Android音频API
Posted 涂程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Android音频API相关的知识,希望对你有一定的参考价值。
android系统提供了四个层面的音频API:
- Java层MediaRecorder&MediaPlayer系列;
- Java层AudioTrack&AudioRecorder系列;
- Jni层opensles;
- JNI层AAudio(Android O引入)
下面分别介绍这些API的使用及特点。
1. MediaRecorder&MediaPlayer
MediaRecorder与MediaPlayer并不能算完整意义的音频API,它们只是系统音频API的封装,除了采集/播放,他们集成了编码/解码、复用/解复用等能力。它们在最底层还是调用了AudioRecorder、AudioTrack。下面主要介绍它们的几个主要的配置项。
1.1 MediaRecorder
MediaRecorder因为已经集成了录音、压缩编码、封装复用等功能,所以使用起来相对比较简单。
MediaRecorder 使用起来相对简单,主要设置以下几项:
- 音源setAudiosource,系统提供的选项:
- AudioSource.DEFAULT:默认音频源;
- AudioSource.MIC:麦克风;
- AudioSource.VOICE_UPLINK:上行电话录音,android.Manifest.permission#CAPTURE_AUDIO_OUTPUT;
- AudioSource.VOICE_DOWNLINK:下行电话录音,android.Manifest.permission#CAPTURE_AUDIO_OUTPUT;
- AudioSource.VOICE_CALL:上下行电话录音,android.Manifest.permission#CAPTURE_AUDIO_OUTPUT;
- AudioSource.CAMCORDER:设定录音来源于同方向的相机麦克风相同,若相机无内置相机或无法识别,则使用预设的麦克风
- AudioSource.VOICE_RECOGNITION:用于语音识别;
- AudioSource.VOICE_COMMUNICATION:用于语音通话;
- AudioSource.UNPRECESSED:原始音频;
- AudioSource.VOICE_PERFORMANCE:低延迟用于满足实时音频处理;
- AudioSource.REMOTE_SUBMIX:用于传输系统混音的音频流到远端, android.Manifest.permission.CAPTURE_AUDIO_OUTPUT;
- AudioSource.ECHO_REFERENCE:回声抑制参考信号,SystemApi,android.Manifest.permission.CAPTURE_AUDIO_OUTPUT;
- AudioSource.RADIO_TUNER:电台广播声音,SystemApi;
- AudioSource.HOTWORD:抢占式的热词检测,SystemApi。
- 编码器setAudioEncoder
- Audio.Encoder.DEFAULT:
- Audio.Encoder.AMR_NB:
- Audio.Encoder.AMR_WB:
- Audio.Encoder.AAC:
- Audio.Encoder.HE_AAC:
- Audio.Encoder.AAC_ELD:4.1+
- Audio.Encoder.VORBIS:
- Audio.Encoder.OPUS:Android 10+
- 复用器setOutputFormat
- OutputFormat.DEFAULT
- OutputFormat.THREE_GPP:3GP;
- OutputFormat.MPEG_4:mp4;
- OutputFormat.RAW_AMR:.aac or .amr;
- OutputFormat.AMR_NB:amr nb;
- OutputFormat.AMR_WB:amr wb;
- OutputFormat.AAC_ADIF:aac adif;
- OutputFormat.AAC_ADTS:aac adts;
- OutputFormat.OUTPUT_FORMAT_RTP_AVP:网络流;
- OutputFormat.MPEG_2_TS:ts封装;
- OutputFormat.WEBM:webm 容器;
- OutputFormat.HEIF: heif容器;
- OutputFormat.OGG:ogg容器。
- 输出文件路径setOutputFile
示例代码:
MediaRecorder recorder = new MediaRecorder();
recorder.setAudioSource(MediaRecorder.AudioSource.MIC);
recorder.setOutputFormat(MediaRecorder.OutputFormat.THREE_GPP);
recorder.setAudioEncoder(MediaRecorder.AudioEncoder.AMR_NB);
recorder.setOutputFile(PATH_NAME);
recorder.prepare();
recorder.start(); // Recording is now started
...
recorder.stop();
recorder.reset(); // You can reuse the object by going back to setAudioSource() step
recorder.release(); // Now the object cannot be reused
上面代码只是基本使用方式,具体使用还需结合项目具体需求制定具体逻辑,但是MediaRecorder使用时需实例化,所以在不用时一定要记得即时释放,以免造成内存泄漏。
MediaRecorder状态图:
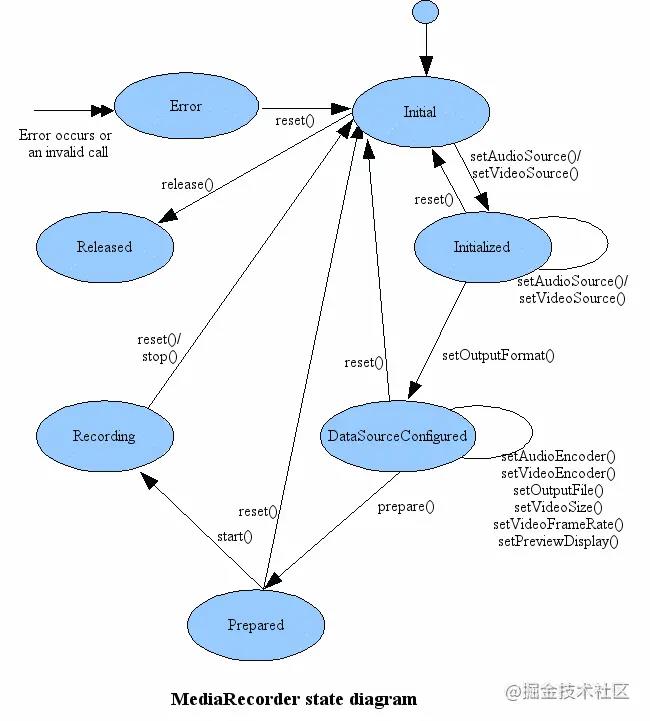
总结:MediaRecorder 实现录音比较简单的,代码量相对较少,较为简明,但也有不足之处,例如输出文件格式选择较少,录音过程不能暂停等。
1.2 MediaPlayer
MediaPlayer使用示例:
MediaPlayer mediaPlayer = new MediaPlayer();
if (android.os.Build.VERSION.SDK_INT >= android.os.Build.VERSION_CODES.LOLLIPOP) {
AudioAttributes audioAttributes = new AudioAttributes.Builder()
.setUsage(AudioAttributes.USAGE_ALARM)
.setContentType(AudioAttributes.CONTENT_TYPE_SPEECH)
.build();
mediaPlayer.setAudioAttributes(audioAttributes);
} else {
mediaPlayer.setAudioStreamType(AudioManager.STREAM_ALARM);
}
mediaPlayer.reset();
mediaPlayer.setOnCompletionListener(new MediaPlayer.OnCompletionListener() {
@Override
public void onCompletion(MediaPlayer mp) {
// 播放完成
}
});
mediaPlayer.setDataSource(path);
mediaPlayer.prepare();
mediaPlayer.start();
//or mediaPlayer.prepareAsync()并在setOnPreparedListener(android.media.MediaPlayer.OnPreparedListener)设置的回调中start
1.2.1 状态图:
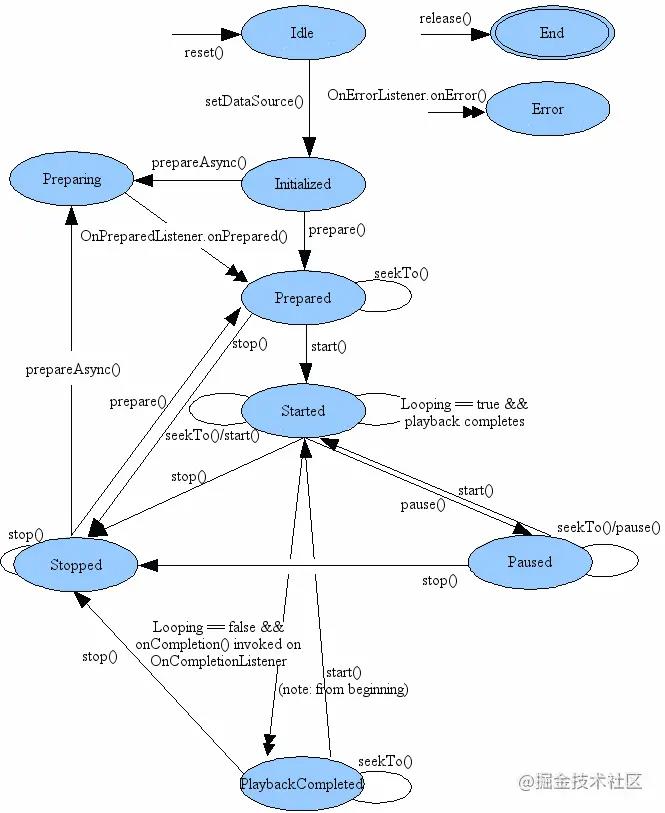
1.2.2setAudioStreamType提供的选项:
- AudioSystem.STREAM_VOICE_CALL:电话通话;
- AudioSystem.STREAM_SYSTEM:系统声音;
- AudioSystem.STREAM_RING:电话响铃声;
- AudioSystem.STREAM_MUSIC:音乐播放;
- AudioSystem.STREAM_ALARM:闹钟;
- AudioSystem.STREAM_NOTIFICATION:通知
AudioAttributes用来替代stream types,它可以设置比stream types更多的属性,有三个方面:
- usage(why):为什么要播放这个声音?
- content type(what):播放的内容是什么?是可选项,有些usage,比如CONTENT_TYPE_MOVIE是movie usage。
- flags(how):如何影响播放。
1.2.3 setDataSource说明
setDataSource设置播放源,可以是本地文件也可以是网络文件。如果是网络文件和本地比较大的文件,在主线程中调用prepare可能会导致ANR,所以尽量用prepareAsync,然后再onPrepared回调中调用start。
2. AudioRecorder&AudioTrack
2.1 AudioRecorder
AndioRecord 类的主要功能是让各种 Java 应用能够管理音频资源,以便它们通过此类能够录制平台的声音输入硬件所收集的声音。它的实现就是通过 “pulling 同步”(reading读取)AudioRecord 对象的声音数据来完成的。在录音过程中,应用所需要做的就是通过后面三个类方法中的一个去及时地获取 AudioRecord 对象的录音数据。 AudioRecord 类提供的三个获取声音数据的方法分别是 read(byte[], int, int), read(short[], int, int), read(ByteBuffer, int)。无论选择使用哪一个方法都必须事先设定方便用户的声音数据的存储格式。
开始录音的时候,一个 AudioRecord 需要初始化一个相关联的声音buffer,这个 buffer 主要是用来保存新的声音数据。这个 buffer 的大小,我们可以在对象构造期间去指定。它表明一个 AudioRecord 对象还没有被读取(同步)声音数据前能录多长的音(即一次可以录制的声音容量)。声音数据从音频硬件中被读出,数据大小不超过整个录音数据的大小(可以分多次读出),即每次读取初始化 buffer 容量的数据。
采集工作很简单,我们只需要构造一个AudioRecord对象,然后传入各种不同配置的参数即可。一般情况下录音实现的简单流程如下:
- 音频源:我们可以使用麦克风作为采集音频的数据源,可选参数跟MediaRecorder一致。
- 采样率:一秒钟对声音数据的采样次数,采样率越高,音质越好。
- 音频通道:单声道,双声道等,
- 音频格式:一般选用PCM格式,即原始的音频样本。
- 缓冲区大小:音频数据写入缓冲区的总数,可以通过AudioRecord.getMinBufferSize获取最小的缓冲区。(将音频采集到缓冲区中然后再从缓冲区中读取)。
代码实现如下:
public class AudioRecorder {
//音频输入-麦克风
private final static int AUDIO_INPUT = MediaRecorder.AudioSource.MIC;
//采用频率
//44100是目前的标准,但是某些设备仍然支持22050,16000,11025
//采样频率一般共分为22.05KHz、44.1KHz、48KHz三个等级
private final static int AUDIO_SAMPLE_RATE = 16000;
//声道 单声道
private final static int AUDIO_CHANNEL = AudioFormat.CHANNEL_IN_MONO;
//编码
private final static int AUDIO_ENCODING = AudioFormat.ENCODING_PCM_16BIT;
public void createDefaultAudio() {
// 获得缓冲区字节大小
int bufferSizeInBytes = AudioRecord.getMinBufferSize(AUDIO_SAMPLE_RATE,
AUDIO_CHANNEL, AUDIO_ENCODING);
AudioRecord audioRecord = new AudioRecord(AUDIO_INPUT, AUDIO_SAMPLE_RATE, AUDIO_CHANNEL, AUDIO_ENCODING, bufferSizeInBytes);
audioRecord.startRecording();
new Thread(new Runnable() {
@Override
public void run() {
readsize = audioRecord.read(audiodata, 0, bufferSizeInBytes);
if (AudioRecord.ERROR_INVALID_OPERATION != readsize) {
//handle audio data
}
}
}).start();
}
}
2.2 AudioTrack
AudioTrack是Java层管理和播放单个音频资源提供的接口。它用来播放PCM原始数据。通过使用write(byte[], int, int)、write(short[], int, int)和write(float[], int, int, int)方法之一写入数据实现播放。AudioTrack实例可以在两种模式下运行:静态模式或流模式。
-
在流模式下,应用程序使用write()方法之一将连续的数据流写入AudioTrack。当数据从Java层传输到native层并排队等待播放时,它们会阻塞并返回。当播放音频数据块时,流式模式是最有用的,例如:因为声音播放的时间太长,所以内存无法容纳;由于音频数据的特性(高采样率,每次采样的比特数…);在播放之前排队的音频时接收或生成。
-
静态模式用于处理适合内存且需要以最小延迟播放的短声音场景。因此,静态模式将更适合UI和游戏声音,并尽可能减少开销。
创建AudioTrack对象时,初始化其关联的音频缓冲区。在构造过程中指定的这个缓冲区的大小决定了AudioTrack在耗尽数据之前可以播放多长时间。对于使用静态模式的AudioTrack,此大小是它可以播放的声音的最大大小。对于流模式,数据将以小于或等于总缓冲区大小的块写入音频接收器。AudioTrack不是final的,因此允许使用子类,但不建议这样使用。
静态模式播放示例:
AudioAttributes audioAttributes = new AudioAttributes.Builder()
.setUsage(AudioAttributes.USAGE_MEDIA)
.setContentType(AudioAttributes.CONTENT_TYPE_MUSIC)
.build();
AudioFormat auidoFormat = new AudioFormat.Builder().setSampleRate(22050)
.setEncoding(AudioFormat.ENCODING_PCM_8BIT)
.setChannelMask(AudioFormat.CHANNEL_OUT_MONO)
.build();
AudioTrack audioTrack = new AudioTrack(audioAttributes,auidoFormat,audioData.length,AudioTrack.MODE_STATIC,
AudioManager.AUDIO_SESSION_ID_GENERATE);
audioTrack.write(audioData, 0, audioData.length);
if(audioTrack.getState() == AudioTrack.STATE_UNINITIALIZED){
Toast.makeText(this,"AudioTrack初始化失败!",Toast.LENGTH_SHORT).show();
return;
}
audioTrack.play();
流模式播放示例:
// ************ 流播放 ************
final int minBufferSize = AudioTrack.getMinBufferSize(SAMPLE_RATE_INHZ, AudioFormat.CHANNEL_OUT_MONO, AUDIO_FORMAT);
AudioAttributes audioAttributes = new AudioAttributes.Builder()
.setUsage(AudioAttributes.USAGE_MEDIA)
.setContentType(AudioAttributes.CONTENT_TYPE_MUSIC)
.build();
AudioFormat auidoFormat = new AudioFormat.Builder().setSampleRate(22050)
.setEncoding(AudioFormat.ENCODING_PCM_8BIT)
.setChannelMask(AudioFormat.CHANNEL_OUT_MONO)
.build();
audioTrack = new AudioTrack(audioAttributes,auidoFormat,minBufferSize,AudioTrack.MODE_STREAM,AudioManager.AUDIO_SESSION_ID_GENERATE);
// 检查初始化是否成功
if(audioTrack.getState() == AudioTrack.STATE_UNINITIALIZED){
Toast.makeText(this,"AudioTrack初始化失败!",Toast.LENGTH_SHORT).show();
return;
}
// 播放
audioTrack.play();
//子线程中文件流写入
workHandler.post(new Runnable() {
@Override
public void run() {
try {
final File file = new File(getExternalFilesDir(Environment.DIRECTORY_MUSIC), "test.pcm");
FileInputStream fileInputStream = new FileInputStream(file);
byte[] tempBuffer = new byte[minBufferSize];
while (fileInputStream.available() > 0) {
int readCount = fileInputStream.read(tempBuffer);
if (readCount == AudioTrack.ERROR_INVALID_OPERATION ||
readCount == AudioTrack.ERROR_BAD_VALUE) {
continue;
}
if (readCount != 0 && readCount != -1) {
audioTrack.write(tempBuffer, 0, readCount);
}
}
fileInputStream.close();
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
});
3. OpenSL ES
OpenSL ES (Open Sound Library for Embedded Systems)是无授权费、跨平台、针对嵌入式系统精心优化的硬件音频加速API。它为嵌入式移动多媒体设备上的本地应用程序开发者提供标准化, 高性能,低响应时间的音频功能实现方法,并实现软/硬件音频性能的直接跨平台部署,降低执行难度,促进高级音频市场的发展。简单来说OpenSL ES是一个嵌入式跨平台免费的音频处理库。 iOS未暴露OpenSL ES接口,Android的OpenSL ES库是在NDK的platforms文件夹对应android平台先相应cpu类型里面:
$ ls ~/Library/Android/ndk/ndk-bundle/android-ndk-r17c/platforms/android-28/arch-arm/usr/lib/
crtbegin_dynamic.o libGLESv3.so libcompiler_rt-extras.a libnativewindow.so
crtbegin_so.o libOpenMAXAL.so libdl.a libneuralnetworks.so
crtbegin_static.o libOpenSLES.so libdl.so libstdc++.a
crtend_android.o libaaudio.so libjnigraphics.so libstdc++.so
crtend_so.o libandroid.so liblog.so libsync.so
libEGL.so libc.a libm.a libvulkan.so
libGLESv1_CM.so libc.so libm.so libz.a
libGLESv2.so libcamera2ndk.so libmediandk.so libz.so
Android 2.3 (API 9) 即开始支持 OpenSL ES 标准了,通过 NDK 提供相应的 API 开发接口(参考:source.android.com/devices/aud… 实现的 OpenSL ES 只是 OpenSL 1.0.1 的子集,并且进行了扩展,因此,对于 OpenSL ES API 的使用,我们还需要特别留意哪些是 Android 支持的,哪些是不支持的,具体相关文档的地址位于 NDK docs 目录下:
NDKroot/docs/Additional_library_docs/opensles/index.html
NDKroot/docs/Additional_library_docs/opensles/OpenSL_ES_Specification_1.0.1.pdf
OpenSL ES 有两个必须理解的概念,就是 Object 和 Interface,Object 可以想象成 Java 的 Object 类,Interface 可以想象成 Java 的 Interface,但它们并不完全相同,其实就是为了用面向过程的语言实现面向对象的接口,下面进一步解释他们的关系: (1) 每个 Object 可能会存在一个或者多个 Interface,官方为每一种 Object 都定义了一系列的 Interface (2)每个 Object 对象都提供了一些最基础的操作,比如:Realize,Resume,GetState,Destroy 等等,如果希望使用该对象支持的功能函数,则必须通过其 GetInterface 函数拿到 Interface 接口,然后通过 Interface 来访问功能函数 (3)并不是每个系统上都实现了 OpenSL ES 为 Object 定义的所有 Interface,所以在获取 Interface 的时候需要做一些选择和判断
3.1 常用的对象和结构体
在 OpenSL ES 中,一切 API 的访问和控制都是通过 Interface 来完成的,连 OpenSL ES 里面的 Object 也是通过 SLObjectItf Interface 来访问和使用的。
3.1.1 Engine Object 和 SLEngineItf Interface
OpenSL ES 里面最核心的对象就是:Engine Object,音频引擎对象,它主要提供如下两个功能:
(1)管理 Audio Engine 的生命周期
(2)提供管理接口: SLEngineItf,该接口可以用来创建所有其他的 Object 对象
(3)提供设备属性查询接口:SLEngineCapabilitiesItf 和 SLAudioIODeviceCapabilitiesItf,这些接口可以查询设备的一些属性信息
Engine Object 对象的创建方法如下:
SLObjectItf engineObject;
slCreateEngine( &engineObject, 0, nullptr, 0, nullptr, nullptr );1.2.
初始化/销毁:
(*engineObject)->Realize(engineObject, SL_BOOLEAN_FALSE);(*engineObject)->Destroy(engineObject);1.2.
获取管理接口:
SLEngineItf engineEngine;(*engineObject)->GetInterface(engineObject, SL_IID_ENGINE, &(engineEngine));1.2.
SLObjectItf结构定义:
struct SLObjectItf_ { SLresult (*Realize) (SLObjectItf self,SLboolean async); SLresult (*Resume) (SLObjectItf self,SLboolean async); SLresult (*GetState) (SLObjectItf self,SLuint32 * pState); SLresult (*GetInterface) (SLObjectItf self, const SLInterfaceID iid, void * pInterface); SLresult (*RegisterCallback) (SLObjectItf self, slObjectCallback callback, void * pContext); void (*AbortAsyncOperation) (SLObjectItf self); void (*Destroy) (SLObjectItf self); SLresult (*SetPriority) (SLObjectItf self, SLint32 priority, SLboolean preemptable); SLresult (*GetPriority) (SLObjectItf self, SLint32 *pPriority, SLboolean *pPreemptable); SLresult (*SetLossOfControlInterfaces) (SLObjectItf self, SLint16 numInterfaces, SLInterfaceID * pInterfaceIDs, SLboolean enabled);};typedef const struct SLObjectItf_ * const * SLObjectItf;
这里的SLObjectItf是一个二级指针,它指向的是一个结构体指针。任何创建出来的Object都必须调用 Realize 方法做初始化,在不需要的时候可以使用 Destroy 方法来释放资源。
下面我们就可以使用 engineEngine 来创建所有 OpenSL ES 的其他对象了。
3.1.2 Media Object
OpenSL ES 里面另一组比较重要的对象就是 Media Object ,代表着多媒体功能的抽象,比如:player、recorder 等等。
我们可以通过 SLEngineItf 提供的 CreateAudioPlayer 方法来创建一个 player 对象实例,可以通过 SLEngineItf 提供的 CreateAudioRecorder 方法来创建一个 recorder 实例。
3.1.3 Data Source 和 Data Sink
OpenSL ES 里面,这两个结构体均是作为创建 Media Object 对象时的参数而存在的,data source 代表着输入源的信息,即数据从哪儿来、输入的数据参数是怎样的;而 data sink 则代表着输出的信息,即数据输出到哪儿、以什么样的参数来输出。
Data Source 的定义如下:
typedef struct SLDataSource_ { void *pLocator; void *pFormat;} SLDataSource;1.2.3.4.
Data Sink 的定义如下:
typedef struct SLDataSink_ { void *pLocator; void *pFormat;} SLDataSink;1.2.3.4.
其中,pLocator 主要有如下几种:
SLDataLocator_AddressSLDataLocator_BufferQueueSLDataLocator_IODeviceSLDataLocator_MIDIBufferQueueSLDataLocator_URI1.2.3.4.5.
也就是说,Media Object 对象的输入源/输出源,既可以是 URL,也可以 Device,或者来自于缓冲区队列等等,完全是由 Media Object 对象的具体类型和应用场景来配置。
3.2 状态机制
OpenSL ES 还有一个比较重要的概念,就是它的状态机制,如图所示:
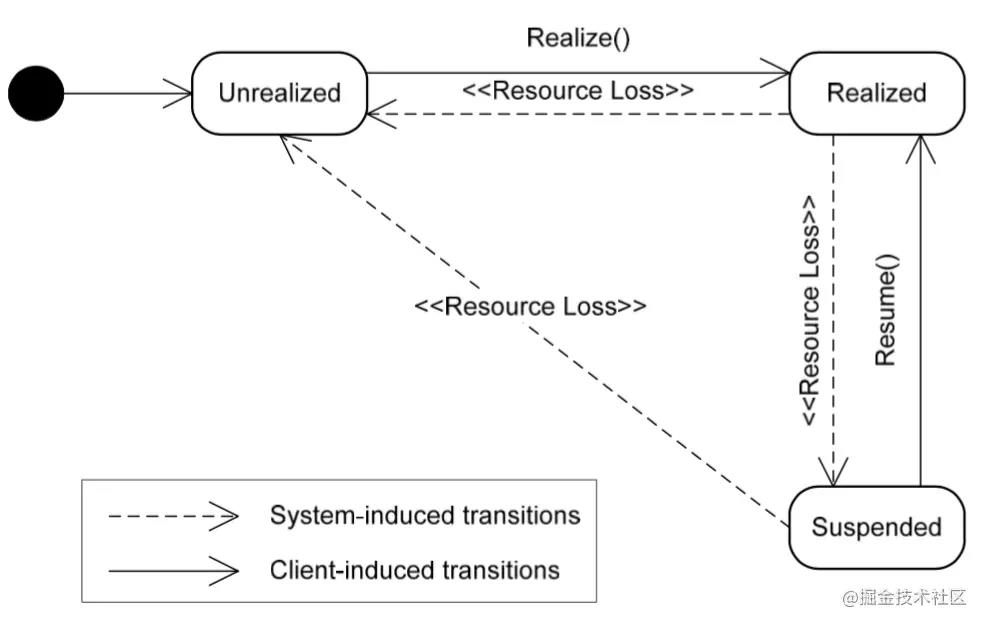
任何一个 OpenSL ES 的对象,创建成功后,都进入 SL_OBJECT_STATE_UNREALIZED 状态,这种状态下,系统不会为它分配任何资源,直到调用 Realize 函数为止。
Realize 后的对象,就会进入 SL_OBJECT_STATE_REALIZED 状态,这是一种“可用”的状态,只有在这种状态下,对象的各个功能和资源才能正常地访问。
当一些系统事件发生后,比如出现错误或者 Audio 设备被其他应用抢占,OpenSL ES 对象会进入 SL_OBJECT_STATE_SUSPENDED 状态,如果希望恢复正常使用,需要调用 Resume 函数。
当调用对象的 Destroy 函数后,则会释放资源,并回到 SL_OBJECT_STATE_UNREALIZED 状态。
简言之,一个 OpenSL ES 对象的生命周期,就是从 create 到 destroy 的过程,生命周期的控制,都是通过开发者显示调用来完成的。
3.3 API调用流程总结
Player: 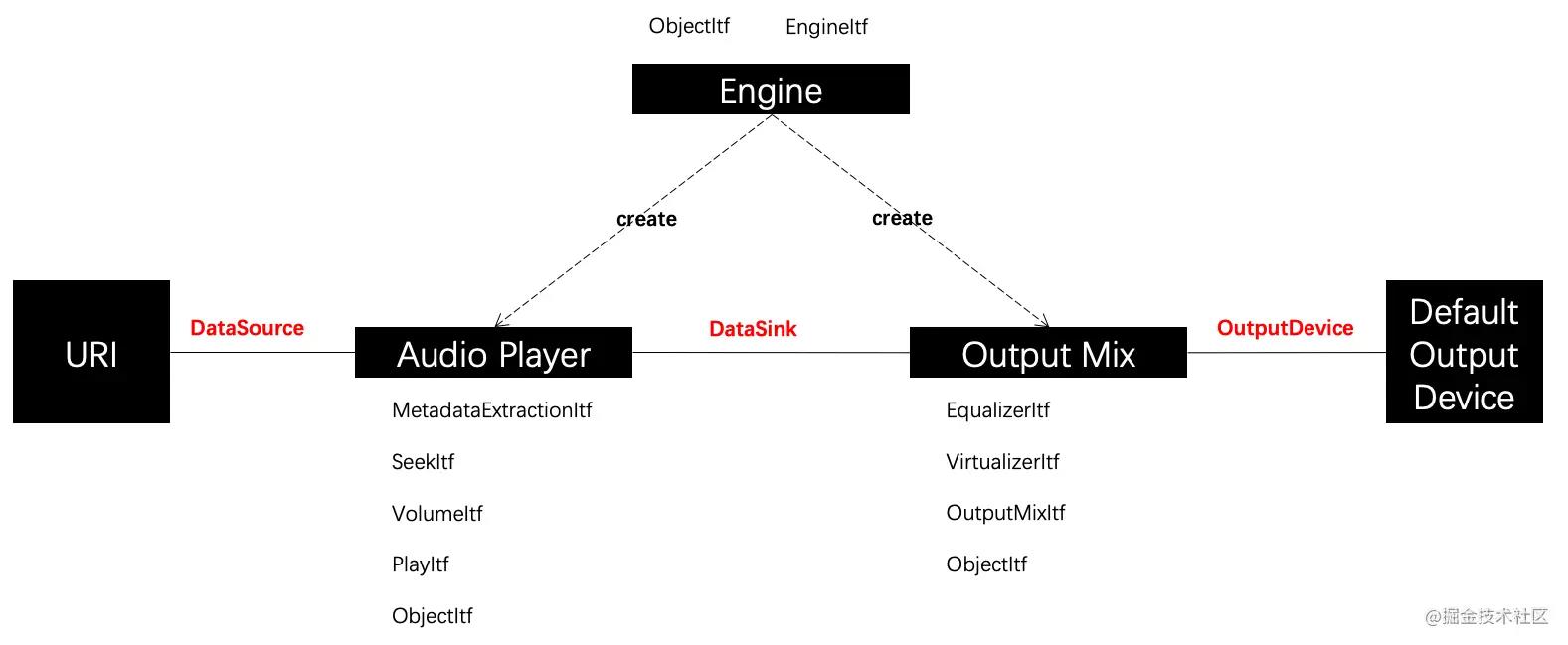
Recorder: 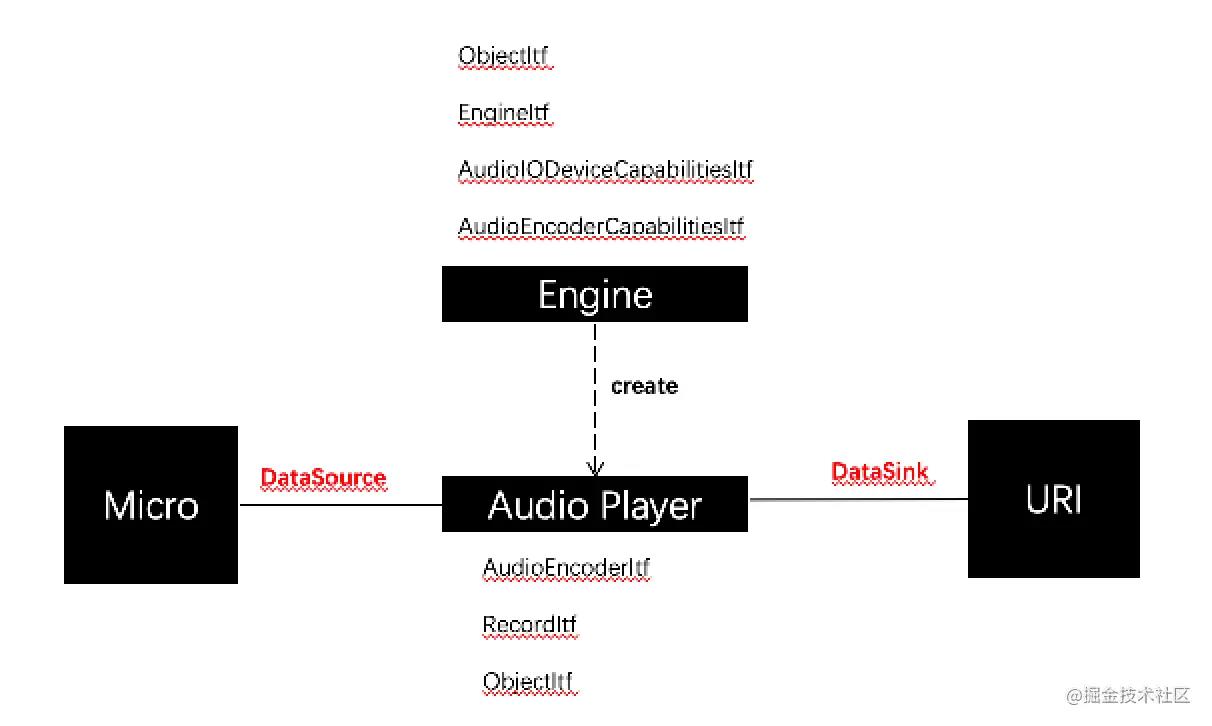
更多API细节可以参考官方提供的《OpenSL_ES_Specification_1.0.1.pdf》。播放逻辑可参考oarplayer中的 github.com/qingkouwei/… 音频输出代码。
4. AAudio & Oboe
AAudio 是在 Android O 版本中引入的全新 Android C API。此 API 专为需要低延迟的高性能音频应用而设计。应用通过读取数据并将数据写入流来与 AAudio 进行通信。
AAudio API 采用最精简的设计,不执行以下功能:
- 音频设备枚举
- 音频端点之间的自动化路由
- 文件 IO
- 解码压缩的音频
- 在单一回调中自动呈交所有输入/流。
每个流都连接到单个音频设备。音频设备是硬件接口或虚拟端点,用作连续的数字音频数据流的来源或接收器。不要将音频设备(内置麦克风或蓝牙耳机)与运行应用的 Android 设备(手机或智能手表)混淆。可以使用 AudioManager 方法 getDevices() 来发现 Android 设备上可用的音频设备。该方法会返回每个设备 type 的相关信息。Android 设备上的每个音频设备都具有唯一 ID。可以使用该 ID 将音频流与特定音频设备绑定。但是,在大多数情况下,可以让 AAudio 选择默认的主要设备,无需自己指定。接到流的音频设备负责确定该流是用于输入还是输出。流只能在一个方向上移动数据。定义流时,您还可以设置其方向。打开流时,Android 会执行检查,确保音频设备与流方向一致。
4.1 API说明
4.1.1 AAudio创建音频流流程
AAudio 库使用了构建器设计模式,并提供 AAudioStreamBuilder。
-
创建 AAudioStreamBuilder:
AAudioStreamBuilder *builder;aaudio_result_t result = AAudio_createStreamBuilder(&builder); -
使用与流参数对应的构建器函数,在构建器中设置音频流配置。可供使用的可选设置函数如下所示:
AAudioStreamBuilder_setDeviceId(builder, deviceId);AAudioStreamBuilder_setDirection(builder, direction);AAudioStreamBuilder_setSharingMode(builder, mode);AAudioStreamBuilder_setSampleRate(builder, sampleRate);AAudioStreamBuilder_setChannelCount(builder, channelCount);AAudioStreamBuilder_setFormat(builder, format);AAudioStreamBuilder_setBufferCapacityInFrames(builder, frames);注意:这些方法不会报告诸如常量未定义或值超出范围之类的错误。
如果未指定 deviceId,将默认为主要输出设备。如果您未指定流方向,将默认为输出流。对于所有其他参数,可明确设置值,也可以完全不指定参数或将其设置为
AAUDIO_UNSPECIFIED,让系统分配最佳值。为安全起见,在创建音频流之后,需要检查其状态。 -
配置 AAudioStreamBuilder 之后,用其创建流:
AAudioStream *stream;result = AAudioStreamBuilder_openStream(builder, &stream); -
创建流之后,验证其配置。如果已指定采样格式、采样率或每帧样本数,这些设置不会变更。如果已指定共享模式或缓冲区容量,这些设置可能会变更,具体取决于流的音频设备能力,以及运行该流的 Android 设备。作为一种良好的防御性编程习惯,您应该先检查流的配置,然后再使用。您可使用相应函数检索与每项构建器设置对应的流设置:
-
可以保存该构建器,以便将来再用其创建更多流。但是,如果不打算再使用该构建器,则应将其删除。
AAudioStreamBuilder_delete(builder);
4.1.2 AAudio使用音频流
仅当流处于“已开始”状态时,数据才会通过流来流动。,使用以下函数请求状态转换:
aaudio_result_t result;result = AAudioStream_requestStart(stream);result = AAudioStream_requestStop(stream);result = AAudioStream_requestPause(stream);result = AAudioStream_requestFlush(stream);
4.1.3 AAudio读取和写入音频流
在流启动后,可通过两种方法来处理流中的数据:
- 使用高优先级回调。
- 使用函数
AAudioStream_read(stream, buffer, numFrames, timeoutNanos)和AAudioStream_write(stream, buffer, numFrames, timeoutNanos)来读取或写入流。
对于传输指定帧数的阻塞读取或写入操作,请将 timeoutNanos 设置为大于零。 对于非阻塞调用,请将 timeoutNanos 设置为零。在这种情况下,结果将是传输的实际帧数。
读取输入值时,您应验证是否已读取正确数量的帧。如果未读取正确数量的帧,缓冲区可能包含未知的数据,从而引起音频干扰。您可以在缓冲区中填入零,以产生静音效果:
aaudio_result_t result = AAudioStream_read(stream, audioData, numFrames, timeout);if (result < 0) { // Error!}if (result != numFrames) { // pad the buffer with zeros memset(static_cast<sample_type*>(audioData) + result * samplesPerFrame, 0, sizeof(sample_type) * (numFrames - result) * samplesPerFrame);}
4.1.4 AAudio关闭音频流
使用完流之后,请将其关闭:
AAudioStream_close(stream);
关闭流之后,便无法将其与任何基于流的 AAudio 函数配合使用。
4.1.5 AAudio断开连接的音频流
如果发生以下任一事件,音频流随时可能会断开连接:
- 关联的音频设备不再处于连接状态(例如,在拔出头戴式耳机时)。
- 发生内部错误。
- 某音频设备不再是主要音频设备。
流断开连接时,其状态为“已断开连接”,所有尝试执行 AAudioStream_write 或其他函数的操作都会返回错误。无论是什么错误代码,您始终必须停止并关闭已断开连接的流。
如果您使用的是数据回调(而不是某个直接读取/写入方法),那么当流断开连接时,您不会收到任何返回代码。如需在发生这种情况时接收通知,请编写 AAudioStream_errorCallback 函数,然后使用 AAudioStreamBuilder_setErrorCallback() 注册该函数。
果您在错误回调线程中收到连接已断开的通知,则流的停止和关闭必须从其他线程中完成。否则可能出现死锁。
请注意,如果打开新的流,其设置可能与原始流不同(例如,framesPerBurst):
void errorCallback(AAudioStream *stream, void *userData, aaudio_result_t error) { // Launch a new thread to handle the disconnect. std::thread myThread(my_error_thread_proc, stream, userData); myThread.detach(); // Don't wait for the thread to finish.}
4.2 状态转换
AAudio 流一般有以下五种稳定状态(本部分结尾将介绍错误状态 Disconnected):
- 打开
- 已开始
- 已暂停
- 已刷新
- 已停止
状态切换函数是异步函数,因此状态不会立即变更。当您请求变更状态时,流会进入以下相应的过渡状态:
- 正在开始
- 正在暂停
- 正在刷新
- 正在停止
- 正在关闭
以下状态图将稳定状态显示为圆角矩形,而将过渡状态显示为虚线矩形。尽管未显示,但您可从任意状态调用 close()
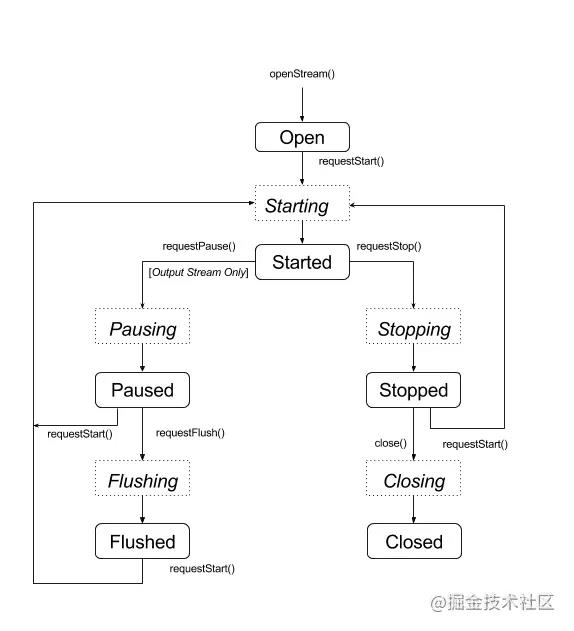
AAudio 未提供回调函数来提醒您状态发生变更。您可使用特殊函数 AAudioStream_waitForStateChange(stream, inputState, nextState, timeout) 等待状态变更。
此函数本身并不会检测状态变更情况,也不会等待特定的状态,而是等待当前状态偏离您指定的 inputState。
例如,请求暂停后,流应立即进入“正在暂停”过渡状态,并在稍后某个时刻进入“已暂停”状态,但不保证一定如此。由于无法等待“已暂停”状态,请使用 waitForStateChange() 来等待除“正在暂停”之外的任何状态。方法如下:
aaudio_stream_state_t inputState = AAUDIO_STREAM_STATE_PAUSING;aaudio_stream_state_t nextState = AAUDIO_STREAM_STATE_UNINITIALIZED;int64_t timeoutNanos = 100 * AAUDIO_NANOS_PER_MILLISECOND;result = AAudioStream_requestPause(stream);result = AAudioStream_waitForStateChange(stream, inputState, &nextState, timeoutNanos);
如果流的状态并非“正在暂停”(即 inputState,我们假定这就是当前执行调用时的状态),该函数会立即返回。否则,函数会阻止运行,直至状态不再是“正在暂停”,或者超时。当函数返回时,参数 nextState 会显示流的当前状态。
您可在调用开始、停止或刷新请求后使用这种方法,将相应的过渡状态用作 inputState。不要在调用 AAudioStream_close() 之后调用 waitForStateChange(),因为流在关闭时会立即被删除。此外,不要在另一线程运行 waitForStateChange() 时调用 AAudioStream_close()。
4.3 优化性能
我们可以通过调整内部缓冲区,使用特殊的高优先级线程,优化音频应用的性能。
4.3.1 调整缓冲区以最大限度减少延迟时间
AAudio 会将数据传入其维护的内部缓冲区,并从中传出数据(每个音频设备各有一个内部缓冲区)。
注意:不要将 AAudio 的内部缓冲区与 AAudio 流读取或写入函数的缓冲区参数混淆。
缓冲区的容量是缓冲区中可以存放的数据总量。我们可以调用 AAudioStreamBuilder_setBufferCapacityInFrames() 来设置容量。这个方法将可分配的容量限制为设备允许的最大值。使用 AAudioStream_getBufferCapacityInFrames() 可以验证缓冲区的实际容量。
应用不必使用缓冲区的全部容量。可以设置 AAudio 填充缓冲区空间的大小上限。缓冲区空间大小不得超过它的容量,而且通常小于其容量。可以通过控制缓冲区大小,确定填充缓冲区所需的脉冲串数,从而控制延迟时间。可以使用 AAudioStreamBuilder_setBufferSizeInFrames() 和 AAudioStreamBuilder_getBufferSizeInFrames() 方法来处理缓冲区大小。
应用播放音频时,会将数据写入缓冲区并阻止运行,直至写入完成。AAudio 以离散的脉冲串从缓冲区中读取数据。每个脉冲串都包含多个音频帧,而且通常小于所读取的缓冲区大小。脉冲串的大小及速率由系统控制,而这些属性通常由音频设备的电路指定。虽然无法更改脉冲串的大小或速率,但可以根据内部缓冲区所含的脉冲串数量来设置内部缓冲区大小。通常,当 AAudioStream 的缓冲区大小是所报告脉冲串大小的倍数时,延迟时间最短。
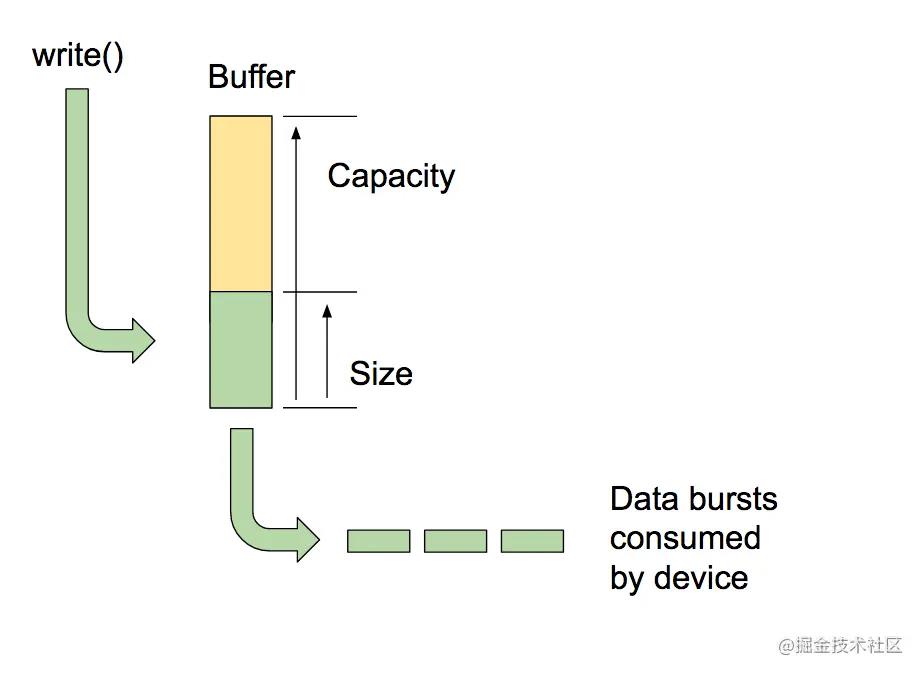
优化缓冲区空间大小的一种方法是从较大的缓冲区开始,逐渐将其减小直至开始出现缓冲区不足现象,再稍稍将其调大。此外,也可以从较小的缓冲区空间大小开始,如果出现缓冲区不足现象,则增大缓冲区空间大小,直至输出再次流畅为止。这个过程推进速度很快,很可能在用户开始播放第一个音频前就已完成。可以先以静音执行初始缓冲区大小调整,确保用户不会听到任何音频干扰声。随着时间推移,系统性能可能会有所变化(例如,用户可能会关闭飞行模式)。因为缓冲区调整所产生的开销非常小,应用可以在对流读取或写入数据的同时,连续不断地调整缓冲区。
以下是缓冲区优化循环的示例:
int32_t previousUnderrunCount = 0;int32_t framesPerBurst = AAudioStream_getFramesPerBurst(stream);int32_t bufferSize = AAudioStream_getBufferSizeInFrames(stream);int32_t bufferCapacity = AAudioStream_getBufferCapacityInFrames(stream);while (go) { result = writeSomeData(); if (result < 0) break; // Are we getting underruns? if (bufferSize < bufferCapacity) { int32_t underrunCount = AAudioStream_getXRunCount(stream); if (underrunCount > previousUnderrunCount) { previousUnderrunCount = underrunCount; // Try increasing the buffer size by one burst bufferSize += framesPerBurst; bufferSize = AAudioStream_setBufferSize(stream, bufferSize); } }}
对于输入流来说,使用这种方法优化缓冲区大小并无益处。输入流以尽可能快的速度运行,以尝试将缓存数据量保持在最低限度,然后在应用被抢占时填补缓冲区。
4.3.2 使用高优先级回调
如果应用从原始线程中读取或写入音频数据,可能会被抢占或遇到定时抖动,进而可能引起音频干扰。使用较大的缓冲区有助于避免此类干扰,但是如果缓冲区较大,音频延迟时间也会更长。对于要求延迟时间较短的应用,音频流可以使用一个异步回调函数,将数据传输到应用并从中传输数据。AAudio 会在优先级较高的线程中执行该回调,这有助于改善性能。
该回调函数的原型如下所示:
typedef aaudio_data_callback_result_t (*AAudioStream_dataCallback)( AAudioStream *stream, void *userData, void *audioData, int32_t numFrames);
使用流构建方式来注册回调:
AAudioStreamBuilder_setDataCallback(builder, myCallback, myUserData);
在最简单的情况下,流会定期执行该回调函数,以获取用于下一个脉冲串的数据。
该回调函数不应对调用它的流执行读取或写入操作。如果该回调属于某个输入流,那么您的代码应处理在 audioData 缓冲区(指定为第三个参数)中提供的数据。如果该回调属于某个输出流,那么您的代码应将数据放入该缓冲区。
例如,可以使用回调来连续生成正弦波输出,如下所示:
aaudio_data_callback_result_t myCallback( AAudioStream *stream, void *userData, void *audioData, int32_t numFrames) { int64_t timeout = 0; // Write samples directly into the audioData array. generateSineWave(static_cast<float *>(audioData), numFrames); return AAUDIO_CALLABCK_RESULT_CONTINUE;}
使用 AAudio 可以处理多个流。可以将其中一个流用作主流,并在用户数据中传递指向其他流的指针。针对主流注册回调。然后,对其他流使用非阻塞 I/O。以下是将输入流传递到输出流的往返回调示例。主调用流是输出流。输入流包括在用户数据中。
该回调从输入流执行非阻塞读取,以将数据放入输出流的缓冲区:
aaudio_data_callback_result_t myCallback( AAudioStream *stream, void *userData, void *audioData, int32_t numFrames) { AAudioStream *inputStream = (AAudioStream *) userData; int64_t timeout = 0; aaudio_result_t result = AAudioStream_read(inputStream, audioData, numFrames, timeout); if (result == numFrames) return AAUDIO_CALLABCK_RESULT_CONTINUE; if (result >= 0) { memset(static_cast<sample_type*>(audioData) + result * samplesPerFrame, 0, sizeof(sample_type) * (numFrames - result) * samplesPerFrame); return AAUDIO_CALLBACK_RESULT_CONTINUE; } return AAUDIO_CALLBACK_RESULT_STOP;}
请注意,在此示例中,假定输入流和输出流的通道数量、格式和采样率均相同。流的格式可以不匹配,只要代码正确处理转换即可。
4.3.3 设置性能模式
每个 AAudioStream 都具有性能模式,而这对应用行为的影响很大。共有三种模式:
AAUDIO_PERFORMANCE_MODE_NONE是默认模式。这种模式使用在延迟时间与节能之间取得平衡的基本流。AAUDIO_PERFORMANCE_MODE_LOW_LATENCY使用较小的缓冲区和经优化的数据路径,以减少延迟时间。AAUDIO_PERFORMANCE_MODE_POWER_SAVING使用较大的内部缓冲区,以及以延迟时间为代价换取节能优势的数据路径。
可以通过调用 setPerformanceMode() 来选择性能模式,并通过调用 getPerformanceMode() 来发现当前模式。
如果在应用中缩短延迟时间比节能更重要,请使用 AAUDIO_PERFORMANCE_MODE_LOW_LATENCY。这对交互性非常强的应用(例如游戏或键盘合成器)非常有用。
如果在您的应用中节能比缩短延迟时间更重要,请使用 AAUDIO_PERFORMANCE_MODE_POWER_SAVING。对于回放先前生成的音乐的应用(例如流式音频或 MIDI 文件播放器),情况通常如此。
在当前版本的 AAudio 中,为了尽量减少延迟时间,必须将 AAUDIO_PERFORMANCE_MODE_LOW_LATENCY 性能模式与高优先级回调配合使用。请参阅以下示例:
// Create a stream builderAAudioStreamBuilder *streamBuilder;AAudio_createStreamBuilder(&streamBuilder);AAudioStreamBuilder_setDataCallback(streamBuilder, dataCallback, nullptr);AAudioStreamBuilder_setPerformanceMode(streamBuilder, AAUDIO_PERFORMANCE_MODE_LOW_LATENCY);// Use it to create the streamAAudioStream *stream;AAudioStreamBuilder_openStream(streamBuilder, &stream);
官方文档:developer.android.google.cn/ndk/guides/…
4.4 Oboe
谷歌开源了Oboe库,Oboe 是一个 C++ 封装容器,提供与 AAudio 非常相似的 API。它在 AAudio 可用时对其进行调用,并在 AAudio 不可用时回退使用 OpenSL ES。
以录音为例实现程序:
class Callback:public oboe::AudioStreamCallback{DataCallbackResultOboeRecorder::onAudioReady(AudioStream *oboeStream, void *audioData, int32_t numFrames) { uint32_t size = 2 * numFrames * channels; //handle audio data return DataCallbackResult::Continue;}}oboe::AudioStreamBuilder builder;builder->setAudioApi(mAudioApi) ->setFormat(mFormat) ->setSharingMode(oboe::SharingMode::Exclusive) ->setPerformanceMode(oboe::PerformanceMode::LowLatency) ->setDeviceId(mRecordingDeviceId) ->setFramesPerCallback(framesPerBuffer) ->setDirection(oboe::Direction::Input) ->setDataCallback(new Callback()) ->setSampleRate(samplerate) ->setChannelCount(channels);oboe::AudioStream *mRecordingStream = nullptr;oboe::Result result = builder.openStream(&mRecordingStream);if (result == oboe::Result::OK && mRecordingStream) { mRealSampleRate = mRecordingStream->getSampleRate(); mFormat = mRecordingStream->getFormat(); oboe::Result result = stream->requestStart(); mRecordingStream->waitForStateChange(StreamState::Starting, &state, 10*kNanosPerMillisecond); if (result != oboe::Result::OK) { Logg("Error starting stream. %s", oboe::convertToText(result)); }} else { Logg("Failed to create recording stream. Error: %s",oboe::convertToText(result)); result = mRecordingStream->close();}
Oboe提供了很多创意的参考,可以直接在Oboe github仓库查看。
5. 总结
本篇介绍了Android提供的音频采集/播放接口,Java层可以使用AudioRecorder/AudioTrack,jni层推荐使用Oboe。不论哪个API都是最终通过framework层、HAL层与硬件打交道。音频采集时在应用层会有一个“AudioRecord”的线程来与framework的服务交互。
以上是关于Android音频API的主要内容,如果未能解决你的问题,请参考以下文章
Android 插件化VirtualApp 源码分析 ( 目前的 API 现状 | 安装应用源码分析 | 安装按钮执行的操作 | 返回到 HomeActivity 执行的操作 )(代码片段