hive储存与压缩
Posted Z-hhhhh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive储存与压缩相关的知识,希望对你有一定的参考价值。
Hive支持的储存格式主要有:textfile(行列存储)、sequencefile(行列存储)、ORC(列式存储)、parquet(列式存储)
1.1、行式存储和列式存储
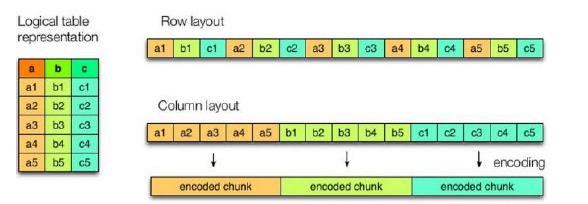
左图为逻辑表,右边第一个为行式存储,第二个为列式存储
**行式存储的特点:**查询满足条件的一整行数据的时候,列存储需要每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻的地方,所以此时行存储查询的速度更快。 select * 效率高 。
**列存储的特点:**因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同,列式存储可以针对性的设计更好的设计压缩算法。select某些字段效率更高。
1.2、textfile
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统会自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行切分,从而无法对数据进行并行操作。
1.3、ORC格式
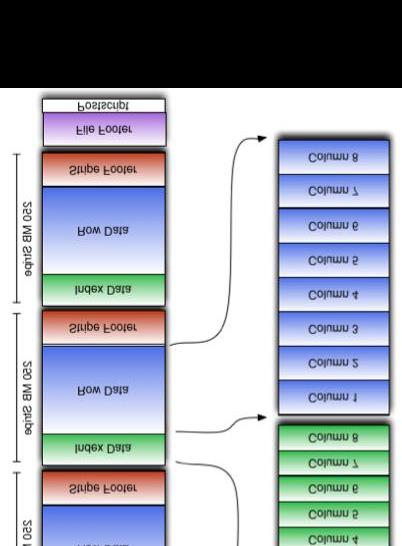
Orc (Optimized Row Columnar)是hive 0.11 版里引入的新的存储格式。可以看到每个Orc 文件由1 个或多个stripe 组成,每个stripe250MB 大小,这个Stripe 实际相当于RowGroup 概念,不过大小由4MB->250MB,这样能提升顺序读的吞吐率。每个Stripe 里有三部分组成,分别是Index Data,Row
-
Index Data: 是一个轻量级的index,默认是每个1W行做一个索引。这里做的索引只是记录某行的各字段在Row Data中的offset。
-
Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
-
Stripe Footer:存的是各个stripe的元数据信息。
每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文
件的压缩类型以及FileFooter 的长度信息等。在读取文件时,会seek 到文件尾部读PostScript,从里面解析到File Footer 长度,再读FileFooter,从里面
解析到各个Stripe 信息,再读各个Stripe,即从后往前读。
1.4、parquet格式
Parquet 文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet 格式文件是自解析的。
通常情况下,在存储Parquet 数据的时候会按照Block 大小设置行组的大小,由于一般情况下每一个Mapper 任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper 任务处理,增大任务执行并行度。Parquet 文件的格式如下图所示。

上图展示了一个Parquet文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length记录了文件元数据的大小,通过该值和文件的长度可以计算元数据的偏移量,文件的元数据中包括每一个行组额元数据信息和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页,字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持引页。
二、Hive压缩格式
2.1、hadoop中的压缩
hive在处理时,一般都需要经过压缩。在配置hadoop时,已经配置了压缩,hive也是可以使用这些压缩来节省MR处理的网络宽带。
mr支持的压缩格式
| 压缩格式 | 工具 | 算法 | 文件扩展名 | 是否可切分 |
|---|---|---|---|---|
| DEFAULT | 无 | DEFAULT | .default | 否 |
| Gzip | gzip | DEFAULT | .gz | 否 |
| bzip2 | bzip2 | bzip2 | .bz2 | 是 |
| LZO | lzop | LZO | .lzo | 是(需要手动加索引) |
| LZ4 | 无 | LZ4 | .lz4 | 否 |
| Snappy | 无 | Snappy | .snappy | 否 |
BZip2压缩率最高,但是需要消耗最多的CPU,且压缩/解压速度慢。
GZip是压缩率和压缩/解压速度都是中等。
LZO和Snappy压缩率相比前面两个要小,但是压缩和解压很快。
2.2、hive配置压缩方式
####map端得压缩方式
# 开启hive中间传输数据压缩功能
set hive.exec.compress.intermediate=true;
# 开启mapredcue中map输出压缩功能
set mapreduce.map.output.compress=true;
# 设置mapreduce 中map 输出数据的压缩方式
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
#### 开启reduce压缩方式
# 开启hive最终数据数据压缩功能
set hive.exec.compress.output=true;
# 开启mapreduce最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true;
# 设置mapreduce最终数据数据压缩方式
set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
# 设置mapreduce之中数据输出压缩为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
2.3、结论
数据压缩比结论
ORC > Parquet > textFile
存储文件的查询效率比较:
ORC > TextFile > Parquet
以上是关于hive储存与压缩的主要内容,如果未能解决你的问题,请参考以下文章
打怪升级之小白的大数据之旅(六十八)<Hive旅程第九站:Hive的压缩与存储>