flink学习day04:对Event Time 与 Watermark的理解
Posted 黑马程序员官方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flink学习day04:对Event Time 与 Watermark的理解相关的知识,希望对你有一定的参考价值。
☑ 带大家零基础入门flink:
▶flink学习day01:Flink基础入门(含案例)
▶flink学习day02::datasource、transforma和sink
▶flink学习day03:flink datastream 开发
流式计算中时间的分类:

1 eventTime:数据、事件产生的时间,
2 ingestionTime:进入flink/spark的时间
3 processingTime:进入到具体计算的operator的系统时间
分析:
spark streaming中的窗口计算使用的就是processingtime,与事件、数据真实发生的时间无关,就取决于什么到达处理节点;
flink中引入了eventtime机制,就是flink中可以指定窗口计算的时候按照事件时间(事件真实发生的时间)来进行计算。使用eventtime进行计算才是正确,符合数据发生的时间。
需要在env进行设置,同时你需要保证数据(事件)中要有eventtime时间字段:
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //设置使用事件时间
watermark
按照eventtime进行是不是就高枕无忧了?
数据有可能会延迟产生 使用eventtime进行计算才是合理的;

问题 二
数据乱序到达的问题,晚(eventime)的数据先到达,早(eventime)的数据后达到

flink watermark原理参考画图
flink watermark案例
api介绍

我们一般选择使用周期性方式生成水印
案例
需求:添加水印统计信号灯通过的汽车数量。
参考代码:
package cn.itcast.flink.watermark
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.scala.DataStream, StreamExecutionEnvironment, WindowedStream
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
/*
演示使用周期性方式生成水印
*/
/*
需求:
编写代码, 计算5秒内(滚动时间窗口),每个信号灯汽车数量
信号灯数据(信号ID(String)、通过汽车数量、时间戳(事件时间)),要求添加水印来解决网络延迟问题。
*/
//3. 定义CarWc 样例类
case class CarWc(id: String, num: Int, ts: Long)
object WatermarkDemo
/*
1. 创建流处理运行环境
2. 设置处理时间为EventTime ,设置水印的周期间隔,定期生成水印的时间
3. 定义CarWc 样例类
4. 使用socketstream发送数据
5. 添加水印
- 允许延迟2秒
- 在获取水印方法中,打印水印时间、事件时间和当前系统时间
6. 按照用户进行分流
7. 设置5秒的时间窗口
8. 进行聚合计算
9. 打印结果数据
10. 启动执行流处理
*/
def main(args: Array[String]): Unit =
//1 创建流处理运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2 设置处理时间为事件时间,
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//3 生成水印的周期 默认200ms
env.getConfig.setAutoWatermarkInterval(200)
// 默认程序并行度是机器的核数,8个并行度,注意在flink程序中如果是多并行度,水印时间是每个并行度比较最小的值作为当前流的watermark
env.setParallelism(1)
//4 添加socketsource
val socketDs: DataStream[String] = env.socketTextStream("node1", 9999)
// 5 数据处理之后添加水印
val carWcDs: DataStream[CarWc] = socketDs.map(
line =>
//按照逗号切分数据组成carwc
val arr = line.split(",")
CarWc(arr(0), arr(1).trim.toInt, arr(2).trim.toLong)
)
// 添加水印 周期性 AssignerWithPeriodicWatermarks 使用其子类 ,构造参数:水印允许的延迟时间,泛型是stream中的数据类型
val watermarkDs: DataStream[CarWc] = carWcDs.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[CarWc](Time.seconds(2))
// 水印机制是在eventtime基础之上减去一段时间,就是flink允许数据延迟的范围;eventtime是来自数据,flink是不知道eventtime是多少,以及是哪个字段
//这个方法就是告诉flink你的数据哪个字段是eventime
override def extractTimestamp(element: CarWc): Long =
element.ts
)
// 6 设置窗口 5s的滚动窗口
val windowStream: WindowedStream[CarWc, Tuple, TimeWindow] = watermarkDs.keyBy(0).
window(TumblingEventTimeWindows.of(Time.seconds(5)))
// 7 使用apply方法对窗口进行计算
val windowDs: DataStream[CarWc] = windowStream.apply(
//泛型:1 carwc,2 carwc,3 tuple,4 timewindow
new WindowFunction[CarWc, CarWc, Tuple, TimeWindow]
//key:tuple,window:当前触发计算的window对象,input:当前窗口的数据,out:计算结果收集器
override def apply(key: Tuple, window: TimeWindow, input: Iterable[CarWc], out: Collector[CarWc]): Unit =
val wc: CarWc = input.reduce(
(c1, c2) =>
CarWc(c1.id, c1.num + c2.num, c2.ts) //累加出通过的汽车数量,关于时间在这里我们不关心
)
//发送计算结果
out.collect(wc)
//获取到窗口开始和结束时间
println("窗口开始时间》》" + window.getStart + "=====;窗口结束时间》》" + window.getEnd + ";窗口中的数据》》" +
input.iterator.mkString(","))
)
// 打印结果
windowDs.print()
// 启动
env.execute()
总结:
注意:
(1)基于事件时间进行计算的时候,判断数据是属于哪个窗口
判断标准:
eventtime >= window -starttime , enenttime <window-endtime
窗口是左闭右开的
[)
(2)窗口开始时间和结束时间的确定:源码解读

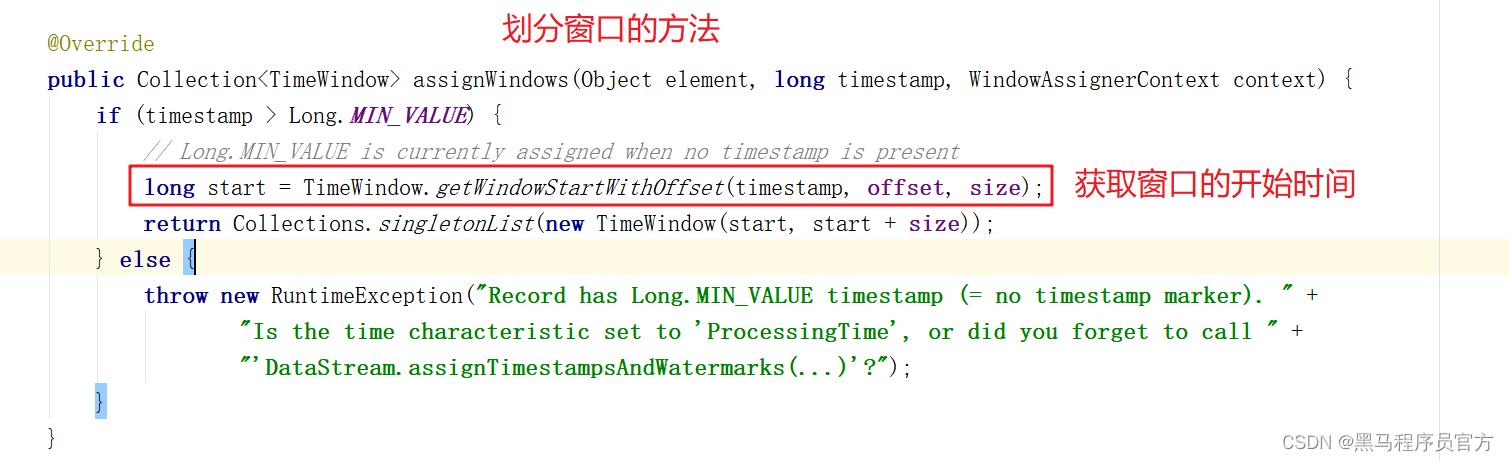

窗口开始时间取决于第一条数据的eventtime的值!!
(3)添加水印方式选择的是周期性添加AssignerWithPeriodicWatermarks,传入的是的AssignerWithPeriodicWatermarks子类,BoundedOutOfOrdernessTimestampExtractor。
复杂版本–手动实现
package cn.itcast.flink.watermark
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.scala.DataStream, StreamExecutionEnvironment, WindowedStream
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
/*
演示使用周期性方式生成水印 -复杂版本--手动实现watermark机制
*/
/*
需求:
编写代码, 计算5秒内(滚动时间窗口),每个信号灯汽车数量
信号灯数据(信号ID(String)、通过汽车数量、时间戳(事件时间)),要求添加水印来解决网络延迟问题。
*/
//3. 定义CarWc 样例类
case class CarWc(id: String, num: Int, ts: Long)
object WatermarkDemo2
/*
1. 创建流处理运行环境
2. 设置处理时间为EventTime ,设置水印的周期间隔,定期生成水印的时间
3. 定义CarWc 样例类
4. 使用socketstream发送数据
5. 添加水印
- 允许延迟2秒
- 在获取水印方法中,打印水印时间、事件时间和当前系统时间
6. 按照用户进行分流
7. 设置5秒的时间窗口
8. 进行聚合计算
9. 打印结果数据
10. 启动执行流处理
*/
def main(args: Array[String]): Unit =
//1 创建流处理运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2 设置处理时间为事件时间,
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//3 生成水印的周期 默认200ms
env.getConfig.setAutoWatermarkInterval(200)
// 默认程序并行度是机器的核数,8个并行度,注意在flink程序中如果是多并行度,水印时间是每个并行度比较最小的值作为当前流的watermark
env.setParallelism(1)
//4 添加socketsource
val socketDs: DataStream[String] = env.socketTextStream("node1", 9999)
// 5 数据处理之后添加水印
val carWcDs: DataStream[CarWc] = socketDs.map(
line =>
//按照逗号切分数据组成carwc
val arr = line.split(",")
CarWc(arr(0), arr(1).trim.toInt, arr(2).trim.toLong)
)
// 5.2 添加水印 周期性 new AssignerWithPeriodicWatermarks
val watermarkDs: DataStream[CarWc] = carWcDs.assignTimestampsAndWatermarks(
new AssignerWithPeriodicWatermarks[CarWc]
// watermark=eventtime -延迟时间
// 5.2.1 定义允许延迟的时间 2s
val delayTime=2000
//定义当前最大的时间戳
var currentMaxTimestamp=0L
/** The timestamp of the last emitted watermark. */
var lastEmittedWatermark = Long.MinValue
// todo 获取watermark时间 实现watermark不会倒退
override def getCurrentWatermark: Watermark =
// 计算watermark
val watermarkTime: Long = currentMaxTimestamp - delayTime
if (watermarkTime >lastEmittedWatermark)
lastEmittedWatermark =watermarkTime
new Watermark(lastEmittedWatermark)
//todo 抽取时间戳 element:新到达的元素,previousElementTimestamp:之前元素的时间戳
// 5.2.2 抽取时间戳 计算watermark
override def extractTimestamp(element: CarWc, previousElementTimestamp: Long): Long =
//获取到时间
//注意的问题:时间倒退的问题:消息过来是乱序的,每次新来的消息时间戳不是一定变大的,所以会导致水印有可能倒退
var eventTime = element.ts
if (eventTime >currentMaxTimestamp) //比较与之前最大的时间戳进行比较
currentMaxTimestamp =eventTime
eventTime
)
// 6 设置窗口 5s的滚动窗口
val windowStream: WindowedStream[CarWc, Tuple, TimeWindow] = watermarkDs.keyBy(0).
window(TumblingEventTimeWindows.of(Time.seconds(5)))
// 7 使用apply方法对窗口进行计算
val windowDs: DataStream[CarWc] = windowStream.apply(
//泛型:1 carwc,2 carwc,3 tuple,4 timewindow
new WindowFunction[CarWc, CarWc, Tuple, TimeWindow]
//key:tuple,window:当前触发计算的window对象,input:当前窗口的数据,out:计算结果收集器
override def apply(key: Tuple, window: TimeWindow, input: Iterable[CarWc], out: Collector[CarWc]): Unit =
val wc: CarWc = input.reduce(
(c1, c2) =>
CarWc(c1.id, c1.num + c2.num, c2.ts) //累加出通过的汽车数量,关于时间在这里我们不关心
)
//发送计算结果
out.collect(wc)
//获取到窗口开始和结束时间
println("窗口开始时间》》" + window.getStart + "=====;窗口结束时间》》" + window.getEnd + ";窗口中的数据》》" +
input.iterator.mkString(","))
)
// 打印结果
windowDs.print()
// 启动
env.execute()
注意:

建议工作中就使用子类方式实现水印即可!
再次理解watermark
基于watermark+eventime只能解决部分数据延迟问题,不能完全解决,对于watermark无法解决的延迟数据,flink默认是丢弃的,如果我们需要保证数据完全不丢失可以再使用allowedlateness+侧道输出来保证。
allowedlateness+侧道输出 API
(1)allowedLateness(lateness: Time) 这种方式设置的允许延迟时间与水印的延迟时间是一个累加的效果,
但是注意这个时间并不会影响窗口触发计算的标准,watermark >=window-endtime就会触发计算,
只是如果这设置了这个时间,窗口不会关闭和销毁而是继续等待我们这种方式设置的时间。
(2)侧道输出 保存极端延迟数据
sideOutputLateData(outputTag: OutputTag[T]):设置侧道输出保存延迟的数据
DataStream.getSideOutput(tag: OutputTag[X]) :获取其中保存的延迟数据
侧道输出+allowedlateness方案
设置侧道输出与allowedlateness
获取侧道输出数据
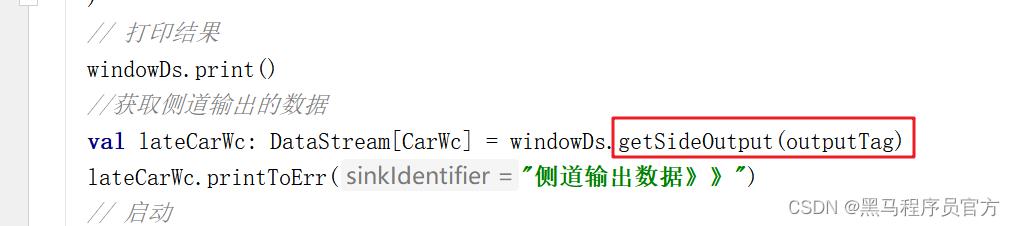
参考代码:
package cn.itcast.flink.watermark
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.scala.DataStream, OutputTag, StreamExecutionEnvironment, WindowedStream
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
/*
演示使用周期性方式生成水印 -复杂版本--手动实现watermark机制,使用侧道输出+allowedlaten保证数据不丢失
*/
/*
需求:
编写代码, 计算5秒内(滚动时间窗口),每个信号灯汽车数量
信号灯数据(信号ID(String)、通过汽车数量、时间戳(事件时间)),要求添加水印来解决网络延迟问题。
*/
//3. 定义CarWc 样例类
case class CarWc(id: String, num: Int, ts: Long)
object SideOutputWKDemo
/*
1. 创建流处理运行环境
2. 设置处理时间为EventTime ,设置水印的周期间隔,定期生成水印的时间
3. 定义CarWc 样例类
4. 使用socketstream发送数据
5. 添加水印
- 允许延迟2秒
- 在获取水印方法中,打印水印时间、事件时间和当前系统时间
6. 按照用户进行分流
7. 设置5秒的时间窗口
8. 进行聚合计算
9. 打印结果数据
10. 启动执行流处理
*/
def main(args: Array[String]): Unit =
//1 创建流处理运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2 设置处理时间为事件时间,
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//3 生成水印的周期 默认200ms
env.getConfig.setAutoWatermarkInterval(200)
// 默认程序并行度是机器的核数,8个并行度,注意在flink程序中如果是多并行度,水印时间是每个并行度比较最小的值作为当前流的watermark
env.setParallelism(1)
//4 添加socketsource
val socketDs: DataStream[String] = env.socketTextStream("node1", 9999)
// 5 数据处理之后添加水印
val carWcDs: DataStream[CarWc] = socketDs.map(
line =>
//按照逗号切分数据组成carwc
val arr = line.split(",")
CarWc(arr(0), arr(1).trim.toInt, arr(2).trim.toLong)
)
// 5.2 添加水印 周期性 new AssignerWithPeriodicWatermarks
val watermarkDs: DataStream[CarWc] = carWcDs.assignTimestampsAndWatermarks(
new AssignerWithPeriodicWatermarks[CarWc]
// watermark=eventtime -延迟时间
// 5.2.1 定义允许延迟的时间 2s
val delayTime=2000
//定义当前最大的时间戳
var currentMaxTimestamp=0L
/** The timestamp of the last emitted watermark. */
var lastEmittedWatermark = Long.MinValue
// todo 获取watermark时间 实现watermark不会倒退
override def getCurrentWatermark: Watermark =
// 计算watermark
val watermarkTime: Long = currentMaxTimestamp - delayTime
if (watermarkTime >lastEmittedWatermark)
lastEmittedWatermark =watermarkTime
new Watermark(lastEmittedWatermark)
//todo 抽取时间戳 element:新到达的元素,previousElementTimestamp:之前元素的时间戳
// 5.2.2 抽取时间戳 计算watermark
override def extractTimestamp(element: CarWc, previousElementTimestamp: Long): Long =
//获取到时间
//注意的问题:时间倒退的问题:消息过来是乱序的,每次新来的消息时间戳不是一定变大的,所以会导致水印有可能倒退
var eventTime = element.ts
if (eventTime >currentMaxTimestamp) //比较与之前最大的时间戳进行比较
currentMaxTimestamp =eventTime
eventTime
)
// 6 设置窗口 5s的滚动窗口
//准备一个侧道输出对象
val outputTag: OutputTag[CarWc] = new OutputTag[CarWc]("lateCarwc")
val windowStream: WindowedStream[CarWc, Tuple, TimeWindow] = watermarkDs.keyBy(0).
window(TumblingEventTimeWindows.of(Time.seconds(5)))
//设置允许延迟时间 --》在水印基础上再次增加延迟允许延迟时间
.allowedLateness(Time.seconds(5))
//设置侧道输出
.sideOutputLateData(outputTag)
// 7 使用apply方法对窗口进行计算
val windowDs: DataStream[CarWc] = windowStream.apply(
//泛型:1 carwc,2 carwc,3 tuple,4 timewindow
new WindowFunction[CarWc, CarWc, Tuple, TimeWindow]
//key:tuple,window:当前触发计算的window对象,input:当前窗口的数据,out:计算结果收集器
override def apply(key: Tuple, window: TimeWindow, input: Iterable[CarWc], out: Collector[CarWc]): Unit =
val wc: CarWc = input.reduce(
(c1, c2) =>
CarWc(c1.id, c1.num + c2.num, c2.ts) //累加出通过的汽车数量,关于时间在这里我们不关心
)
//发送计算结果
out.collect(wc)
//获取到窗口开始和结束时间
println("窗口开始时间》》" + window.getStart + "=====;窗口结束时间》》" + window.getEnd + ";窗口中的数据》》" +
input.iterator.mkString(","))
)
// 打印结果
windowDs.print()
//获取侧道输出的数据
val lateCarWc: DataStream[CarWc] = windowDs.getSideOutput(outputTag)
lateCarWc.printToErr("侧道输出数据》》")
// 启动
env.execute()
flink state
state是什么?
state就是task/operator计算的中间结果,
无状态计算:相同的输入得到相同的结果,只根据输入的数据无需借助其他数据就可以计算出我想要的结果,
有状态计算:相同的输入得到的可能是不同的结果,计算过程会需要中间结果或者历史结果进行联合处理。

flink的wordcount 可以轻松实现累加效果,就是因为使用了state(keyed state)
flink中state的分类
从是否被flink框架管理:
1 manage state:flink框架帮我们管理,自动内存,序列化等,支持数据结构:value,list,map等 ,manage state 推荐使用
2 raw state:需要自己管理,序列化;byte[], 除非自定义operator时可以考虑使用该种state
从是否与key相关分类:
manage state :
keyed state:都是基于keyedstream,只有keyedstream可以使用,与key绑定;
operator state:是非keystream时候使用,与operator绑定
raw state:operator state

keyedstate
访问:getruntimecontext访问,要求operator是RichFunction;
数据结构:
valuestate:单一值, 是与key对应,我们无需关注key与state之间的映射关系,kv映射关系flink维护;
liststate:是一个列表结构, add:添加值;,遍历其中数据,get获取值
mapstate:状态值就是一个map结构,put,get,putall等
aggregationstate与reducingstate:存储的都是单值,但是需要提供一个reducefunciton aggregate策略,add添加数据之后其实得到的是之前定义function的计算结果。
operator state
访问:无需上下文
数据结构:
liststate,如果不能满足需求可以考虑自己定义一个operator state;
常见keyedstate 的api

value state案例

总结:使用valuestate可以帮助我们存储keyedstream中key对象的value数据,而且无需关心kv之间的映射。
状态使用:
1 定义一个描述器
2 获取一个状态
代码:
package cn.itcast.flink.state.keyedstate
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.state.ValueState, ValueStateDescriptor
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.scala.DataStream, KeyedStream, StreamExecutionEnvironment
import org.apache.flink.api.scala._
import org.apache.flink.configuration.Configuration
/*
使用ValueState保存中间结果对下面数据求出最大值
*/
object ValueStateDemo
def main(args: Array[String]): Unit =
/*
1.获取流处理执行环境
2.加载数据源 socke数据:k,v
3.数据分组
4.数据转换,定义ValueState,保存中间结果
5.数据打印
6.触发执行
*/
//1 创建流处理运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 默认程序并行度是机器的核数
env.setParallelism(1)
// 2 使用socket source
val socketDs: DataStream[String] = env.socketTextStream("node1", 9999)
// 3 keyed stream 使用keyby进行分组
val tupleDs: DataStream[(String, Int)] = socketDs.map(line =>
val arr: Array[String] = line.split(",")
//转为tuple类型
(arr(0), arr(1).trim.toInt)
)
// 3.1 分组
val keyStream: KeyedStream[(String, Int), Tuple] = tupleDs.keyBy(0)
// keyStream.maxBy(1)
// 使用valuestate来存储两两比较之后的最大值,新数据到来之后如果比原来的最大值还大则把该值更新为状态值,保证状态中一直存储的是最大值
//需要通过上下文件来获取keyedstate valuestate
val maxDs: DataStream[(String, Int)] = keyStream.map(
// 3.2 使用richfunction操作,需要通过上下文
new RichMapFunction[(String, Int), (String, Int)]
// 3.2.1 声明一个valuestate (不是创建) ,value state无需关心key是谁以及kv之间的映射,flink维护
var maxValueState: ValueState[Int] = _
// 3.3 通过上下文才能获取真正的state,上下文件这种操作在执行一次的方法中使用并获取真正的状态对象
override def open(parameters: Configuration): Unit =
// 3.3.1 定义一个state描述器 参数:state的名称,数据类型的字节码文件
val maxValueDesc: ValueStateDescriptor[Int] = new ValueStateDescriptor[Int]("maxValue", classOf[Int])
// 3.3.2 根据上下文基于描述器获取state
maxValueState = getRuntimeContext.getState<以上是关于flink学习day04:对Event Time 与 Watermark的理解的主要内容,如果未能解决你的问题,请参考以下文章