Hive数据定义与操作
Posted shi_zi_183
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive数据定义与操作相关的知识,希望对你有一定的参考价值。
Hive数据定义与操作
HiveQL数据定义语言
创建数据库
create database sogou;
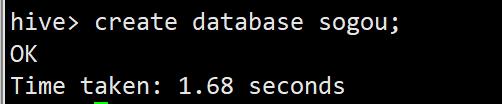
如果数据库sogou已经存在的话,会抛出异常,创建数据库的命令应为
create database if not exists sogou;

查看数据库
随时可以通过如下命令查看Hive中所包含的数据库
show databases;
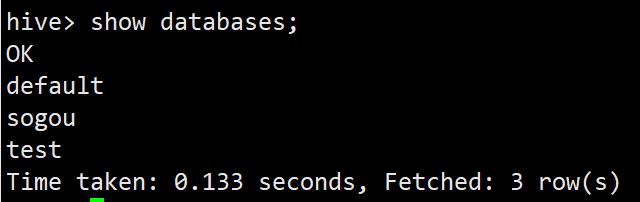
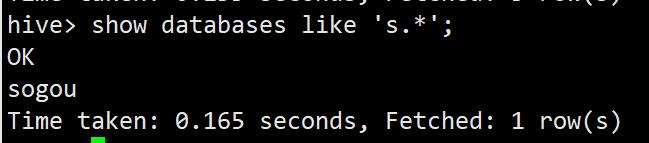
数据多的时候,可以使用正则表达式来筛选
show databases like 's.*';
为数据库增加描述,以说明该数据库的业务含义
create database bank comment 'Internet Banking'; //创建数据库bank,其作为电子网银系统后台数据库
describe database bank; //查看数据库bank的详细信息
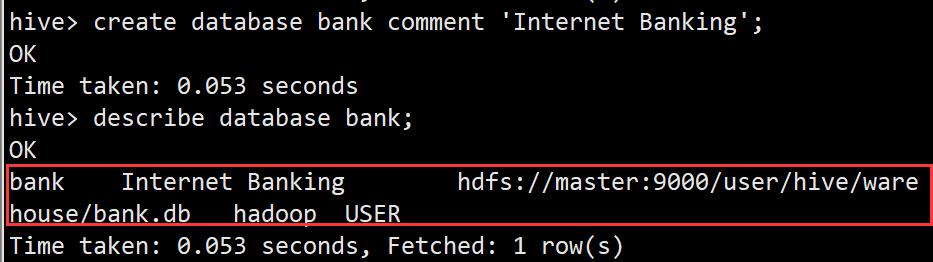
数据库拓展名为.db,存放目录为:hdfs://master:9000/user/hive/warehouse/bank.db,该父目录层级在Hive的配置文件hive-site.xml中进行hive.metastore.warehouse.dir属性值的自定义设置。
Hive创建新的数据库时,Hive为每个数据库创建一个目录
删除数据库
drop database sogou;
drop database database if exists sogou;
Hive数据仓库不允许删除一个包含有表的数据库
先删除数据库中的表再删除数据库
创建测试表
create database if not exists book_sale;
use book_sale;
create table if not exists book_sale.book(id_book int ,name_book string)row format delimited fields terminated by ',';
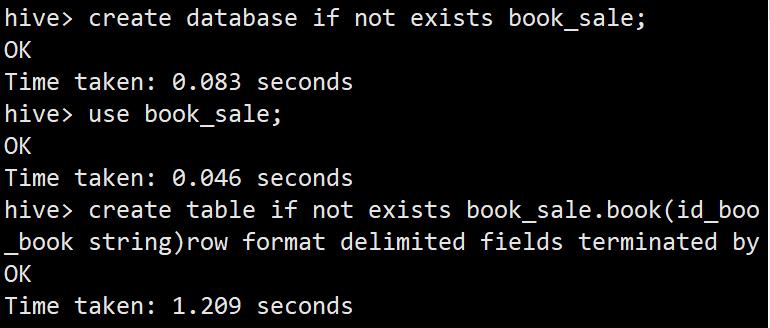
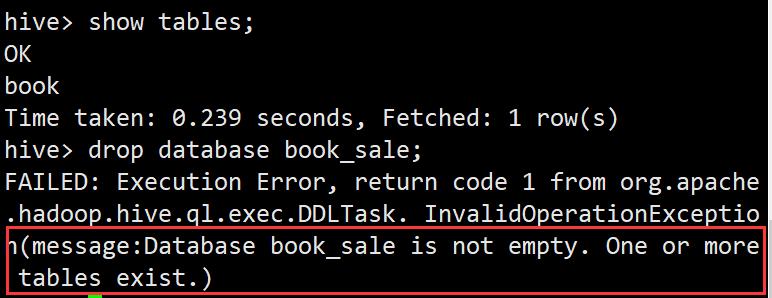
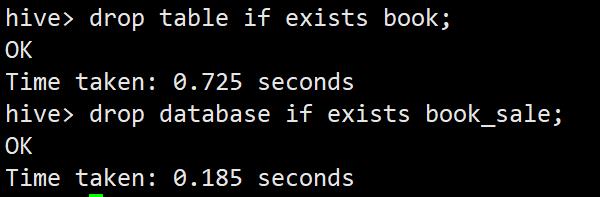
drop table if exists book;
drop database if exists book_sale;
在删除数据库的命令后加上关键字cascade
drop database if exists book_sale cascade;

HiveQL数据定义语言
创建表
Hive数据仓库提供了类似关系型数据库的表结构存储,可以创建数据库,然后基于数据库来创建表应用,最后通过表来管理业务数据。
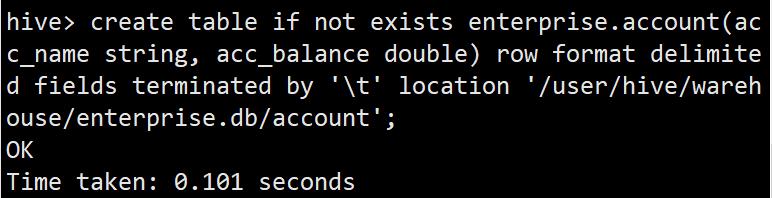
create table if not exists enterprise.account(acc_name string, acc_balance double) row format delimited fields terminated by '\\t' location '/user/hive/warehouse/enterprise.db/account';
创建表
在Hive中按照表数据的生命周期可以将表分为内部表和外部表两大类
管理表(内部表;临时表)
Hive控制着管理表的整个生命周期,默认情况下Hive管理表的数据存放在Hive主目录/user/hive/warehouse/中,当删除一张表时,表中的数据一起被删除。
以前建立的enterprise数据库中的表都属于管理表
管理表的缺陷:删除表时,表中数据也被删除。
外部表(在实际业务系统中常用)
在创建表时,加上关键字external,则创建外部表。
外部表中的数据生命周期不受Hive的控制,可以和其他外部表进行数据共享,当删除一张外部表时,表对应的数据不会被删除。
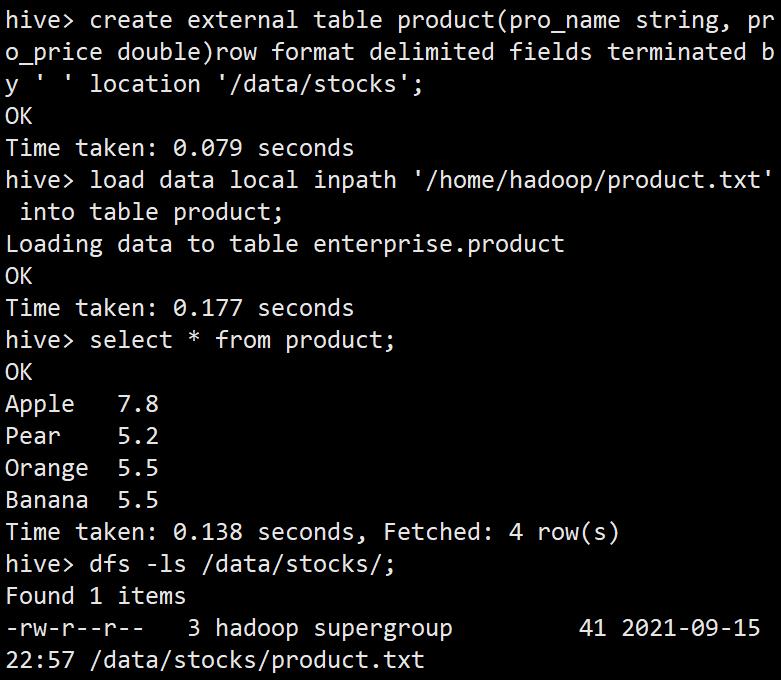
create external table product(pro_name string, pro_price double)row format delimited fields terminated by ' ' location '/data/stocks';
load data local inpath '/home/hadoop/product.txt' into table product;
select * from product;
dfs -ls /data/stocks/;
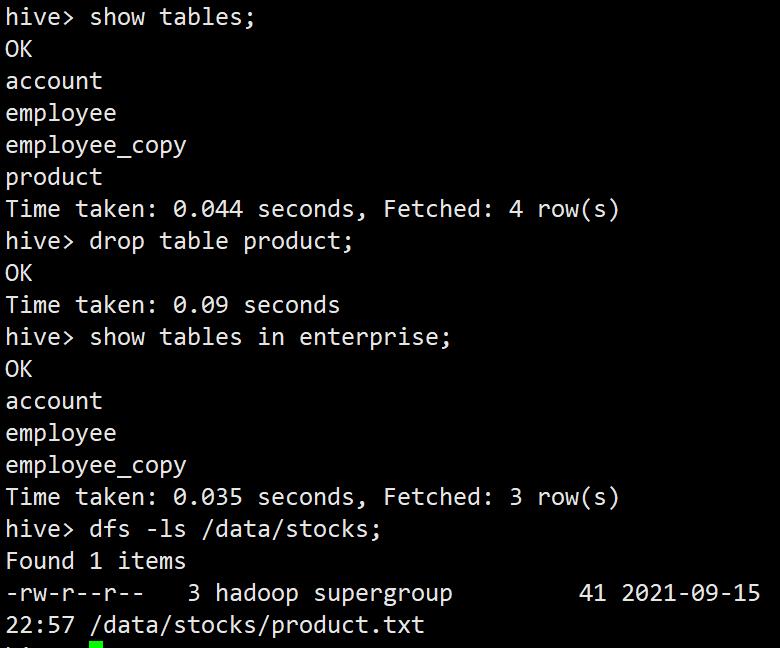
show tables;
drop table product;
show tables in enterprise;
dfs -ls /data/stocks;
外部表通常用在关键信息表中,即使删除了表,数据依然存在,重新创建表后,表中数据就恢复了。
另外在公用数据表中可以保证数据安全
共用表实现
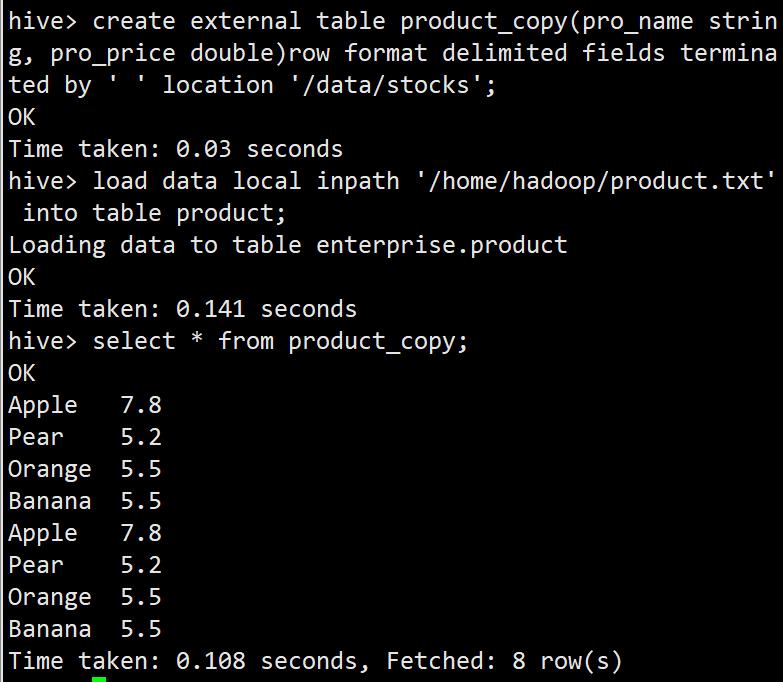
create external table product(pro_name string, pro_price double)row format delimited fields terminated by ' ' location '/data/stocks';
create external table product_copy(pro_name string, pro_price double)row format delimited fields terminated by ' ' location '/data/stocks';
load data local inpath '/home/hadoop/product.txt' into table product;
select * from product_copy;
修改表
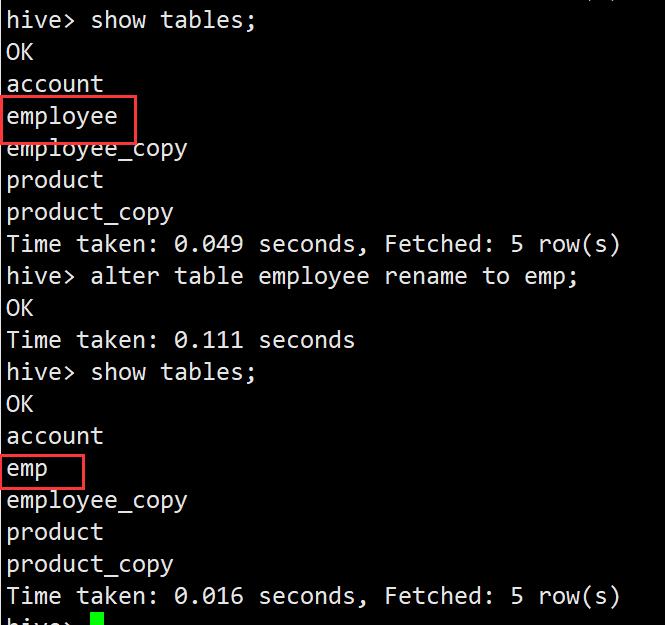
重命名表
alter table employee rename to emp;
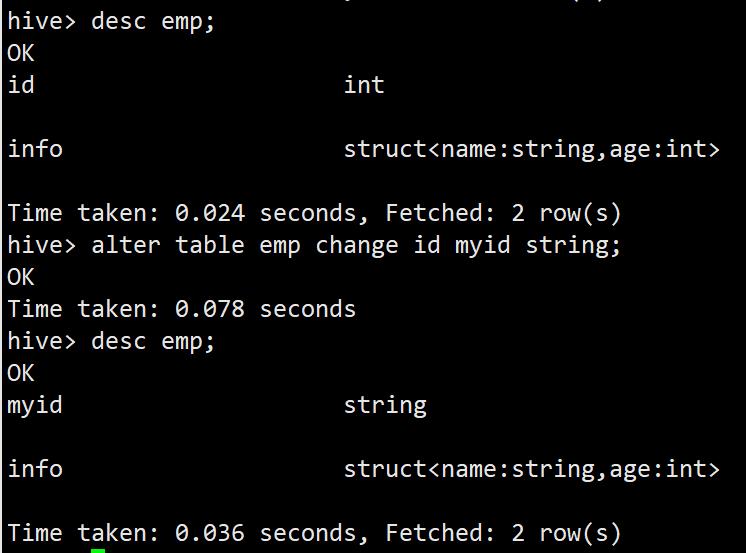
更改表的字段和类型
alter table emp change id myid string;
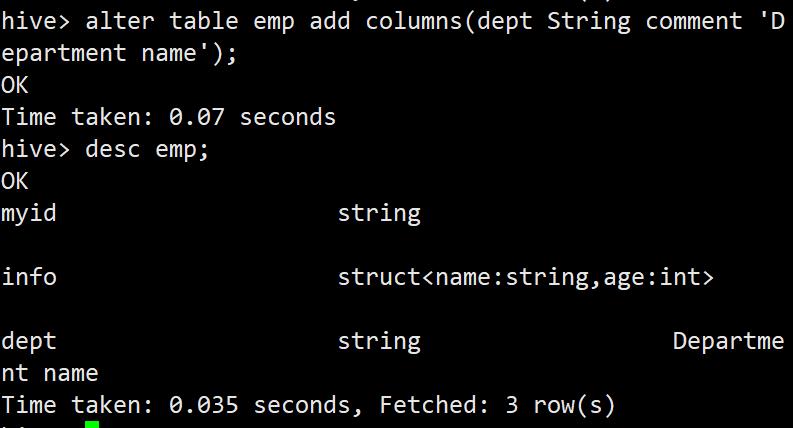
增加一列
alter table emp add columns(dept String comment 'Department name');
删除表
外部表只删除表,不删除数据。如果删除数据,可以删除数据所在的hdfs文件夹
drop table emp;
//如果外部表,需要删除hdfs中的数据
分区表
解决数据库存储和计算机性能能够采取的措施:
1)创建分表
把一张大表数据根据业务需求分配到多张小表中。
优点:提高表的并发量
缺点:SQL代码维护成本增高。
2)创建分区表
所有数据在一张表中,底层物理存储数据根据一定的规划划分到不同的文件中,这些文件可以存储在不同的磁盘上。
优点:分散了存储压力。
缺点:没有提供表的并发量。
Hive的分区方式是在HDFS文件系统上的一个分区名对应一个目录名,子分区名就是子目录名,并不是一个实际字段。
Hive的分区是在创建表的时候用partitioned by关键字定义的。patitioned by定义的列是表中正规的列,但Hive下的数据文件中并不包含这些列,因为定义只是目录名。
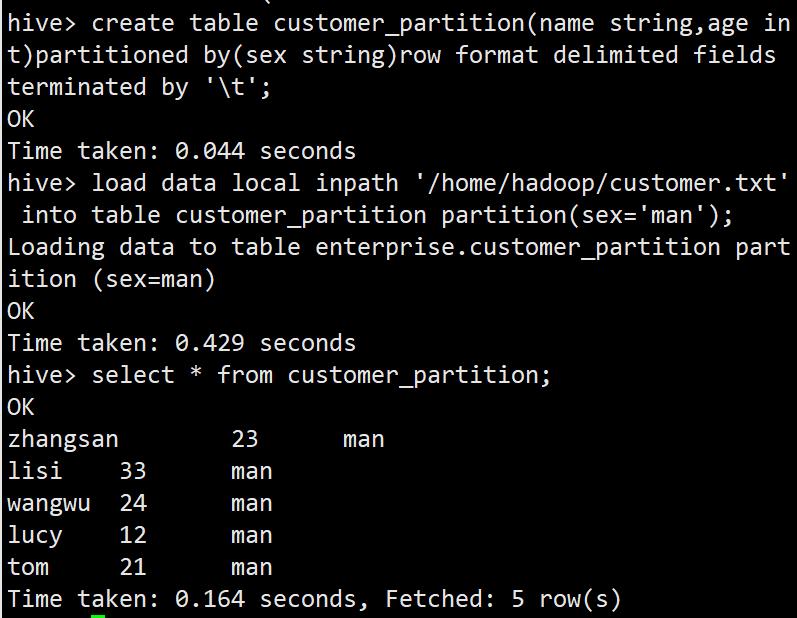
静态分区
create table customer_partition(name string,age int)partitioned by(sex string)row format delimited fields terminated by '\\t';
load data local inpath '/home/hadoop/customer.txt' into table customer_partition partition(sex='man');
dfs -ls -R /user/hive/warehouse/enterprise.db/customer_partition;

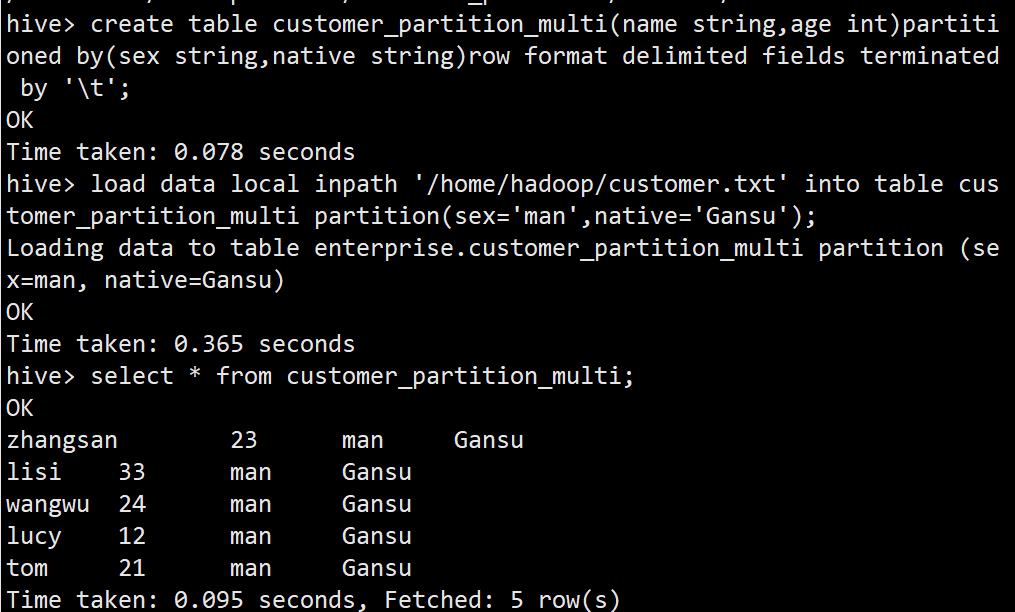
一张表有多个分区
create table customer_partition_multi(name string,age int)partitioned by(sex string,native string)row format delimited fields terminated by '\\t';
load data local inpath '/home/hadoop/customer.txt' into table customer_partition_multi partition(sex='man',native='Gansu');
dfs -ls -R /user/hive/warehouse/enterprise.db/customer_partition_multi;
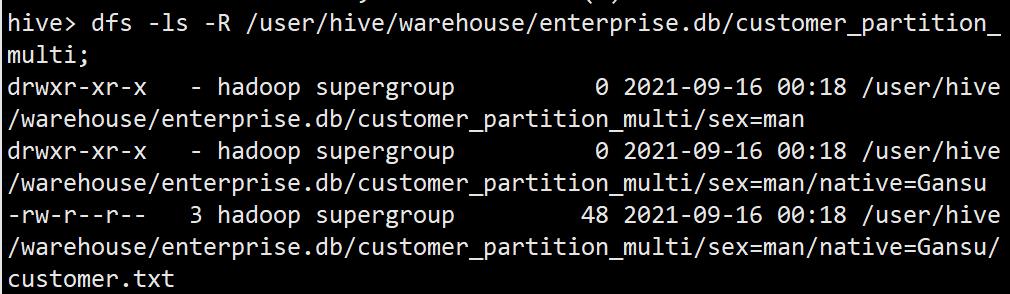
动态分区(实际使用)
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=1000;
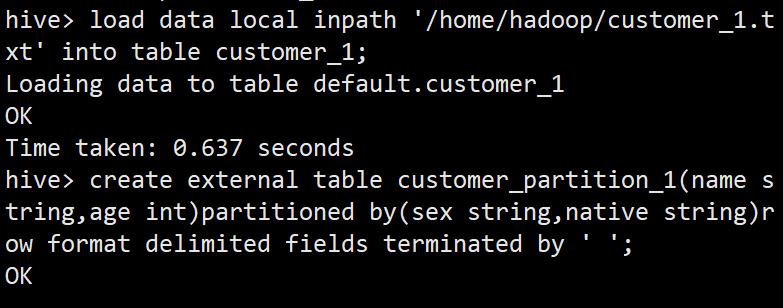
create external table customer_1(name string,age int,sex string,native string)row format delimited fields terminated by ' ' location '/data/customer_1';
load data local inpath '/home/hadoop/customer_1.txt' into table customer_1;
create external table customer_partition_1(name string,age int)partitioned by(sex string,native string)row format delimited fields terminated by ' ';
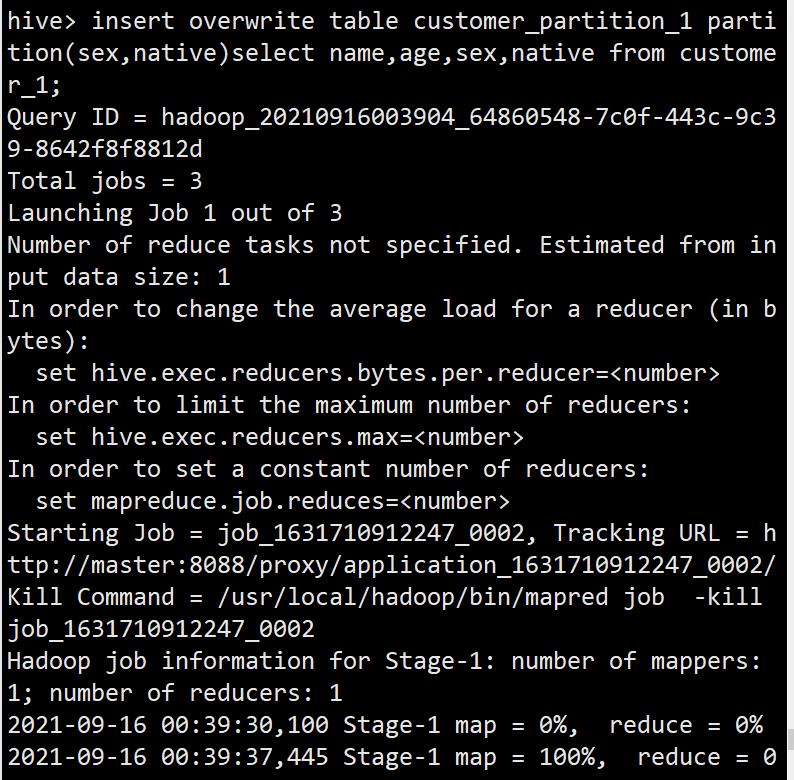
insert overwrite table customer_partition_1 partition(sex,native)select name,age,sex,native from customer_1;
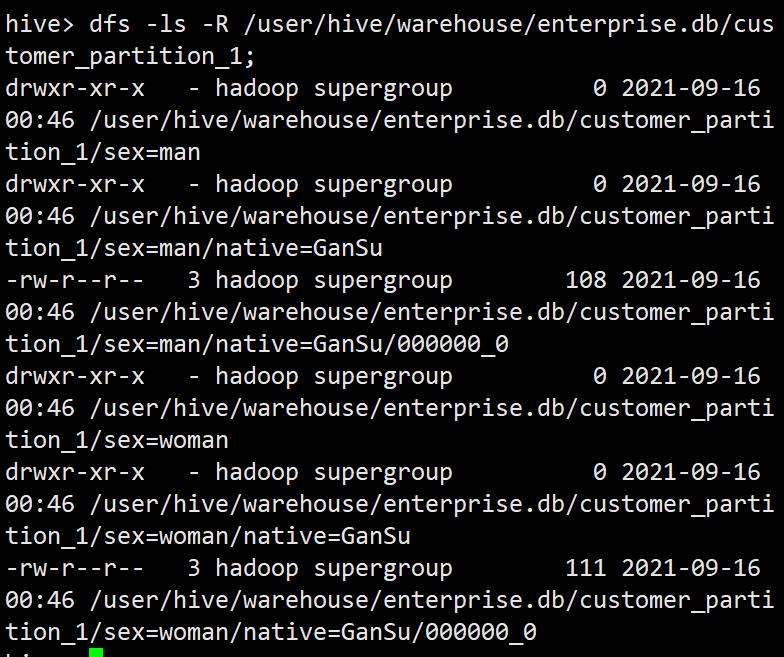
dfs -ls -R /user/hive/warehouse/enterprise.db/customer_partition_1;


HiveQL数据操作
向管理表中装载数据
create database sogou;
use sogou;
create table if not exists sogou.sogou_500w(ts string,uid string,keyword string,rank string,orders int,url string)row format delimited fields terminated by '\\t' stored as textfile;
load data local inpath '/home/hadoop/sogou.500w.utf8'overwrite into table sogou.sogou_500w;
select * from sogou.sogou_500w limit 5;
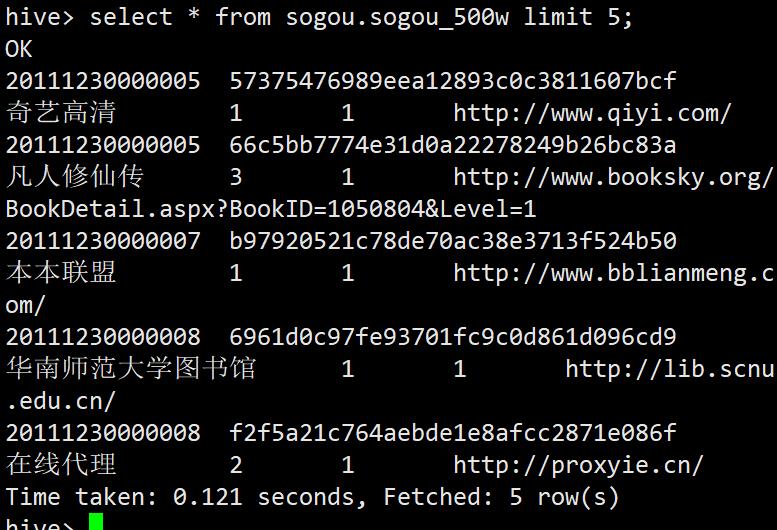
经查询语句向表中插入数据
create table if not exists sogou.sogou_xj(ts string,uid string,keyword string,rank string,orders int,url string)row format delimited fields terminated by '\\t';
insert overwrite table sogou.sogou_xj select * from sogou.sogou_500w where keyword like '%仙剑奇侠传%';
select * from sogou.sogou_xj limit 10;
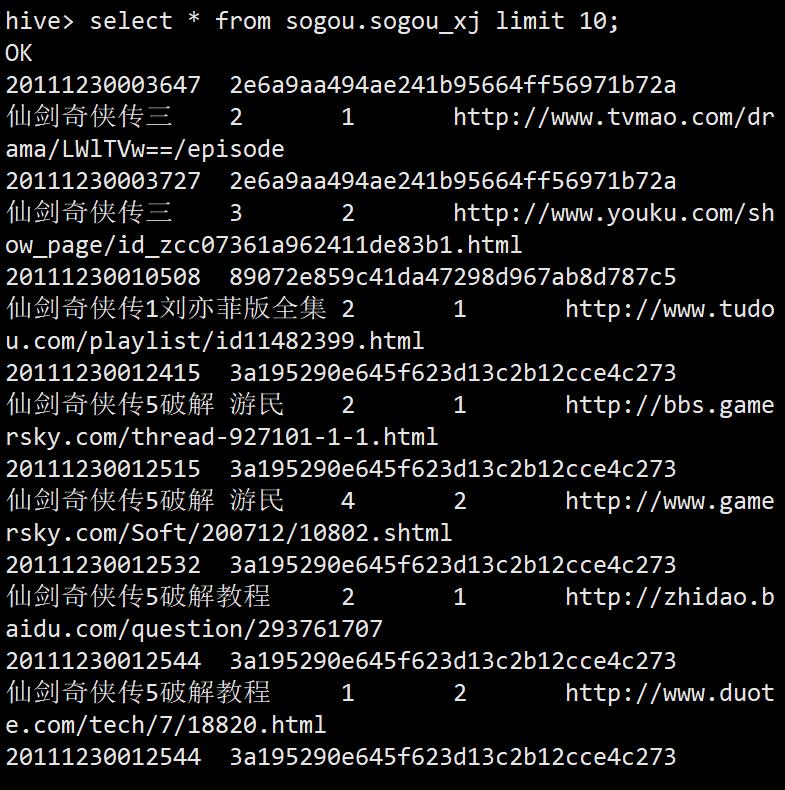
单个查询语句中创建表并加载数据
create table sogou.sogou_xj_backup as select * from sogou.sogou_xj;
select * from sogou.sogou_xj_backup limit 10;
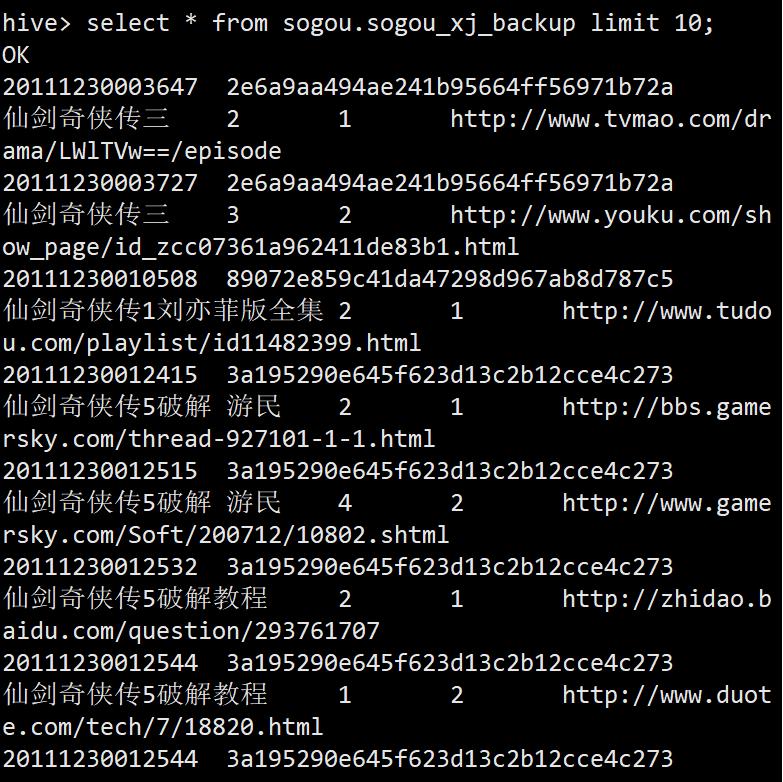
导入数据
Hive表中的数据最终落地在HDFS文件系统上,可以通过HDFS的命令操作直接将数据写入Hive表LOCALTION属性所指向的地址。
导出数据
从Hive导出数据到本地是从HDFS导出数据。
以上是关于Hive数据定义与操作的主要内容,如果未能解决你的问题,请参考以下文章