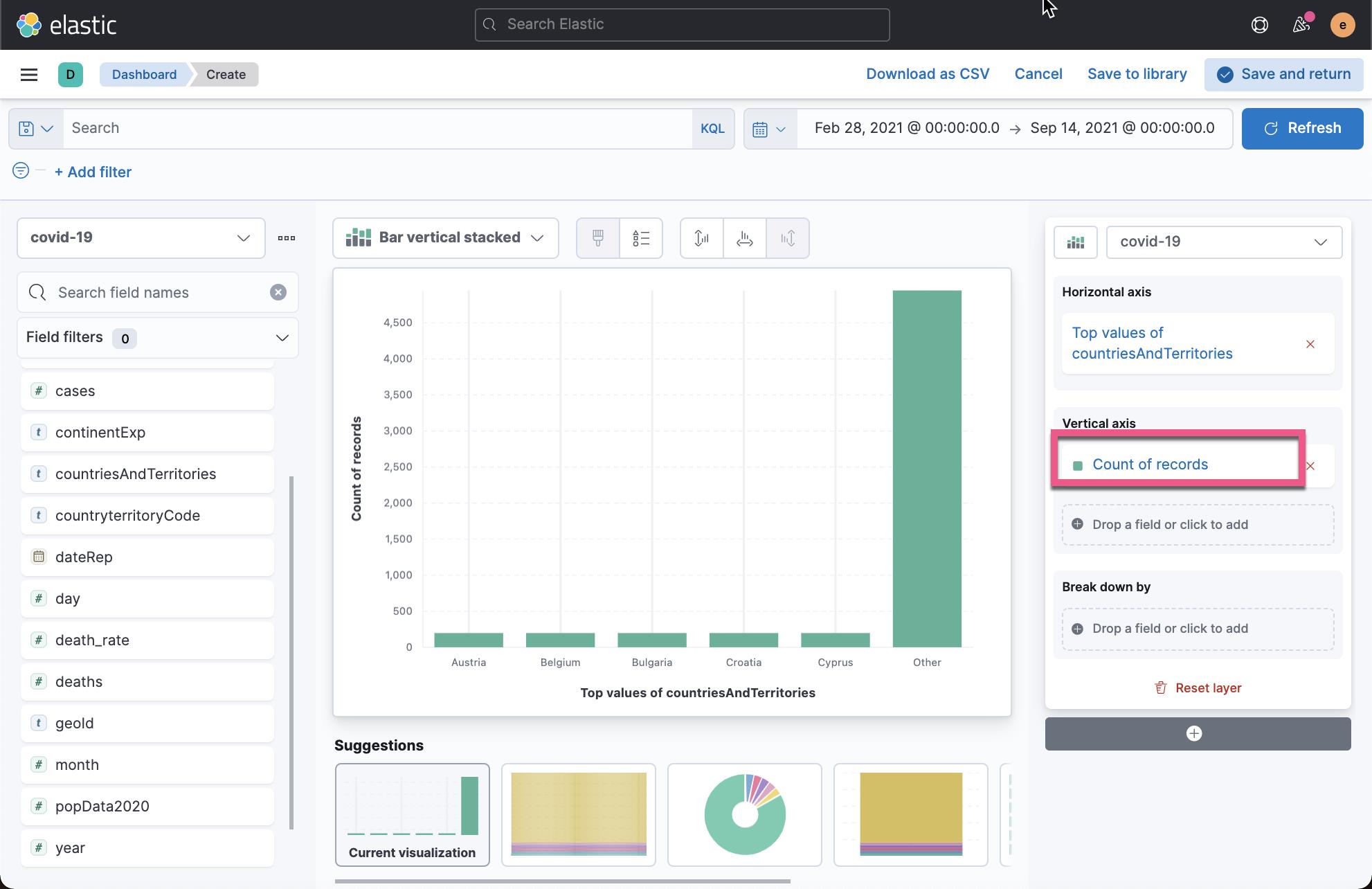
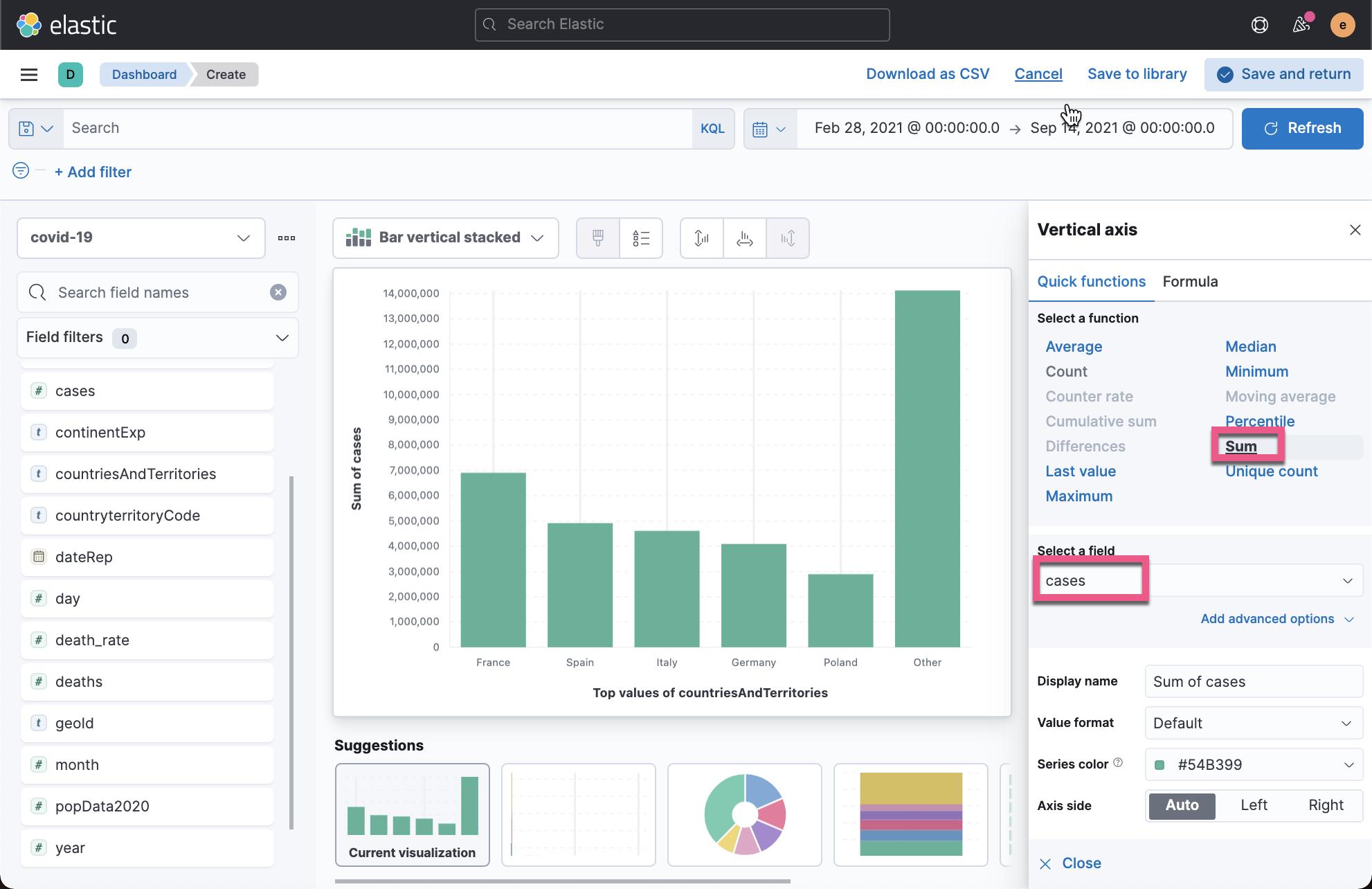
从上面,我们可以看出来总数最多的是 France。点击 Save & return:
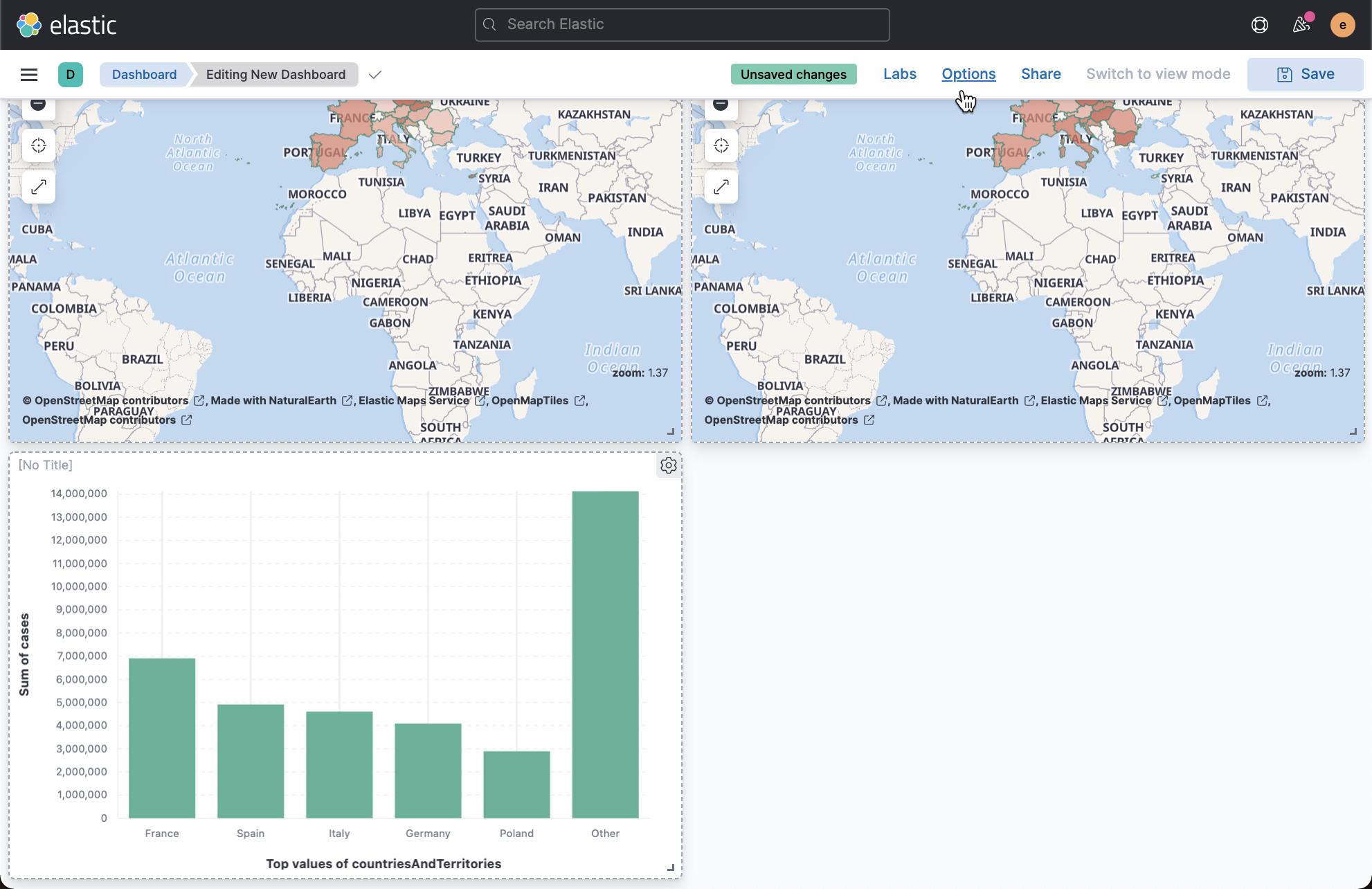
按照同样的方法,我们可以找出死亡率最高的10个国家:
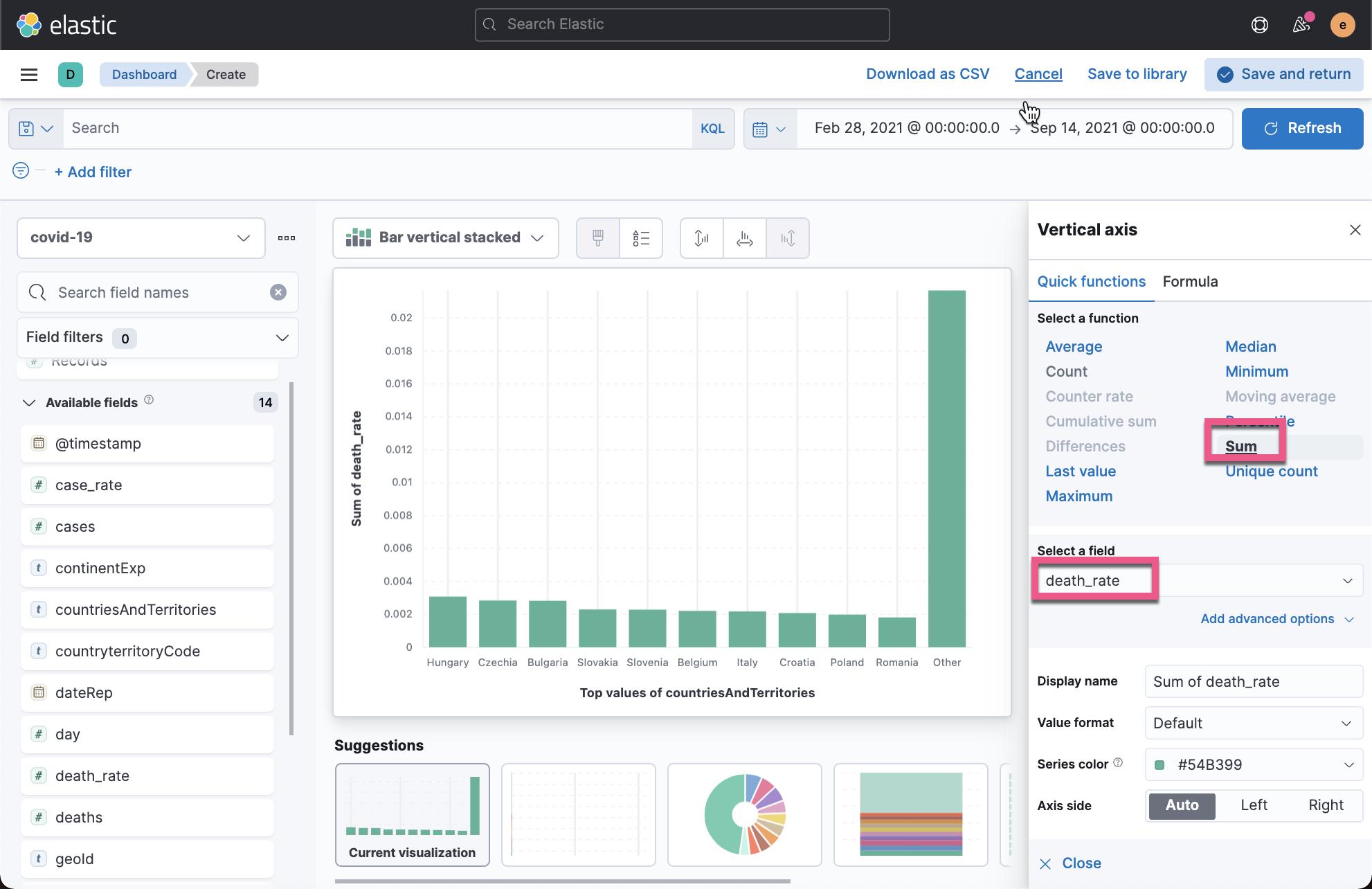
我们接下来看每天的案例的发生情况:
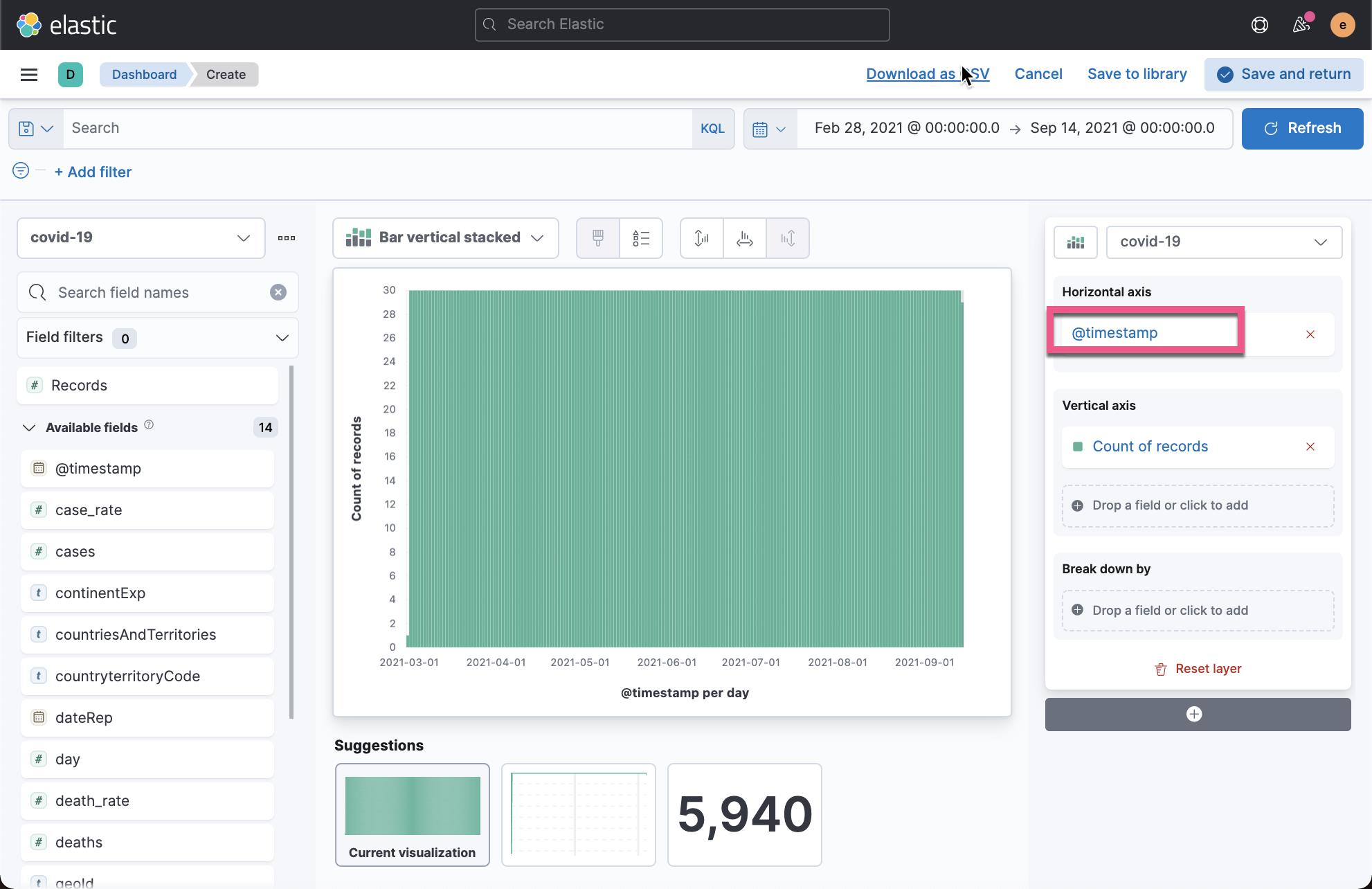
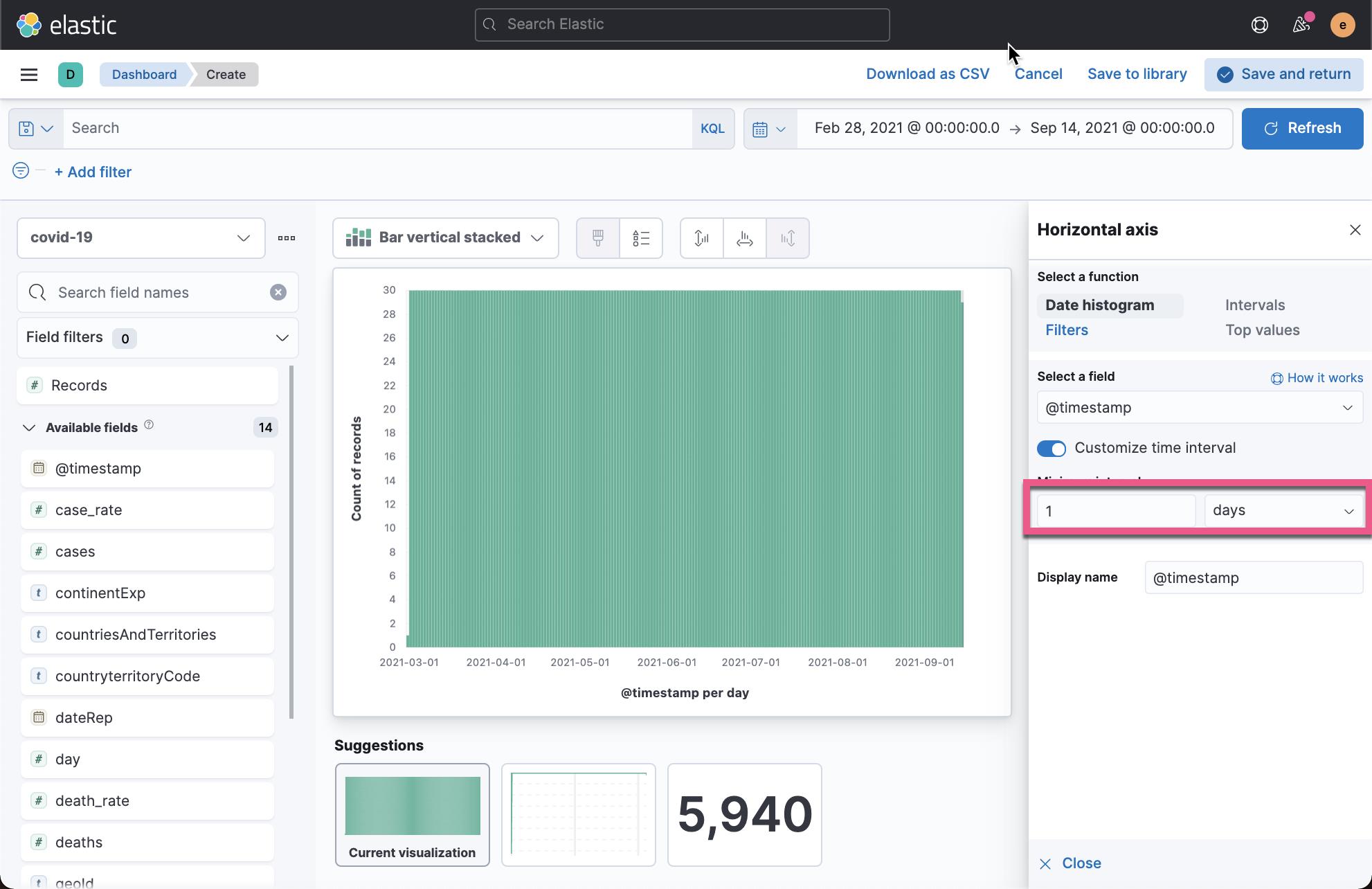
我们很清楚地看出来在3月1号,有一个高峰期。案例非常多。
在这里,我就简单地分析这些数据。希望对大家如何分析数据有一定的帮助。你可以做更多的可视化,甚至对数据进行机器学习的分析。
最后,我们点击右上角的 Save 按钮就可以保存我们的 Dashboard 了:
总结
在本教程中,我们展示了如何创建 runtime field 以及如何使用 Lens 及 Maps 来创建我们所需要的可视化图。
以上是关于Kibana:使用 Elastic Stack 来分析 COVID 数据的主要内容,如果未能解决你的问题,请参考以下文章
Kibana:Waffle 可视化介绍 - Elastic Stack 8.1
Kibana:为访问 Kibana 添加 https - Elastic Stack 8.0
Kibana:Mosaic 可视化介绍 - Elastic Stack 8.1