数据结构排序
Posted 蓝乐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构排序相关的知识,希望对你有一定的参考价值。
排序
排序的概念
所谓排序,即是将一串数据,按照某个或某些关键字的大小,按照递增或递减的顺序排列的操作。
常见的几种排序算法

本篇文章将介绍插入排序和选择排序。
一.插入排序
插入排序的思想其实在日常生活中就有体现,比如我们平时打扑克牌时,一般会将所发的牌按照顺序插入到已经有序的牌中,这便是插入排序了
其基本思想即为将待排序的记录按其关键值的大小插入到一个已经有序的序列当中,直到所有的记录插入完为止,得到一个新的有序序列。
1.直接插入排序
概念及分析
顾名思义,当插入a[i]时,a[0],a[1]…a[i - 1] 已经有序,则将a[i] 插入到前i个数中的合适位置,原来位置上的元素按顺序后移。
首先在实现直接插入排序算法之前,我们先将插入算法进行分解,先看看将一个数插入到一个已经有序的数列中的操作,比如将17插入到下列数据{3,5,6,13,28}中,记end为有序序列的最后一个数的下标,将17与end依次比较,若17比end处的值小,则将end处的数据依次后移,直到17比end大则结束比较,同时17与end + 1下标的数进行交换,那么这一趟比较的终止条件则为end < 0。考虑两个极端情况,(1)若17最大,则直接插入到数列最后即可;(2)若17最小,则将17插入到数据开头即可。

解决完一趟插入排序要进行的操作后,那么接下来就需要思考全部数据进行插入排序的条件了,即遍历数组将end从 0 开始遍历到 n - 2,进行上述的一趟插入操作,即可将数据进行排序。为什么是n - 2,而不是n - 1 呢,这是因为在end到n - 2时,即是将n - 1处的数据进行插入操作。
算法实现
综上所述,即可写出直接插入排序的代码了:
void InsertSort(int* a, int n)
{
int i = 0;
for (i = 0; i <= n - 2; i++)//遍历数组,对每一个数据进行插入排序
{
int end = i;//前end个数据已经有序
int tmp = a[end + 1];//故将end + 1 处的数据进行插入排序
while (end >= 0)//比较进行的条件
{
if (tmp < a[end])//若tmp小于end处的数据,则让tmp与end前的数比较,同时将end处的数据后移
{
a[end + 1] = a[end];
end--;
}
else//若tmp大于end处的数据,则结束比较
break;
}
a[end + 1] = tmp;//将tmp插入到其所要插入的位置
}
}
小结
直接插入排序的特性总结:
- 元素集合越接近有序,直接插入排序算法的时间效率越高
- 时间复杂度:O(N^2)
- 空间复杂度:O(1),它是一种稳定的排序算法
2.希尔排序
概念及分析
希尔排序又称缩小增量排序。希尔排序法的基本思想是:先选定一个整数,把待排序文件中所有记录分成gap个组,所有距离为gap的记录分在同一组内,并对每一组内的记录进行排序。然后,逐渐缩小gap,重复上述分组和排序的工作。当到达gap=1时,所有记录在同一组内排好序。
简单来说,希尔排序先进行预排序,就是将一组数据分为gap组,分别对这gap组数进行直接插入排序,比如gap = 3

实际上,当gap = 1时,希尔排序就是直接插入排序,因此希尔排序的一趟排序的思想与直接插入排序并无区别,只是将end处的值后移gap以及将end前移gap罢了。而对整体数据进行排序的条件是i < n - gap,与直接插入排序一样,当i遍历到n - gap时,每组数据都已经有序,同时逐渐缩小gap到1,即完成排序。
算法实现
希尔排序的代码如下:
void ShellSort(int* a, int n)
{
int i = 0;
int gap = n / 3;
while (gap > 1)
{
//gap > 1 时为预排序,gap = 1 时数据有序
gap = gap / 3 + 1;
for (i = 0; i < n - gap; i++)//遍历前 n - gap 个数,逐渐缩小gap,分组进行插入排序
{
int end = i;
int tmp = a[end + gap];//每次将同一组的数据进行插入排序
while (end >= 0)
{
if (tmp < a[end])//若tmp小于end处的数据,则将end处的数据后移,同时end前移gap
{
a[end + gap] = a[end];
end -= gap;
}
else//若tmp大于end处的数据,则结束比较
break;
}
a[end + gap] = tmp;//将tmp插入到end + gap处
}
}
}
小结
希尔排序的特性总结:
- 希尔排序是对直接插入排序的优化。
- 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样排序就会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。
- 希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,因此在好些书中给出的希尔排序的时间复杂度都不固定。
二.选择排序
选择排序的基本思想:每一次将待排序的数据中的最小或最大的数据放在该序列的起始位置,直到全部待排序的数据排完。
1.直接选择排序
概念
直接选择排序的步骤是
1.在a[i] 到 a[n - 1]中选出最小(或最大)的元素
2.若该元素不是这组数中的第一个(或最后一个)元素,则将其与第一个(或最后一个)元素交换
3.在剩下的数中重复上述操作,直到待操作序列只剩下一个数据。

简单分析之后,直接选择排序的代码实现就很简单了:
算法分析
void SelectSort(int* a, int n)
{
int i = 0;
for (i = 0; i < n - 1; i++)//排序n - 1趟即可使数列达到有序
{
int mini = i;
int j = 0;
for (j = i; j < n - 1; j++)//每一趟选出最小的数据的下标
{
if (a[mini] > a[j])
{
mini = j;
}
}
Swap(&a[mini], &a[i]);//交换
}
}
但是这个算法的效率其实是很低的,需要将数据多次对比才能够完成排序,因此在可以对该算法进行优化,即使用两个变量同时求出最大值和最小值,并进行交换,这样的算法效率比原来的高了一倍,代码如下:
void SelectSort(int* a, int n)
{
int begin = 0;
int end = n - 1;
while (begin < end)
{
int maxi = begin;
int mini = begin;
int i = 0;
for (i = begin; i <= end; i++)//每趟找出[begin, end] 中的最大值和最小值
{
if (a[maxi] < a[i])
{
maxi = i;
}
if (a[mini] > a[i])
{
mini = i;
}
}
//注意特殊情况可能会出现bug
if (maxi == begin)
{
maxi = mini;
}
Swap(&a[mini], &a[begin]);
Swap(&a[maxi], &a[end]);
begin++;
end--;
}
}

小结
直接选择排序的特性总结:
- 直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
2.堆排序
概念
堆排序是指利用堆积树进行选择排序的算法,它是选择排序的一种。它是通过堆来进行选择排序。需要注意的是排升序要建大根堆,排降序要建小根堆。
算法分析
堆排序的步骤是:首先建一个大根堆,其次每次选出大根堆堆顶的元素,在对接下来的数据进行调整,使其认为大根堆,重复上述步骤,就得到了一个升序的序列。
堆的介绍及大根堆的构建
什么是堆?堆就是一棵完全二叉树,且满足所有的父亲结点都大于孩子结点(即大根堆)或者所有的父亲结点都小于孩子结点(即小根堆)。
那么大根堆要如何构建呢?首先我们来介绍一种向下调整算法:

向下调整算法的实现:
void AdjustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)//从当前父亲结点开始不断向下调整
{
if (child < n - 1 && a[child] < a[child + 1])//选出左右孩子中较大的那个
{
++child;
}
if (a[parent] < a[child])//若父亲结点小于孩子结点中较小的那个,交换之
{
Swap(&a[parent], &a[child]);
//迭代
parent = child;
child = parent * 2 + 1;
}
else//若当前父亲结点符合条件则跳出循环
{
break;
}
}
}
在了解了向下调整算法之后,我们再来介绍一下如何构建大根堆:
从最后一个父亲结点开始,一直向下调整,最后得到的树便是大根堆。
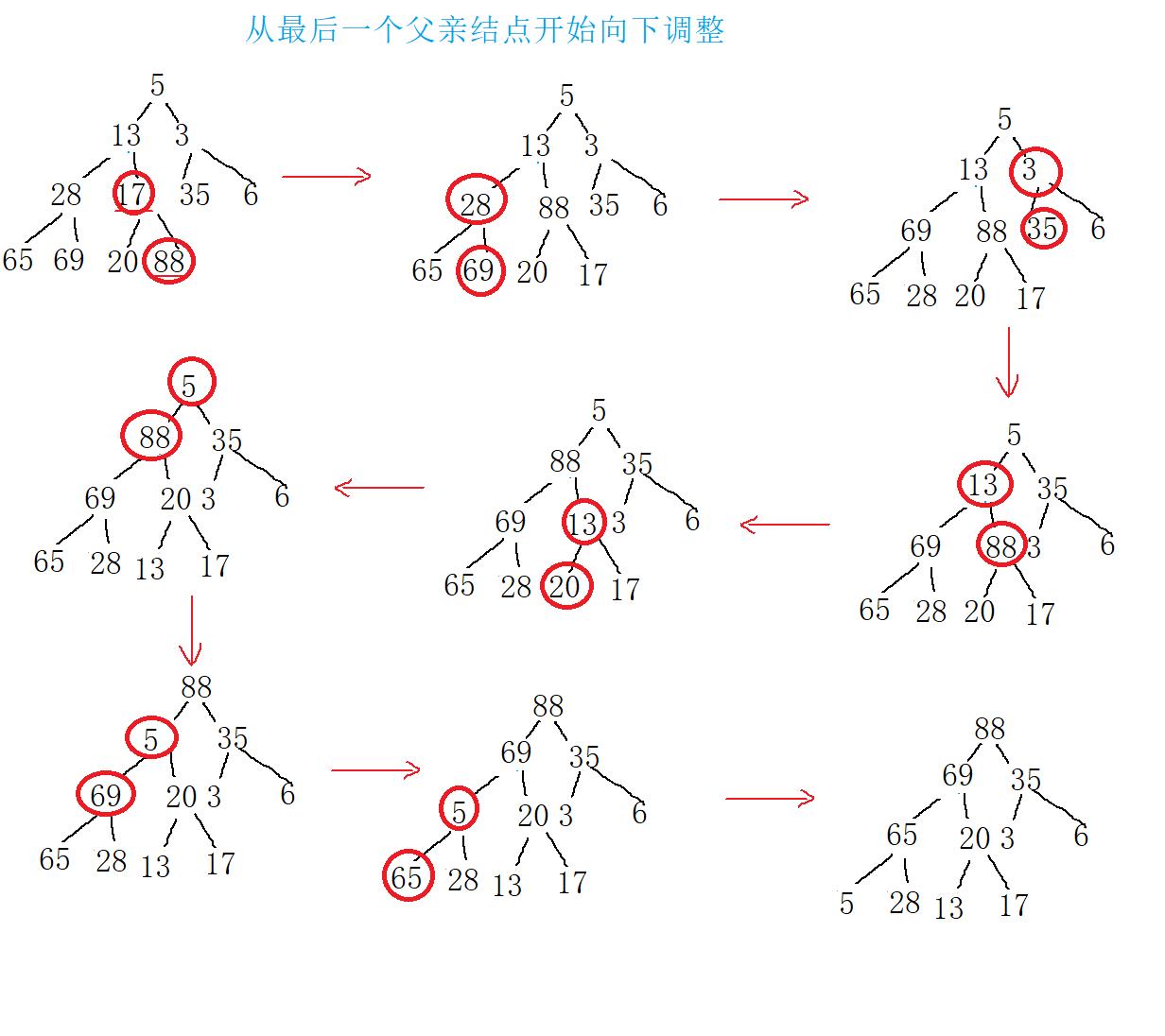
建好大根堆后,我们每次从堆中选出堆顶元素,将其与最后一个叶子结点交换,这样除了交换前的堆顶元素,交换后的堆底元素为这组数的最大值,且出去二者外,堆顶结点的两棵子树均为大根堆,这是将堆顶结点向下调整即可维持大根堆,重复上述步骤最后得到的序列则为升序序列。
综上所述,堆排序的代码为:
void HeapSort(int* a, int n)
{
//向下调整建大根堆
int i = 0;
for (i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
//每次选出堆顶元素进行排序
int end = n - 1;
while (end >= 0)
{
Swap(&a[end], &a[0]);
//向下调整保持堆
AdjustDown(a, end, 0);
end--;
}
}
小结:
- 堆排序使用堆来选数,效率就高了很多。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(1)
以上是关于数据结构排序的主要内容,如果未能解决你的问题,请参考以下文章