java-----哈希冲突
Posted 小鹿可可乐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java-----哈希冲突相关的知识,希望对你有一定的参考价值。
1,何时哈希冲突
首先在哈希表存储元素时,最初是根据值的hashcode()计算结果作为下标在数组中进行存储,数组开辟的大小至少等于hashcode()值,存在一个问题:如果只有一个元素,但是他的hashcode值很大时,那么就存在堆内存严重浪费的问题。当多个元素的hashcode()返回值相同时,就会发生哈希冲突。
1.当将8、1、2、7都放入数组中后,再放6会发生哈希冲突
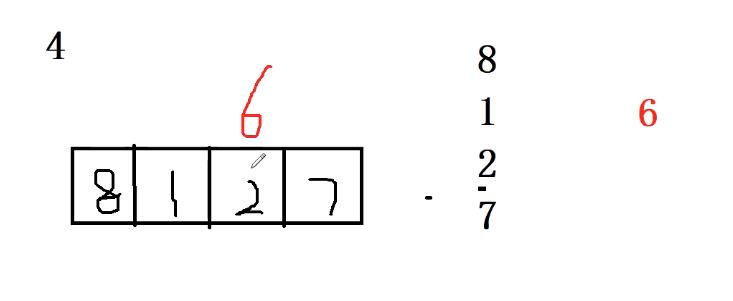
当数组大小为4时
放入过程:
- 8%4=0 将8放入0号下标
- 1%4=1 放入1号下标处
- 2%4=2 放2号下标处
- 7%4=3 放入3号下标处
扩容之后,需要重新哈希
默认大小:16
扩容倍数:0.75
2.线性探测法
思想:主要根据index = val.hashcode()%element.length来解决哈希冲突问题。从数组当前位置(hashcode())开始,找到下一个空位置,进行存放。当数组填充满之后,进行数组的扩容操作,继续存放值。存储的键值对中键相等进行值的覆盖操作。进行扩容后的操作,还得进行元素的重新哈希操作。
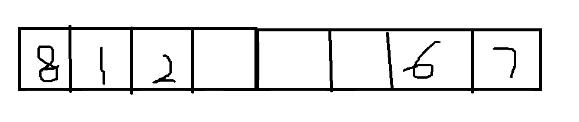
扩容之后,需要重新哈希
默认大小:16
扩容倍数:0.75

2.1 代码实现
map:
public interface Map<K,V>{
void put(K key,V value);//添加
boolean containKey(K key);//是否包含键
void remove(K key);//删除k
V get(K key);//查找k,返回对应value
}
//线性探测法
public class MyHashMap<K extends Comparable<K>,V> implements Map<K,V>{
private Entry<K,V>[] element;
private int size;//有效节点个数
public MyHashMap(){
element = new Entry[16];
}
/*
重新哈希
*/
private void rehash(Entry[] newArray){
//原有的数据依次遍历 重新哈希到新数组中
int index;
for(int i = 0;i< element.length;i++){
if(element[i] != null){
index = element[i].key.hashCode()% newArray.length;
if(newArray[index]==null){
newArray[index] = element[i];
}else {
for (int j = (index + 1) % newArray.length; j != index; j = (++j) % newArray.length) {
if (newArray[j] == null) {
newArray[j] = element[i];
break;
}
}
}
}
}
element = newArray;
}
@Override
public void put(K key, V value) {
//1.如果数组“已满“,扩容因子=> 0.75(不能全满,效率高),扩容,重新哈希
if((double)size/element.length >=0.75){
Entry[] newElement = new Entry[element.length*2];
rehash(newElement);
}
//2.index? 如果哈希冲突,从当前位置开始找一圈,找一个空位置插入
int index = key.hashCode()% element.length;//获得插入数据的下标
if(element[index] == null){
element[index] = new Entry<>(key,value);
}else{ //存在元素
for(int i = (index+1)%element.length;i != index;i=(++i)% element.length){
if(element[i]==null){
element[i] = new Entry<>(key,value);
break;
}
}
}
size++;
}
@Override
public boolean containKey(K key) {
for(int i = 0;i < element.length;i++){
if(element[i] != null){
if(element[i].key.compareTo(key)==0){
return true;
}
}
}
return false;
}
@Override
public void remove(K key) {
for(int i = 0;i < element.length;i++){
if(element[i] != null){
if(element[i].key.compareTo(key)==0){
element[i]=null;
}
}
}
}
@Override
public V get(K key) {
for(int i = 0;i < element.length;i++){
if(element[i] != null){
if(element[i].key.compareTo(key)==0){
return element[i].value;
}
}
}
return null;
}
static class Entry<K,V>{
private K key;
private V value;
public Entry(K key,V value){
this.key = key;
this.value = value;
}
}
}
3.链地址法
线性探测法当产生哈希冲突的键值对越多,遍历数组的次数就会越多。为了解决这个问题,我们采用数组和链表结合的方式,数组元素是一个链表结构,产生哈希冲突,在相同的索引下标下进行链表的插入操作。
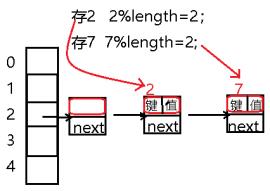
缺点:
① 链地址法存在的不足在于,当产生哈希冲突的节点越多,那么数组索引下标查找就会变成链表的遍历操作。数组的优势在于随机取值,时间复杂度达到O(1),而链表的查找时间效率达到O(n)。
② 当产生数组扩容时,所有的元素节点都必须进行重新哈希。
3.1代码实现
重新哈希:
import src15.Map;
public class MyLinkedHashMap<K extends Comparable<K>,V>implements Map<K,V> {
private Node<K,V>[] element;//Node 节点类型
private int node_size;//保存当前节点个数
private int array_size;//数组有效个数
private static final double LOADFACTOR = 0.75;
private static final int INITSIZE = 10;
//构造
public MyLinkedHashMap(){
element = new Node[INITSIZE];
}
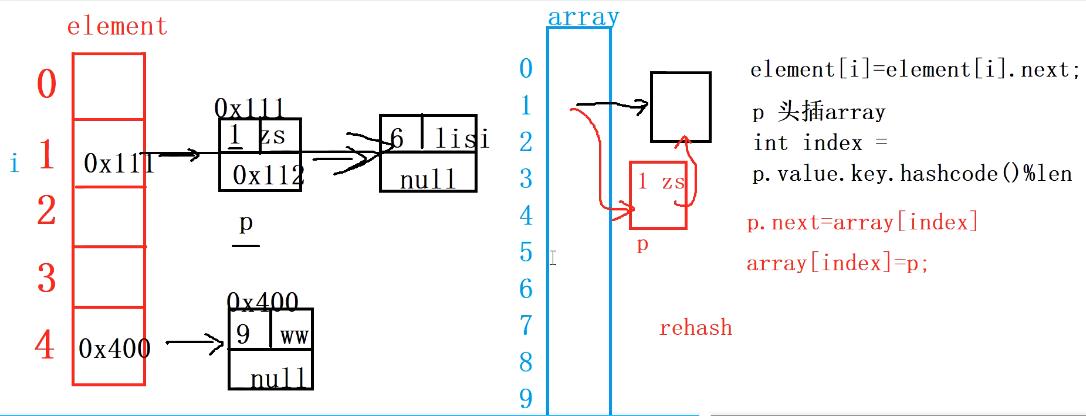
private void rehash(Node<K,V>[] array){
array_size=0;
for(int i = 0;i<element.length;i++){//遍历原数组
while(element[i] != null){
Node<K,V> p = element[i];//p用来节点删除以及头插array中
element[i] = element[i].next;//p从当前链表独立出来
int arrayIndex = p.value.key.hashCode()% array.length;//新数组插入的下标
if(array[arrayIndex]==null){
array_size++;
}
p.next = array[arrayIndex];
array[arrayIndex] = p;//p头插进数组中
}
}
element = array;
}
@Override
public void put(K key, V value) {
//map特点 键相同,值覆盖
Node.Entry<K,V> entryKV = containKey0(key);
if(entryKV !=null){//找到,值覆盖
entryKV.value=value;
return;
}
//键不存在,插入操作
if (1.0 * array_size / element.length >= LOADFACTOR) {//扩容
Node<K, V>[] newArray = new Node[element.length * 2];
rehash(newArray);
}
//1.根据key值,求index -> 单链表头插
int index = key.hashCode()% element.length;
if(element[index] == null){
array_size++;
}
//2.头插法
Node.Entry<K,V> entry = new Node.Entry<>(key,value);
Node<K,V> node = new Node<>(entry);
node.next = element[index];// 头插 新节点的next 保存原来”head‘
element[index] = node;// 保存新的头部起始位置
node_size++;
}
private Node.Entry containKey0(K key){
int index = key.hashCode()% element.length;
for(Node<K,V> p = element[index];p!=null;p=p.next){
if(p.value.key.compareTo(key) == 0){
return p.value;
}
}
return null;
}
@Override
public boolean containKey(K key) {
return containKey0(key) != null;
}
@Override
public void remove(K key) {
}
@Override
public V get(K key) {
Node.Entry<K,V> entry = containKey0(key);
if(entry == null){
return null;
}else{
return entry.value;
}
}
//单链表节点类型
static class Node<K,V>{
private Entry<K,V> value;
private Node<K,V> next;
//构造
public Node(Entry<K, V> value) {
this.value = value;
}
//键值对
static class Entry<K,V>{
private K key;
private V value;
public Entry(K key, V value) {
this.key = key;
this.value = value;
}
}
}
}
今天也要好好学习呀~
以上是关于java-----哈希冲突的主要内容,如果未能解决你的问题,请参考以下文章