canal 源码解析系列-store模块解析
Posted 犀牛饲养员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了canal 源码解析系列-store模块解析相关的知识,希望对你有一定的参考价值。
引言
parser模块用来订阅binlog事件,然后通过sink投递到store。store模块用来执行最终的落库(基于内存),数据存储。
正文
核心接口是CanalEventStore,目前只有一个实现类MemoryEventStoreWithBuffer,这是一个基于内存buffer构建内存memory store。先来看下类图:
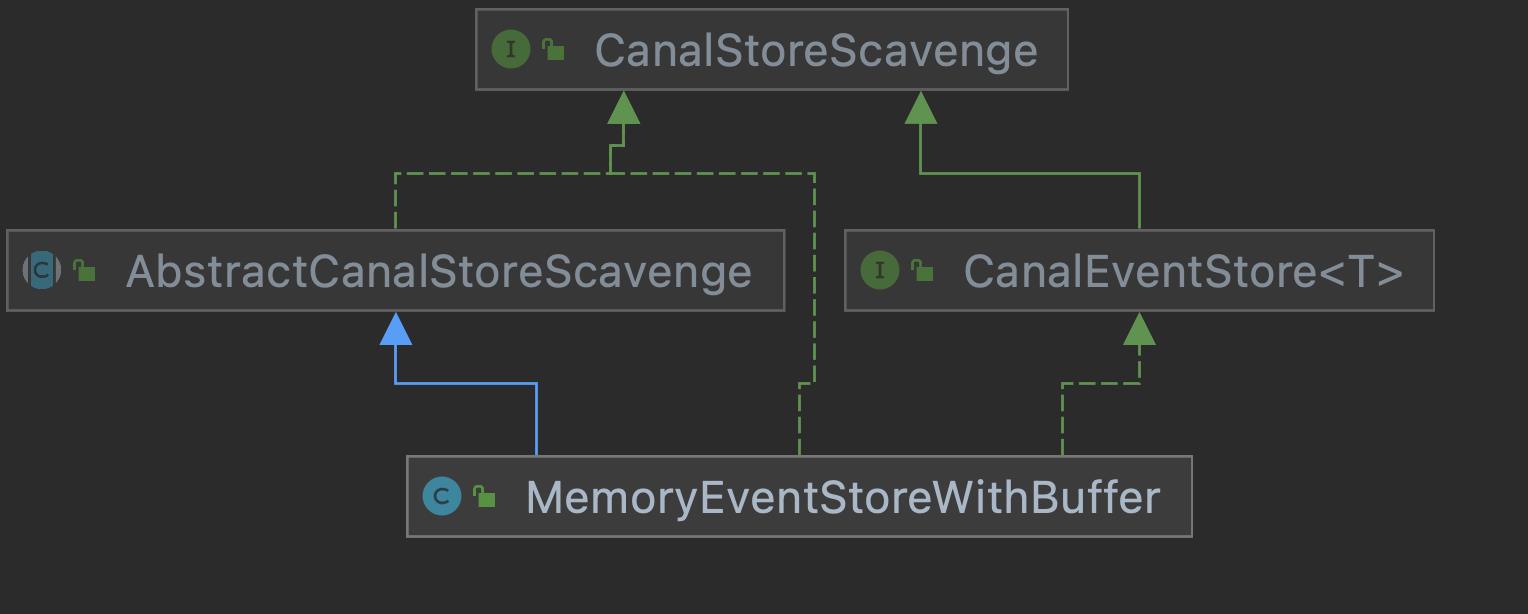
CanalStoreScavenge接口是干啥的?CanalEventStore都继承了它。看下它的接口定义:
/**
* store空间回收机制,信息采集以及控制何时调用{@linkplain CanalEventStore}.cleanUtil()接口
*
* @author jianghang 2012-8-8 上午11:57:42
* @version 1.0.0
*/
public interface CanalStoreScavenge {
/**
* 清理position之前的数据
*/
void cleanUntil(Position position) throws CanalStoreException;
/**
* 删除所有的数据
*/
void cleanAll() throws CanalStoreException;
}
通过注释大概能看出来,这是专门抽象了一个接口来解决数据清理的问题。比如定时清理,满了之后清理,每次 ack 清理等。晚点再说清理的具体实现原理。
CanalEventStore接口定义的方法很多,不过总体可以分为4类接口:
- put
- get
- ack
- rollback
接口定义如下:
public interface CanalEventStore<T> extends CanalLifeCycle, CanalStoreScavenge {
/**
* 添加一组数据对象,阻塞等待其操作完成 (比如一次性添加一个事务数据)
*/
void put(List<T> data) throws InterruptedException, CanalStoreException;
/**
* 添加一组数据对象,阻塞等待其操作完成或者时间超时 (比如一次性添加一个事务数据)
*/
boolean put(List<T> data, long timeout, TimeUnit unit) throws InterruptedException, CanalStoreException;
/**
* 添加一组数据对象 (比如一次性添加一个事务数据)
*/
boolean tryPut(List<T> data) throws CanalStoreException;
/**
* 添加一个数据对象,阻塞等待其操作完成
*/
void put(T data) throws InterruptedException, CanalStoreException;
/**
* 添加一个数据对象,阻塞等待其操作完成或者时间超时
*/
boolean put(T data, long timeout, TimeUnit unit) throws InterruptedException, CanalStoreException;
/**
* 添加一个数据对象
*/
boolean tryPut(T data) throws CanalStoreException;
/**
* 获取指定大小的数据,阻塞等待其操作完成
*/
Events<T> get(Position start, int batchSize) throws InterruptedException, CanalStoreException;
/**
* 获取指定大小的数据,阻塞等待其操作完成或者时间超时
*/
Events<T> get(Position start, int batchSize, long timeout, TimeUnit unit) throws InterruptedException,
CanalStoreException;
/**
* 根据指定位置,获取一个指定大小的数据
*/
Events<T> tryGet(Position start, int batchSize) throws CanalStoreException;
/**
* 获取最后一条数据的position
*/
Position getLatestPosition() throws CanalStoreException;
/**
* 获取第一条数据的position,如果没有数据返回为null
*/
Position getFirstPosition() throws CanalStoreException;
/**
* 删除{@linkplain Position}之前的数据
*/
void ack(Position position) throws CanalStoreException;
/**
* 删除指定seqId之前的数据
*
* @Since 1.1.4
*/
void ack(Position position, Long seqId) throws CanalStoreException;
/**
* 出错时执行回滚操作(未提交ack的所有状态信息重新归位,减少出错时数据全部重来的成本)
*/
void rollback() throws CanalStoreException;
}
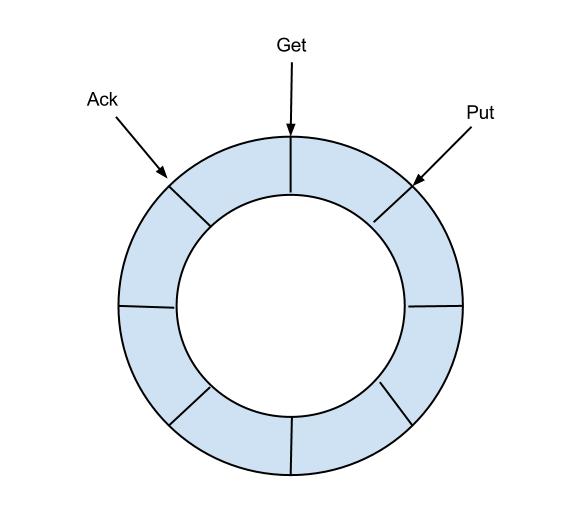
在深入分析源码之前,要先理解EventStore的含义,EventStore是一个RingBuffer,有三个指针:Put、Get、Ack。
- Put: Canal Server从mysql拉取到数据后,放到内存中,Put增加
- Get: 消费者(Canal Client)从内存中消费数据,Get增加
- Ack: 消费者消费完成,Ack增加。并且会删除Put中已经被Ack的数据
RingBuffer是Disruptor中的设计概念,这个有兴趣的可以查阅相关资料

put方法的实现有很多种,但是核心都差不多,最终都是调用doPut方法,我们来看其中一个put方法的源码:
public boolean put(List<Event> data, long timeout, TimeUnit unit) throws InterruptedException, CanalStoreException {
if (data == null || data.isEmpty()) {
return true;
}
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
//检查是否满足插入条件
if (checkFreeSlotAt(putSequence.get() + data.size())) {
doPut(data);
return true;
}
//判断是否已经超时,如果超时,则不执行插入操作,直接返回false
if (nanos <= 0) {
return false;
}
try {
//队列满了,等一会
nanos = notFull.awaitNanos(nanos);
} catch (InterruptedException ie) {
//如果一直等待到超时,都没有可用空间可以插入,notFull.awaitNanos会抛出InterruptedException
//超时之后,唤醒一个其他执行put操作且未被中断的线程(感觉就是自己不行了,让其他兄弟再试试)
notFull.signal(); // propagate to non-interrupted thread
throw ie;
}
}
} finally {
lock.unlock();
}
}
操作之前先加锁,MemoryEventStoreWithBuffer使用的是ReentrantLock,考虑到put操作的线程安全,这里加速是显而易见的。不过有个细节我们考虑下,为啥要把成员变量lock赋值给一个本地变量再进行后续的操作呢?
其实如果你看的源码比较多,会发现很多地方都有类似的操作。我个人理解,这是一个良好的编码习惯。它至少有两个好处:一是拷贝给方法的本地变量后,访问效率更高(一个是在堆上,一个是栈上)。另一个原因本地变量用了final修饰,可以保证在操作的过程中即使成员变量被修改了也不会影响到自己。
然后我们看到notFull变量,还有一个变量叫notEmpty,他们两个一般搭配使用:
// 阻塞put/get操作控制信号
private ReentrantLock lock = new ReentrantLock();
private Condition notFull = lock.newCondition();
private Condition notEmpty = lock.newCondition();
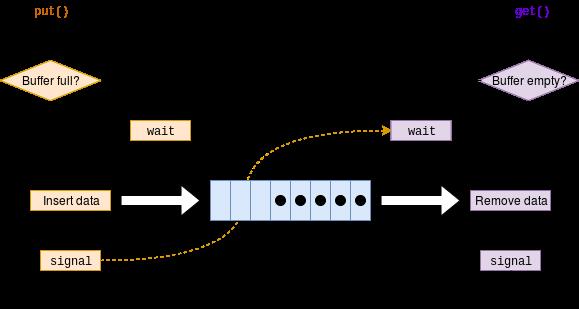
这是一个比较经典的使用场景,在这个场景中,通常有生产者和消费者两个角色,然后有一个共享缓冲区。生产者用于将消息放入缓冲区,消费者用于从缓冲区中取出消息。
当缓冲区已经满了,而此时生产者还想放入一个新的数据的时候,解决方法是让生产者此时进行休眠(notFull.await),等待消费者从缓冲区中取走了一个或者多个数据后再去唤醒它(notFull.signal)。
同样当缓冲区已经空了,而消费者还想去取数据,此时让消费者进行休眠(notEmpty.await()),等待生产者放入一个或者多个数据时再唤醒它(notEmpty.signal)。我们可以用一幅图来描述上述流程:
checkFreeSlotAt方法是用来检查是否满足插入条件,看看它的实现:
/**
* 查询是否有空位
*/
private boolean checkFreeSlotAt(final long sequence) {
//1、检查是否足够的slot。入参的sequence值是:当前putSequence位置 + 新插入的event的记录数。
//结合文章中的图,其减去bufferSize不能大于ack位置,或者换一种说法,减去bufferSize不能大于ack位置。
final long wrapPoint = sequence - bufferSize;//队列的长度默认是16*1024
final long minPoint = getMinimumGetOrAck();//取get或者ack较小的
if (wrapPoint > minPoint) { // 刚好追上一轮
return false;
} else {
// 在bufferSize模式上,再增加memSize控制
//2、如果batchMode是MEMSIZE,继续检查是否超出了内存限制
if (batchMode.isMemSize()) {
final long memsize = putMemSize.get() - ackMemSize.get();
if (memsize < bufferSize * bufferMemUnit) {
return true;
} else {
return false;
}
} else {
return true;
}
}
}
注释写的比较详细了,不多说。
接下来看看核心方法doPut:
/**
* 执行具体的put操作
*/
private void doPut(List<Event> data) {
long current = putSequence.get();//当前put的位置
long end = current + data.size();
// 先写数据,再更新对应的cursor,并发度高的情况,putSequence会被get请求可见,拿出了ringbuffer中的老的Entry值
for (long next = current + 1; next <= end; next++) {
//通过getIndex方法对next变量转换成正确的位置,设置到Event[]数组中,
// Event[]数组是环形队列的底层实现,其大小为bufferSize值,默认为16 * 1024。
// getindex通过与操作一个mask防止越界
entries[getIndex(next)] = data.get((int) (next - current - 1));
}
putSequence.set(end);//更新位置
// 记录一下gets memsize信息,方便快速检索
if (batchMode.isMemSize()) {
long size = 0;
for (Event event : data) {
size += calculateSize(event);
}
putMemSize.getAndAdd(size);
}
profiling(data, OP.PUT);//记录put时间,监控用
// tell other threads that store is not empty
notEmpty.signal();
}
总结下doPut方法,主要有4个操作:
- 的event数据赋值到Event[]数组上
- 更新ringbuffer上的put位置
- 如果是内存模式,计算新插入的event数据对内存的影响
- 调用notEmpty.signal()方法,通知buffer有数据了(get操作阻塞的线程可以被唤醒)
get方法不说了,理解了put很容易理解get方法。我们来看下ack方法:
public void ack(Position position) throws CanalStoreException {
cleanUntil(position, -1L);
}
前面我们提到了CanalStoreScavenge接口,有两个方法:cleanUntil和cleanAll,后者在stop的时候调用,而前者就是在ack的时候调用。
public void cleanUntil(Position position, Long seqId) throws CanalStoreException {
final ReentrantLock lock = this.lock;
lock.lock();
try {
long sequence = ackSequence.get();//当前ack的位置
long maxSequence = getSequence.get();//当前get的位置
boolean hasMatch = false;
long memsize = 0;
// ack没有list,但有已存在的foreach,还是节省一下list的开销
long localExecTime = 0L;
int deltaRows = 0;
if (seqId > 0) {
maxSequence = seqId;
}
//遍历所有未被ack的event,从中找出与需要ack的position相同位置的event,清空这个event之前的所有数据。
for (long next = sequence + 1; next <= maxSequence; next++) {
Event event = entries[getIndex(next)];//要ack的event
if (localExecTime == 0 && event.getExecuteTime() > 0) {
localExecTime = event.getExecuteTime();
}
deltaRows += event.getRowsCount();//要ack的event包含的mysql行数
memsize += calculateSize(event);//要ack的event占用字节数
if ((seqId < 0 || next == seqId) && CanalEventUtils.checkPosition(event, (LogPosition) position)) {
// 找到对应的position,更新ack seq
hasMatch = true;
if (batchMode.isMemSize()) {
ackMemSize.addAndGet(memsize);
// 尝试清空buffer中的内存,将ack之前的内存全部释放掉
for (long index = sequence + 1; index < next; index++) {
entries[getIndex(index)] = null;// 设置为null,方便GC
}
// 考虑getFirstPosition/getLastPosition会获取最后一次ack的position信息
// ack清理的时候只处理entry=null,释放内存
Event lastEvent = entries[getIndex(next)];
lastEvent.setEntry(null);//方便gc
lastEvent.setRawEntry(null);//方便gc
}
//更新ack的值
if (ackSequence.compareAndSet(sequence, next)) {// 避免并发ack
notFull.signal();//清空了就可以继续put数据了
ackTableRows.addAndGet(deltaRows);
if (localExecTime > 0) {
ackExecTime.lazySet(localExecTime);
}
return;
}
}
}
if (!hasMatch) {// 找不到对应需要ack的position
throw new CanalStoreException("no match ack position" + position.toString());
}
} finally {
lock.unlock();
}
}
Ack操作实际上就是将消费成功的事件从队列中删除,如果一直不Ack的话,队列满了之后,Put操作就无法添加新的数据了。
rollback方法比较简单,这里不多说了。
参考:
- https://www.bookstack.cn/read/canal-v1.1.4/34357b71c7c1f182.md#%E6%9E%B6%E6%9E%84
- http://www.tianshouzhi.com/api/tutorials/canal/401
以上是关于canal 源码解析系列-store模块解析的主要内容,如果未能解决你的问题,请参考以下文章