AWS DeepRacer 默认参数调优 实验一
Posted 架构师易筋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AWS DeepRacer 默认参数调优 实验一相关的知识,希望对你有一定的参考价值。
默认参数训练 60分钟,
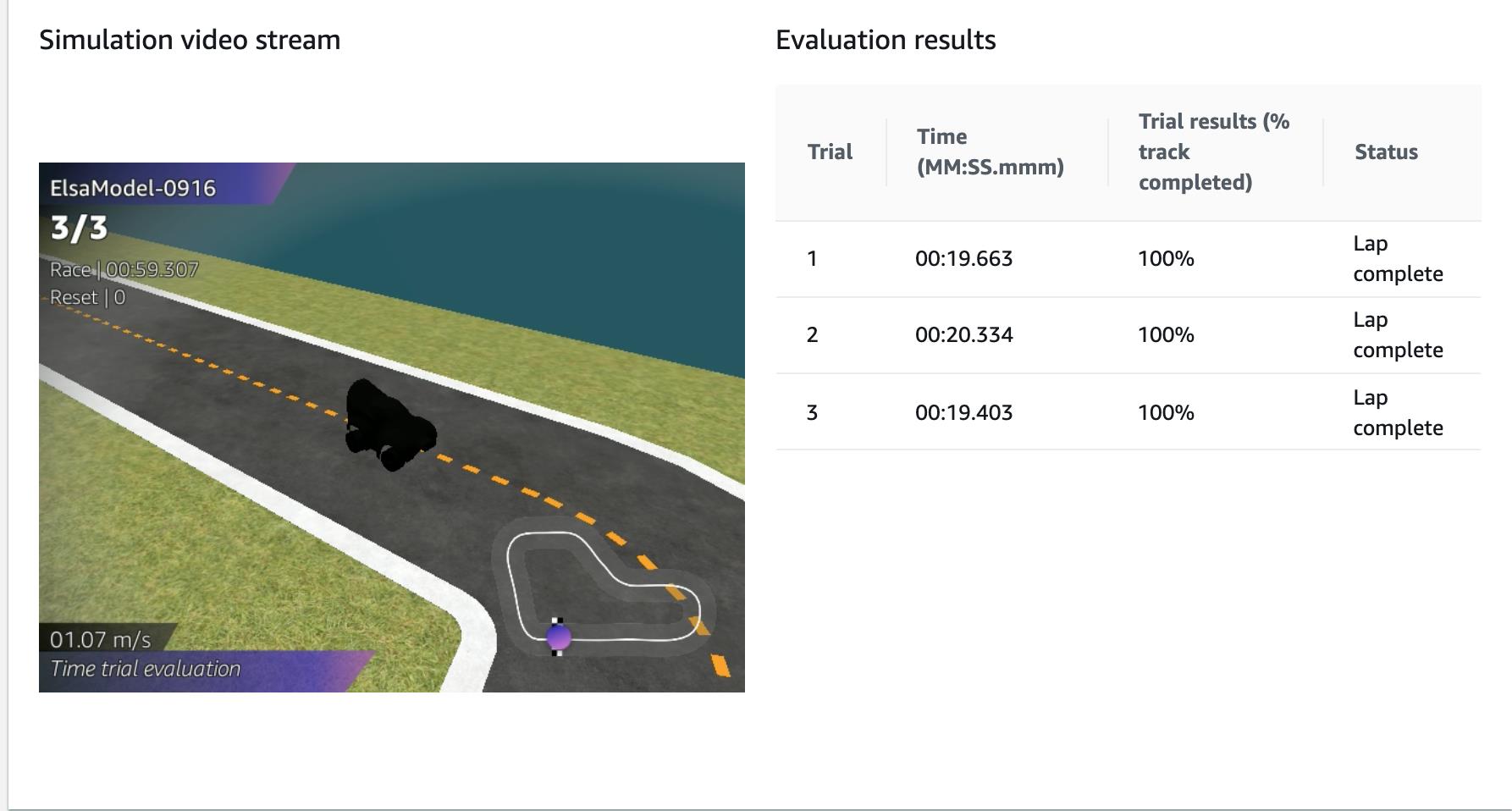
Evaluation Results
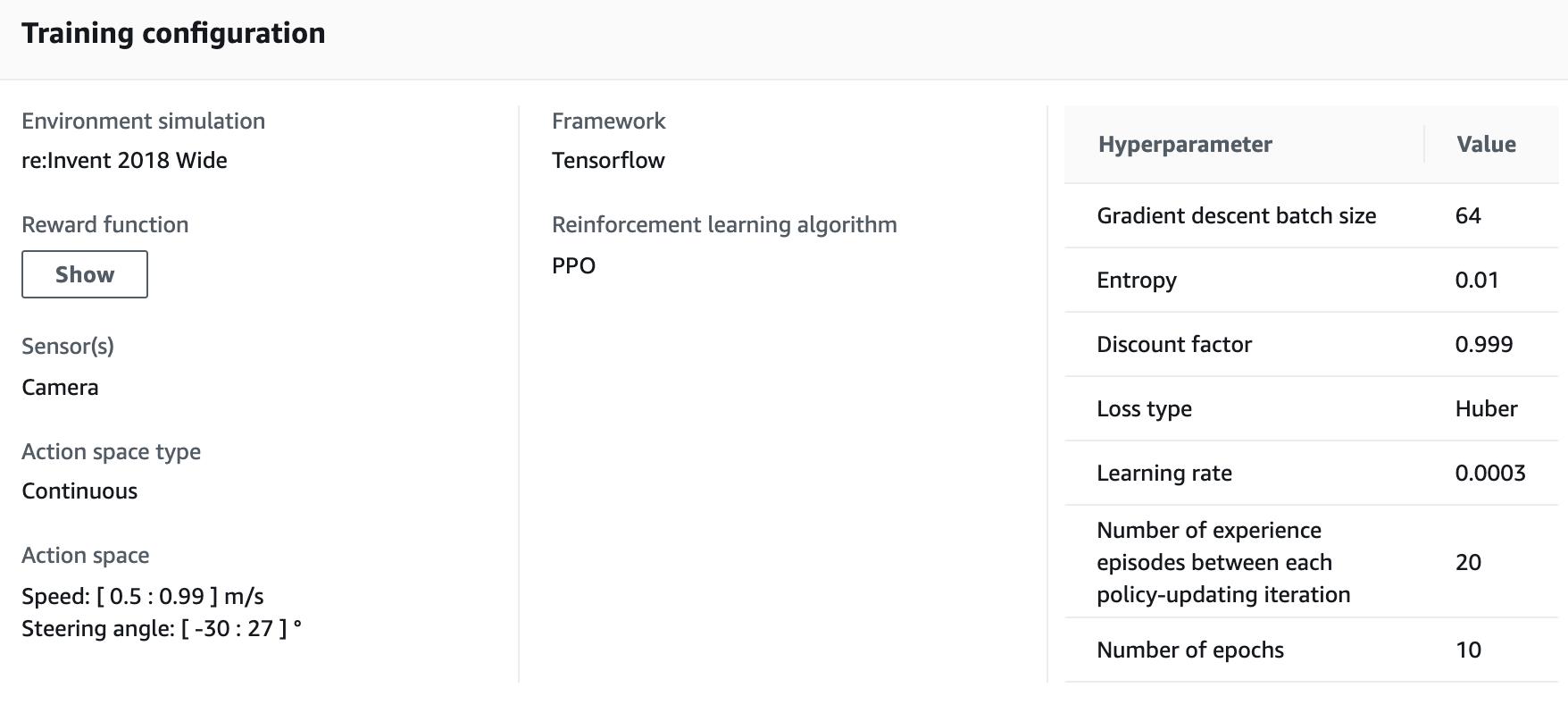
Reward function
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# Calculate 3 markers that are at varying distances away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward = 1.0
elif distance_from_center <= marker_2:
reward = 0.5
elif distance_from_center <= marker_3:
reward = 0.1
else:
reward = 1e-3 # likely crashed/ close to off track
return float(reward)
以上是关于AWS DeepRacer 默认参数调优 实验一的主要内容,如果未能解决你的问题,请参考以下文章
翻译: AWS DeepRacer一步一步详细步骤的自定义航点更快地运行 自定义waypoints
翻译: AWS DeepRacer一步一步详细步骤的自定义航点更快地运行 自定义waypoints