64位双系统Ubuntu 14.04 LTS + Caffe + CUDA 7.5 + Opencv 3.0 安装配置实战
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了64位双系统Ubuntu 14.04 LTS + Caffe + CUDA 7.5 + Opencv 3.0 安装配置实战相关的知识,希望对你有一定的参考价值。
一切的一切,开端便是这caffe,作为博客的第一篇文章,自然要讲讲一个哲学问题“我是从哪来的”
一、windows情况下安装双系统64位Ubuntu
本段落根据http://www.linuxidc.com/Linux/2014-04/100369p2.htm而成。
下面开始:
1)首先还是分区,在计算机上右键--管理--磁盘管理
装Ubuntu分配的硬盘大小最好是(20G以上)不要太小,配好整个环境就要消耗10G左右,再加上数据集和各种库,空间太小非常尴尬。这里请注意,Ubuntu和Windows文件系统完全不同,所以我们划好要给Ubuntu的分区后,删除卷。到时候,安装好的ubuntu的分区,在Windows下是看不到的,但是进入Ubuntu是可以访问Windows的磁盘的。
2)准备两个东西EasyBCD软件,百度官网有下,个人版免费
还需要准备好Ubuntu 14.04 的ISO镜像
3)下面打开EasyBCD软件,可以看到现在我们的计算机只有一个启动“入口”,我们来给他加一个,第一步选择添加新条目(添加移动入口点),
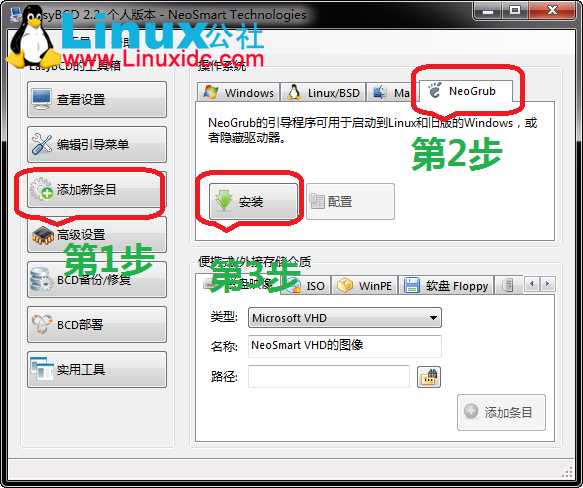
第2步选NeoGrub,第3步点安装点保存 ,接着是配置(第4步),
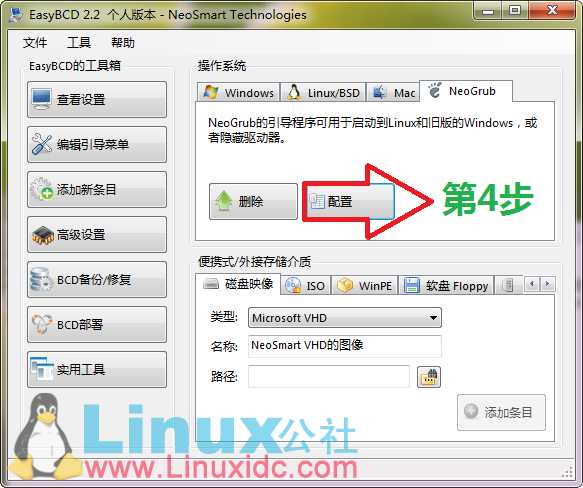
然后就会出现一个menu.lst文件

我们要编辑这个文件 因为系统就是这个文件找到我们的Ubuntu的。
把下面的英文复制进去,把原来的全覆盖掉
title Install Ubuntu root (hd0,0) kernel (hd0,0)/vmlinuz.efi boot=casper iso-scan/filename=/ubuntu-14.04.3-desktop-amd64.iso ro quiet splash locale=zh_CN.UTF-8 initrd (hd0,0)/initrd.lz
特别注意:
ubuntu-14.04.3-desktop-amd64.iso是iso的名字,考虑实际情况再行修改。
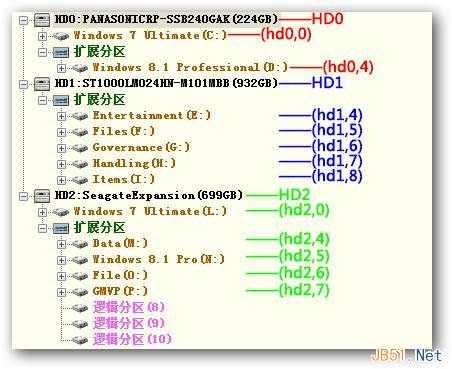
对于有的电脑上你的第一个盘符并不是C盘,在磁盘管理中可以看出,所以安装时需将(hd0,0)改为(hd0,1)【假设为第二个】。
注意:
(hd[n-1],[m-1]):表示的是第n块磁盘的第m个分区。通常MBR主引导的磁盘上允许最多4个主分区存在,所以一般来说【0=<m-1<4】表示主分区,而【4=<m-1】则表示逻辑分区。下图取自DiskGenius。
关闭保存。
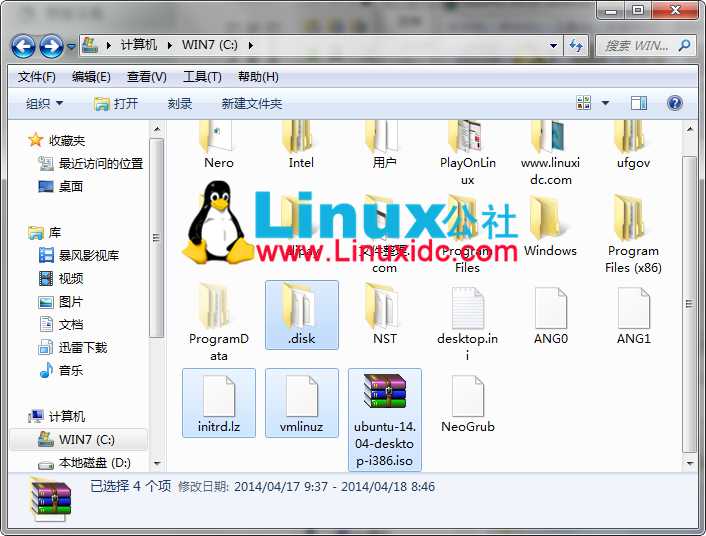
下面把准备好的Ubuntu镜像文件用压缩软件或者虚拟光驱打开,找到casper文件夹,把里面的initrd.lz和vmlinuz.efi解压到C盘,把.disk文件夹也解压到C盘,然后在把整个iso文件复制到C盘。
重启 你就会看到有2个 启动菜单给你选择,我们选择 NeoGrub 引导加载器 这个选项。

然后稍等待一段时间 就会见到我们想要安装的 Ubuntu了。

跟以前版本不一样的地方会出现一个键盘快捷键视图,就不再截图了。
默认 桌面有2个文档 一个是示例,我们选择 开始安装Ubuntu 14.04 LTS
记得在这之前 要按Ctrl+Alt+T 打开终端,输入代码:sudo umount -l /isodevice这一命令取消掉对光盘所在驱动器的挂载(注意,这里的-l是L的小写,-l 与 /isodevice 有一个空格),否则分区界面找不到分区。
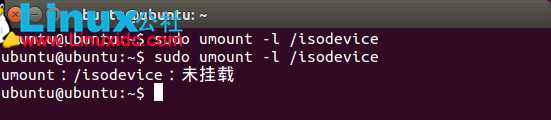
下面就点击 安装Ubuntu 14.04开始安装,选语言不用说,


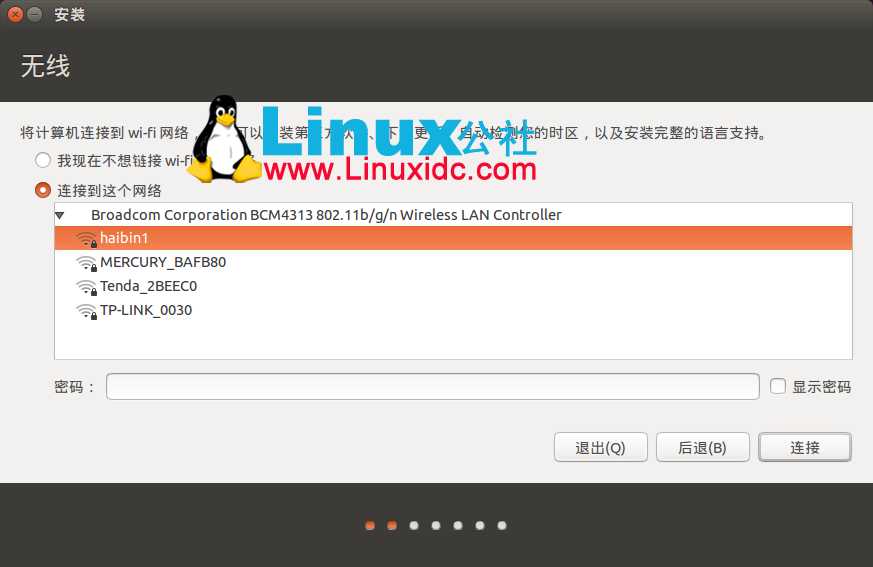
没插网线或者网络不通反正没有无线的时候不会有上面这一步。
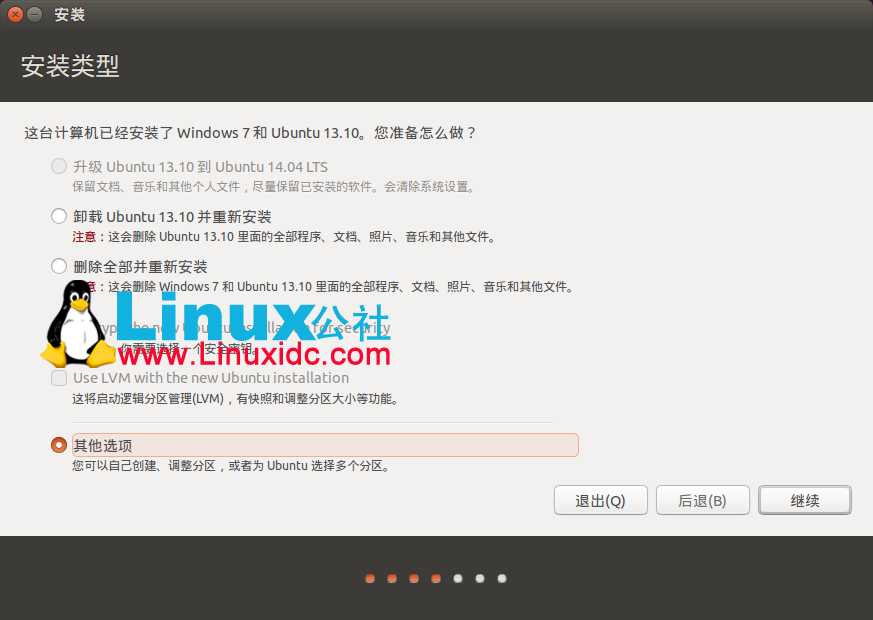
选安装类型,装双系统我们用其他选项。
接下来进入磁盘"分区"情况。这里安装 Ubuntu 的分区是上面我们腾出来的未定义分区(显示"空闲"状态)。上面"分区"加了引号,因为在 Linux 系统中,并没有硬盘分区这个概念,Linux 中取而代之的是文件概念,这个和 Windows 是有本质区别的。
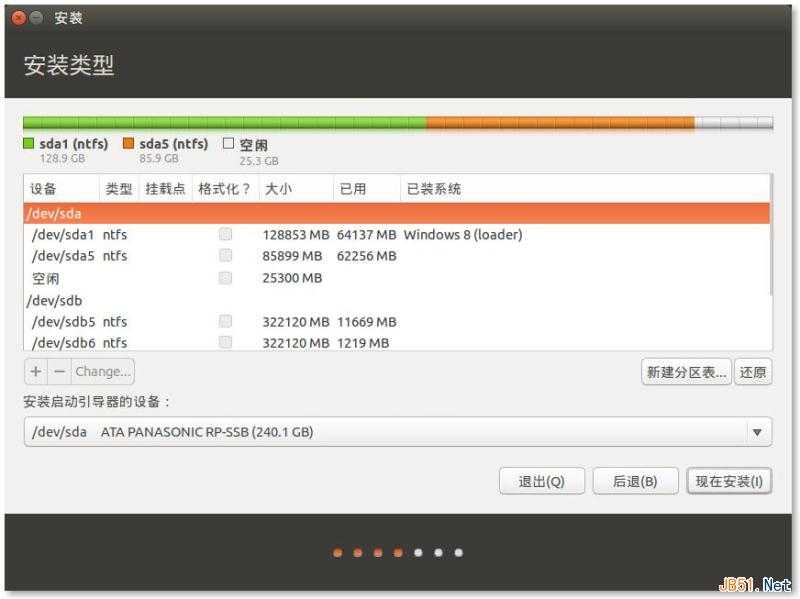
注意:
挂载点
在 Linux 系统里面,"分区"被称作"挂载点",简单明了的说,"挂载点"意思就是:
把一部分硬盘容量,"分"成一个文件夹的形式,用来干其他事情。这个文件夹的名字,就叫做:"挂载点"。所以,和Windows有着本质上的区别,你在任何 Linux 发行版系统里面,绝对不会看到C盘,D盘,E盘这样的,你能看到的,只有"文件夹"形式存在的"挂载点"。Linux 以目录的方式来组织和管理系统中的所有文件。
在Linux 系统里面,有一些已经定义好,用来干特定事情的挂载点,常见的"挂载点"有:
/boot:用于存储系统引导文件,也是 vmlinuz 核心的所在。
/ :就一个符号,表示根目录的意思。也是系统管理员root的目录。
/home:系统使用者的目录。用来存储用户程序、文件、文档等资源。
SWAP:严格来说,swap不是挂载点。它是一种虚拟内存交换分区,当你机子的物理内存用完之后,会动用这部分 swap 分区来当作虚拟内存使用。当然 swap 是硬盘上的空间,即使是 SSD,速度也不及物理内存快。如果希望快速度的话,不能寄厚望于 swap,最好是加大物理内存,swap 只是临时解决方法。物理内存在4G或以上的机子,可以不需要 swap 分区。但是如果你的 Linux 是用来做开发,需要一些诸如 oracle 这样的软件数据库,swap 还是必须保留的。
Linux 磁盘命名
磁盘设备在 Linux 环境下,均以文件夹命名,挂载在 /dev 设备目录下。
IDE 接口的硬盘,显示为:HD
SATA 或 SCSI 硬盘,显示为:SD。多个硬盘为:sda,sdb,sdc。
光驱,显示为:CDROM。多个光驱按数字排列:CDROM0,CDROM1,CDROM2。
硬盘分区,如第一块硬盘的第一个和第二个分区,分别显示为:sda1,sda2。
常见挂载点设置
SWAP:上面说过,物理内存在4G或以上的机子,可以不需要 swap 分区。但是如果你的 Linux 是用来做开发,需要一些诸如 oracle 这样的软件数据库,swap 还是必须保留的,给 1~2GB 足够了。
/ :如果是个人用,新手没必要分那么多分区,全部分一个根目录就行了。
/boot:不一定要分出来。看你把 Linux 的引导安装在那个设备。
如果是默认安装启动引导器的设备不更改(即/sda),则是用 GRUB 2 来引导系统的,每次开机均会先进入 Grub 2 引导界面供你选择 Ubuntu 或者 Windows,选择后者的话才进入 Windows 的 NT6.x 引导界面,因为装在 sda 里会改写 mbr 引导信息。这种情况是不需要单独分 /boot 出来的。
如果把 /boot 分了出来,建议大小为 100M~300M。安装启动引导器可以选择 / 或者 /boot 分区,但是这样一来,装完之后只能看见 Windows 的引导菜单,也只能启动 Windows,需要进入 Windows 中使用 EasyBCD 或者 Grub4DOS 等软件来添加 Ubuntu 启动项。
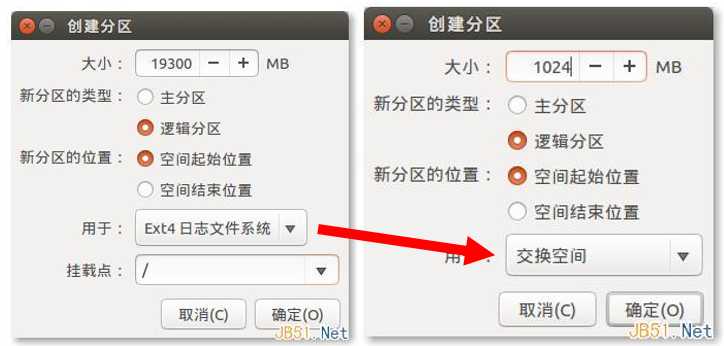
双击显示空闲的设备,弹出"创建分区"对话框,依次填写大小,选择分区类型,分区位置,以及文件系统和挂载点。分区挂载点顺序可以调换,但当有一个设为主分区后其后面的也会跟着默认为主分区,而逻辑分区则不会。建议全部设置为逻辑分区。
说了这么多,推荐分区的方案如下(以30G为例):——yy
/ 15G ext4(根分区可以大点,python库和cuda都在这)
SWAP 2G
/home 13G ext4(剩下的给/home,home要也适当大一点——yy)
设置好后,回到安装类型窗口,检查一下各分区和启动引导器的安装设备情况。
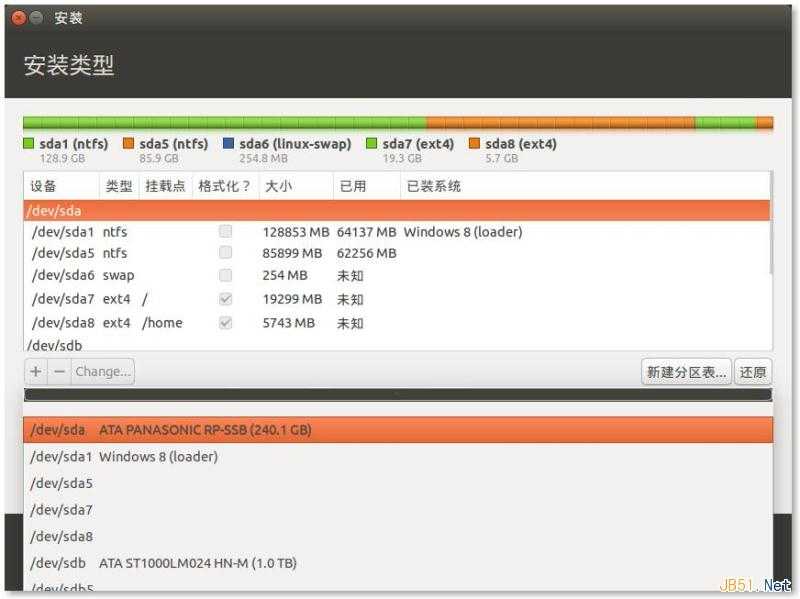
如无错误,点"现在安装"。如果没有分 swap 分区,会有一个提示如下图,点"继续"就好了。

有的说自动联网的,最好拔下网线,安装过程中会下载语言包等文件,会要一些时间,认为可以安装好后再下载,有空的就联网安装吧。这里选择不联网安装。
部分安装图:
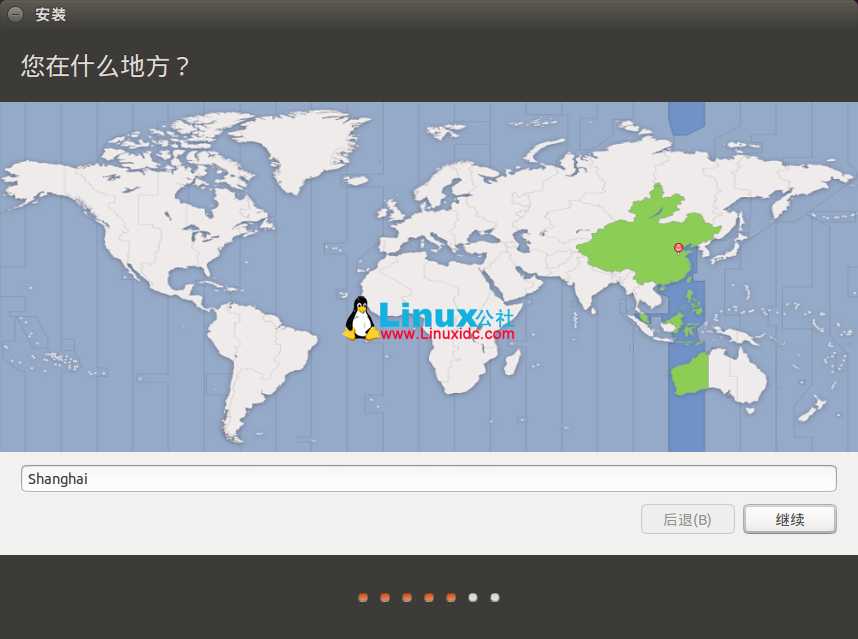
这里插着网线的时候按继续会停止响应,拔下网线可解决。——yy
下面的安装选择默认吧,不要改动什么(对菜鸟来说)。

点击 现在重启 即可。
如果没有按本教程做的,看看下面的一些情况,可能对你有帮助。
注意:
(1)在选择安装启动引导器的设备时,可以选择我们分好的 / 区,也可以新建一个/boot区。
(2)若重启就会发现原来 Windows进不去了。
打开终端输入命令
sudo gedit /etc/default/grub
修改GRUB_TIMEOUT="10"
然后在终端中输入sudo update-grub
update 命令会自动找到 windows 7 启动项。并且自动更新 /boot/grub/grub.cfg 文件。这样重启就能进windows了。
(3)最后进入Windows 7,打开EasyBCD删除安装时改的menu.lst文件,按Remove即可。
然后去我们的c盘 删除vmlinuz,initrd.lz和系统的iso文件。
利用EasyBCD可以更改启动项菜单按Edit Boot Menu按钮,可以选择将Windows7设为默认开机选项。
后续——yy
提供一些可能会有帮助的网址:
【Caffe搭建:常见问题解决办法和ubuntu使用中遇到问题(持续更新)】
【error while loading shared libraries的解決方法】
再推荐一些Linux上也能用得上的小程序:
Google Chrome
搜狗拼音
WPS office
二、Ubuntu入门
All by yy,以下想到哪写到哪。
到了Linux或者说Ubuntu,就要慢慢习惯使用命令行(cmd),命令行在Linux里称终端或者Terminal。Windows里拿鼠标点点点就能解决问题的情况一去不复返了。
1、先说文件结构。
上面在分区的时候已经提过,在Linux里没有分区的概念,取而代之成为了挂载点,换句话说不再有所谓的C盘D盘。
万物的源头叫做 / ,这个东西也称为根目录。
进一步叫 /home ,这个叫做主目录
再往下 /home/用户名/ ,从这里开始和“我的文档”有一定相似之处。
2、Terminal
直接Ctrl+Alt+T或者上搜索里搜终端出来的命令行一般是以 ~$ 结尾。
换句话说,~$ 成为了用户输入命令的开头。
以 $ 为界,前面为路径,后面为命令。
这里有两个特殊情况 ~就是/home,~/就是home/
/就是/ 就是根目录。
换句话说,除了有 ~$ 还有 /$ 表示命令的位置不同。
网上写的代码 $ 开头的命令只需要复制 $ 后面的命令就好,注意使用场合以及路径。
有的代码会专门写明 /$ 就是要去根目录下运行,也会有 ~$ 的现象
3、后续教程里没写的常用命令:
sudo 用超级用户身份执行,super user do,常用于各种“权限不足”“permission balabala”
dir 显示当前目录下的文件列表,有变体可以上网查
cd空格+目录 就是打开目录
特例 cd ~ 直接跳到/home
cd / 直接跳到/
cd .. 返回上一层
4、其他
# 多用于注释
Ctrl+Alt+F1~F6会黑屏进入tty界面,tty也是终端,一样的。+F7回到图形化界面。
5、最后,注意目录问题,多百度多谷歌,祝你顺利。
三、Ubuntu 14.04 LTS + Caffe + CUDA 7.5 + Opencv 3.0
这部分主要参照http://blog.csdn.net/mduanfire/article/details/50939210
Caffe 安装
根据我们前面的情况说明,我们现在机器上没有GPU,按照官网的Caffe官网安装教程,我们先一步步地进行,之后安装完GPU(CUDA)后再重新编译即可,不用担心。
(1) 安装依赖库(一)
$ sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler $ sudo apt-get install --no-install-recommends libboost-all-dev
(2) 安装BLAS
也可以安装OpenBLAS或者MKL,以加速CPU性能(有GPU的童鞋可以忽略),这里我按照官网装了BLAS,有兴趣的童鞋可以自己研究另外两种,只需在最后编译caffe的时候修改一下配置文件即可。(这里我推荐OpenBLAS——yy文件夹里有,照着readme来做就好,或者官网说明)
$ sudo apt-get install libatlas-base-dev
(3) Python安装
Ubuntu 14.04 自带Python 2.7 ,无需自行安装。可以自测:$ python,进入python环境后会有版本提示;如果未出现请使用如下命令进行安装:
$ sudo apt-get install python
(4). Opencv3.0安装
安装方法详见: ubuntu14.04 LTS系统中Opencv 3.0开发环境的搭建 ,Opencv必须安装,且版本需要大于2.4。—[来自官网说明]
以下为网页内容摘抄外加个人状况——yy
安装基本编译环境
$ sudo apt-get install build-essential
安装相关依赖库
$ sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev $ sudo apt-get install python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev
下载OpenCV 3.0
下载使用 wget 工具,解压使用 unzip, 如果没有安装,请使用如下代码安装:
$ sudo apt-get install wget $ sudo apt-get install unzip
$ mkdir ~/opencv # 新建opencv目录 $ cd opencv/ # 切换至opencv目录下 $ wget https://github.com/Itseez/opencv/archive/3.0.0-alpha.zip -O opencv-3.0.0-alpha.zip # 使用wget下载源码 $ unzip opencv-3.0.0-alpha.zip # 解压下载文件
安装OpenCV
$ cd ~/opencv/opencv-3.0.0-alpha # 切换至源码目录 $ cmake . # cmake+空格+”.” $ sudo make $ sudo make install $ sudo /bin/bash -c ‘echo "/usr/local/lib" > /etc/ld.so.conf.d/opencv.conf‘ $ sudo ldconfig
注:如果cmake过程中提示:ippicv_linux_20141027.tgz的hash码不对,则将下载的ippicv_linux_20141027.tgz手动复制到 opencv-3.0.0-beta/3rdparty/ippicv/downloads/linux-8b449a536a2157bcad08a2b9f266828b文件夹中,重新cmake即可
yy注:出现nvcc fatal : Unsupported gpu architecture ‘compute_11‘错看这里
http://blog.csdn.net/sysuwuhongpeng/article/details/45485719
CUDA_GENERATION=还就真的是开普勒 GTX650是GK107核心
于是使用:
$ cmake -D CUDA_GENERATION=Kepler . #注意这后面有个点
yy注:make过程超级慢。。。。。
yy注:error: a storage class is not allowed in an explicit specialization
参见http://www.cnblogs.com/platero/p/3993877.html
把 NCVPixelOperations.hpp放到
‘/home/yying/opencv/opencv-3.0.0-alpha/modules/cudalegacy/src/cuda/NCVPixelOperations.hpp‘
这里
这种问题多半是它报错的那个文件(右键gedit打开)那几行的static删掉就好了,后面还会错一次
yy注:make过程真的巨慢,而且很费空间,所以/home要大一点
编译samples程序
$ cd ~/opencv/opencv-3.0.0-alpha/samples # 切换至例程目录 $ cmake . # cmake+空格+”.” $ sudo make -j $(nproc) #(nproc)是进程数,根据计算机实际情况来定,一般电脑选4或8都可以
运行测试程序
$ cd ~/opencv/opencv-3.0.0-alpha/samples/cpp # 切换目录, 使用alpha版本,images在samples/cpp文件夹下 $ ./cpp-example-facedetect lena.jpg
运行结果,如图所示:
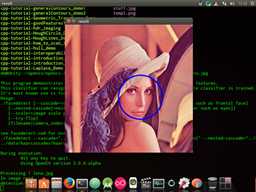
至此opencv就装好了。
(5) 安装依赖库(二)
$ sudo apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev
(6) Caffe下载
使用Git进行下载,直接从github上下载最新版本,下载前切换至home目录。注:git的使用方法可参看:我的vim配置(.vimrc:git+github管理) ,这篇文章内容进行安装配置。clone后在home中便可以找到Caffe的下载目录了。
$ cd $ git clone git://github.com/BVLC/caffe.git
(7) 编译Caffe前准备
<1>修改Makefile文件,最新版的Caffe已经帮我们修改好了,可以跳过;如果使用以前的版本则仍需要修改,这个可以自行Google。
<2>修改caffe/examples/cpp_classification/classification.cpp文件,加入:
#include <opencv2/imgproc/types_c.h>
#include <opencv2/objdetect/objdetect.hpp>
(8) 编译Caffe
$ cd ~/caffe $ cp Makefile.config.example Makefile.config # 修改Makefile.config文件:如果没有GPU,则去掉CPU_ONLY:= 1的注释 # 如果安装了Opencv3.0,去掉 OPENCV_VERSION := 3的注释 $ make all # 到这一步可能会出现,缺少cublas_v2.h的错误提示,先不用管,这时以下两步也不需要执行了,这是由于未安装cuda造成的。 $ make test $ make runtest
yy注:make 的过程中会有很多问题
缺gflag时
$ sudo apt-get install libgflags-dev
缺glog时,进入文件夹目录
$ ./configure $ make $ make install
还要修改caffe makefile.config里
带着波浪线的三行,修改完去掉#
# BLAS choice: # atlas for ATLAS (default) # mkl for MKL # open for OpenBlas BLAS := open~~~~~~~~~~~~~~~~~~~~ # Custom (MKL/ATLAS/OpenBLAS) include and lib directories. # Leave commented to accept the defaults for your choice of BLAS # (which should work)! # BLAS_INCLUDE := /path/to/your/blas~~~~~~~~ # BLAS_LIB := /path/to/your/blas~~~~~~~~~~
以上两项的路径为/opt/OpenBLAS/xxx里
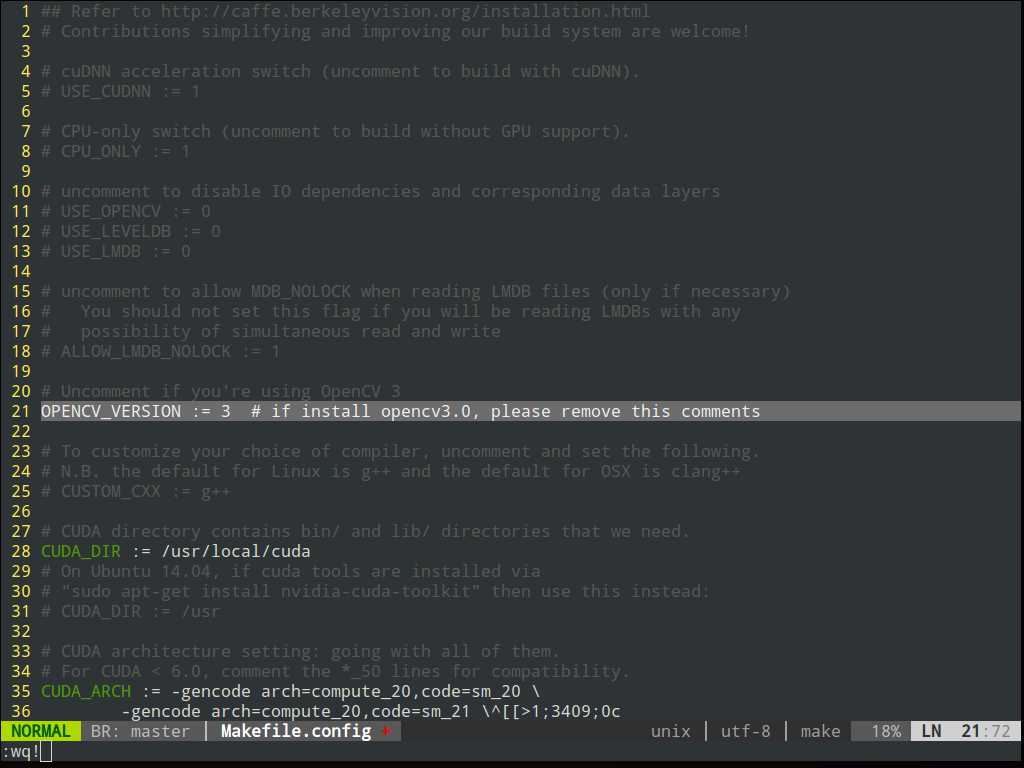
Nvidia显卡驱动及Cuda 7.5 的安装
如果你的机器还没有装GPU,请直接忽略这一步和cuDNN安装
(1) 验证你的gpu支持是否支持Cuda
打开支持Cuda运算的Gpu列表,只要你的GPU在里面找得到就没问题。
(2) 查看当前使用显卡
在终端输入以下命令,确认当前使用的是独立显卡,如果使用的是集显,则需要在开机时进入Bios关闭集显。
$ lspci | grep -i nvidia

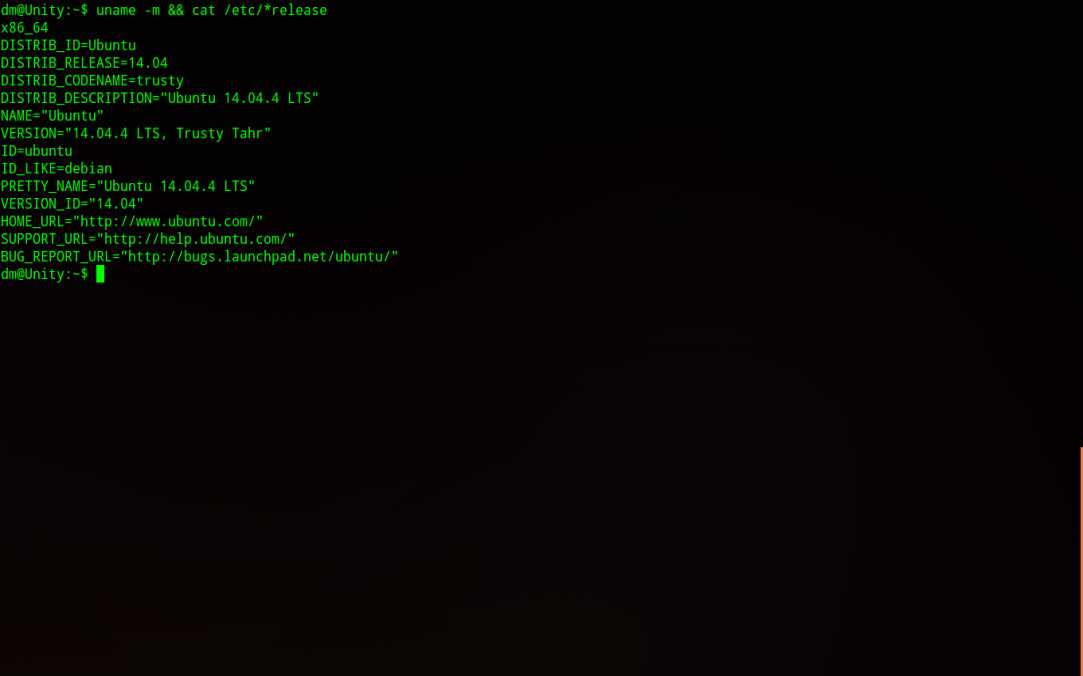
(3) 确认你的系统是X86架构,可通过下面的命令查询
$ uname -m && cat /etc/*release # 显示X86_64和系统信息即可
(4) 安装gcc
Ubuntu 14.04已经自带gcc 4.8.5,无需自行下载,检查gcc版本可通过如下方法:
$ gcc --version
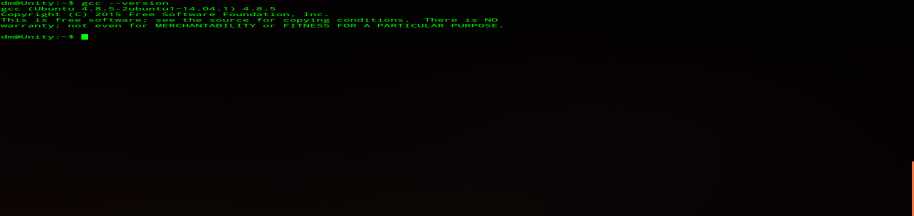
如果发现还没安装gcc,可以执行:$ sudo apt-get install gcc-版本号
(5) 下载Cuda
Cuda可以直接到Nvidia官网下载,下面官网的下载地址,有两种安装方式(.run 和 .deb),这里只介绍后者,因为比较简单易行。
这里选择下载信息如下图:
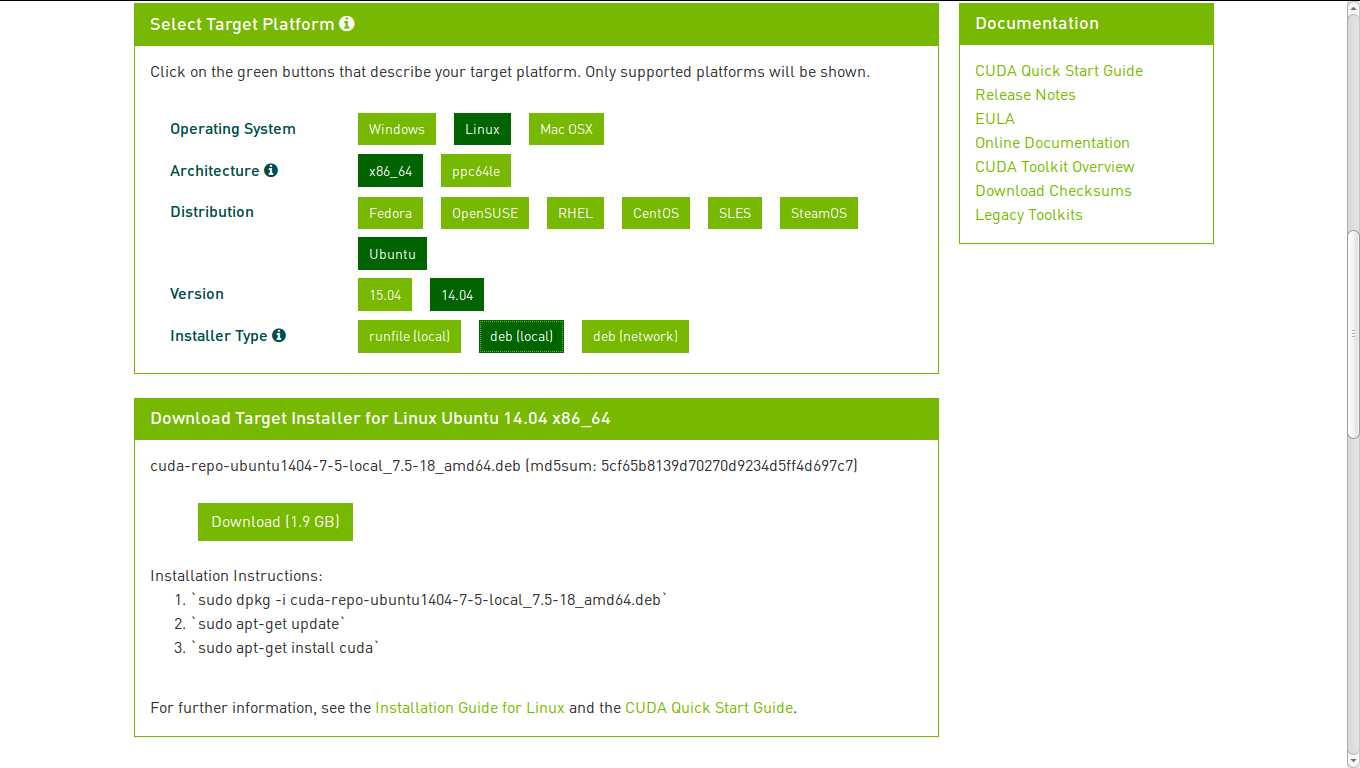
(6) 验证Cuda安装包(可跳过——yy)
$ md5sum 你的filename
如果下载没出错,那得到的MD5序列号和上图中是一致的,否则只能重新下载。
(7) 卸载旧版本Nvidia
根据官网介绍,之前安装的版本都会有冲突的嫌疑。卸载命令:
$ sudo apt-get --purge remove nvidia*
(8) 安装Cuda
cd切换至cuda安装包所在的目录,执行以下命令:
$ sudo dpkg -i cuda-repo-ubuntu1404-7-5-local_7.5-18_amd64.deb $ sudo apt-get update $ sudo apt-get install cuda
安装CUDA 装完重启——yy
(9) 添加环境变量
$ sudo vim /etc/profile # 在末尾添加(注意自己的Cuda版本,vim可以用gedit代替): export PATH=/usr/local/cuda-7.5/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda-7.5/lib64:$LD_LIBRARY_PATH $ source /etc/profile $ sudo reboot
(10) 安装例程
例程本来在/usr/local/cuda-7.5/samples路径下,但不可写,使用如下命令进行复制:
$ cuda-install-samples-7.5.sh ~/cuda
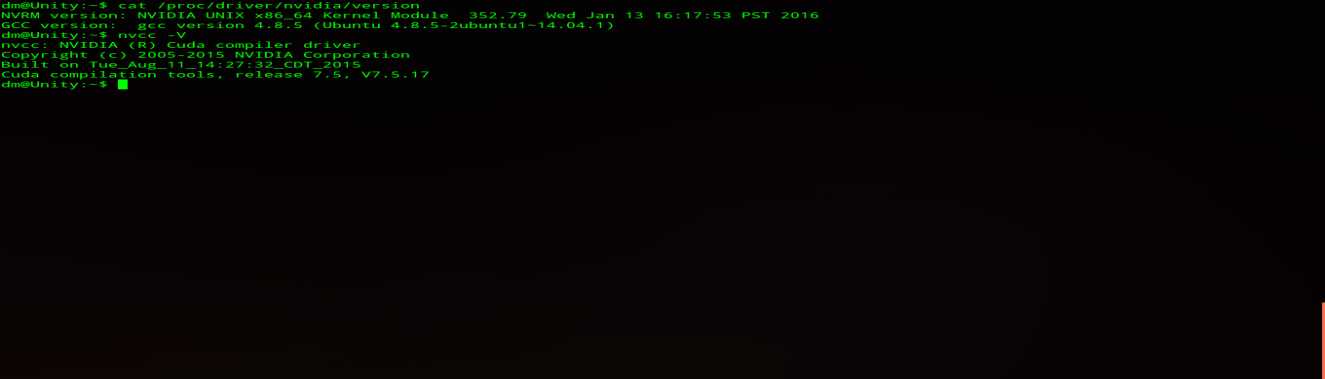
(11) 查看GPU驱动版本、Cuda版本:
正常安装的话,会出现版本信息,如果没出现说明安装出错,官网教程说的很清楚。
$ cat /proc/driver/nvidia/version $ nvcc -V
(12) 编译例程
cd进NVIDIA_CUDA-7.5_Samples中make:
$ cd ~/cuda/NVIDIA_CUDA-7.5_Samples $ make
编译结果在 ~/cuda/NVIDIA_CUDA-7.5_Samples/bin/x86_64/linux/release中
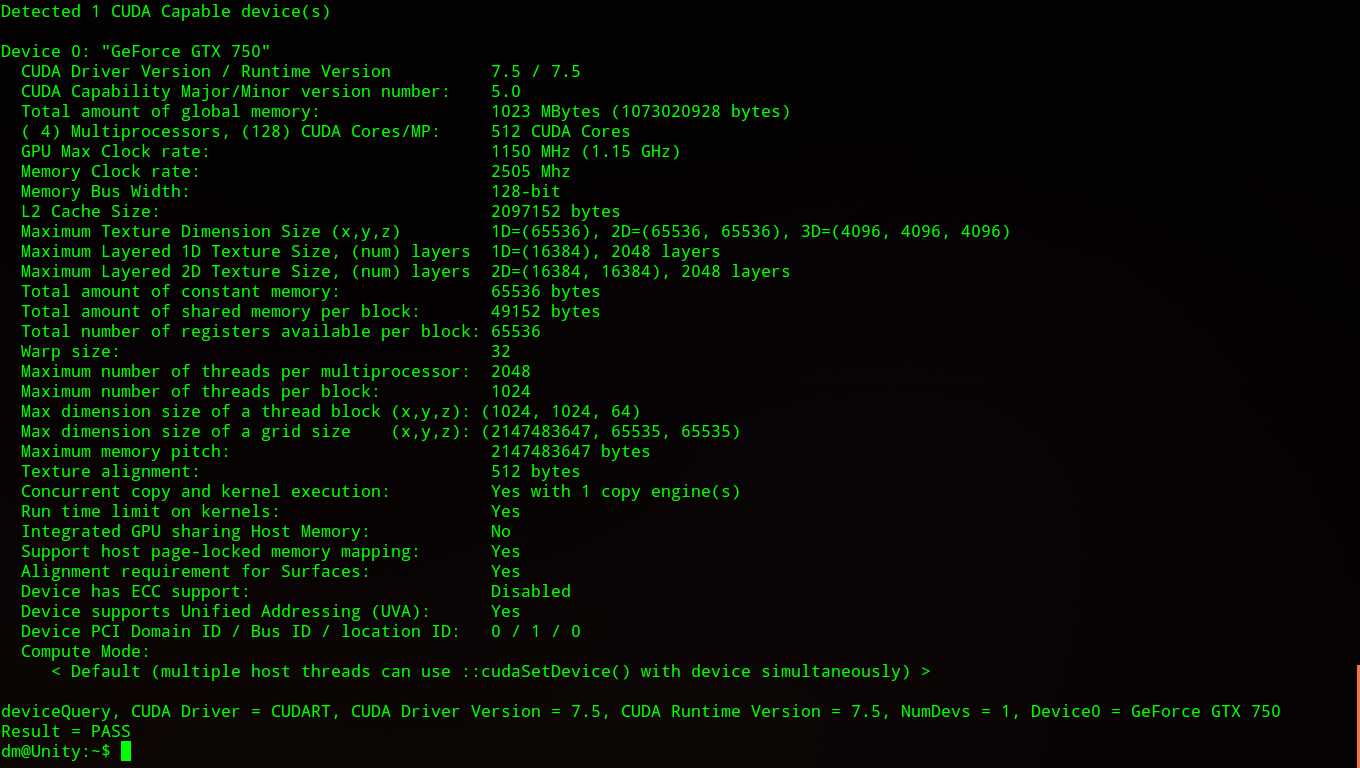
(13). 执行编译结果,确认安装配置
$ cd $ ./cuda/NVIDIA_CUDA-7.5_Samples/bin/x86_64/linux/release/deviceQuery
顺利的话如下图所示,若出错可参考此处
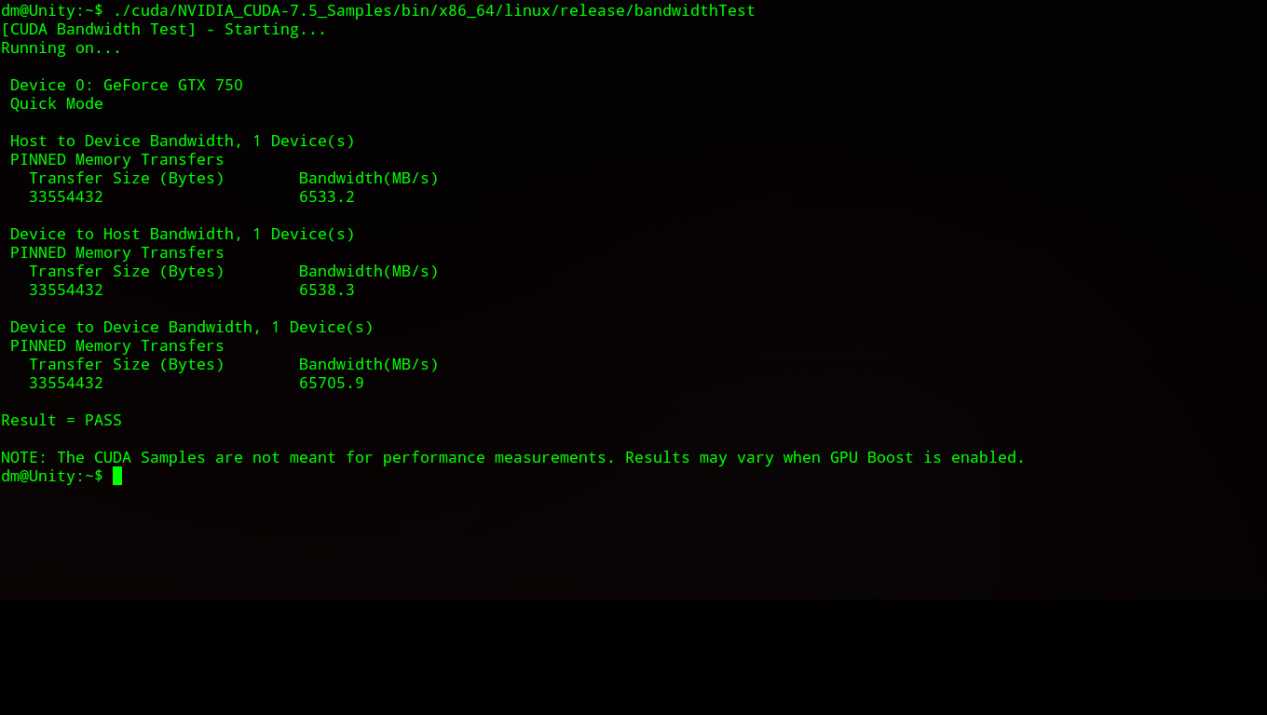
(14). bandwidthTest确认
$ ./cuda/NVIDIA_CUDA-7.5_Samples/bin/x86_64/linux/release/bandwidthTest
确认结果如下图所示则安装成功:
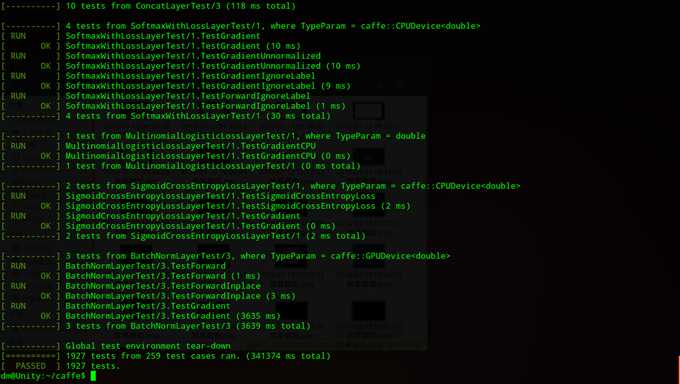
yy注:之前一上来就make了一次caffe,由于没有装cuda终止了,现在可以再次走一遍caffe的
$ make all $ make test $ make runtest
缺imdb.h的时候:
$ sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libboost-all-dev libhdf5-serial-dev libgflags-dev libgoogle-glog-dev liblmdb-dev protobuf-compiler
出现如下错误的时候:
CXX/LD -o .build_release/tools/convert_imageset.bin .build_release/lib/libcaffe.so: undefined reference to cv::imread(cv::String const&, int)’ .build_release/lib/libcaffe.so: undefined reference tocv::imencode(cv::String const&, cv::_InputArray const&, std::vector >&, std::vector > const&)’
原因就是opencv3.0.0把imread相关函数放到imgcodecs.lib中了,而非原来的imgproc.lib
解决办法:修改Makefile文件(不是Makefile.config):
在位置{ (LIBRARIES += glog gflags protobuf leveldb snappy lmdb boost_system hdf5_hl hdf5 m opencv_core opencv_highgui opencv_imgproc opencv_imgcodecs) }处添加opencv_imgcodecs
修复错误重新执行上述代码,成功后的截图如下所示:
配置pycaffe
(1) 安装依赖库
$ sudo apt-get install python-numpy python-scipy python-matplotlib python-sklearn python-skimage python-h5py python-protobuf python-leveldb python-networkx python-nose python-pandas python-gflags Cython ipython $ sudo apt-get install protobuf-c-compiler protobuf-compiler
(2) 编译
进入caffe目录,编译pycaffe
$ cd ~/caffe $ make pycaffe
(3) 修改环境变量
添加caffe目录下的python地址到 $PYTHONPATH
$ sudo gedit /etc/profile # 末尾添加: export PYTHONPATH = caffe目录下的python地址:$PYTHONPATH,用完整路径,不要用~ $ source /etc/profile # 使之生效
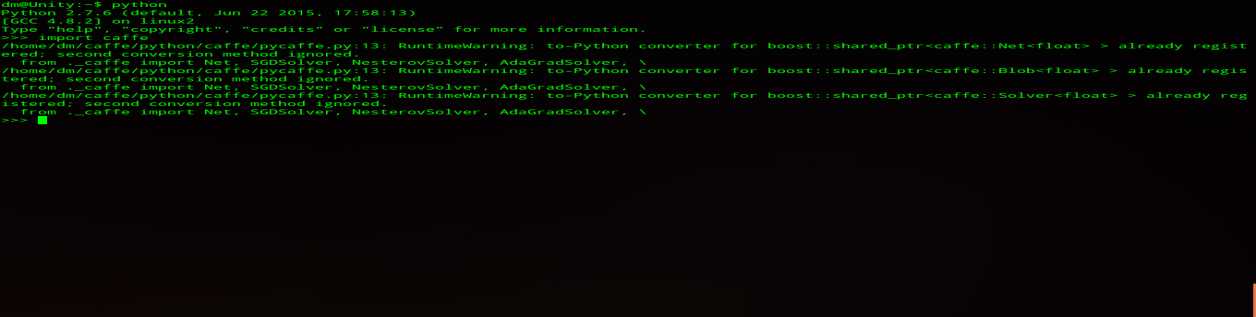
(4) 测试
在terminal进入python,import caffe 如果没错说明安装成功,效果如图:
yy注:你肯定也发现了,事情没有这么顺的。
报ImportError: No module named skimage.io
参照http://www.cnblogs.com/empty16/p/4828476.html
报ImportError: No module named scipy
$ sudo pip install scipy
报ImportError: No module named matplotlib
$ sudo pip install matplotlib
报ImportError: No module named google.protobuf.internal
$ sudo pip install protobuf
使用MNIST数据集进行测试
切换至caffe目录下,下面的工作主要是:用于测试Caffe是否工作正常,不做详细评估。具体设置请参考官网:MNIST数据集在Caffe中的测试 。
数据预处理
$ sh data/mnist/get_mnist.sh
重建lmdb/leveldb文件。Caffe支持三种数据格式输入网络,包括Image(.jpg, .png等),leveldb,lmdb,根据自己需要选择不同输入吧。
$ sh examples/mnist/create_mnist.sh
生成mnist-train-lmdb 和 mnist-train-lmdb文件夹,这里包含了lmdb格式的数据集
训练mnist
$ sh examples/mnist/train_lenet.sh
这时你会在终端窗口中看到caffe的训练过程
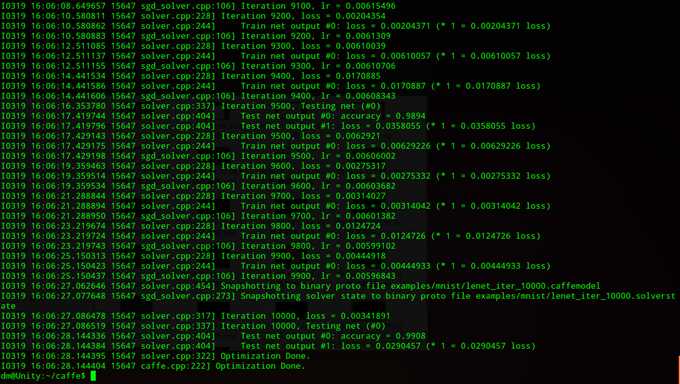
测试证明caffe应该可以用了,祝各位成功。
以上是关于64位双系统Ubuntu 14.04 LTS + Caffe + CUDA 7.5 + Opencv 3.0 安装配置实战的主要内容,如果未能解决你的问题,请参考以下文章
markdown 最安全的方法来清理启动分区 - Ubuntu 14.04LTS-x64,Ubuntu 16.04LTS-x64
ruby ubuntu / trusty64的最小Vagrantfile(14.04 LTS)
64位的ubuntu14.04 LTS安装 Linux交叉编译工具链及32位“ia32-libs”依赖库