OCR--秒懂文字检测CTPN(CNN+LSTM) 二
Posted myriads_changes_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OCR--秒懂文字检测CTPN(CNN+LSTM) 二相关的知识,希望对你有一定的参考价值。
简介
CTPN是在ECCV 2016提出的一种文字检测算法。CTPN结合CNN与LSTM深度网络,能有效的检测出复杂场景的横向分布的文字,效果如下图,是目前比较好的文字检测算法。

如下图所示,左面为传统RPN预测的框,右面为CTPN的框。由于RPN中anchor感受野的问题,不可能有一个anchor可以像传统的人车物检测那样覆盖了整行的文本。

CTPN
网络结构
CTPN结构与Faster R-CNN基本类似,但是加入了LSTM层。
CTPN 使用到了 CNN 和 双向LSTM 的网络结构:
- CNN使用了VGG16进行图像的特征提取。
- 双向LSTM对序列各元素前后的联系进行学习。
- 最后为一个全连接层输出要预测的参数
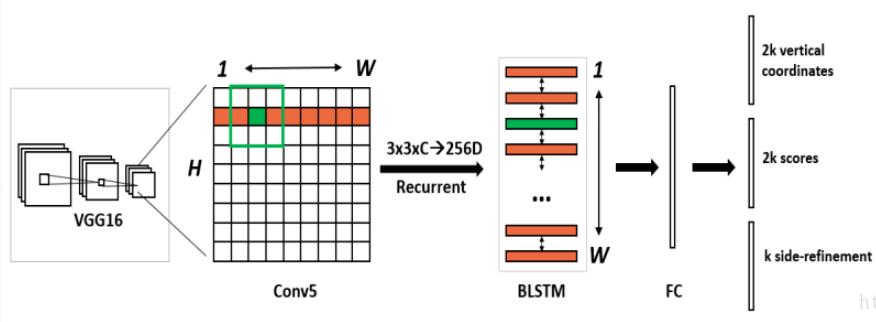
N:images
首先VGG16提取特征,获得大小为
N
∗
C
∗
W
∗
H
N*C*W*H
N∗C∗W∗H 的conv5 feature map。之后在conv5上做3*3的滑动窗口,即每个点都结合周围
3
∗
3
3*3
3∗3区域特征获得一个长度为
3
∗
3
∗
C
3*3*C
3∗3∗C的特征向量。输出
N
∗
9
C
∗
H
∗
W
N*9C*H*W
N∗9C∗H∗W 的feature map,但是该特征显然只有CNN学习到的空间特征。后面我们需要将将这个feature map进行Reshape
r
e
s
h
a
p
e
:
N
∗
9
C
∗
H
∗
W
−
−
>
(
N
H
)
∗
W
∗
9
C
reshape:N*9C*H*W-->(NH)*W*9C
reshape:N∗9C∗H∗W−−>(NH)∗W∗9C(变成LSTM能学习的大小256),再将数据流输入双向LSTM,学习每一行的序列特征。最后在将双向LSTM的输出
(
N
H
)
∗
256
∗
W
(NH)*256*W
(NH)∗256∗W变为原来的形状
N
∗
256
∗
H
∗
W
N*256*H*W
N∗256∗H∗W应此该特征既包含空间特征,也包含了LSTM学习到的序列特征。
最后在经过FC,配置anchors,全连接,获得text proposals(文本位置)
参考代码
class CTPN_Model(nn.Module):
def __init__(self):
super().__init__()
base_model = models.vgg16(pretrained=False)
layers = list(base_model.features)[:-1]
self.base_layers = nn.Sequential(*layers) # block5_conv3 output
self.rpn = basic_conv(512, 512, 3, 1, 1, bn=False)
self.brnn = nn.GRU(512,128, bidirectional=True, batch_first=True)
self.lstm_fc = basic_conv(256, 512, 1, 1, relu=True, bn=False)
self.rpn_class = basic_conv(512, 10 * 2, 1, 1, relu=False, bn=False)
self.rpn_regress = basic_conv(512, 10 * 2, 1, 1, relu=False, bn=False)
重点–CTPN得anchor
由上面得第二张image我们可知,Faster RCNN用来检测文字时采用的是一个大框,未考虑文本长条型的特性。
而CTPN通过`分治法的思想,采用了一组(10个) 等宽度的竖向Anchors,用于定位文字位置。
Anchor宽高为:
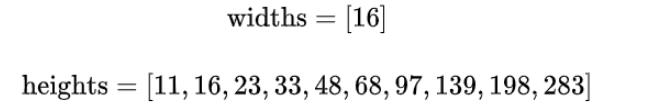
CTPN在全连接的特征图上,其中的每个点都会有10anchor锚框
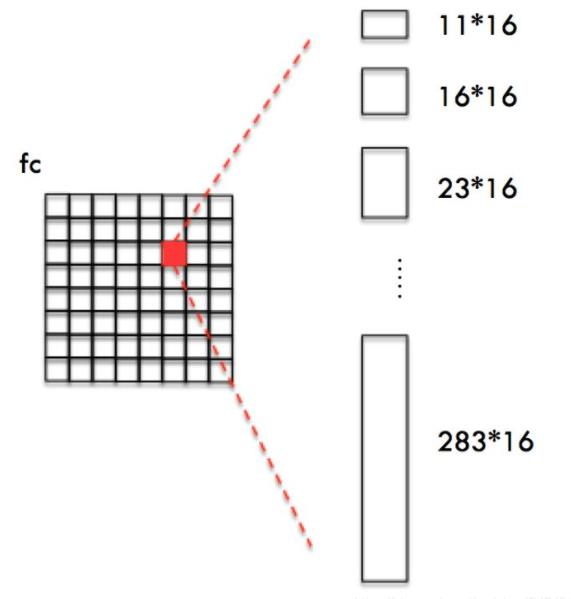
例图:
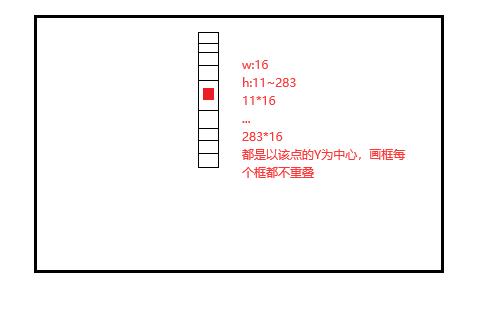
CTPN设置Anchors是为了:
- 保证在水平方向上,Anchor覆盖原图每个点且不相互重叠。
- 不同文本在竖直方向上高度差距很大,所以设置Anchors高度为11-283,用于覆盖不同高度的文本目标。
因为anchors是
16
∗
H
(
11
到
283
)
16*H (11到283)
16∗H(11到283)的锚框(是文字在图像中的位置)。
因此在获得Anchor后,CTPN会做如下处理:
- Softmax判断Anchor中是否包含文本,即选出Softmax score大的正Anchor(
就是找出文字在anchors里概率最大锚框)。 - Bounding box regression修正包含文本的Anchor的中心y坐标与高度。 注意,与Faster
R-CNN不同的是,这里Bounding box regression不修正Anchor中心x坐标和宽度。(这是因为anchors的wide是固定16,可以根据增加anchors来达到覆盖完全)
如下图

后面对检测出来的anchors就需要去构造文本行,将两个anchors相近的合并为一个anchors,成为一个文本行。
对于文本行的构造就需要去(1)判断两个anchors的垂直方向上的重合度,大于0.5;(2)对两个anchors的中心位置间的距离经行判断,小于30PX;
CTPN中为何使用双向LSTM?
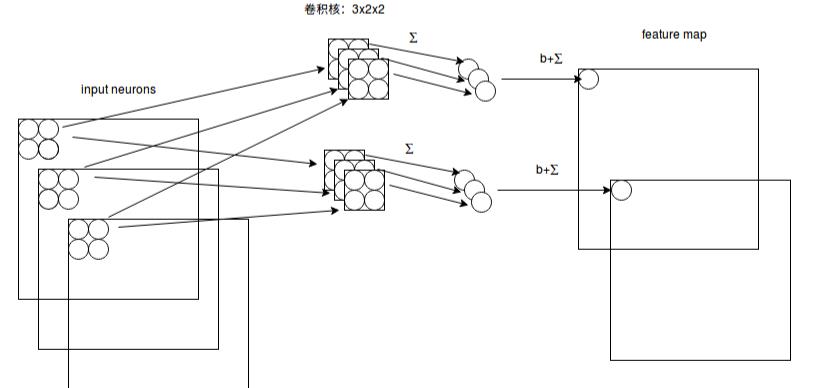
CNN学习的是感受野内的空间信息,LSTM学习的是序列特征。对于文本序列检测,显然既需要CNN抽象空间特征,也需要序列特征(毕竟文字是连续的)。
CTPN的优缺点
优点
(1)采用一组竖直Anchor定位文字位置,将文本检测任务转换为一连串小尺度文本框的检测。
(2)采用CNN与双向LSTM想结合的方式,CNN用于提取图像特征,LSTM用于提取序列前后关系特征。
(3)Side-refinement(边界优化)提升文本框边界预测精准度。
缺点
对于非水平的文本的检测效果并不好。
参考文献:https://blog.csdn.net/weixin_42454048/article/details/114444748
参考文献:https://zhuanlan.zhihu.com/p/34757009
参考文献:https://blog.csdn.net/qq_14845119/article/
希望这篇文章对你有用!
谢谢点赞评论!
以上是关于OCR--秒懂文字检测CTPN(CNN+LSTM) 二的主要内容,如果未能解决你的问题,请参考以下文章